はじめに
はじめにこの記事に関しての動機をメモしておくと、「とりあえず、簡易的な実装含め記事を残しておけば興味持って取り組んでる人が出てきてくれるかな?」というのを少しばかり期待しているのと、「Houdini上で機械学習のプロセスを通したI/O処理を整理していく上で、基礎のところをまとめておこう」ということがある。
今回の優先順目的は2つある。Houdini上のCOP Netoworkプロセス(画像合成処理操作ネットワーク、 Composite OPeration Network)で処理した画像を機械学習プロセスを通し、出力した結果を利用してSOP Netowrk(ジオメトリ操作ネットワーク、 Surface OPeration Network)に対して影響させるというI/O処理を実装する事。この方法をもとに、様々な実験・実装を重ねていくための一歩として残しておくことにある。次に、Houdini上でTensorFlowを動かすにはといったことや、Python Digital Assetなどを作成して実装していく方法などをまとめていく。
以下は、以上の目的項目を実装のプロセス上でミックスしながら試していく。なので、概要を掴みたい場合は目次を参照とのこと。
#Houdini で機械学習 with #TensorFlow | ノートまとめました〜😆https://t.co/s86VERRifU…#HFXJP #machinelearning pic.twitter.com/YNAPuNZihg
— Takanori.K (@auratus) 2017年12月14日
実行環境
OS: Linux_x64 Ubuntu 16.04
Houdini Version: Houdini 16.5.268
TensorFlow Version: v1.4.0
Houdiniとはとは
機械学習の方をキーワードにここにやってきた人のために簡単な紹介をば。

Houdiniは、主に、映像やゲームなどのコンテンツに使用されるDCC(Digital Contents Creation)ツールの一つ。
ノードベースというGUIを特徴にもち、一個一個の処理をノード単位で処理出来る機構をもっている。
このノード単体は、各自開発して作成する事が可能で、今回はこれを利用して、単一ノードを作成し、画像のインプットから推論処理、結果を接続されているジオメトリを扱うノードに影響させる。ということをやっていく。
ツールに関して詳しくは公式ページを参照
無料で試せるツールなので、是非インスールして触ってみてください!!
TensorFlowとはとは
今度は逆に、Houdini関連からやってきた人のために簡単な紹介をば。

TensorFlowはGoogleがメインで開発している機械学習向けライブラリで、GitHubのスター数を見ても分かる通り今や超人気ライブラリ。なので知見が速攻で溜まっていくので情報を探しやすい上、サポートプラットフォームがどんどん豊富になってきているので、とりあえず使い方覚えておけば様々なところで応用が効きそうというのがある。
ただ、内部の方でどう処理しているかなどは詳しいところまで見に行けないため、Chainerなどの他のライブラリと比べて、現在はあまり機械学習研究向けとは言えない。
今回は人気ライブラリという事や、環境構築が楽、コード量も抑えられるということから、TensorFlowを使って、機械学習プロセスを実装する基礎の一部をまとめてみたという感じ。
環境構築
1. Houdiniの設定
以下を参照
2. TensorFlowのインストール
まず、前準備。ココらへんの環境は色々やりようがあるので、各個人の調査と趣向次第にお任せするが、とりあえず、構成と手段の両面で超シンプルプランでまとめていく。
2-1. virtualenv(仮想環境)の準備
pipを使ってインストールする。
Python2.7.9以上のバージョンであればpipはデフォルトで入っているが、入ってない場合には次を参照。
Installation — pip 9.0.1 documentation
UNIX系でさくっとやるなら、次でもok
curl -kL https://bootstrap.pypa.io/get-pip.py | python
Virtualenvをインストール
sudo pip install virtualenv
既にインストールされてる場合は、
sudo pip upgrade virtualenv
2-2. Virtualenvの作成
mkdir .virtualenv; cd .virtualenv
virtualenv python=python2.7 tensorflow
※ Houdiniは、まだ2.7.x系じゃないと動かないので、Python2.7環境を用意しておく。
2-3. Virtualenv環境に入る(アクティベートする)
source .virtualenv/tensorflow/bin/activate
2-4. Virtualenv環境に入っことを確認。
Terminal上で以下の表示で待機されてればOK
(tensorflow)takanori$
2-5. TensorFlowのインストール
pip install tensorflow
これでCPU処理での実行環境は終了。
GPU処理が望まれる場合もあるが、その場合は環境に応じて準備をする。
環境構築はやっかいな手順があるが、僕の環境の場合は、とりあえずドキュメント通りに進めれば上手く行った。
2-6. とりあえずモジュールのインポートまでテスト
ターミナルでpythonを起動
python
Pythonのインタプリタで次を実行
import tensorflow
何もエラーが出なければとりあえず成功
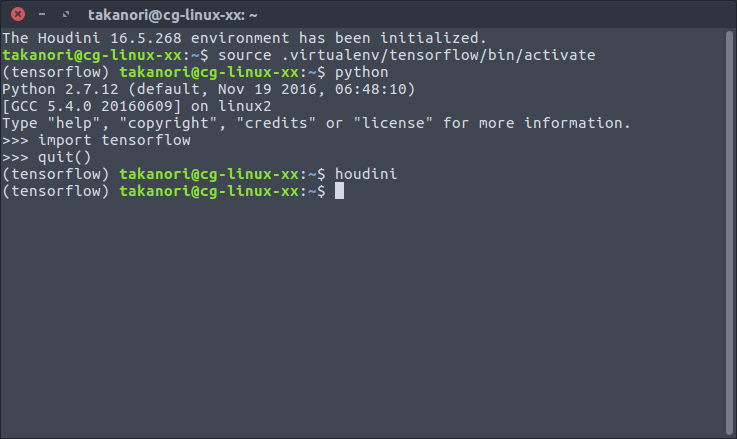
TensorFlowのインストール環境でHoudiniの立ち上げ
2.の手順を踏んだ上で、TensorFlowの仮想環境に入ってる状態を確認しつつ、houdiniコマンドで立ち上げる。
MNISTの学習結果を利用してHoudiniのジオメトリを操作してみる
MNISTの機械学習といえば、機械学習の世界の"Hellow, World!"みたいなもので、知ってる方も多い。
まずは、(実用かどうかはともかく)よりI/Oをどうすべきかを理解するために、このよりシンプルなサンプルを利用して手法を明確にさせていきたい。
Houdiniで使う上で、チュートリアルのものからは少し書き換えが必要になるのだが、
はじめに、いくつか書き換えポイントを列挙しておくと、
- 学習済みパラメーターの保存
- Houdini COP(Composite OPeration) -> Python Digital Asset -> TensorFlowのデータ受け渡し
- 学習済みパラメーターの読み込み
- 出力結果を(Geometry)Detail Attributeに移し、次のプロセスで使用
というのに注意していただきたい。
1. 学習モデルと学習済みパラメーターの用意
Houdini上で多層のニューラルネットで学習させるには、待ち時間が長すぎる上、とても非効率。なので、学習済みパラメーターを作成して、それを展開させることで速度の向上を図る。
1-1. MNISTで学習済みパラメーターを保存
まずHoudiniの上で軽快に動かすために、学習モデルを使ってパラメーターの保存を行う。
以下は多層ニューラルネットを使ったCNN(Convolutional Neural Network)モデル。なんかCPUで回すと重いやつ。
この内容に関しては、TensorFlowのチュートリアルや数多の人らによって詳しい解説がなされているので、とりあえずこういうものだよということで解説はスキップ。
注:ちゃんと理解しようと思ったら数学の知識が要ります。
import os
import tensorflow as tf
# Multilayer Convolutional Network
def convolutional(x, keep_prob):
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def weight_variable(shape, name=None):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name=name)
def bias_variable(shape, name):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name=name)
# First Convolutional Layer
x_image = tf.reshape(x, [-1, 28, 28, 1])
W_conv1 = weight_variable([5, 5, 1, 32], name='W_conv1')
b_conv1 = bias_variable([32], name='b_conv1')
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# Second Convolutional Layer
W_conv2 = weight_variable([5, 5, 32, 64], name='W_conv2')
b_conv2 = bias_variable([64], name='b_conv2')
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# Densely Connected Layer
W_fc1 = weight_variable([7 * 7 * 64, 1024], name='W_fc1')
b_fc1 = bias_variable([1024], name='b_fc1')
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Dropout
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# Readout Layer
W_fc2 = weight_variable([1024, 10], name='W_fc2')
b_fc2 = bias_variable([10], name='b_fc2')
y = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
return y, [W_conv1, b_conv1, W_conv2, b_conv2, W_fc1, b_fc1, W_fc2, b_fc2]
def train():
from tensorflow.examples.tutorials.mnist import input_data
data = input_data.read_data_sets("/tmp/data/", one_hot=True)
# model
# with tf.variable_scope("convolutional"):
x = tf.placeholder(tf.float32, [None, 784])
keep_prob = tf.placeholder(tf.float32)
y, variables = convolutional(x, keep_prob)
# train
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print('variables :: '), variables
saver = tf.train.Saver(variables)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = data.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g" % (i, train_accuracy))
sess.run(train_step, feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print(sess.run(accuracy, feed_dict={x: data.test.images, y_: data.test.labels, keep_prob: 1.0}))
path = saver.save(
sess, os.path.join(os.path.dirname(__file__), 'data', 'convolutional.ckpt'),
write_meta_graph=False, write_state=False)
print("Saved:", path)
if __name__ == '__main__':
train()
このファイルをHoudiniがデフォルトアクセス可能な場所( HOUDINI_PATH や HOUDINI_USER_PREF_DIR の環境変数が通っているパス)に配置する。
次の例は、 houdini16.5 まで HOUDINI_USER_PREF_DIR が通っており、Houdiniが起動時に自動で python2.7libs の中にパスを通してくれる。
例) /home/takanori/houdini16.5/python2.7libs/mnist.py
そして、このファイルをTerminalで実行する。
python model.py
すると学習処理が始まり、同じ階層に data/convolutional.ckpt.index と data/convolutional.ckpt.data-00000-of-00001 が作られる。 **-data-**と付いているものが、TensorFlowの学習済みパラメーターを保存したCheckpointファイルの一部。
と、全て解説をスキップしようと思ったけれども一点だけ。
1-1-1. 解説1
train関数の中で、 saver = train.Saver(variables) と saver.save(....) が使われているが、ここがTensorFlowのCheckpointファイルを作っているところ。
saver = tf.train.Saver(variables) で、保存するvariablesを明示的に指定しつつ、tf.train.Saver() オブジェクトを生成している。
そして、 saver.save() で tf.train.Saver() がもつsaveメソッドを使用して保存行為を行っている。
2. COPで画像を処理
画像をHoudiniに読み込む前に処理してしまってもいいが、Houdiniは一応コンポジットとかもできるCOP Networkがあるので、これでプロシージャル管理が出来る利点を活かして画像の加工を行ってみる。
下記画像で組んでるネットワークの目的はシンプルで、「スイッチでInputを切り替えれる」というのを行っているのと、Scale COPで処理に送る用の適切なピクセルスケール(今回は28x28)に縮めている。
動作を検証するため、適当にMNISTに使われていると思われる画像をネットから拾ってきて使用。 test9_png というものはネットからだが手書きで書かれたものを拾ってきて用意。 san_png と nana_png は、GIMPを使って自分で書いたものを読み込んでいる。
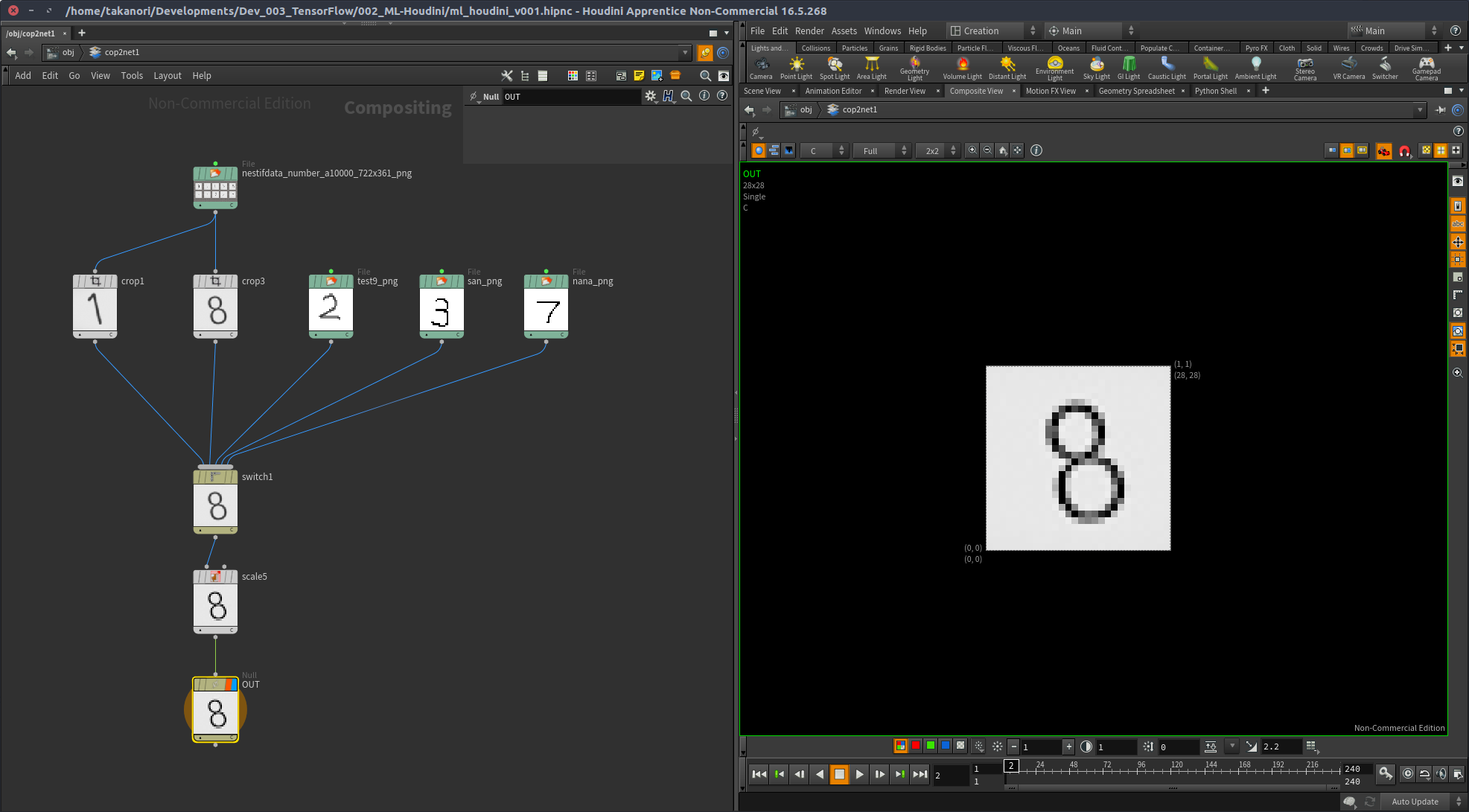
3. Python Digital Asset
3-1. Python Digital Assetの作成
Python SOPとかで書いてもいいのだが、まぁ、「機械学習ノード」を作るって名目でPython Digital Assetの方を選択した。
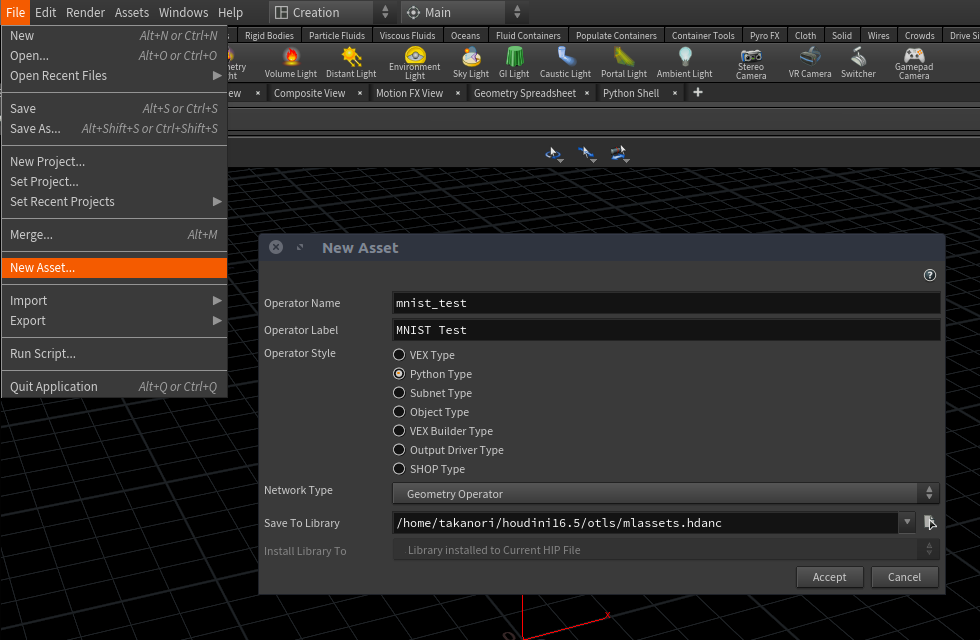
アイコンとかも適当に当ててみた。SVGファイル製(ネットから落としてきたものをInkscapeでちょっとイジイジ)。
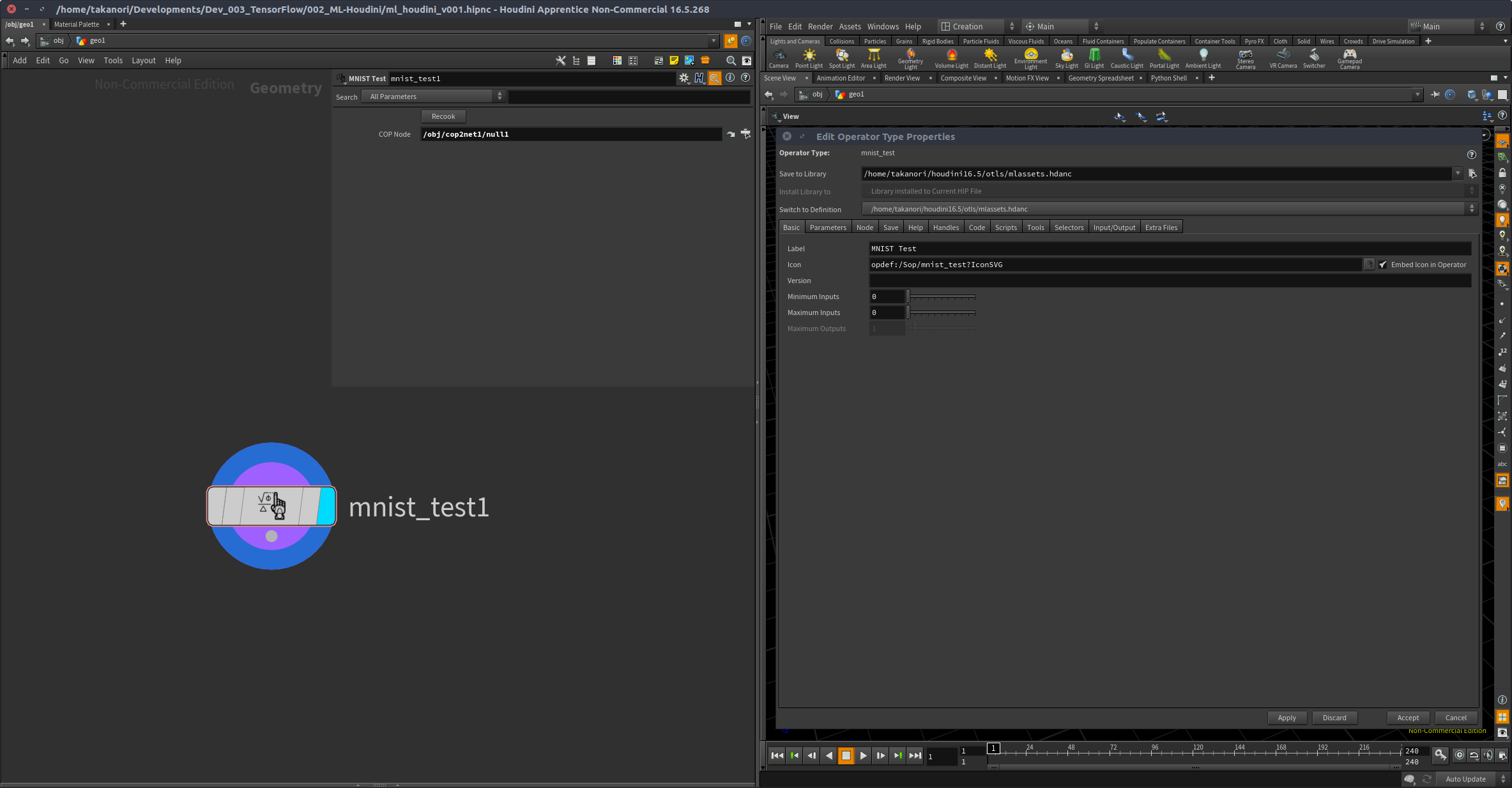
3-2. ノードのパラメーターを作る
今回は、COP側で受け取って、ノード内で処理するだけなので、シンプルに。
ただ、COP側から処理を受け取るのに、Recookが必要という縛りがあり、Recookボタンは付けておく。
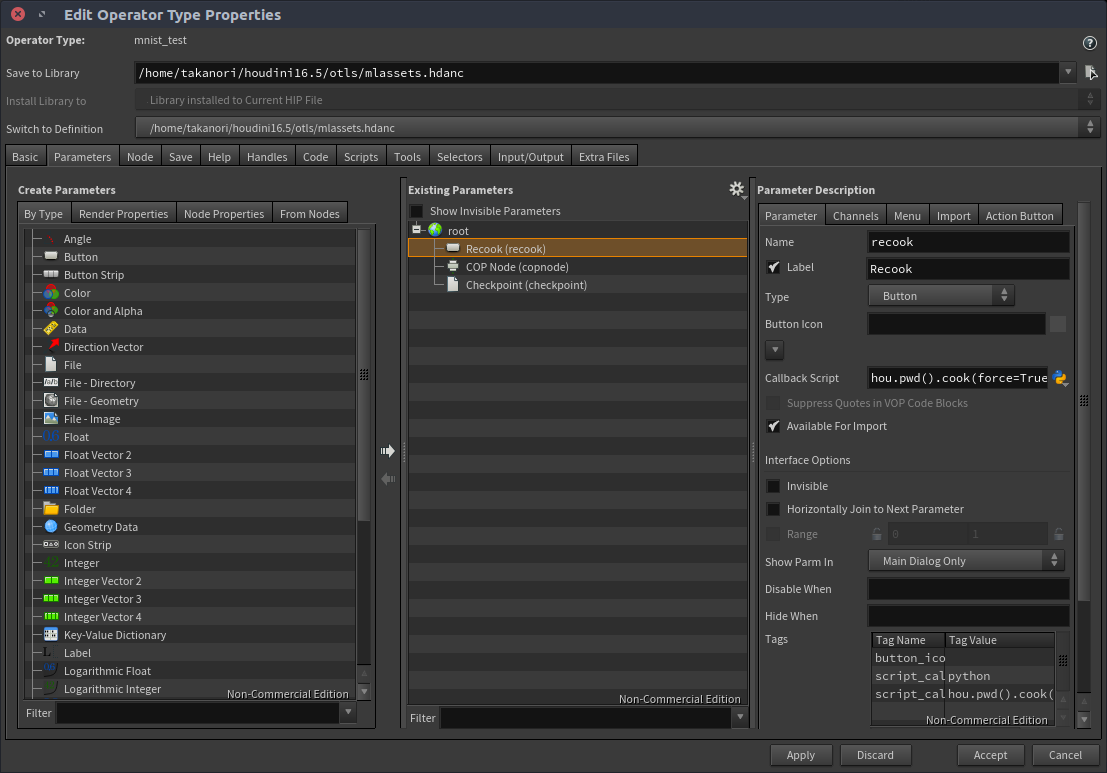
Recookボタンには次のPython Callback Scriptを埋め込んでおく
hou.pwd().cook(force=True)
3-3. コードを記述していく
Codeタブにて、次のコードを記述する。
import os
import re
import numpy as np
import hou
import tensorflow as tf
import mnist
reload(mnist)
node = hou.pwd()
def getCopNode(copnode_path):
if not copnode_path:
raise hou.NodeError('COP Node parameter value is empty.')
copnode = hou.node(copnode_path)
# Detect current node render flag set if the node is COP Network.
if copnode.type().name() == 'cop2net':
for child in copnode.children():
if child.isRenderFlagSet():
copnode = child
break
# Raise error for other nodes.
if not copnode.type().category().name() == 'Cop2':
raise hou.NodeError('Selected node type is not "Cop2".')
return copnode
def copimage_to_numpy_array(copnode):
'''Helper function to convert pixels to numpy array.
'''
pixels = np.asarray(copnode.allPixels(component='r'))
img = pixels.reshape([28,28])
img = np.flip(img, axis=0)
img = 1.0 - img
img = img.reshape((1,784))
return img
copnode_path = node.parm('copnode').eval()
ckpt_path = node.parm('checkpoint').eval()
if not ckpt_path:
raise hou.NodeError('Checkpoint file is not selected.')
if not re.search(r'.ckpt$', ckpt_path):
filename = re.split(r'.ckpt',os.path.basename(ckpt_path))[0]
if not filename:
raise hou.NodeError('The checkpoint file name is invalid.')
ckptname = filename + '.ckpt'
ckpt = os.path.dirname(ckpt_path) + '/' + ckptname
else:
ckpt = ckpt_path
copnode = getCopNode(copnode_path)
input_image = copimage_to_numpy_array(copnode)
with tf.Graph().as_default():
with tf.Session() as sess:
x = tf.placeholder("float", [None, 784])
keep_prob = tf.placeholder("float")
y, variables = mnist.convolutional(x, keep_prob)
saver = tf.train.Saver()
saver.restore(sess, ckpt)
prediction = tf.argmax(y, 1)
result = prediction.eval(feed_dict={x: input_image, keep_prob: 0.5}, session=sess)
geo = node.geometry()
geo.addAttrib(hou.attribType.Global, 'result', result[0])
以下、Pythonスクリプトの処理順に解説していく。
3-3-1. 解説1
最初に必要なモジュールを入力する。
node = hou.pwd() は、現在のノードを取得して node 変数として使えるようにする、まぁ、後で使うときに見やすくするためのおきまりみたいなもので。やってもやらなくてもいい。
import os
import re
import numpy as np
import hou
import tensorflow as tf
import mnist
reload(mnist)
node = hou.pwd()
3-3-2. 解説2
次に、中盤にある、ここで、Houdiniのパラメーターの値を取得している。
copnode_path = node.parm('copnode').eval() # COPノードのパスを取得
ckpt_path = node.parm('checkpoint').eval() # checkpointファイルのパスを取得
3-3-3. 解説3
その次に記述されているところでは、Checkpointファイルを指定した際、 .ckpt として終わらないパス設定がされるため、 .ckpt として終わるように内部処理の切り替えを行っている。なので、 .ckpt で終わるように入力すれば、それでも動作するようにパスを流す。
if not ckpt_path:
raise hou.NodeError('Checkpoint file is not selected.')
if not re.search(r'.ckpt$', ckpt_path):
filename = re.split(r'.ckpt',os.path.basename(ckpt_path))[0]
if not filename:
raise hou.NodeError('The checkpoint file name is invalid.')
ckptname = filename + '.ckpt'
ckpt = os.path.dirname(ckpt_path) + '/' + ckptname
else:
ckpt = ckpt_path
3-3-4. 解説4
ここで2つのヘルパ関数が読まれ、最終的にその返り値を input_image として格納している。
copnode = getCopNode(copnode_path)
input_image = copimage_to_numpy_array(copnode)
ヘルパ関数は次のようになる。
一つ目の getCopNode(copnode_path) は、パラメーターに入力されたパスを引数として受け取り、それが適切なノードタイプになるように判別して、返り値としてCOP Nodeオブジェクトを返している。
そして、もうひとつが、これから学習済みのプロセスを通して予測値を出すために適切な形にするための関数、 copimage_to_numpy_array である。
引数にCOP Nodeオブジェクトを受け取り、そこから全てのピクセル取得からそのピクセルのNumpy配列への変換、操作を行い、学習モデルに食わせる形に変形している。
def getCopNode(copnode_path):
if not copnode_path:
raise hou.NodeError('COP Node parameter value is empty.')
copnode = hou.node(copnode_path)
# Detect current node render flag set if the node is COP Network.
if copnode.type().name() == 'cop2net':
for child in copnode.children():
if child.isRenderFlagSet():
copnode = child
break
# Raise error for other nodes.
if not copnode.type().category().name() == 'Cop2':
raise hou.NodeError('Selected node type is not "Cop2".')
return copnode
def copimage_to_numpy_array(copnode):
'''Helper function to convert pixels to numpy array.
'''
pixels = np.asarray(copnode.allPixels(component='r'))
img = pixels.reshape([28,28])
img = np.flip(img, axis=0)
img = 1.0 - img
img = img.reshape((1,784))
return img
ちなみに、記述の通り、ノードのエラー表示としてエラー処理を行う時は、 hou.NodeError でraiseしてあげると良い。
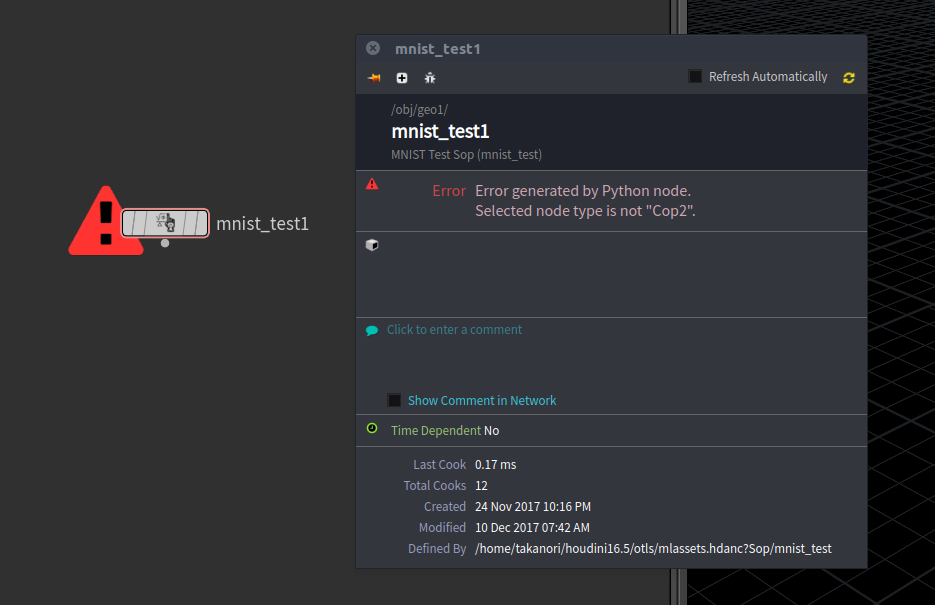
ここでひっかかった!その1
予測値を出すために、画像データをTensorFlowのプロセスに食わせることになるが、これを適切な形に処理する方法に苦労した。
(普通にPILモジュールを使って読み込むスタイルを取れば問題はなかったが、今回はCOPからの入力にこだわりたかったので譲れなかった!!)
hou.COP.allPixels() は、ドキュメントを見ると、Bottom Scanlineタイプというものだという記述がある。
When calling allPixels[AsString] or setPixelsOfCookingPlane[FromString], scanlines are ordered with the bottom scanline first.
つまり、画像の左下が(0,0)で、そこから右上に向けて順々に読み取られて配列化されたものが返り値として帰ってくる。
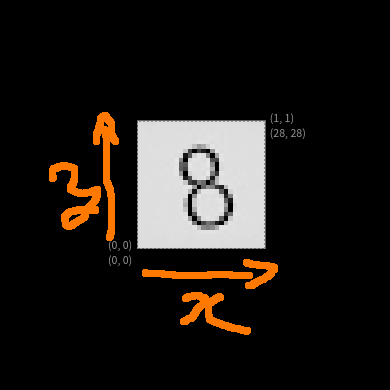
しかし、これだと、画像が上下反転したようになってしまうため、今回使用した学習モデルではその反転により結果の精度が極端に下がってしまう(8とか対象のものは上下左右反転してても問題ないので、だいたい当たる。ただ、他の数字が間違えて8の値を出してしまうことなども多々あった。)。最初はこれに気付かず苦労していた。。
なので、Numpy配列に変換した後にVerticalフリップを行っている。
3-3-5. 解説5
そして取得してきたinput_imageをTensorFlowのパラメーターに食わせ、学習済みのパラメーターを介して結果を取得する。
with tf.Graph().as_default():
with tf.Session() as sess:
x = tf.placeholder("float", [None, 784])
keep_prob = tf.placeholder("float")
y, variables = mnist.convolutional(x, keep_prob)
saver = tf.train.Saver()
saver.restore(sess, ckpt)
prediction = tf.argmax(y, 1)
result = prediction.eval(feed_dict={x: input_image, keep_prob: 0.5}, session=sess)
ここでひっかかった!その2
Houdini上でTensorFlowを走らせると、どうやら、TensorFlowが高速化のためにインスタンスしたグラフ(Graph)を作成するため、VariablesやVariable Scopeの値を新しい箱を作って、それを使用するようになってしまうらしい。これが影響し、 Variable として取得したいはずのものが Variable_1 という名前で扱われしまい、「Variable_1なんてものCheckpointファイルにないよ!」って怒られる。ややこしい。。
図にするとおそらくこんな感じ?
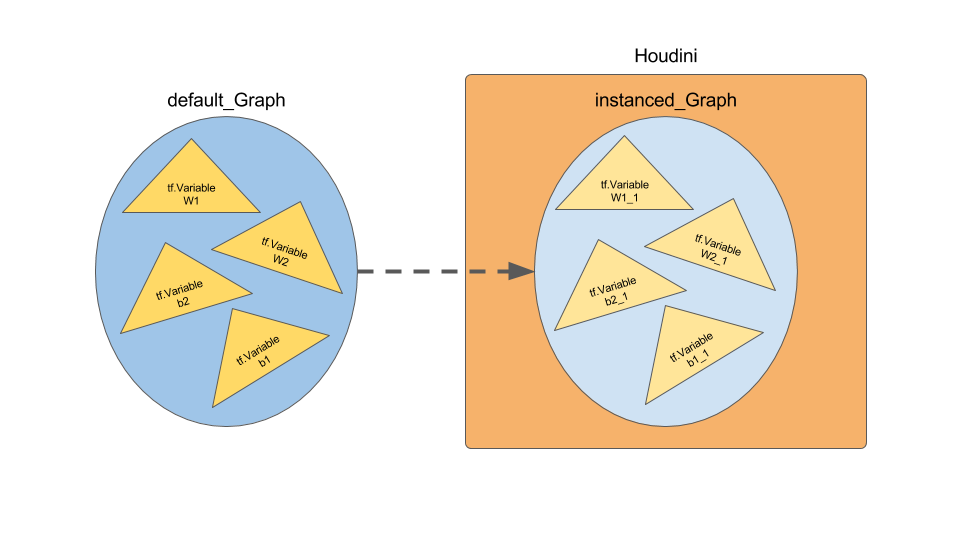
で解決方法としては、いくつかあるらしいのだが、記述している通り、 tf.Graph().as_default()を使うことにした。
この中で処理を行うことで、本来のデフォルトGraphを使用出来るようになるので、問題なく行くようになった。
しかし、同じ類いの中でもVariable Scopeに関しては本当にやっかいだった。上の処理をやっても上手くいかなかった。
今回はその処理を省いたけれども、Issueも立っているので気になる方はそちらを参照。(まぁ、また機会あったら、別でまとめます。
Inconsistent behavior for tf.variable_scope - GitHub
3-3-6. 解説6
そして、最後に、Detail Attributeに result という名前で、出力結果を格納している。
これを後の工程で利用し、ジオメトリを操作するというわけだ。
geo = node.geometry()
geo.addAttrib(hou.attribType.Global, 'result', result[0])
ちなみに、この hou.attribType.Global というのがDetail Attributeのこと。
3-4. ノードのパラメーターに入力する
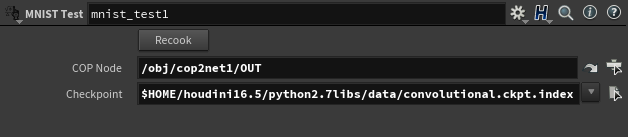
作ったノードのパラメーターに、次の項目を入力する。
- COP Node: 先程までで作成してきた、COP NetworkのOUT(Null COP)かもしくはCOP Network自体を選択する(この場合、最後の合成結果のところにRender Flagを立てておくこと)
- Checkpoint: 1.で書きだした、Checkpointファイルを選択する(Code内で文字列処理しちゃってるので、生成されたやつどっち入力しても良い
4. MNIST Test(Python Digital Asset)の結果を受け取る仕組みを作る
3.で、予測結果をDetail Attributeとして格納したので、これを次のノードで受け取る様にし、これを利用してFontのスイッチを行うようにする
Font SOPに直接値を処理させる方法がわからなかったので、とりあえずSwitch SOPのIndexの値で切り替えて0-9のジオメトリを切り替えるようにした。
4-1. Subnetの中にSwitch構造を作る。
Font SOPを使って、0-9までの数の分、フォントジオメトリを用意して、Switch SOPで切り替えるように構築。
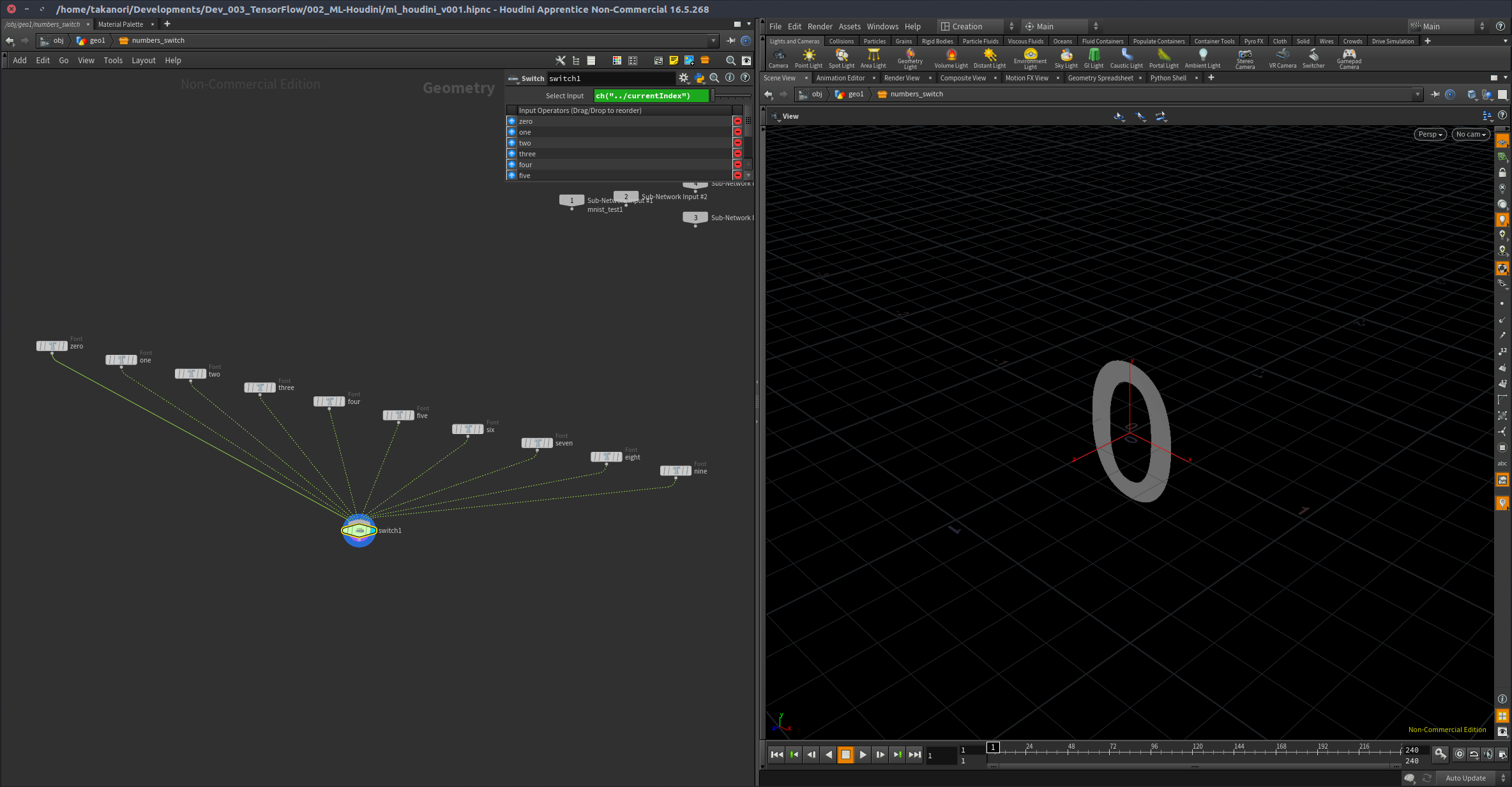
Subnetのパラメーターはこんな感じ。
Switch SOPのinputパラメーターをリファレンスしてきて、Subnetの上でスクリプトタイプをPythonに変え、Current Indexに次のスクリプトを入力する。
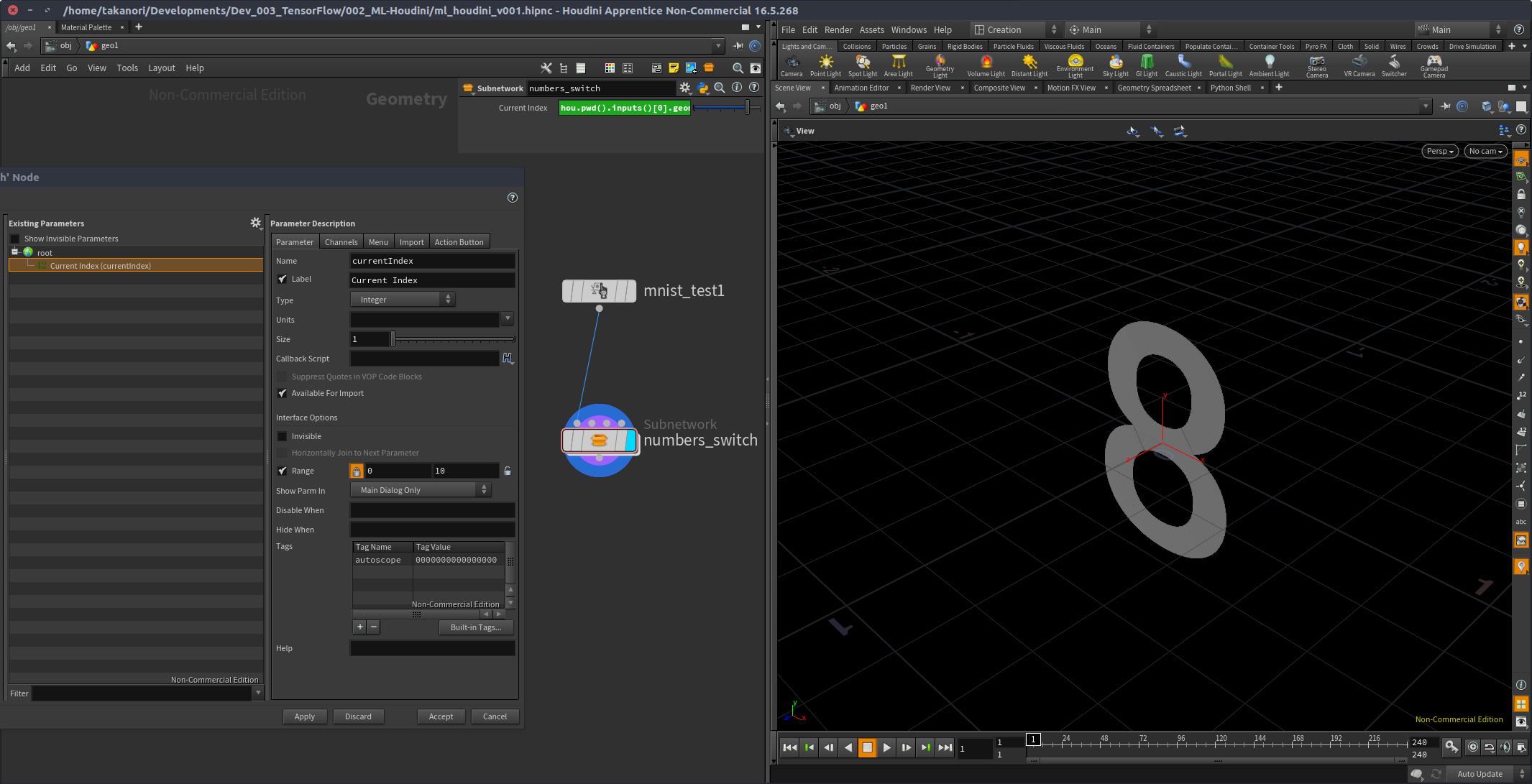
hou.pwd().inputs()[0].geometry().attribValue('result')
これで、上の階層の result アトリビュートが変更され、cookされるたびに、Switchの切り替えがなされ、数字で示されたフォントジオメトリが切り替わる。
#Houdini で機械学習 with #TensorFlow | ノートまとめました〜😆https://t.co/s86VERRifU…#HFXJP #machinelearning pic.twitter.com/YNAPuNZihg
— Takanori.K (@auratus) 2017年12月14日
まとめ
とりあえず、TensorFlowを使う環境を作って、Houdiniの中で使える・使うという事を書いてきた。
なぜTensorFlow選択したのか?と聞かれたら、とりあえず有名だからって感んじで。実際のところ、ChainerかPyTorchでも似たような事をやろうと思ったけれども、今回はやめておいた。誰か興味がある人がいれば是非試して欲しいと思う。(でも、近々自分で別の学習モデルで実装とかはやりそうな気配
COP -> SOPという流れは実は結構クセがある(SOPに持って行って、いつもの感覚で更新されるかなと思いきや、更新されない。使えないじゃん!!オイ!まぁ、COPはHoudiniに統合されたものの中で一番発展が遅れているのも要因)ので、この方法が万能で行くかという保証がないが、Houdiniらしくノードベース・プロシージャルフローでの機械学習プロセスを介したネットワークが組めると見れるのは面白い。こういった試験の場所として、Digital Assetという仕組みを利用してミクロベースの開発(ノード単位の開発)を行いつつも、実装をして行けるというのはHoudiniの醍醐味ではなかろうか。
今回の気付きとしては、結局引っかかったTensorFlowらしいライブラリの特色を上手く掴むことと、Houdini側のノードの処理関連も特有のクセがあるので、何か問題に行き詰まった場合には、そこらへん注意して調査していくと解決が速いかもしれないと思った。
日に日に刷新され、流れの速い機械学習業界なので、今のうちにこうして基礎の基礎の部分をまとめはじめてまとめていくのは重要だと思うので、こうして実装において出来たこととこれからの課題点などが整理出来たのは良かったと思う。
間違いとかあったら、遠慮無くぶつけてください ![]()
関連情報
- CGWORLD - プロシージャルコンテンツ生成の可能性に沸くゲーム業界~Tokyo Houdini Meetup Vol.1レポート にて、Meetupでこの記事に関して話した内容を少々紹介頂きました!