はじめに
Elastic の Inference API が提供するチャンク分割には、従来の sentence(文単位で区切る)モードや word (単語単位) が使われてきました。これは比較的単純で、短めのテキストや文書に適していますが、構造のある長文や Markdown/段落入りドキュメント、レポートやマニュアルなどを扱うには、文レベルだけでは最適でないことがあります。
sentence モードについてはこちらの記事を参照してください
https://qiita.com/takeo-furukubo/items/2b9becaf2c5aa4f04ffb
このたび追加された recursive モードは、段落区切り、Markdown の見出しや水平線などの構造/セパレータを利用して、ドキュメントを意味ある塊に分割する新しいチャンク戦略です。必要に応じて再帰的に分割・再結合を試みるため、いわゆる「セクション単位」でのチャンク化が可能になり、構造化された長文の処理に強みを持ちます。
2025/12/12: Tech Preview機能のため変更の可能性があります。利用にはEnterpriseライセンスが必要です
準備
Elasticのクラスタがあればよいです。
このあたりを参考にしてください
https://qiita.com/takeo-furukubo/items/250245360d59c1765408#elastic%E3%82%AF%E3%83%A9%E3%82%B9%E3%82%BF%E3%81%AE%E4%BD%9C%E6%88%90
手順
E5モデルの利用を前提としています。
設定
まずはsentenceモードとrecursiveモードでEmbeddingするためのインタフェースを作成します。
以下をDev Toolsで実行します。一回目はモデルのダウンロードなどがあるので時間がかかります。
ちなみにこれはMac用です。Intel系ならmodel_idを.multilingual-e5-small_linux-x86_64に変えます。
PUT _inference/text_embedding/e5-recursive
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".multilingual-e5-small"
},
"chunking_settings": {
"strategy": "recursive",
"max_chunk_size": 250
}
}
PUT _inference/text_embedding/e5-sentence
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".multilingual-e5-small"
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250
}
}
次にインデックスを作成します。
sentenceフィールドとrecursiveフィールドで異なるinference_idを使っていますので、チャンキングの方法がそれぞれのフィールドで変わります。
PUT test-index-e5
{
"mappings": {
"properties": {
"description": {
"type": "text",
"fields": {
"sentence": {
"type": "semantic_text",
"inference_id": "e5-sentence"
},
"recursive": {
"type": "semantic_text",
"inference_id": "e5-recursive"
}
}
}
}
}
}
データ投入
Markdownを入れてみます。
POST test-index-e5/_doc
{
"description": "# はじめに\n\n現代のシステム運用では、メトリクス、ログ、トレース、構成情報など、さまざまなデータソースを組み合わせて分析する オブザーバビリティ が重要になっています。\nたとえば「特定のホストでCPU使用率が高い原因はどのリージョンやラックに設置されたどのハードウェアか?」といった問いに答えるには、複数のデータを正確に突き合わせる必要があります。\n\nElasticsearchのES|QLでは、これまでLOOKUP JOINを使うことで異なるインデックスのデータを結合できましたが、単一キーでの結合しかサポートされていなかったため、同じホスト名が複数リージョンに存在する場合などには誤った結合が発生することがありました。\n\nしかし最新のアップデートにより、複数キーでのLOOKUP JOINがサポートされるようになりました。\nこれにより、host.name と cloud.region のような複合キーで正確にデータを結合でき、Observabilityデータの分析精度が格段に向上します。\n\n本記事では、この新機能を活用して サンプルデータを作成・Elasticsearchに投入し、複合キーJOINでメトリクスとインベントリ情報を結合する方法 を紹介します。\n\n# Elasticクラスタの作成\nstart localでPC上に作ってもクラウドでもOKです\nObservability Solution Viewを前提にしています\n- クラウド\nhttps://cloud.elastic.co/registration\nHostedとServerlessがありますが、Serverlessは東京リージョンはまだAWSにしかありませんので、今回はhostedをベースに話を進めます\n作成する際にObservabilityを選ぶと今回の用途には何かと便利です。\nこのキャプチャだと真ん中です。\n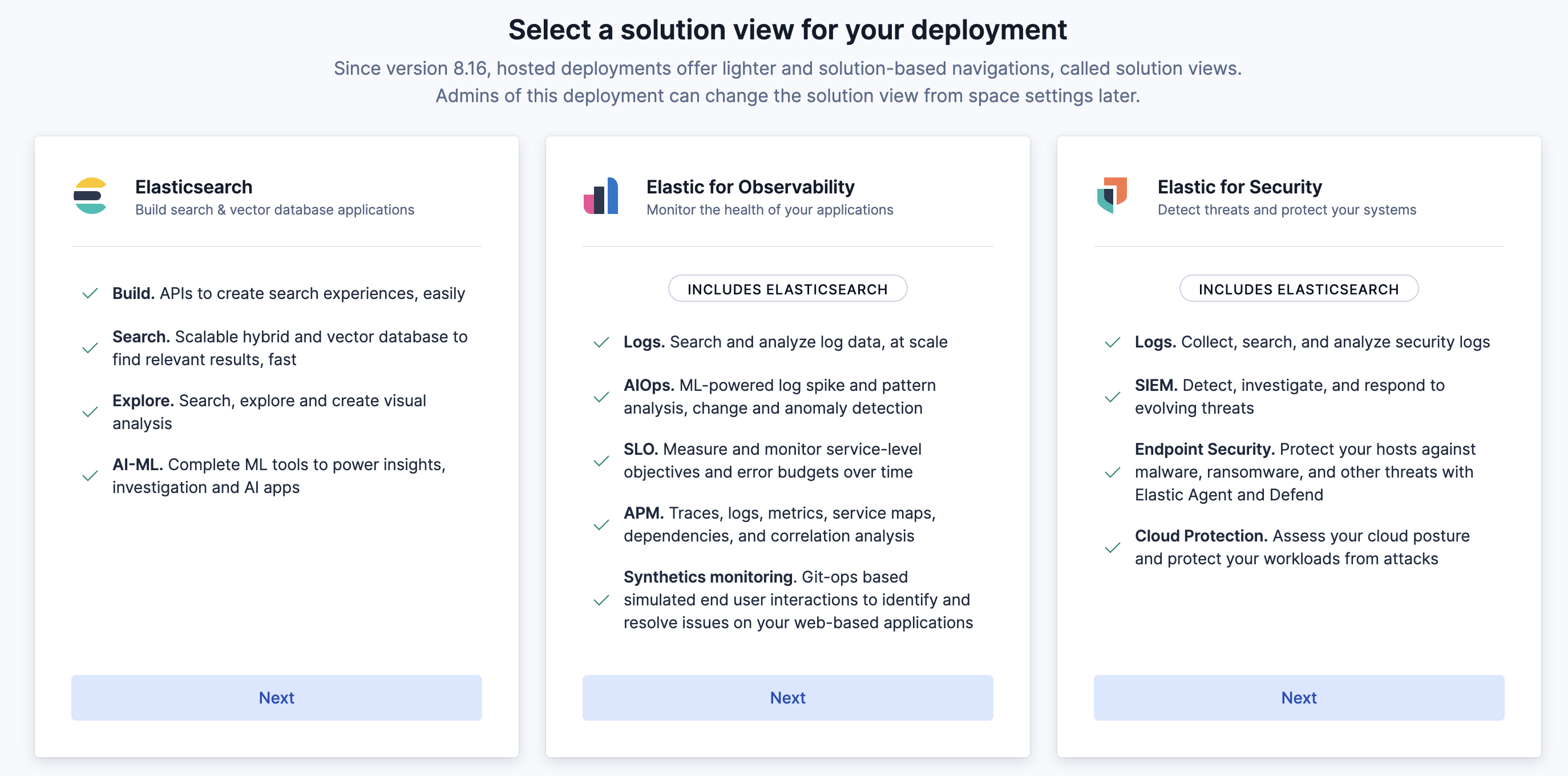\n\n- ローカル\n - start local\n https://qiita.com/takeo-furukubo/items/df17ca57203825a45da1\n - Solution view\nstart localで作るとKibanaの見た目がClassicというこれまで通りのものになります。\n下記の記事を参考にObservability Viewにします\nhttps://qiita.com/takeo-furukubo/items/b041b2aff9cf068c21f1\n\n# サンプルデータの準備\n\nまず、Observabilityでよく使われる メトリクス情報 (metrics) と インベントリ情報 (inventory) の2種類のサンプルデータを用意します。\n\n以下のGitHubリポジトリをクローンします\nhttps://github.com/legacyworld/smart_join\n\n## 環境変数\n\n```.env\nES_ENDPOINT=https://your-deployment-id.region.cloud.es.io:443\nES_API_KEY=your_api_key_here\nES_INDEX_METRICS=metrics\nES_INDEX_INVENTORY=inventory\n```\n\nここでENDPOINTとAPI_KEYが必要になります。\n- ENDPOINT\nメニュー左下のデータベースアイコンをクリックして右上の`Connection details`をクリックすると表示されますので、`Elasticsearch endpoint`をコピーします。\n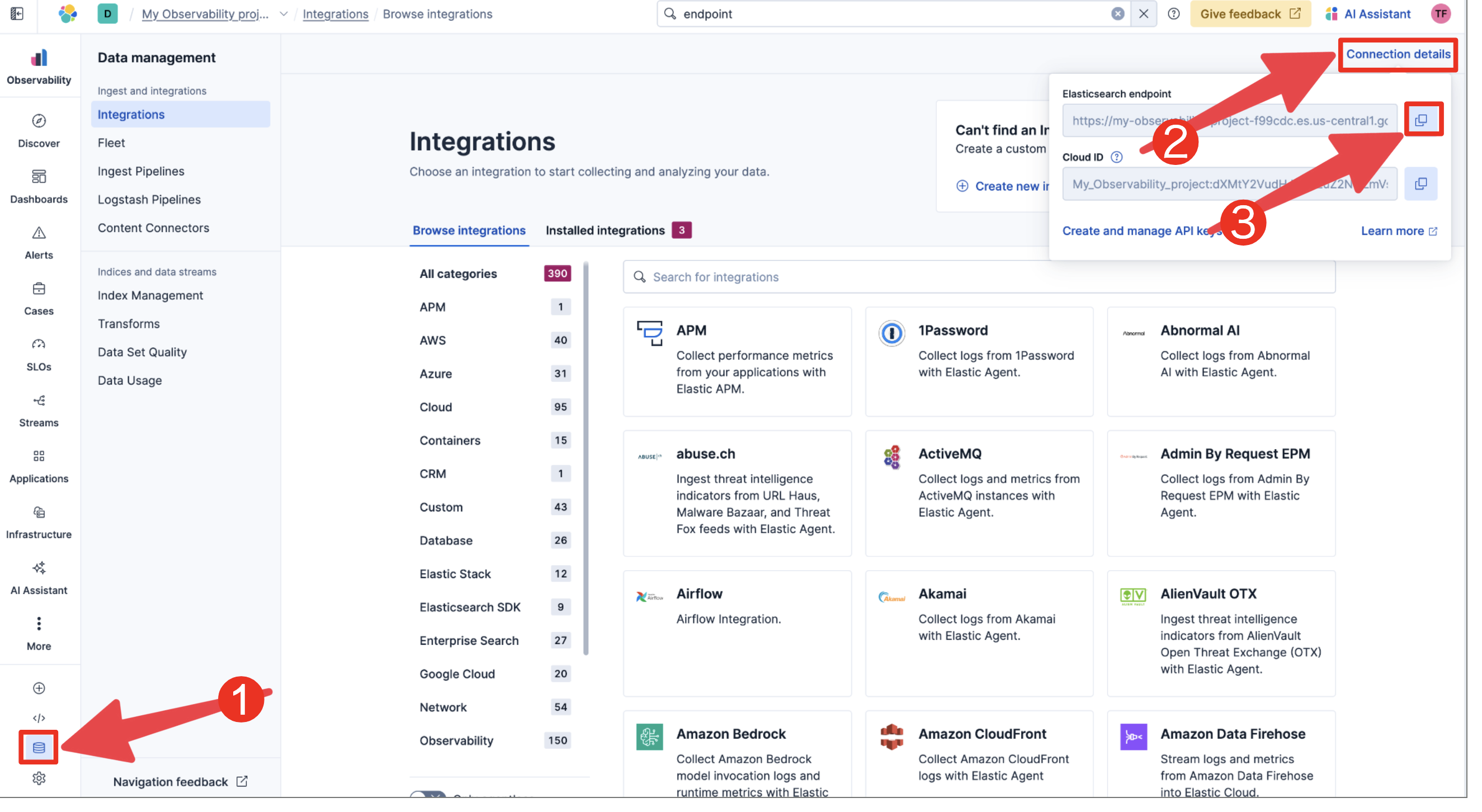\n\n- API KEY\nメニュー左下の歯車をクリックして`API keys`を選び、右上の`Create API key`をクリックすると作成画面が表示されます\n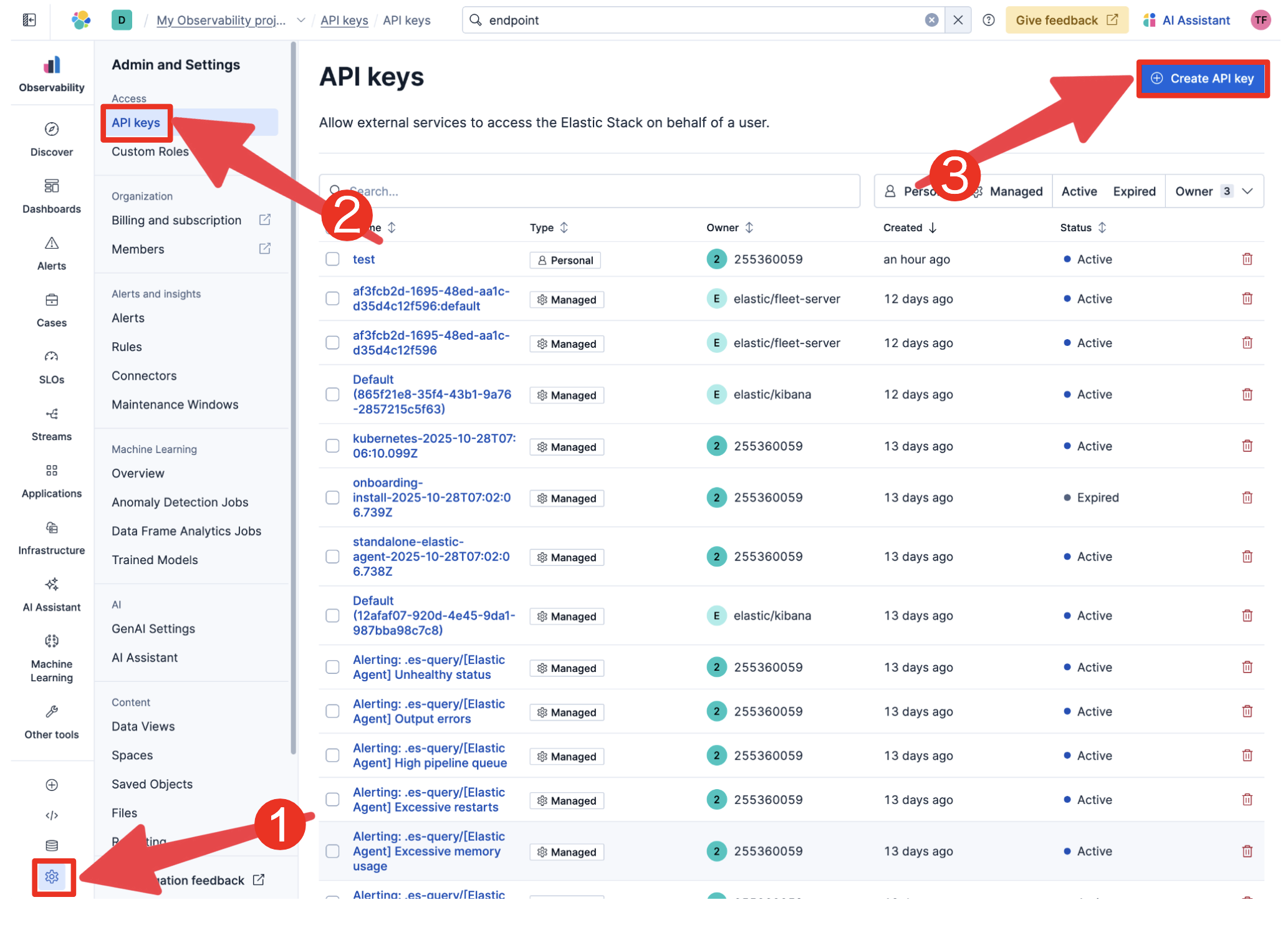\n\n## プログラム実行\n\n### プログラムの中身\nPythonスクリプトでは以下を行います:\n1. .env から接続情報を読み込む\n2. metrics インデックスを存在する場合は削除して再作成\n3. inventory インデックスを LOOKUP JOIN 用に index.mode=lookup で作成\n4. サンプルデータを Elasticsearch に投入\n\n### 実行\ndockerで実行できます。\n\n```\ndocker compose up -d\ndocker exec -it python python create.py\n\n```\n\nstart localなどでElasticをローカルに立てている場合は、Elasticsearchに`localhost:9200`でアクセスできない(コンテナ自身になってしまう)ため、`create.py`をPC上で実行するなどしてください\n\n# ES|QLでJOIN\nDiscoverに行って、右上にある`Try ES|QL`をクリックします。\n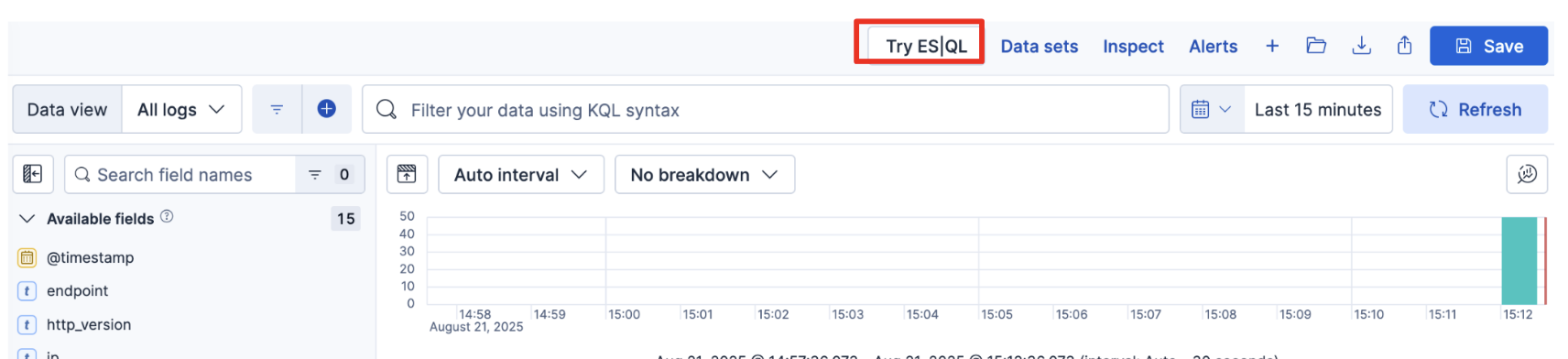\n\n以下のように入れてみます\n\n```\nFROM metrics\n| LOOKUP JOIN inventory ON host.name.keyword, cloud.region.keyword\n| EVAL cpu_pct = system.cpu.usage * 100\n| KEEP host.name, cloud.region, cpu_pct, system.memory.used_pct, hardware.model, hardware.rack\n| SORT cloud.region, cpu_pct DESC\n```\n\n\n\n複数キーで突合できていることがわかります\n\n# まとめ\nv9.0でJOINがリリースされて以来、いろいろご利用いただいていると思います。\n今回はご要望の多かった複数キーでのJOINについて取り上げました。\nこれからもJOIN機能は増えていく予定です。様々な場面でぜひ使ってみてください"
}
データ確認
ではチャンキングの違いを見てみましょう。これをDev Toolsで実行します。
GET test-index-e5/_search
{
"_source": false,
"query": {
"match_all": {}
},
"fields": [
"_inference_fields"
]
}
右側にチャンキングの結果が出ています。
- sentence
最初の段落は621文字あることがわかります(トークン数ではありません)
"fields": {
"_inference_fields": [
{
"description.sentence": {
"inference": {
"inference_id": "e5-sentence",
"model_settings": {
"service": "elasticsearch",
"task_type": "text_embedding",
"dimensions": 384,
"similarity": "cosine",
"element_type": "float"
},
"chunks": {
"description": [
{
"start_offset": 0,
"end_offset": 621, <== 最初の段落の文字数
621文字まではこれです
# はじめに
現代のシステム運用では、メトリクス、ログ、トレース、構成情報など、さまざまなデータソースを組み合わせて分析する オブザーバビリティ が重要になっています。
たとえば「特定のホストでCPU使用率が高い原因はどのリージョンやラックに設置されたどのハードウェアか?」といった問いに答えるには、複数のデータを正確に突き合わせる必要があります。
ElasticsearchのES|QLでは、これまでLOOKUP JOINを使うことで異なるインデックスのデータを結合できましたが、単一キーでの結合しかサポートされていなかったため、同じホスト名が複数リージョンに存在する場合などには誤った結合が発生することがありました。
しかし最新のアップデートにより、複数キーでのLOOKUP JOINがサポートされるようになりました。
これにより、host.name と cloud.region のような複合キーで正確にデータを結合でき、Observabilityデータの分析精度が格段に向上します。
本記事では、この新機能を活用して サンプルデータを作成・Elasticsearchに投入し、複合キーJOINでメトリクスとインベントリ情報を結合する方法 を紹介します。
# Elasticクラスタの作成
start localでPC上に作ってもクラウドでもOKです
Observability Solution Viewを前提にしています
- resursive
最初の段落は534文字あることがわかります
"description.recursive": {
"inference": {
"inference_id": "e5-recursive",
"model_settings": {
"service": "elasticsearch",
"task_type": "text_embedding",
"dimensions": 384,
"similarity": "cosine",
"element_type": "float"
},
"chunks": {
"description": [
{
"start_offset": 0,
"end_offset": 534, <== 最初の段落の文字数
534文字まではこれです。
見てわかるように#Elasticクラスタの作成の前で切れており、Markdownを認識したチャンキングになっています。
# はじめに
現代のシステム運用では、メトリクス、ログ、トレース、構成情報など、さまざまなデータソースを組み合わせて分析する オブザーバビリティ が重要になっています。
たとえば「特定のホストでCPU使用率が高い原因はどのリージョンやラックに設置されたどのハードウェアか?」といった問いに答えるには、複数のデータを正確に突き合わせる必要があります。
ElasticsearchのES|QLでは、これまでLOOKUP JOINを使うことで異なるインデックスのデータを結合できましたが、単一キーでの結合しかサポートされていなかったため、同じホスト名が複数リージョンに存在する場合などには誤った結合が発生することがありました。
しかし最新のアップデートにより、複数キーでのLOOKUP JOINがサポートされるようになりました。
これにより、host.name と cloud.region のような複合キーで正確にデータを結合でき、Observabilityデータの分析精度が格段に向上します。
本記事では、この新機能を活用して サンプルデータを作成・Elasticsearchに投入し、複合キーJOINでメトリクスとインベントリ情報を結合する方法 を紹介します。
検索
では検索してみましょう。正直この程度の文章量ではどちらのほうが良いチャンキングであるというのは無理だと思います。本記事で出しているのもたまたまかも知れません。
- sentenceチャンキングで検索
以下をDev Toolsで実行
GET test-index-e5/_search
{
"_source": false,
"query": {
"semantic": {
"field": "description.sentence",
"query": "サンプルデータの準備方法"
}
},
"highlight": {
"fields": {
"description.sentence": {
"order": "score",
"number_of_fragments": 1
}
}
}
}
結果はこのとおり。残念ながらヒットしていません。
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9236208,
"hits": [
{
"_index": "test-index-e5",
"_id": "Uyo86JoB893ps80kzJNF",
"_score": 0.9236208,
"highlight": {
"description.sentence": [
"""
- API KEY
メニュー左下の歯車をクリックして`API keys`を選び、右上の`Create API key`をクリックすると作成画面が表示されます

...
- recursive
以下をDev Toolsで実行
GET test-index-e5/_search
{
"_source": false,
"query": {
"semantic": {
"field": "description.recursive",
"query": "サンプルデータの準備方法"
}
},
"highlight": {
"fields": {
"description.recursive": {
"order": "score",
"number_of_fragments": 1
}
}
}
}
結果はこれ。正しくもってきています。
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.92693686,
"hits": [
{
"_index": "test-index-e5",
"_id": "Uyo86JoB893ps80kzJNF",
"_score": 0.92693686,
"highlight": {
"description.recursive": [
"""
# Elasticクラスタの作成
start localでPC上に作ってもクラウドでもOKです
Observability Solution Viewを前提にしています
- クラウド
https://cloud.elastic.co/registration
HostedとServerlessがありますが、Serverlessは東京リージョンはまだAWSにしかありませんので、今回はhostedをベースに話を進めます
作成する際にObservabilityを選ぶと今回の用途には何かと便利です。
このキャプチャだと真ん中です。

- ローカル
- start local
https://qiita.com/takeo-furukubo/items/df17ca57203825a45da1
- Solution view
start localで作るとKibanaの見た目がClassicというこれまで通りのものになります。
下記の記事を参考にObservability Viewにします
https://qiita.com/takeo-furukubo/items/b041b2aff9cf068c21f1
# サンプルデータの準備
まず、Observabilityでよく使われる メトリクス情報 (metrics) と インベントリ情報 (inventory) の2種類のサンプルデータを用意します。
...
まとめ
Elastic Inference API に新しく追加された recursive チャンキングは、従来の sentence モードでは難しかった「文書構造を理解した分割」を可能にする強力な機能でした。特に Markdown や段落構造を持つテキストでは、文単位よりも自然で意味のまとまりを保ったチャンクが生成されています。
Tech Preview 機能ではありますが、 semantic_text を組み合わせることで、より構造に強い RAG やドキュメント検索を手軽に実現できます。
ぜひ sentence モードと recursive モードを用途に応じて使い分け、最適な文書検索体験を構築してみてください。