1. はじめに
1-1 ご挨拶
初めまして、井村と申します。
Microsoft Fabricは、データの統合、エンジニアリング、分析、ビジネスインテリジェンスなどの機能を統合したSaaS型データ分析ツールです。
そしてMicrosoft Fabricは60日間のフリートライアル期間があります。
さらに、Microsoftが提供する無料のオンライン学習プラットフォームであるMicrosoft Learn(MSLearn)にはたくさんのMicrosoft Fabricに関する記事があります。
本記事はフリートライアル期間を利用してMSLearnの演習を行っていきます。
演習を通して気づいた点やTipsを、なるべく多くのスクリーンショットとともに備忘録として残します。
1-2 MSLearn
今回はMicrosoft Fabric で Delta Lake テーブルを操作するを行います。
この演習の学習の目的は以下の通りです。
- Microsoft Fabric の Delta Lake テーブルとデルタ テーブルについて
- Spark を使用してデルタ テーブルを作成および管理する
- デルタ テーブルを最適化する
- Spark を使用してデルタ テーブル内のデータに対してクエリと変換を行う
- Spark 構造化ストリーミングでデルタ テーブルを使用する
1-3 Get started with Microsoft Fabric
以下からMicrosoft Fabricのフリートライアルを開始できます。
Get started with Microsoft Fabric
2. Delta Lakeについて
Delta Lakeについての概要になります。
Microsoft Fabric Lakehouse のテーブルは、Delta Lake テーブル形式(Linux Foundationが管理)に基づいています。Delta Lake は、バッチデータとストリーミングデータのリレーショナルデータベース機能を有効にする Spark 用のオープンソースストレージレイヤーです。
Delta Lake を使用すると、トランザクションとスキーマの適用をサポートし、Spark で SQL ベースのデータ操作セマンティクスをサポートする Lakehouse アーキテクチャを実装できます。
こちらの記事にとても分かりやすい解説があります。
3. 演習スタート
演習 - Apache Spark でデルタ テーブルを使用する
上記URLから演習を開始できます。実際のMicrosoft Fabricを使うため、とても勉強になります。
3-1 ワークスペースの作成
1 . 【Azure】Microsoft Fabric レイクハウス内にあるファイルとテーブルにデータを取り込む。(3-1 レイクハウスを作成する)をご参照ください。
3-2 レイクハウスを作成してデータをアップロードする
1 . レイクハウスの作成は上記リンクをご参照ください。
2 . ファイルのアップロードは以下リンクをご参照ください。
【Azure】Microsoft Fabric レイクハウス内にあるファイルとテーブルにデータを取り込む。(3-2 ファイルのアップロード)
なお今回のファイルはproducts.csvになります。
3-3 DataFrame 内のデータを探索する
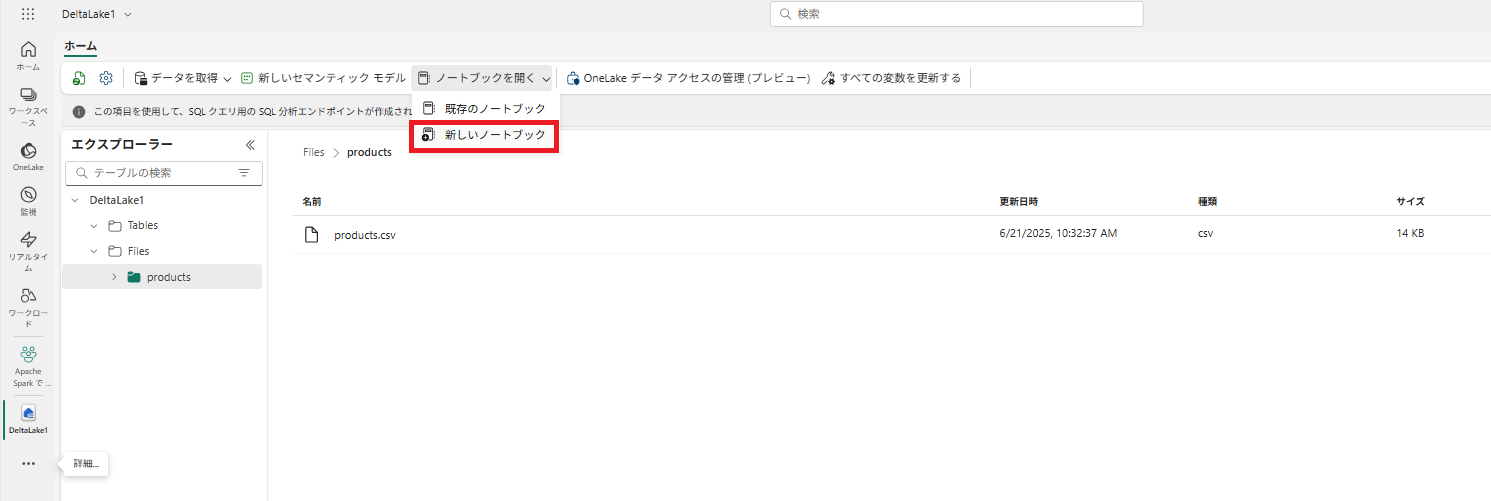
1 . 上側[ツールバー] - [ノートブックを開く] - [新しいノートブック]を押下します。
マークダウン セルを使用して、コードに関する説明情報を記載します。
2 . 最初のセル (今はコード セル) を選択し、右上のツール バーで [M↓] ボタンを使用して Markdown セルに変換します。

3 . ([編集]) ボタンを使用してセルを編集モードに切り替え、マークダウンを次のように変更します。

# Delta Lake tables
Use this notebook to explore Delta Lake functionality
4 . マークダウンの内容が更新されました。[コード セルの追加]を押下します。

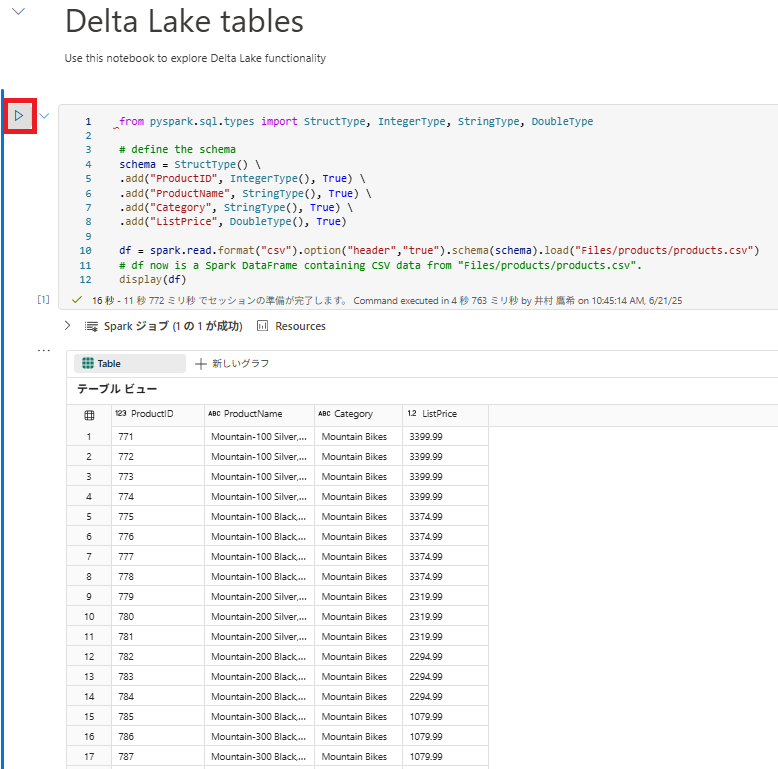
5 . 次のコードを追加して、定義したスキーマにより製品データを DataFrame に読み取ります。セルの左側にある [セルの実行] (▷) ボタンを使用して実行します。
from pyspark.sql.types import StructType, IntegerType, StringType, DoubleType
# define the schema
schema = StructType() \
.add("ProductID", IntegerType(), True) \
.add("ProductName", StringType(), True) \
.add("Category", StringType(), True) \
.add("ListPrice", DoubleType(), True)
df = spark.read.format("csv").option("header","true").schema(schema).load("Files/products/products.csv")
# df now is a Spark DataFrame containing CSV data from "Files/products/products.csv".
display(df)
3-4 Delta テーブルを作成する
saveAsTable メソッドを使用すると、DataFrame を Delta テーブルとして保存できます。 Delta Lake では、マネージド テーブルと外部テーブルの両方の作成がサポートされています。
- マネージド Delta テーブル : スキーマ メタデータとデータ ファイルの両方が Fabric によって管理されるため、パフォーマンスが向上します。
- 外部テーブル : メタデータはFabricで管理されますが、データファイル自体は指定した外部ストレージ(例: Files フォルダーなど)に格納されます。
マネージド テーブルを作成する
1 . マネージド Delta テーブルを作成するには、新しいセルを追加し、次のコードを入力して、セルを実行します。[Tables] フォルダーを更新し、[Tables] ノードを展開して、[managed_products] テーブルが作成されていることを確認します。
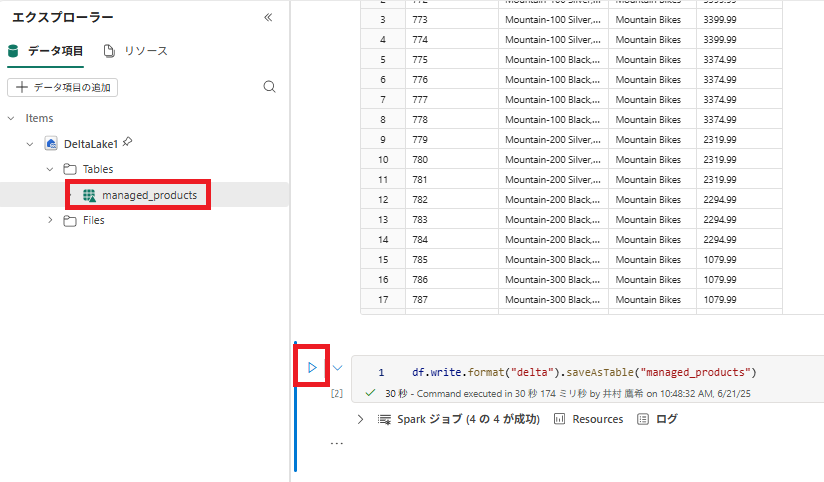
[!NOTE] ファイル名の横にある三角形アイコンは Delta テーブルを示します。
外部テーブルを作成する
レイクハウスに格納されているスキーマ メタデータを使用して、レイクハウス以外の場所に格納できる外部テーブルを作成することもできます。
1 . [レイクハウス エクスプローラー] ペインで、 Files フォルダーの […] メニューにある [ABFS パスのコピー] を選択します。 ABFS パスは、レイクハウスの Files フォルダーへの完全修飾パスです。
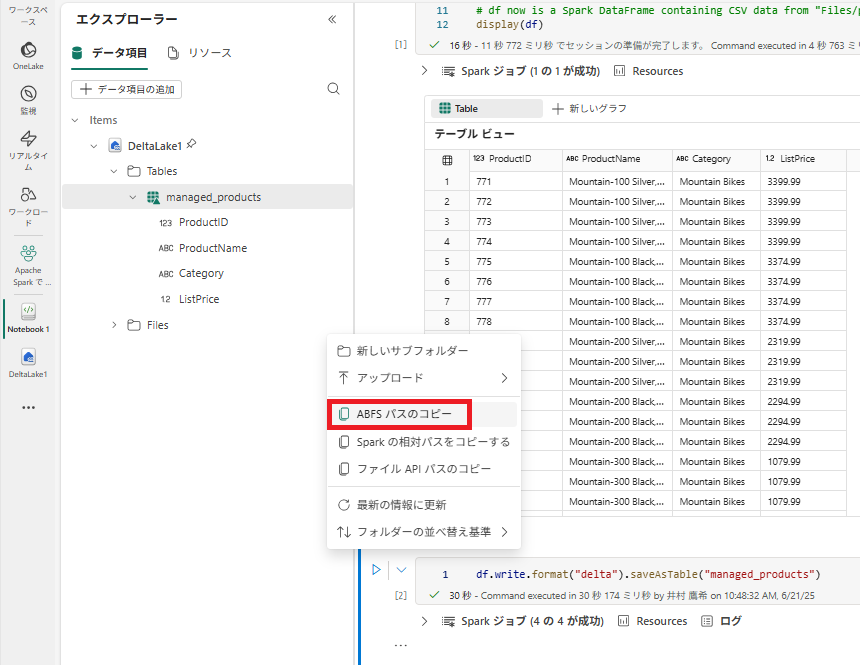
2 . 新しいコード セルに、ABFS パスを貼り付けます。 切り取りと貼り付けを使用して、コード内の正しい場所に abfs_path を挿入して、次のコードを追加します。
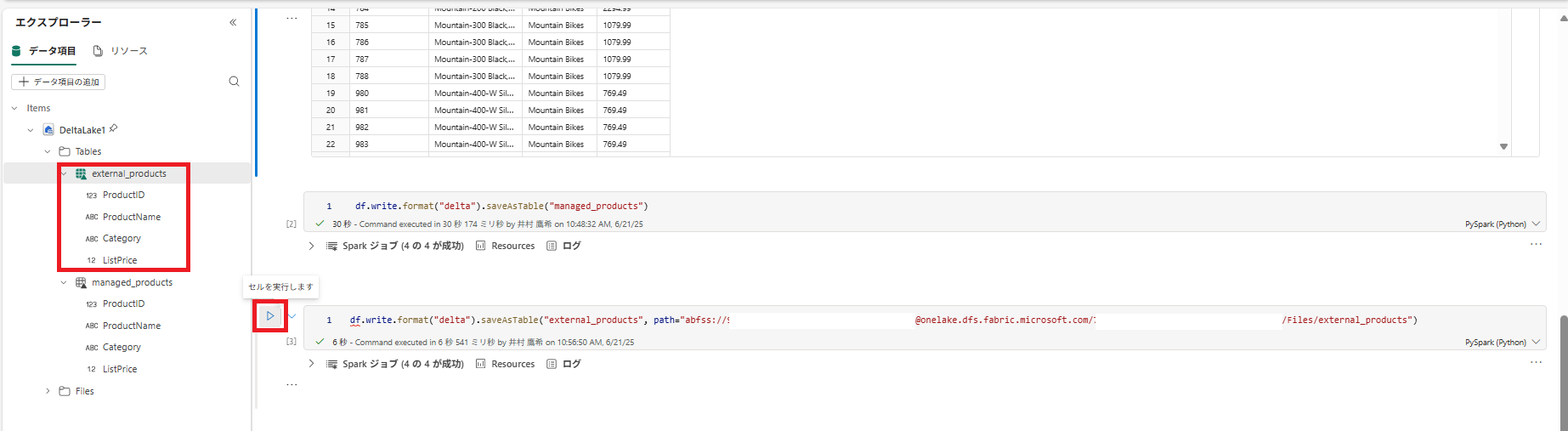
df.write.format("delta").saveAsTable("external_products", path="abfs_path/external_products")
セルを実行し、DataFrame を外部テーブルとして Files/external_products フォルダーに保存します。
3 . [Tables] フォルダーを更新し、[Tables] ノードを展開して、スキーマ メタデータが入った [external_products] テーブルが作成されていることを確認します。
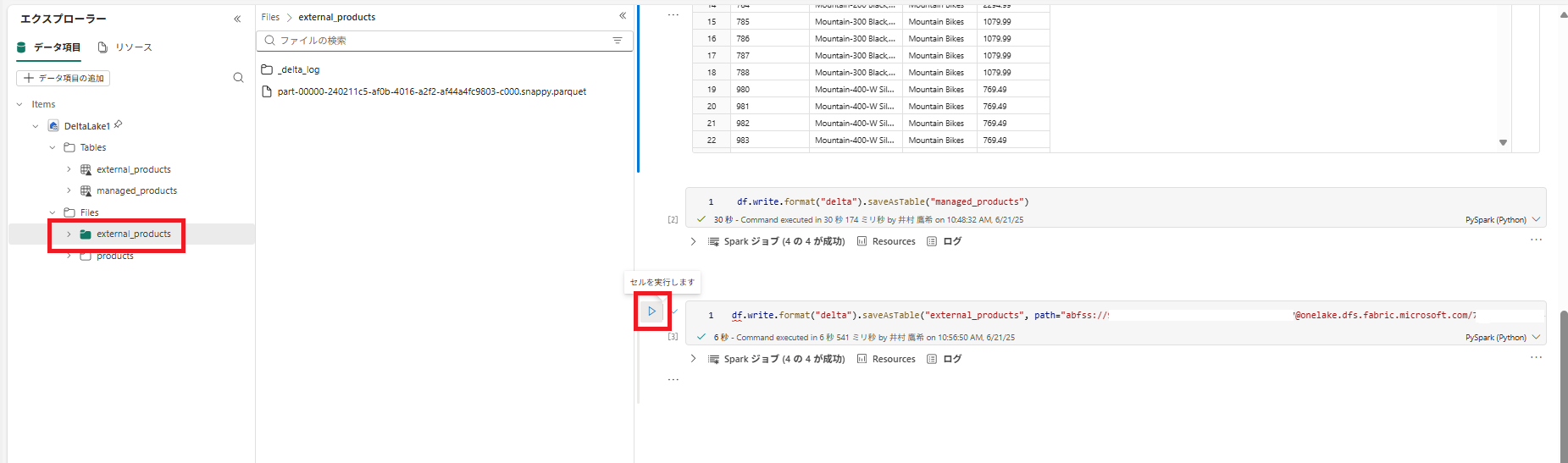
4 . [Files] フォルダーの […] メニューにある [更新] を選択します。 次に、[Files] ノードを展開し、テーブルのデータ ファイル用に [external_products] フォルダーが作成されていることを確認します。
マネージド テーブルと 外部 テーブルを比較する
1 . 新しいコード セルで、次のコードを実行します。
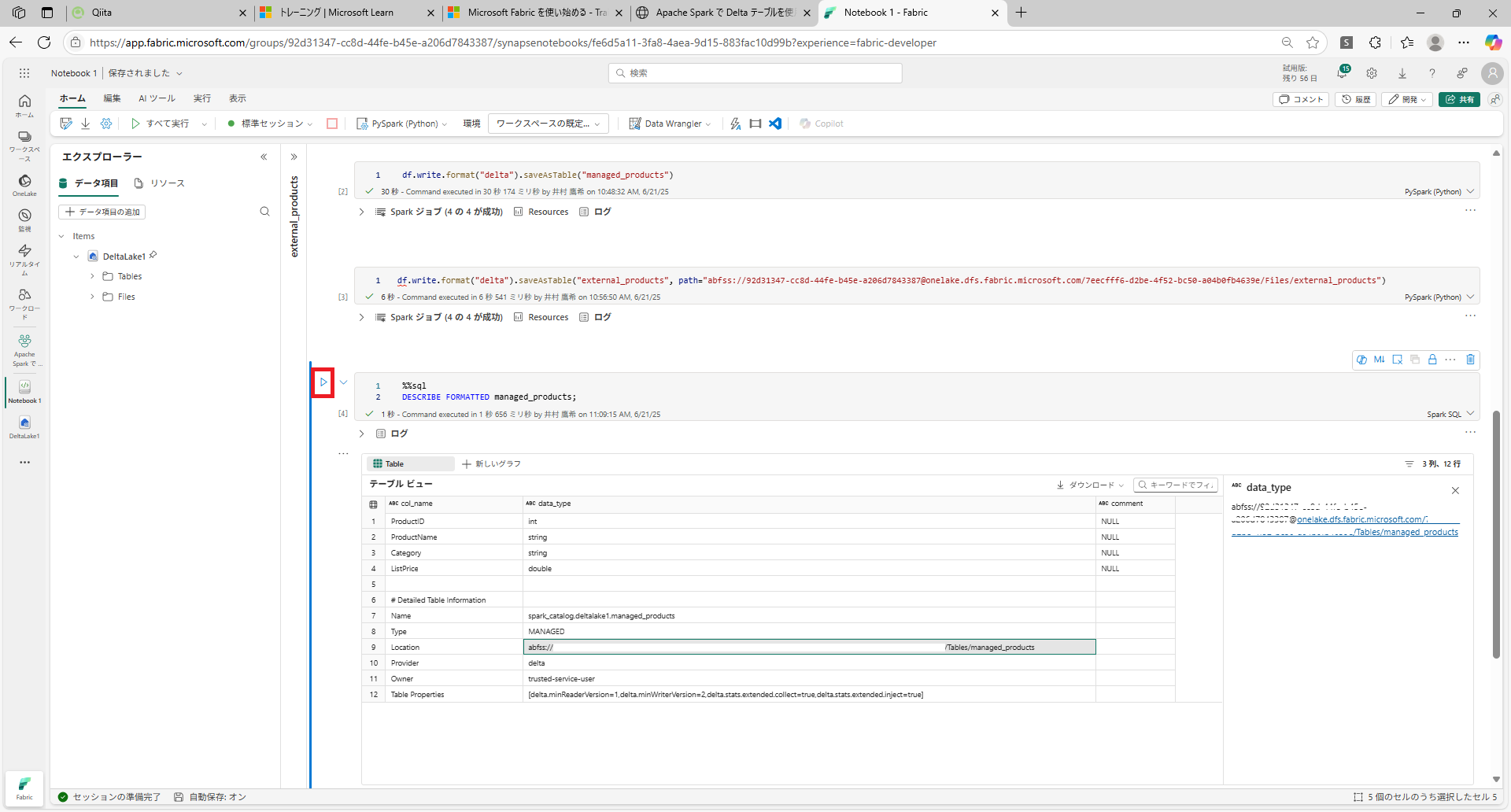
%%sql
DESCRIBE FORMATTED managed_products;
2 . 結果で、テーブルの Location プロパティを確認します。 [データ型] 列の Location 値をクリックすると、完全なパスが表示されます。 OneLake ストレージの場所が /Tables/managed_products で終わります。
3 . 次のように、external_products テーブルの詳細を表示するように DESCRIBE コマンドを実行します。
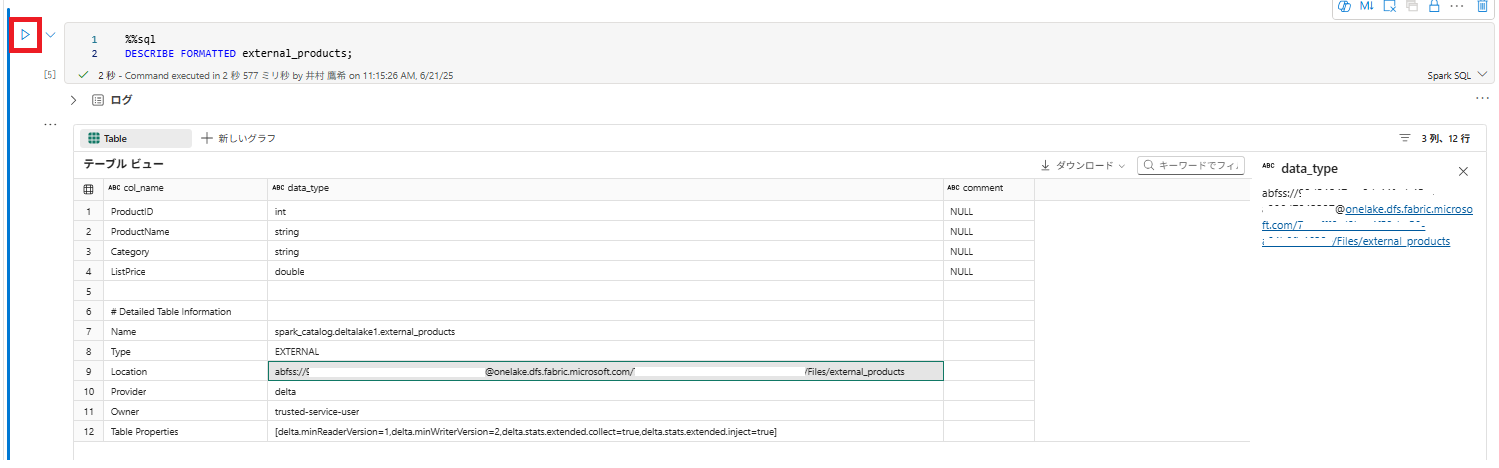
%%sql
DESCRIBE FORMATTED external_products;
4 . 結果でテーブルの Location プロパティを確認します。 [データ型] 列の幅を広げて完全なパスを表示し、OneLake ストレージの場所が /Files/external_products で終わります。
5 . 新しいコード セルで、次のコードを実行します。
%%sql
DROP TABLE managed_products;
DROP TABLE external_products;
6 . [Tables] フォルダーを更新し、[Tables] ノードにテーブルが表示されていないことを確認します。また、[Files] フォルダーを更新し、[external_products] ファイルが削除されていないことを確認します。 このフォルダーを選択して、[Parquet] データ ファイルと [_delta_log] フォルダーを表示します。
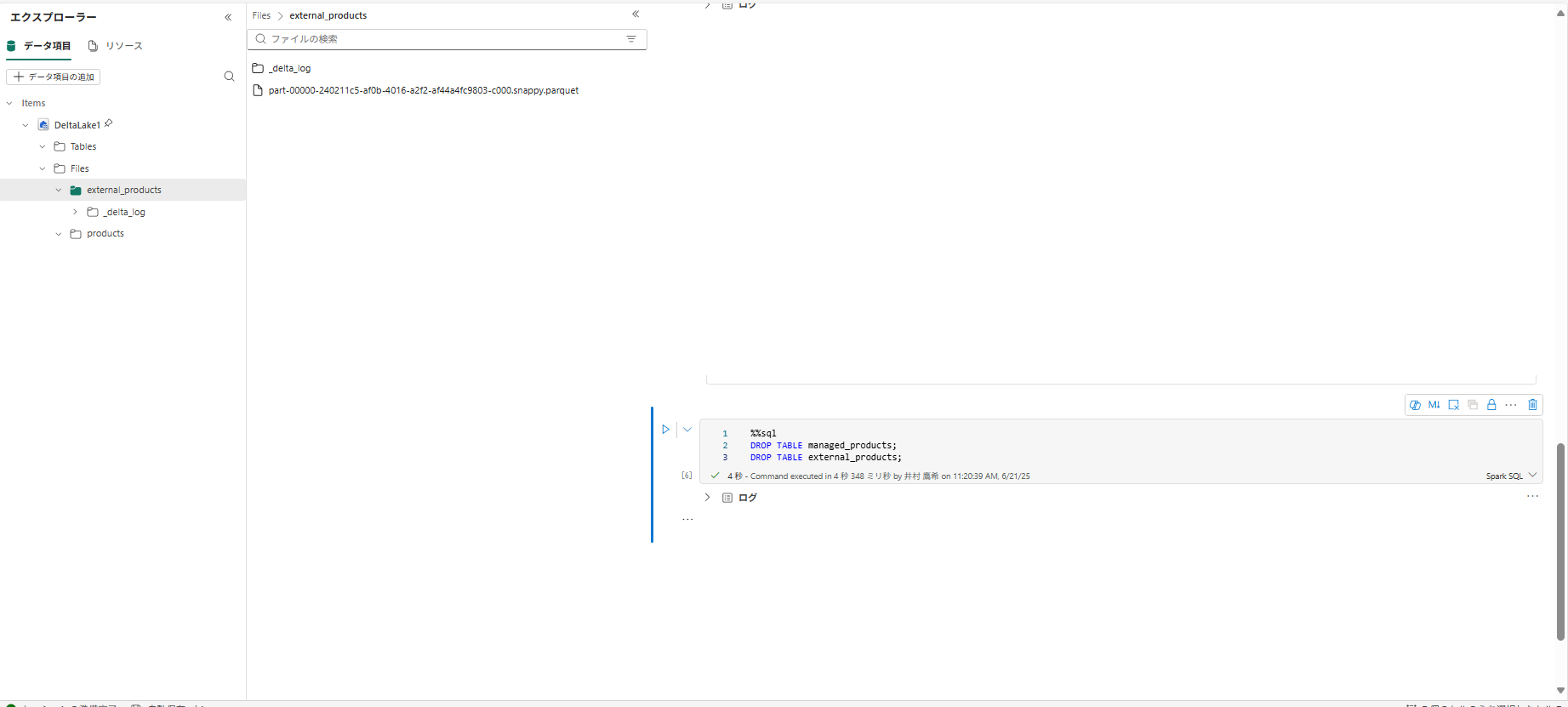
外部テーブルのメタデータは削除されましたが、データ ファイルは削除されていません。
3-5 SQL を使用して Delta テーブルを作成する
今度は、%%sql マジック コマンドを使用して Delta テーブルを作成します。
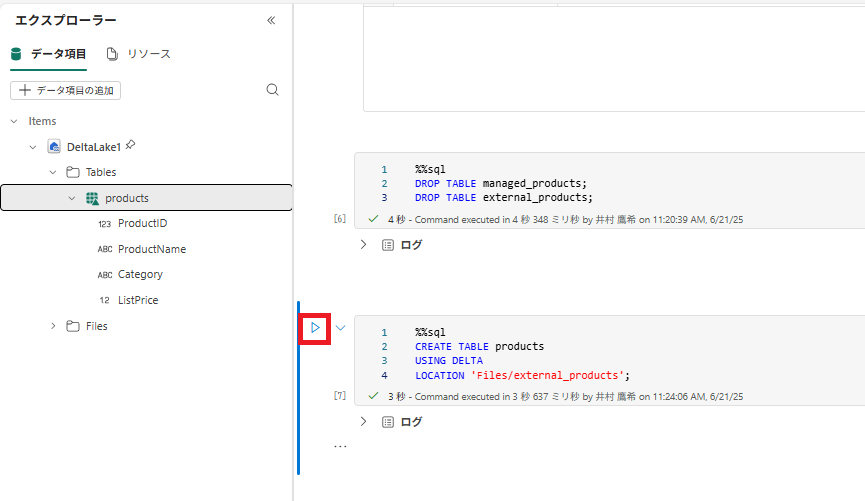
1 . 別のコード セルを追加し、次のコードを実行します。
%%sql
CREATE TABLE products
USING DELTA
LOCATION 'Files/external_products';
2 . [Tables] フォルダーの […] メニューにある [最新の情報に更新] を選択します。 次に、[Tables] ノードを展開し、[products] という名前の新しいテーブルが表示されていることを確認します。 そして、テーブルを展開してスキーマを表示します。
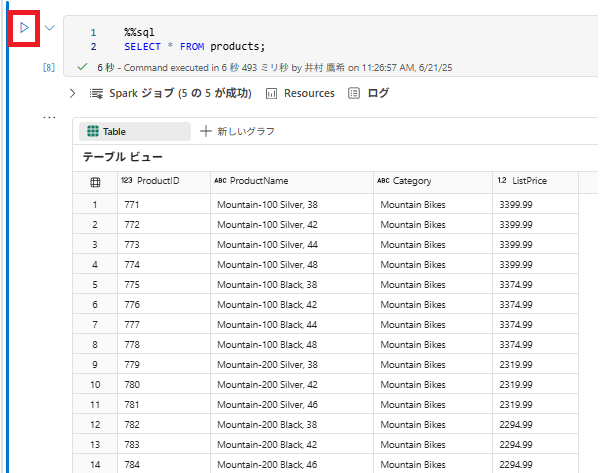
3 . 別のコード セルを追加し、次のコードを実行します。
%%sql
SELECT * FROM products;
3-6 テーブルのバージョン管理を調べる
Delta テーブルのトランザクション履歴は、delta_log フォルダー内の JSON ファイルに格納されます。 このトランザクション ログを使用して、データのバージョンを管理できます。
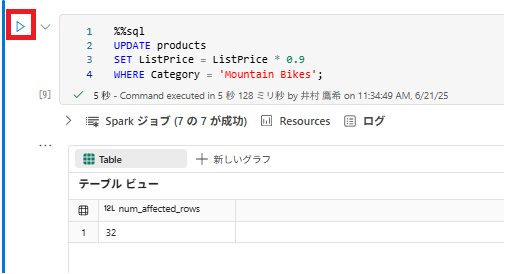
1 . ノートブックに新しいコード セルを追加し、マウンテン バイクの価格を 10% 値下げする次のコードを実行します。
%%sql
UPDATE products
SET ListPrice = ListPrice * 0.9
WHERE Category = 'Mountain Bikes';
2 . 別のコード セルを追加し、次のコードを実行します。
%%sql
DESCRIBE HISTORY products;

結果には、テーブルに関して記録されたトランザクションの履歴が表示されます。
3 . 別のコード セルを追加し、次のコードを実行します。
delta_table_path = 'Files/external_products'
# Get the current data
current_data = spark.read.format("delta").load(delta_table_path)
display(current_data)
# Get the version 0 data
original_data = spark.read.format("delta").option("versionAsOf", 0).load(delta_table_path)
display(original_data)
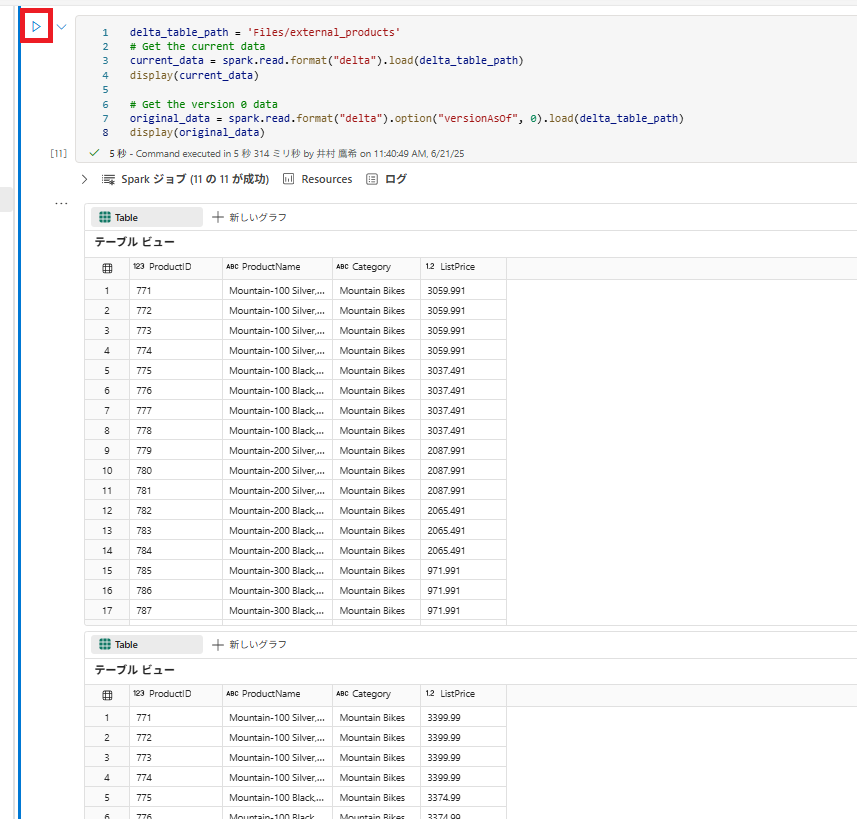
2 つの結果セットが返されます。1 つは値下げ後のデータが入っており、もう 1 つはデータの元のバージョンが表示されます。
3-7 SQL クエリを使用してデルタ テーブルのデータを分析する
SQL マジック コマンドを使用すると、Pyspark の代わりに SQL 構文を使用できます。 ここでは、SELECT ステートメントを使用して、製品テーブルから一時ビューを作成します。
1 . 新しいコード セルを追加し、次のコードを実行して、一時ビューを作成および表示します。
%%sql
-- Create a temporary view
CREATE OR REPLACE TEMPORARY VIEW products_view
AS
SELECT Category, COUNT(*) AS NumProducts, MIN(ListPrice) AS MinPrice, MAX(ListPrice) AS MaxPrice, AVG(ListPrice) AS AvgPrice
FROM products
GROUP BY Category;
SELECT *
FROM products_view
ORDER BY Category;
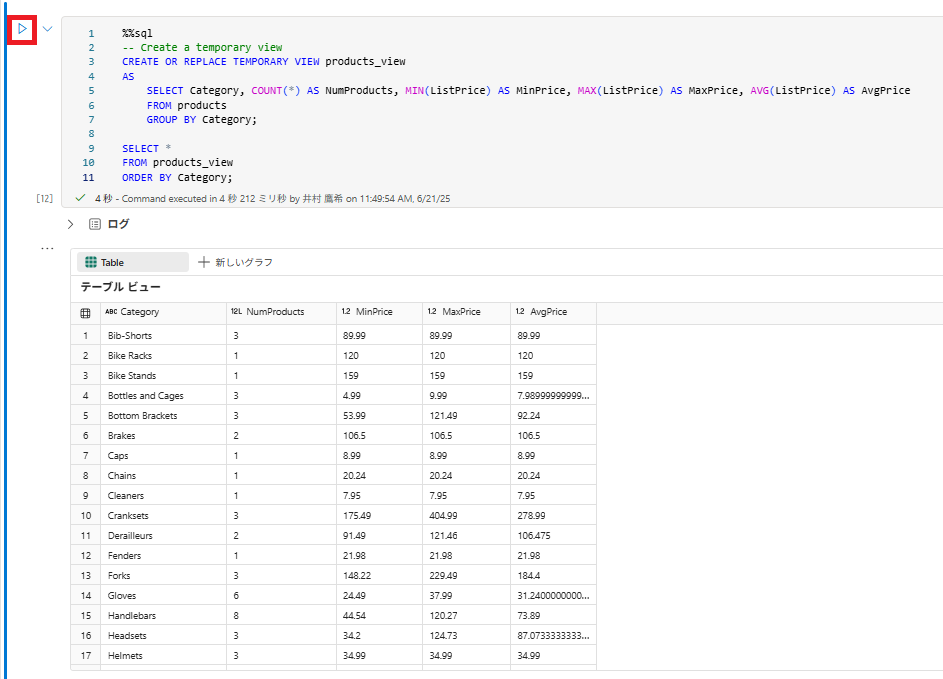
2 . 新しいコード セルを追加し、次のコードを実行して、製品の数で上位 10 のカテゴリを返します。
%%sql
SELECT Category, NumProducts
FROM products_view
ORDER BY NumProducts DESC
LIMIT 10;
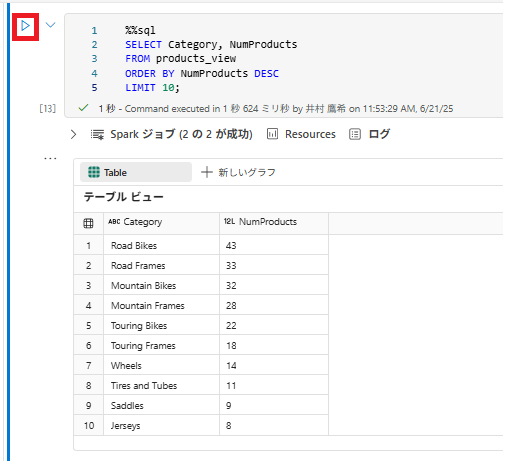
3 . データが返されたら、 [+ 新しいグラフ] を押下して棒グラフを表示します。
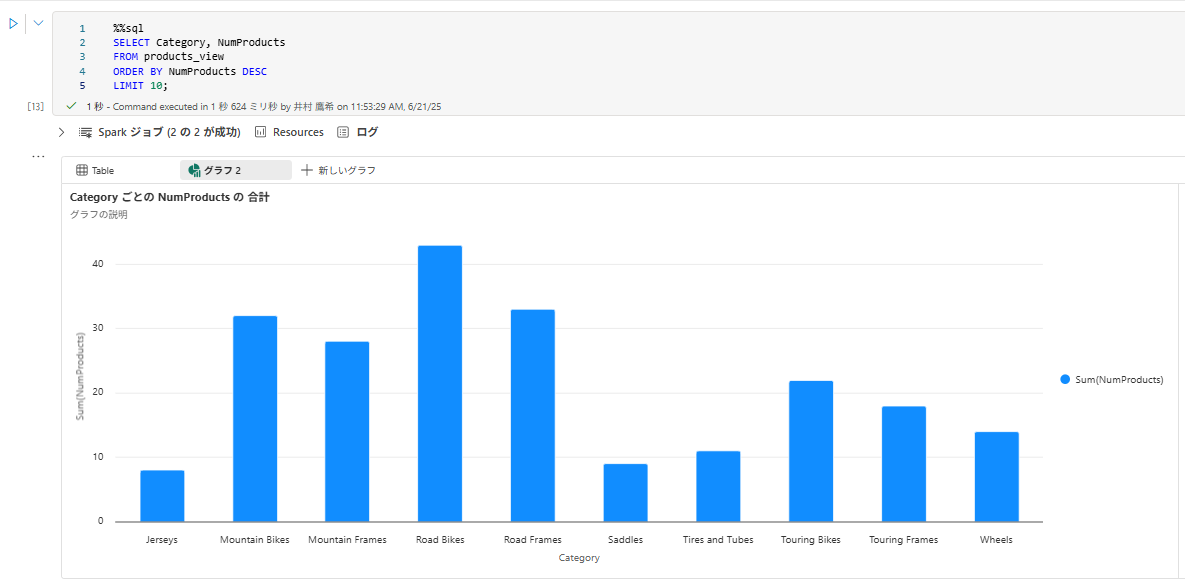
または、PySpark を使用して SQL クエリを実行することもできます。
4 . 新しいコード セルを追加し、次のコードを実行します。
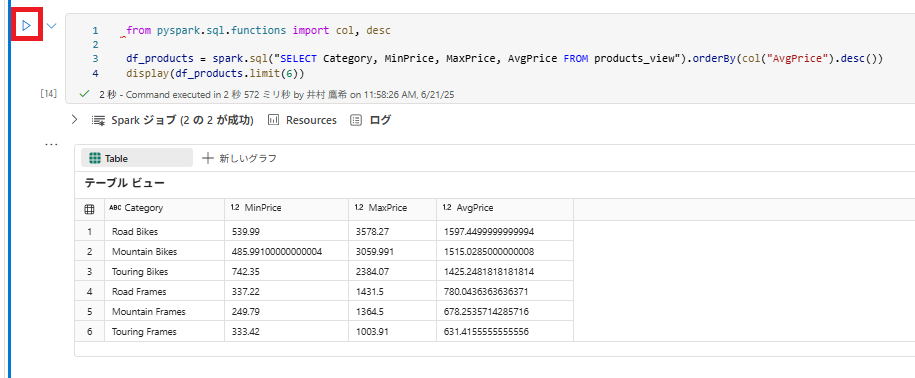
from pyspark.sql.functions import col, desc
df_products = spark.sql("SELECT Category, MinPrice, MaxPrice, AvgPrice FROM products_view").orderBy(col("AvgPrice").desc())
display(df_products.limit(6))
3-8 ストリーミング データに Delta テーブルを使用する
Delta Lake ではストリーミング データがサポートされています。 デルタ テーブルは、Spark 構造化ストリーミング API を使用して作成されたデータ ストリームの “シンク” または “ソース” に指定できます。
この例では、モノのインターネット (IoT) のシミュレーション シナリオで、一部のストリーミング データのシンクに Delta テーブルを使用します。
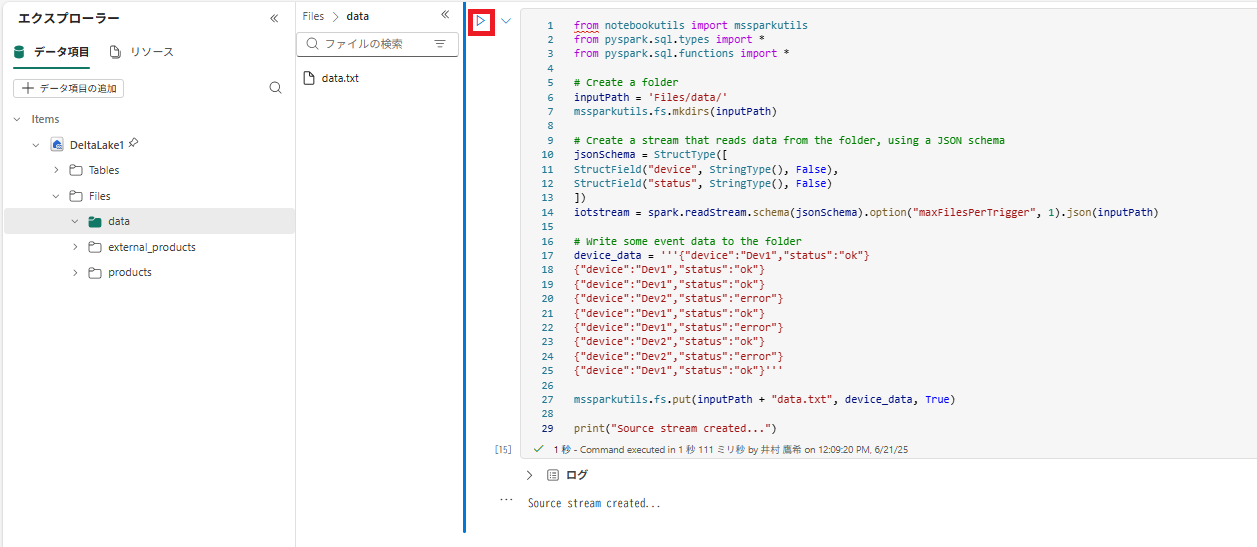
1 . 新しいコード セルを追加し、次のコードを追加して、実行します。
from notebookutils import mssparkutils
from pyspark.sql.types import *
from pyspark.sql.functions import *
# Create a folder
inputPath = 'Files/data/'
mssparkutils.fs.mkdirs(inputPath)
# Create a stream that reads data from the folder, using a JSON schema
jsonSchema = StructType([
StructField("device", StringType(), False),
StructField("status", StringType(), False)
])
iotstream = spark.readStream.schema(jsonSchema).option("maxFilesPerTrigger", 1).json(inputPath)
# Write some event data to the folder
device_data = '''{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev2","status":"error"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"error"}
{"device":"Dev2","status":"ok"}
{"device":"Dev2","status":"error"}
{"device":"Dev1","status":"ok"}'''
mssparkutils.fs.put(inputPath + "data.txt", device_data, True)
print("Source stream created...")
メッセージ「Source stream created…」が表示されることを 確認します。 先ほど実行したコードによって、一部のデータが保存されているフォルダーに基づいてストリーミング データ ソースが作成されました。これは、架空の IoT デバイスからの読み取り値を表しています。
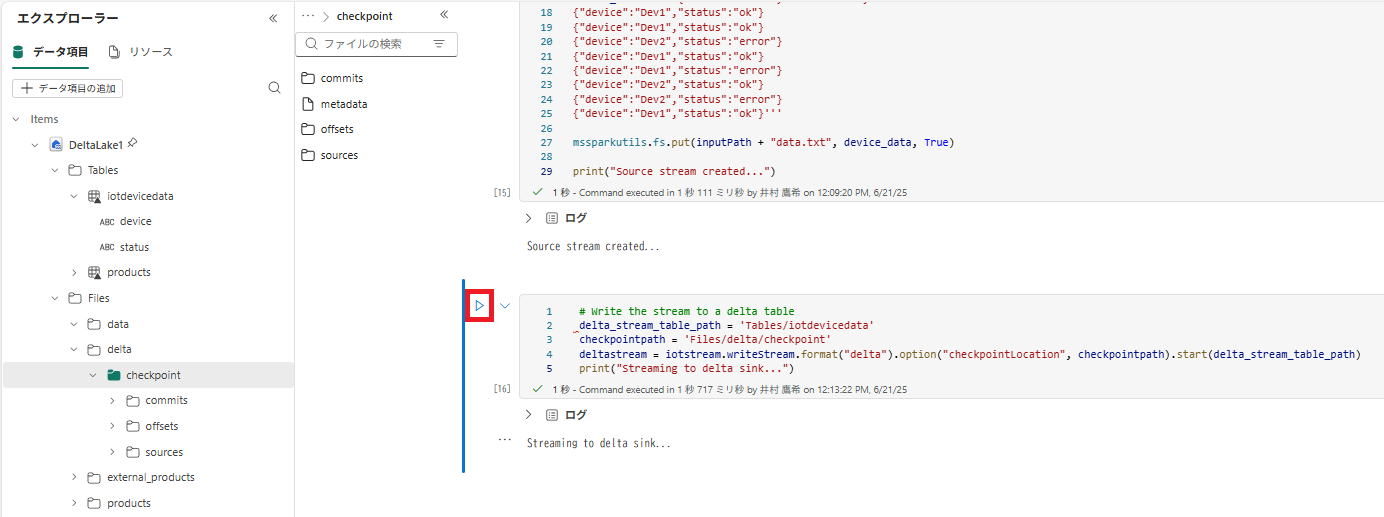
2 . 新しいコード セルに、次のコードを追加して実行します。
# Write the stream to a delta table
delta_stream_table_path = 'Tables/iotdevicedata'
checkpointpath = 'Files/delta/checkpoint'
deltastream = iotstream.writeStream.format("delta").option("checkpointLocation", checkpointpath).start(delta_stream_table_path)
print("Streaming to delta sink...")
このコードは、[iotdevicedata] という名前のフォルダーに、ストリーミング デバイス データを差分形式で書き込みます。 このフォルダーの場所を示すパスは [Tables] フォルダー内であるため、テーブルは自動的に作成されます。
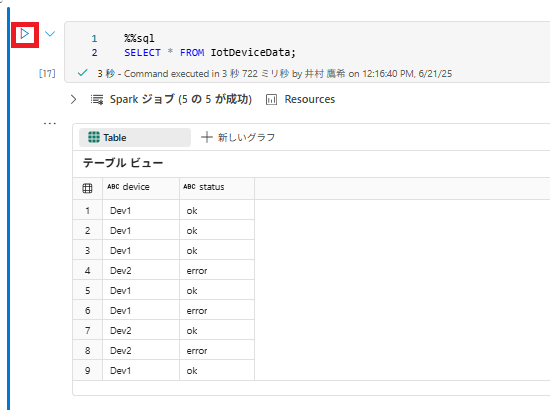
3 . 新しいコード セルに、次のコードを追加して実行します。
%%sql
SELECT * FROM IotDeviceData;
このコードを実行して、ストリーミング ソースのデバイス データが含まれる IotDeviceData テーブルに対してクエリを実行します。
4 . 新しいコード セルに、次のコードを追加して実行します。
# Add more data to the source stream
more_data = '''{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"ok"}
{"device":"Dev1","status":"error"}
{"device":"Dev2","status":"error"}
{"device":"Dev1","status":"ok"}'''
mssparkutils.fs.put(inputPath + "more-data.txt", more_data, True)
このコードを実行して、さらに架空のデバイス データをストリーミング ソースに書き込みます。
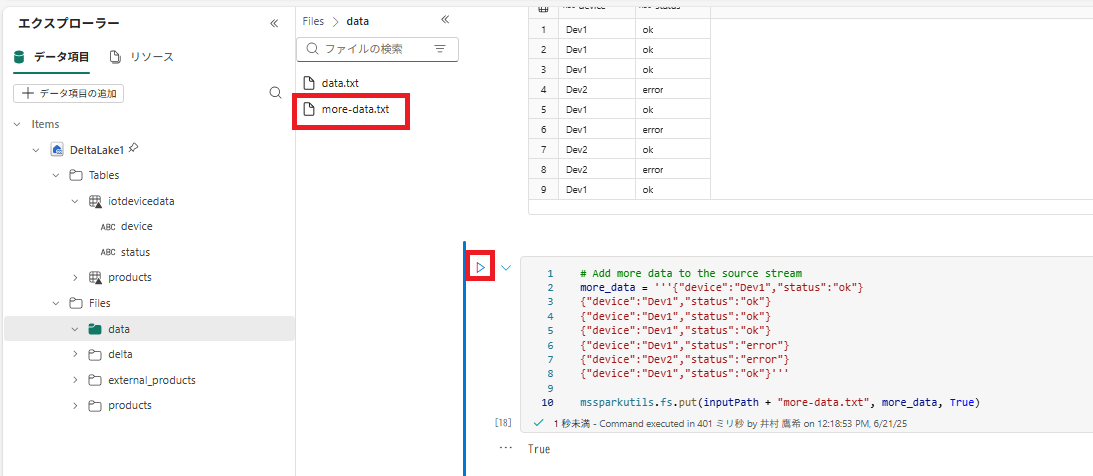
5 . 次のコードを含むセルを再実行します。
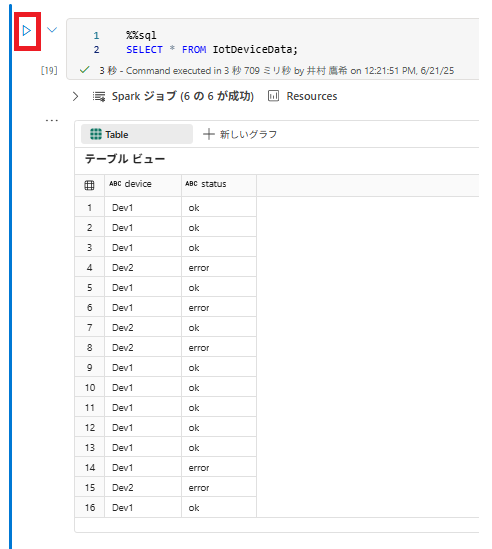
%%sql
SELECT * FROM IotDeviceData;
このコードを実行して、IotDeviceData テーブルに対してもう一度クエリを実行します。今度は、ストリーミング ソースに追加された追加データが含まれます。
6 . 新しいコード セルに、ストリームを停止するコードを追加して、セルを実行します。
deltastream.stop()
以上で演習は終了になります。
この演習では、Microsoft Fabric で Delta テーブルを操作する方法を学習しました。
3-9 リソースをクリーンアップする
1 . 【Azure】Microsoft Fabric レイクハウス内にあるファイルとテーブルにデータを取り込む。(3-7 リソースをクリーンアップする)をご参照ください。
以上でワークスペースが削除されます。お疲れ様でした!
本演習を通じて Microsoft Fabric の演習 が一覧化されていることを初めて知りましたので共有致します。