scrapy 1.4.0
サンプルコード
class HogeSpider(scrapy.Spider):
name: str = 'hoge'
start_urls: List[str] = ['https://data-ippai.com/']
def parse(self, response):
for li in response.xpath('li-no-xpath'):
url = li.xpath('anchor-no-link').extract_first()
yield Request(
url=url,
callbacl=self.parse_detail,
)
def parse_detail(self, response):
loader = HogeItemLoader(
response=response,
selector=response.body,
)
return loader.load_item()
この記事の目的
例えばSpiderクラスは概ね上記サンプルコードの感じで書いていくと思いますが、
Spider の挙動が思っていた動作と違ったり、
クロール対象サイト側に問題があるのか、Spiderに問題があるのか、
切り分けが難しいシチュエーションに多々出会ったため、
scrapy について理解を深める・備忘録目的でこの記事を残します。
scrapy のアーキテクチャ
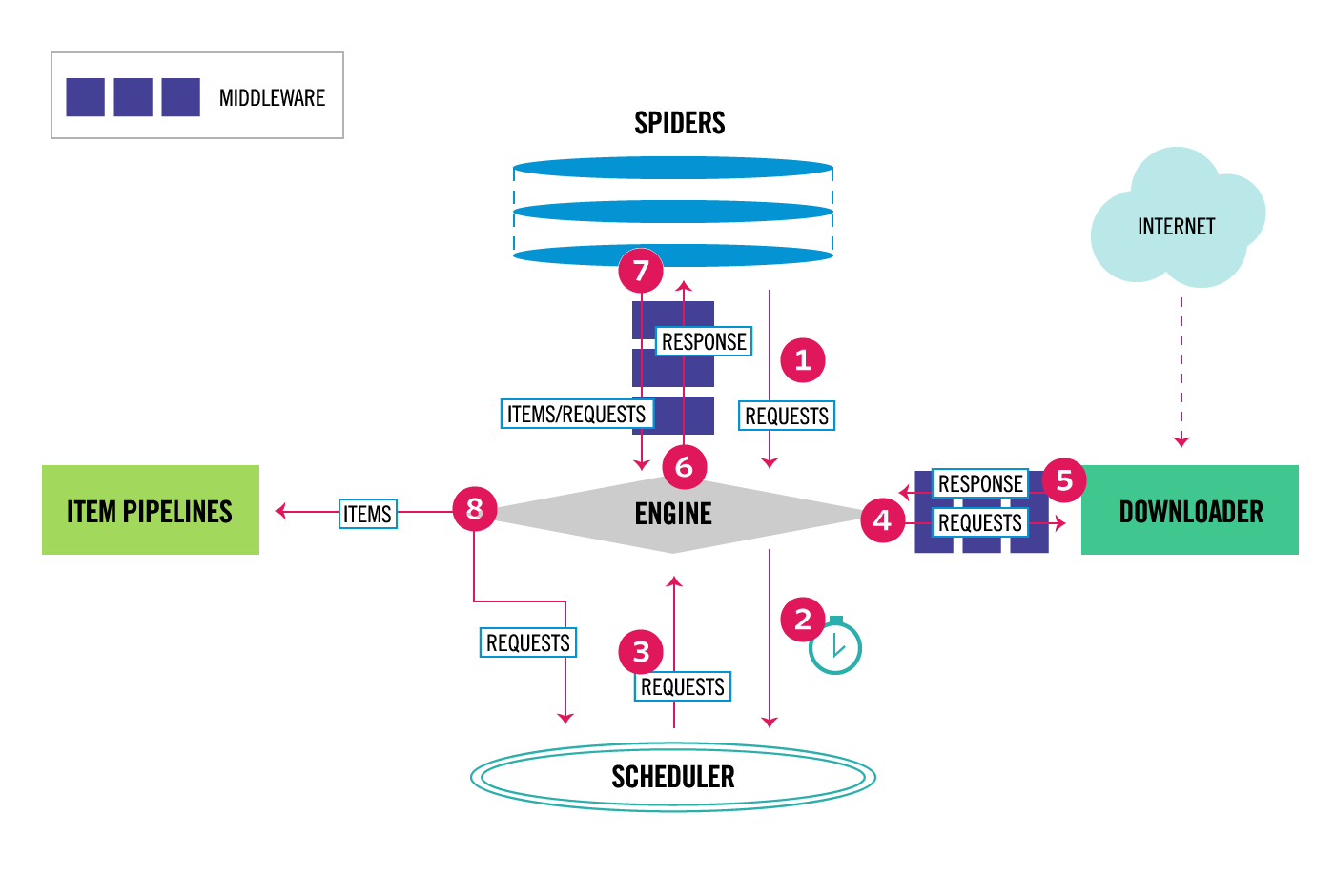
公式にある画像ですがこの図を見ても全然理解できず。
Requestオブジェクトをジェネレート又はreturn をしたときにscrapy 側で何が起きているのか
サンプルコードでいうと以下の箇所のお話です。図でいうと2のお話。
yield Request(
url=url,
callbacl=self.parse_detail,
)
ここは yield でも return でも良いのですか、Requestオブジェクトを spider クラスに返すことにより、
スケジューラー に登録されます。
じゃあこの スケジューラー って何?って話なんですが、 タスクキュー みたいな仕組みだと思ってだいたい間違いないです。
scrapy では queuelib というライブラリを使用して、
Requestオブジェクトをシリアライズしてファイルに突っ込んでいます。(キューイングしている)
突っ込まれたRequestオブジェクトは一つずつ取り出され、リクエストの間隔時間を計算してリクエストしています。
その結果 callback で指定したメソッドが実行される仕組みです。
余談ですが、Spider で指定したコールバックメソッド内の yield, return では Request オブジェクト 又は scrapy.Item オブジェクト のみ受け付けます。
Request オブジェクト を渡すと スケジューラー に登録され、
scrapy.Item オブジェクト を渡すと ItemPipeline に処理が移ります。図の7と8のお話です。
(サンプルコード内の def parse もscrapy が内部で呼んでいるコールバックメソッドです。)
Requestオブジェクトはいつリクエストされているのか。
上記でも少し触れていますがスケジューラーからRequestクラスが取り出されたときです。図の3, 4 あたりのお話。
スケジューラからRequestクラスが取り出される間隔は概ね設定値 DOWNLOAD_DELAY で指定した秒数です。
(正確には DOWNLOAD_DELAY を元にディレイする秒数をscrapy 側で計算している)
ターミナルに出力しているリクエストログを見ると順番どおりにリクエストしてないな。
図の4あたりのお話です。
scrapy のキューの取り出し順序どうなってんだろと調べた所 (公式)[https://doc.scrapy.org/en/latest/faq.html#does-scrapy-crawl-in-breadth-first-or-depth-first-order] に記載がありました。
デフォルトだと 後入れ先出し で処理されるらしい。
つまり順番どおりにリクエストされるはずですがそれが確認できず、よく分かりませんでした。
キューに優先順序をつけられる
図の7, 8, 3のあたりのお話です。
Requestクラスに priority をつけることができる。
この値が高いキューが優先的に処理される。
負の値を指定することも可能。
スクレイピング時に正常にクローリングできてるはずなのに出来てない問題が発生した
階段上ったはずのに登ってなかった問題がありあれれー?となりました。図の7, 4, 5あたりのお話です。
結論から言うと、 ミドルウェアの DupeFilter に引っかかり、scrapy がリクエストするのを諦めていました。
この DupeFilter って何?って話なんですが、
scrapy が url を元に、既に同じリクエストをしたことがあるかどうかを判定し、
同じリクエストの場合、以降の処理を行わないというものです。
この問題の解決策として、Requestクラスの引数に dont_filter=True 入れると同じURLでも正常にクロールしてくれます。
最後に
最近サボってしまいましたが、本日の Friday I/O でした。
株式会社ワムウでは、毎週金曜日は 興味がある事柄に取り組み、その成果を何らかの形でアウトプットする日としています。ありがとうございました。