はじめに
2019年4月26日に「Forecasting Climatic Trends Using Neural Networks: An Experimental Study Using Global Historical Data」という論文が発表されました。京大がプレスリリースを出すほどの素晴らしい論文かと思いきや、色々と問題が指摘されていますので、実際に追試をしてみました。
論文:
https://www.frontiersin.org/articles/10.3389/frobt.2019.00032/full
京大のプレスリリース:
http://www.kyoto-u.ac.jp/ja/research/research_results/2019/190426_1.html
この論文で述べられている実験には、以下のような問題があります。
- 論文に記述されていないことが多く同じ条件での再実験は困難。
- 学習データと検証データの分け方に問題があるため、論文中の性能評価が正しいとは思えない。
キツめの評価となっていますが、情報処理学会や電子情報通信学会の論文誌ならrejectになるよね1、という程度であって、このような論文は世の中にたくさんあります2 3。
論文の内容
論文のタイトルは「ニューラルネットワークを使った気候変動の予測」となっていますが、実際は「ある場所における将来10年間の気温の平均気温の上昇or下降を予測」という内容になっています4。提案されている手法は、過去に観測された気温データから2次元の画像データを作成し、作成した画像をCNN(畳み込みニューラルネットワーク)を使って分類することで、将来の気温の上昇or下降を予測するというものです。
追試
この追試に使った実装をgithubで公開しています(pytorchを使っています)。
https://github.com/takedarts/DLofClimaticTrends
実装にあたり、k-haradaさんのプログラムを参考にさせてもらいました。この論文の問題点についてLightGBMを使って検証されています。
https://github.com/k-harada/ML_climate
実装
追試を行うために論文を読んでみたのですが、いくつかの重要な手法やパラメータが説明されていませんでした。そのため、同じ条件では実験できていないと思います。
この論文では、画像認識用のCNNとしてLeNetを使っています。しかし、一言でLeNetといっても、色々な実装があるのですが、どの実装を使ったのかは論文中に書かれていません。そこで、適当にLeNetらしきCNNを実装しました。
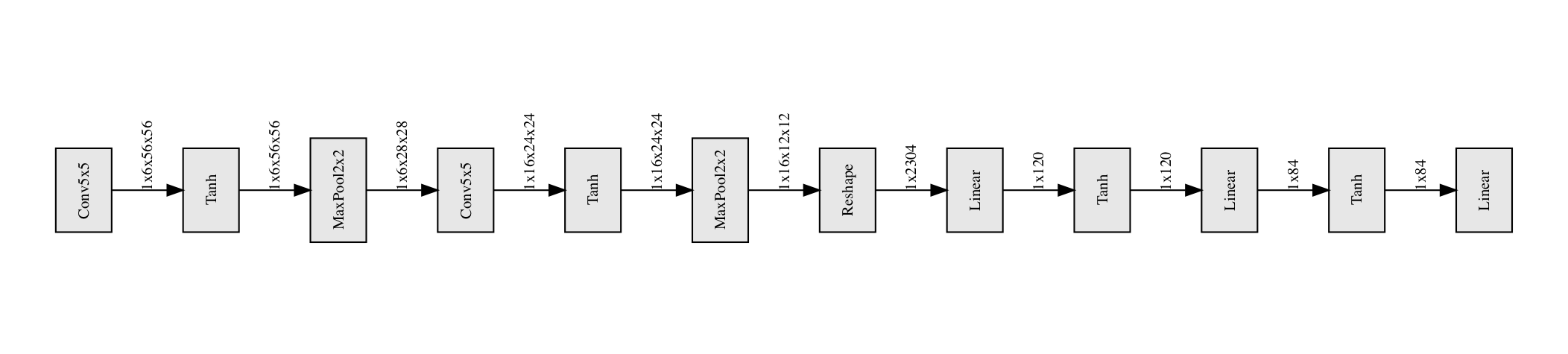
LeNetは簡潔なグラフで表現できるところがいいですね5。
学習時のパラメータ更新はStochastic Gradient Descent (SGD)で行うようですが、基本学習係数が0.01と書いてあるだけで6、モーメンタム7や正則化係数などは書かれていません。また、学習係数を減らしていく、という趣旨のことが記述されていますが、どのように減らすのかも書かれていません。さらにバッチサイズも書かれていません。よって、このあたりのパラメータも適当に想像で決めました。
あとは、入力データの作成です。論文中でも使われていたデータセット「CRU TS 4.01」は公開されていましたので、1901年から2016年の気温データをダウンロードしました。そして、入力データとラベルを作成するのですが、ラベルの作成方法が論文中に書かれていません。「将来10年の平均気温が上がるor下がる」がラベルとなるのですが、「どの値と比較して上がるor下がる」とするのかが分かりません。仕方ないので、過去30年の平均気温との比較で「上がるor下がる」というラベルを作成することにしました。
入力画像については、30年×12ヶ月のデータを60×60ピクセルの画像に変換するようですが、もちろん変換方法は一部しか書かれていません。ただ、論文中の図を見ると、30×12の画像データを作成して、それをnearestアルゴリズムでupsampleしたように見えますので、そのようにしました。
また、入力画像に色をつけるのですが、論文中には「heat.colors」と書かれています。これは、どうもRのカラーパレットのようなのですが、Rの実装を見る気力がなかったので、これも手探りで作成してみました。作成した画像は以下の通り。
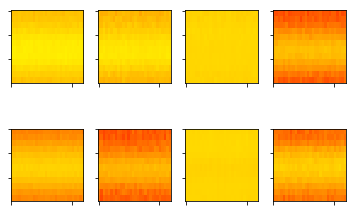
それっぽいものが出来ました。
この色つけしているプログラムはこちら。
# img: グレースケール画像 -> カラー画像
r = numpy.ones_like(img)
g = img
b = numpy.zeros_like(img)
img = numpy.stack([r, g, b], axis=0)
私としては、完全に無駄なコードを書いた気がしています。
最後に、学習データと検証データの分割方法ですが、次の2通りで行いました。
データ分割1
1901-2016年のデータから519,718個のデータをランダムに選ぶ。その後、選んだデータの75%を学習データとし、25%を検証データとする。
データ分割2
1901-1981年のデータから194,894個の気温上昇データと同数の気温下降データをランダムに選び、これを学習データとする。また、1952-2016年のデータ8 9から64,964個の気温上昇データと同数の気温下降データをランダムに選び、これを検証データとする。
データ分割1は論文中に書かれている分割方法ですが、これは時系列データを扱う場合は問題のあるデータ分割方法です。ほぼ同じ時刻・同じ場所のデータが学習データと検証データの両方に含まれている可能性があるため、分類精度を正しく評価できない可能性があります10。
そこで、データ分割2では、1931-1981年をラベルとするデータを学習データとし、1982-2016年をラベルとするデータを検証データとしました(1981年以前のデータを使って1982年以降を予測しようとしています)。また、1982年以降は気温上昇データが多数(95%以上)を占めていたので、気温上昇データと気温下降データが同数となるよう調整しました。
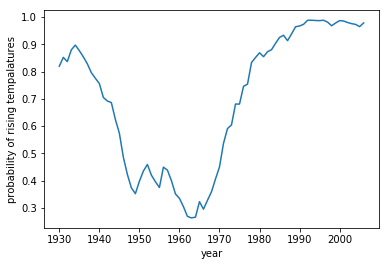
ちなみに、気温上昇データの割合をグラフにするとこんな感じになります。このデータからは温暖化が進んでいるように見えますね。
追試結果 - データ分割1(論文と同じ)
論文と同じ条件で学習を30エポック行いました。
学習: 誤差(loss)=0.2884, 精度(accuracy)=0.8762
検証: 誤差(loss)=0.2907, 精度(accuracy)=0.8749
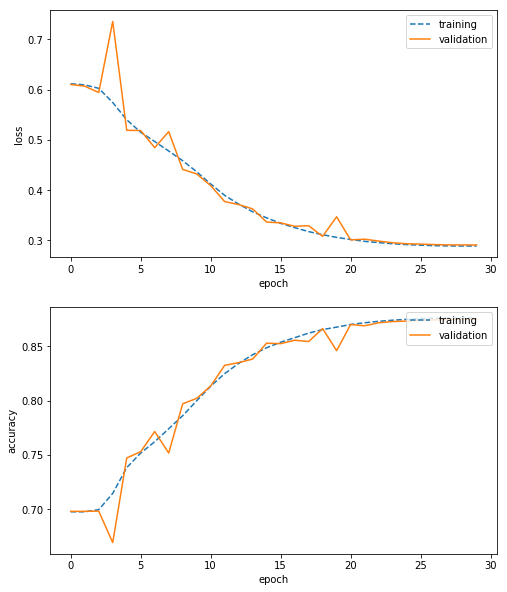
論文中の評価結果では「精度97%」ということでしたが、その精度にはまったく届かない状態でした。もっとも、論文とは実装もパラメータも異なるでしょうから、これらの結果の違いをもって何かの結論を出すことは出来ないかと思います。
ちなみに、この追試の結果ですが、機械学習をやっている人だと「データの作成方法を間違えたかな?」と疑う結果です。この結果は理想的すぎる。
この追試のプログラムコード:
https://nbviewer.jupyter.org/github/takedarts/DLofClimaticTrends/blob/master/ForecastingClimatic_original.ipynb
追試結果 - データ分割2 (時系列を考えて分割)
時系列を考えて学習データと検証データを分割した場合、学習を30エポック行った結果はこのようになりました。
学習: 誤差(loss)=0.3015, 精度(accuracy)=0.8649
検証: 誤差(loss)=0.8963, 精度(accuracy)=0.6464
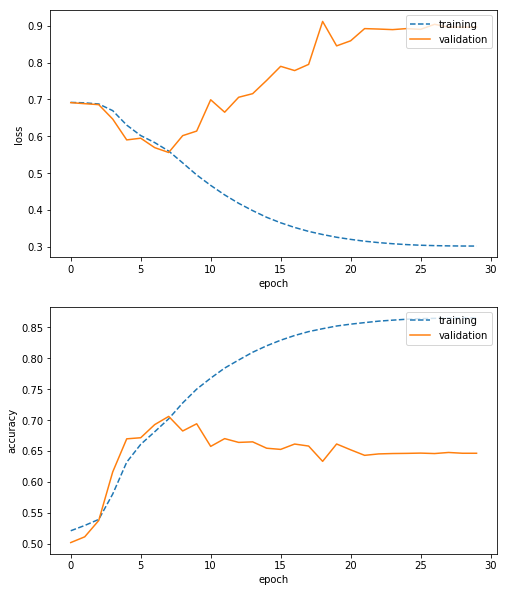
教科書に出てきそうな過学習となりました。ここでは、気温上昇データと気温下降データを同数にしているので、何も学習できていないと精度は50%となります。それよりは高い精度となっているので何かを学習しているようではあります。
ちなみに、1962-2016年のデータから129,929個のデータをランダムに選び、これをテストデータとした場合、テストデータに対する精度は以下の通りになりました。
テスト: 誤差(loss)=0.7757, 精度(accuracy)=0.7111
予測精度は71%となりました。ただし、全体の95%以上が気温上昇データですので、上昇と答えるだけで精度95%以上となります。
追記(2019/05/11):
「テストデータ全体の95%以上が気温上昇データ」という意味です。データセット全体ですと約70%が気温上昇データとなります(紛らわしい書き方をしてしまい申し訳ないです)。
この追試のプログラムコード:
https://nbviewer.jupyter.org/github/takedarts/DLofClimaticTrends/blob/master/ForecastingClimatic_validation.ipynb
追試結果 - データ分割1でPyramidNetを使ってみる
せっかくなのでPyramidNetを試してみました。ただし、画像のカラー化やupsamplingはあまり意味がないように思えるので外しました。
学習: 誤差(loss)=0.0607, 精度(accuracy)=0.9762
検証: 誤差(loss)=0.0982, 精度(accuracy)=0.9628
精度96%までいきました(あんまり意味ないけど)。
この追試のプログラムコード:
https://nbviewer.jupyter.org/github/takedarts/DLofClimaticTrends/blob/master/ForecastingClimatic_resnet_original.ipynb
追試結果 - データ分割2でPyramidNetを使ってみる
ついでに、時系列を考慮したデータ分割方法に対してもPyramidNetを使ってみました。こちらも、画像のカラー化やupsamplingを外しています。
学習: 誤差(loss)=0.0539, 精度(accuracy)=0.9789
検証: 誤差(loss)=2.1140, 精度(accuracy)=0.5538
テスト: 誤差(loss)=1.4204, 精度(accuracy)=0.6401
LeNetよりも酷い結果となりました(予想通りですが)。
この追試のプログラムコード:
https://nbviewer.jupyter.org/github/takedarts/DLofClimaticTrends/blob/master/ForecastingClimatic_resnet_validation.ipynb
おわりに
論文「Forecasting Climatic Trends Using Neural Networks: An Experimental Study Using Global Historical Data」の追試を行ってみました。ただ、論文中に記述されていないパラメータが多く、同じ条件で試験を行えたとは思っていません。そのため、この結果をもって、「上記の論文は間違っている」と主張するものではありません。ただし、この論文にはデータ分割方式などの多くの疑問点が残っています。
個人的には、「気温データを画像データにしてCNNで解析する」という方法は筋が悪いように思えます。このタスクであれば、他の機械学習の手法(boostingなど) の方がよい結果を得られるのではないでしょうか。
ちなみに、現在、Kaggleで音声分類のコンペティション(2019年6月10日まで)が開催されています。このタスクの場合、音声データを画像データに変換してからCNNで分類する手法がよいと知られています11。基本的なkernelも公開されていますので、のぞいてみてはいかがでしょうか。
https://www.kaggle.com/c/freesound-audio-tagging-2019/
-
他の分野の先生には驚かれることがあるのですが、情報処理学会や電子情報通信学会の日本語論文誌は、一部の国際論文誌よりも査読が厳しかったりします(採録されると業績として評価されます)。もし、rejectになったとしても、査読担当の先生方が有用なコメントを書いてくれると思います。この分野の研究をされている方々からの投稿を(編集委員の先生方が)お待ちしております。 ↩
-
私も酷い論文を書いて投稿した経験があります。もちろん、rejectとなりました。 ↩
-
情報以外の分野を専門とする先生が書かれた論文ですので、実験や評価に関する部分の質が低いのは理解できます。また、質の低い論文であったとしても、投稿や発表には問題ありません(採録を決めたのは論文誌の編集委員ですし、価値を決めるのは読者です)。ただ、個人的には、京大のプレスリリースはやりすぎかなと思います。 ↩
-
タイトルが大げさすぎるようにも感じます。 ↩
-
最近のCNNは複雑すぎるので、グラフにしても意味がないですね(グラフが巨大すぎて読み取れない)。 ↩
-
基本学習係数(Base learning rate)って何? ↩
-
モーメンタムを使わないSGDであればモーメンタムの設定値は必要ありません。ただ、最近の研究では、CNNに対してモーメンタム無しのSGDを使うことは稀ですので、もし使っていないとしても、モーメンタムについての説明が必要だったかなと思います(「SGDでパラメータを更新しました。Momentumは0.9です。」なんて書いてある論文も結構あります)。 ↩
-
1982年以降の気温予測を検証タスクとしたいので、その直前30年分を入力データとして検証データに含めています。 ↩
-
検証データの範囲の説明が間違っていたので修正しました(githubのプログラムはあっています)。(2019/05/09) ↩
-
この評価方法では、過学習状態(学習データを記憶しているだけで、未知のデータには対応出来ない状態)となったとしても、予測精度が高く評価される可能性があります(実際そうなった)。 ↩
-
論文( https://arxiv.org/abs/1605.09507 )も発表されています。 ↩