はじめに
Claude Code に追加された Sysdig Secure のリモート MCP サーバと、プラグインとして配布されるAgent Skill を使って、ランタイム脅威の 調査(investigate)→ 対処(remediate) を実際に回してみました。
本記事は「動かしてみた」体験記の技術深掘り版です。実際に呼ばれた MCP ツール、SysQL、API レスポンス、そしてエージェントが内部で行っている可用性プリフライトやブラストradius解析のロジックまで踏み込みます。
対象読者:
- MCP(Model Context Protocol)でセキュリティ製品を AI エージェントに繋ぐ構成に興味がある人
- AI に「本番環境への対処」をどこまで・どう安全に任せられるか気にしている人
- Sysdig の Response Actions / Threats Engine / SysQL を API レベルで知りたい人
1. アーキテクチャ全体像
今回の登場要素は、大きく 「ローカル」 と 「リモート」 の2領域に分かれます。
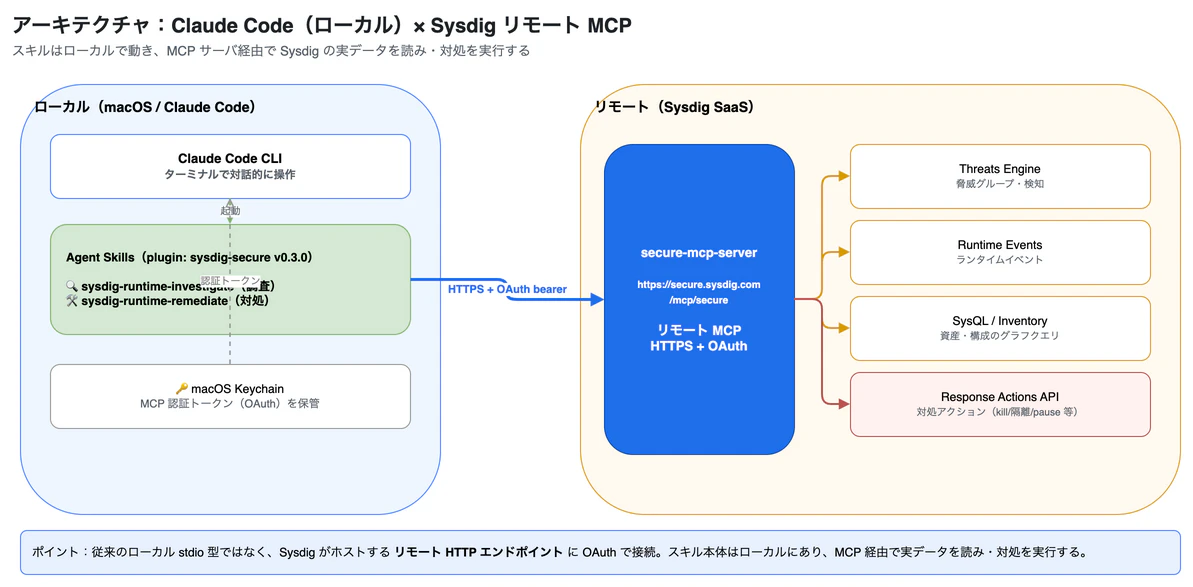
ポイントは、MCP サーバがリモート(Sysdig がホスト) であること。ローカルで stdio プロセスを起動する従来型ではなく、https://secure.sysdig.com/mcp/secure という HTTP エンドポイントに OAuth で認証して繋ぎます。スキル本体はプラグインとしてローカルにあり、MCP 経由で Sysdig の実データを読み・対処を実行します。
2. investigate スキルの内部動作
ユーザーがやることは、たった一言 「ランタイムの脅威を調べて」 とお願いするだけです。あとはスキルが、人間のアナリストが手でやるような調査を、順番に自動で進めてくれます。その流れは大きく4ステップ。
- 準備(Preflight) — ちゃんと Sysdig に繋がっているか確認する
- 洗い出し(Surface) — いま起きている脅威を一覧にする
- 深掘り(Investigate) — 選んだ脅威の「攻撃の流れ」を組み立てる
- 報告(Report) — 読めるレポートにまとめる
以下、それぞれの裏側で何が起きているかを、順に見ていきます。
ステップ1:準備 — 「そもそも繋がってる?」を確かめる
調査を始める前に、スキルはまず 「Sysdig にちゃんとログインできているか」 を確認します。ここが面白くて、わざわざ問い合わせを送らずに判定します。
仕組みはこうです。Sysdig に未ログインだと、スキルから見える道具(ツール)は「ログイン用の道具」だけ。ログイン済みになって初めて、「顧客設定を読む」「脅威を一覧する」といった本来の道具一式が見えるようになる。つまり、今どの道具が手元にあるかを眺めるだけで、ログイン状態がわかるわけです。本物のデータには一切触れずに前提チェックを済ませる、行儀のよい設計です。
次にスキルは 「前回の調査の続きはある?」 と自分のメモ帳を確認します。今回は初回なので、メモは空っぽ。スキルは「まっさらな状態から始めよう」と判断して先へ進みます。
💡 このメモ帳(共有ステート)は、過去に調べた事案や「報告先は Jira がいい」といったユーザーの好みを覚えておく仕組みです。2回目以降はここを読んで、いちいち同じことを聞かずに済ませます。
ステップ2:洗い出し — いま起きている脅威を新しい順に
スキルは Sysdig に 「今ひらいている脅威を、新しい順に5件見せて」 と頼みます。返ってきたのは5つの脅威グループ。ここでスキルが気を利かせます。
5つのうち4つが、5月29日の同じ数時間内・同じクラスタ・同じコンテナイメージで起きていました。バラバラのアラートに見えても、時間と場所と道具立てが揃っていれば、それはひとつの攻撃キャンペーンの別々の場面である可能性が高い。スキルはこれらを束ねて「ひとつのインシデント」として扱うことにしました。アラートを「点」ではなく「線」で読む、アナリストの第一歩です。
ステップ3:深掘り — 「攻撃の流れ」を組み立てる
ここからが本番。スキルは束ねた脅威グループについて、**「このインシデントに関わったリソースは?」「具体的にどんな脅威が含まれる?」**と Sysdig に細部を問い合わせ、現場の輪郭を描いていきます。判明したのは次のような事実でした。
| 項目 | 値 | これは何か |
|---|---|---|
| クラスタ |
takao-ocp-pov(OpenShift) |
攻撃が起きた Kubernetes 環境 |
| namespace | sysdig-dr-test |
その中の区画。名前からして検証用 |
| 関与した Pod |
drift-sandbox / crypto-test
|
攻撃の舞台になった2つのコンテナ |
| イメージ | nicolaka/netshoot:latest |
ネットワーク調査用の万能ツール箱イメージ |
| クラウド | AWS(東京リージョン) | 土台になっているクラウド環境 |
攻撃の流れを組み立て、いまの状況まで押さえる
スキルは、複数の手がかりを突き合わせて攻撃のストーリーを組み立てます。検知ルールの構成と、Sysdig の AI が残してくれていた自然言語の振る舞い説明(例:「curl で xmrig をダウンロードした」)。これらを重ね合わせることで、「何が・どの順で・どこで起きたか」がくっきりと浮かび上がります。
さらにスキルは、過去の再構成だけで満足せず、「この攻撃、今もまだ続いてる?」という確認も入れます。直近7日間に高重大度のイベントが出ていないかを調べたところ、結果はゼロ件。つまりこの攻撃は5月29日のひと吹きで、すでに沈静化していると裏付けが取れました。過去の再構成と現在の状況、その両方を押さえる手堅さが頼もしい。
攻撃に「名前」を付ける(MITRE ATT&CK)
最後にスキルは、検知ルールと振る舞いから、この攻撃が攻撃手法の世界標準カタログ「MITRE ATT&CK」のどれに当たるかを割り当てます。今回の主役は Impact(T1496:リソース乗っ取り=クリプトマイニング)、脇を固めるのが Execution(T1059:/tmp への不正バイナリ投下・実行)。この“ラベル”が、関連する別の攻撃を探す手がかりにもなります。
組み上がった攻撃フロー
こうして再構成された攻撃の流れが、下の図です。横軸が MITRE ATT&CK のフェーズ(①初期アクセス・実行 → ②ツール転送 → ③実行・防御回避 → ④影響)、縦の2レーンが攻撃の舞台になった2つの Pod。外部インフラからダウンロードした道具を /tmp で実行し、最終的に暗号通貨マイナー xmrig を動かす——という一連の流れが、時間軸に沿って追えます。
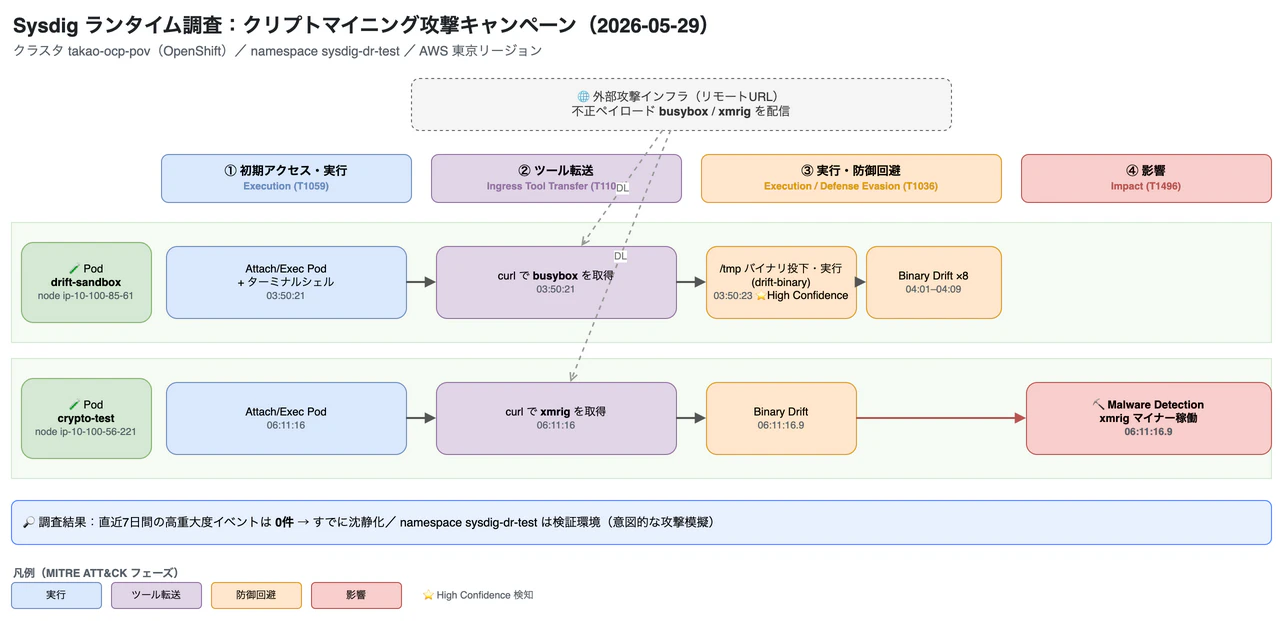
| Time (UTC) | Where | Action |
|---|---|---|
03:50:21 |
drift-sandbox |
Attach/Exec Pod + Terminal shell
|
03:50:21 |
drift-sandbox |
Ingress Remote File Copy — curl で busybox 取得 |
03:50:23 |
drift-sandbox |
Drop and Execute /tmp Binary(HC) + Execution from /tmp
|
04:01–04:09 |
drift-sandbox |
Binary Drift ×8 (Crit) |
06:11:16 |
crypto-test |
Attach/Exec → curl で xmrig 取得 |
06:11:16.9 |
crypto-test |
Malware Detection + Binary Drift
|
いちばん感心した「誠実さ」
この調査でいちばん感心したのは、スキルがアラートを鵜呑みにしなかったことです。
実は Sysdig の AI は、/tmp バイナリ投下の方に 「正規のテスト活動を検出(Legitimate Testing Activity Detected)」 という、むしろ良性寄りの注釈を残していました。区画の名前は sysdig-dr-test、コンテナ名は drift-sandbox に crypto-test。どう見ても**検証・デモのために意図的に作られた“攻撃のリハーサル”**です。
スキルはここを見抜き、レポートにこう書きました——「検知そのものの正確さは満点(5/5)。ただし、これが本物の攻撃者である確からしさは低い」。真っ赤なアラートに飛びつかず、状況証拠から温度を補正する。誤報対応に消耗しがちな現場で、これがどれだけありがたいか。
報告:そのまま使える2つのレポート
最後にスキルは、調査結果を2つのファイルに書き出しました。チケットにそのまま貼れる Markdown 版と、ブラウザで開くと先ほどの攻撃フロー図が絵として表示される HTML 版です。チャットに出すのは2段落の要約だけで、長い証拠や表はファイル側へ。**「人が読むのは要約、深掘りはファイル」**という割り切りが心地よい。
そして調査の記録を自分のメモ帳に保存し、次の「対処」担当へバトンを渡します。ここからが第2幕です。
3. remediate スキルの内部動作
調査が終わると、バトンを受け取った「対処」スキルが動き出します。ここでのユーザーの役割は、提案された対処を承認するか断るかを選ぶこと。スキルは決して、勝手にコンテナを止めたり消したりはしません。いきなり手を出さず、まず現場を調べ、できることを並べ、ひとつずつ許可を取る——この慎重さが最大の特徴です。
まず「自分に何ができるか」を確かめる
対処を提案する前に、スキルは Sysdig に **「この環境で打てる対処アクションの一覧」**を尋ねます。返ってきたのは全部で 24種類。これらは効く場所によって3つに分かれます。
| 効く場所 | アクションの例 | ざっくり言うと |
|---|---|---|
| ホスト(サーバ単位) | プロセス強制終了、コンテナの kill / 一時停止、不審ファイルの隔離 | 動いている“もの”を直接止める |
| クラスタ(Kubernetes 単位) | Pod 削除、ワークロード再起動、ネットワーク隔離 | K8s のレイヤーで封じ込める |
| クラウド(AWS 単位) | IAM ユーザ/ロールの隔離、公開リソースの非公開化 | クラウドの権限・露出を絞る |
ただし「一覧に載っている=今すぐ実行できる」ではありません。スキルはここでも楽観しません。たとえば、ログ取得などの一部アクションは保存先ストレージが設定済みでないと動きません。確認すると、この環境ではストレージが未設定。スキルは「これらは出しても失敗する」と判断し、提案の段階で候補から外しました。さらに過去の実行履歴もゼロだったため、「本当に動くかは実際に試すまで断定しない」と慎重に構えます。
真骨頂:「壊す前に、対象が生きているか確かめる」
ここが対処スキルの白眉です。破壊的な操作をする前に、読み取り専用で現場を偵察します。
最初の確認は 「自分の手元の操作対象が、本当に正しいクラスタを向いているか」。調べると、ローカルの接続先は調査対象の takao-ocp-pov とは別のクラスタでした。スキルは即座に「これで kubectl を動かしたら、無関係なクラスタを誤操作してしまう」と察し、kubectl を使う許可は求めませんでした。事故の芽を自分から摘む判断です。
次に、Sysdig のデータベースに **「攻撃当時の Pod は今も存在する?」と問い合わせます。ここで Sysdig 独自の問い合わせ言語の書き方が少し特殊で、最初の2回は文法エラーで弾かれました。スキルは無理に手書きを続けず、「自然言語から正しい問い合わせ文を生成してくれる補助機能」**に正しい形を作らせ、それで取得に成功——いわば、道具の使い方を道具自身に教わったわけです。
返ってきた答えが決定打でした。現在その区画にいる Pod は media-sandbox と shell-sandbox の2つ。攻撃に使われた drift-sandbox も crypto-test も、もう存在しない。攻撃当時のコンテナはとっくに撤去され、別の検証用 Pod に入れ替わっていたのです。
結論:「直すものは無い」と言い切る
対象が消えている以上、何を実行しても意味がありません。スキルは、提案候補を一つひとつ正直に×にしていきました。
| 対処の分類 | 判定 | 理由 |
|---|---|---|
| コンテナを止める/隔離する系 | ❌ 実行不能 | 止めたいコンテナがもう存在しない |
| Pod 削除・ネットワーク隔離系 | ❌ 実行不能 | 対象の Pod が存在しない |
| ログ・キャプチャ取得系 | ❌ 実行不能 | 保存先ストレージが未設定 |
| クラウド権限の隔離系 | ⚠️ 見送り | 隔離すべき具体的な不正アカウントが特定できていない |
そしてスキルは、破壊的な対処を1つも実行せずにクローズしました。多くのツールは「とりあえず押せるボタン」を並べたがりますが、このスキルは違います。空振りに終わる操作を提案しない。対象が無ければ「無い」と言い切る。 地味ですが、これは高度な振る舞いです。
最後に残した助言も的確でした——「対処より、整理を」。これは検証環境の意図的なリハーサルなのだから、該当の脅威を整理(アーカイブ)するか、この区画を「検証用」として通常の監視対象から外せばいい、と。本物のインシデントなら同じ流れで封じ込めまで走れる。“ただの演習”なら、無駄に手を動かさず片付け方を教えてくれる。この使い分けの賢さこそが価値でした。
4. 技術的に良くできていると感じた設計
最後に、エンジニア視点で「うまい」と思った設計上の工夫を5つ挙げておきます。
- 問い合わせゼロで前提チェック:ログイン状態を、実際にAPIを叩かず「今どの道具が見えているか」だけで判定する。副作用なしで安全に確認できる。
- 情報源を柔軟に使い分ける:検知ルール・AIの振る舞い説明・自動生成された問い合わせなど、複数のデータソースを突き合わせて結論まで到達する。
- 「できること」を実行前に確定:打てる対処・過去の実行履歴・ストレージ設定を事前に照合し、失敗するアクションを最初から提案しない。
-
承認の粒度が細かい:調べるだけ(読み取り)はノーゲート、環境を変える操作は1件ごとに明示的なYes。
kubectlやクラウドの許可もその場限りで、保存しない。 -
推測より証拠:Pod が生きているかを推測せず問い合わせで確認し、対処が打てるかも楽観せず確認する。
Evidence > assumptionsを徹底している。
5. まとめ
今回の検証は、**「AI エージェントにセキュリティ運用をどこまで・どう安全に任せられるか」**の良いケーススタディになりました。
- investigate は読み取り専用で深く調べ、文脈で温度を補正し、再利用可能なレポート(Markdown / Mermaid 入り HTML)を残す。
- remediate は破壊する前に偵察し、能力を事前確定し、「直す対象が無い」なら正直にそう言う。
派手なアクションは1つも実行されていません。それでも、「これはキャンペーンだ/これは検証環境だ/もう対象は無い」という判断こそが、現場の時間を最も節約します。AI エージェント × セキュリティの価値は、実行力よりも安全装置付きの判断力にある——そう実感した2連発でした。
環境:Claude Code + Sysdig Secure リモート MCP サーバ(secure.sysdig.com/mcp/secure)/ プラグイン sysdig-secure v0.3.0