はじめに
夏休み前に,Transformer, BERTを一から勉強し直したこともあって,実際に試してみたいなと思っていたら,ちょうど良さげなコンペ(SIGNATE Student Cup 2020)があって参加していました.
提出した結果を見てみると,BERTをfine-tuningしただけのモデルでも,最終順位50位に入れるくらいの結果が出ていたので,復習も兼ねて簡単にまとめられたらと思い,記事を書くことにしました.
最終順位は色々あって,かなり低くなってしまいました.その辺りのコンペの感想や他に試した手法などについては,はてなブログにSIGNATE Student Cup 2020参加レポートとして書きました.
SIGNATE Student Cup 2020 [予測部門] 参加レポート
Transformer, BERTは,論文と「つくりながら学ぶ!PyTorchによる発展ディープラーニング」を読んで勉強し直したこともあって,実装は「PyTorchでBERTなど各種DLモデルを作りながら学ぶ書籍を執筆しました」の記事中にあるGitHubリポジトリで公開しているものを使わせていただきました.
GitHubリポジトリのリンク↓
https://github.com/YutaroOgawa/pytorch_advanced
環境
Jupyter Notebook
GPUは使わず,今回はCPUを使用
(一応,GPUでも動くようにコード書いてますが,試してないのでGPUでも動く保証はないです)
ノートパソコン
- MacBook Air (13-inch, Mid 2013)
- macOS Catalina ver10.15.4
- プロセッサ: 1.3 GHz デュアルコアIntel Core i5
- メモリ: 4 GB 1600 MHz DDR3
python関係
python 3.7.7
torch 1.5.0
torchtext 0.5.0
scikit-learn 0.21.3
tqdm 4.48.2
numpy 1.17.2
ディレクトリ構造
GitHubにあるmake_folders_and_data_downloads.ipynbを参考にしました.
make_folders_and_data_downloads.ipynb
import os
import urllib.request
import zipfile
import tarfile
import glob
import io
ディレクトリ「data」,「vocab」,「weights」が存在しない場合は作成
data_dir = "./data/"
if not os.path.exists(data_dir):
os.mkdir(data_dir)
vocab_dir = "./vocab/"
if not os.path.exists(vocab_dir):
os.mkdir(vocab_dir)
weights_dir = "./weights/"
if not os.path.exists(weights_dir):
os.mkdir(weights_dir)
単語集:ボキャブラリーをダウンロード
save_path="./vocab/bert-base-uncased-vocab.txt"
url = "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt"
urllib.request.urlretrieve(url, save_path)
BERTの学習済みモデルのダウンロード&解凍
# ダウンロード
save_path = "./weights/bert-base-uncased.tar.gz"
url = "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz"
urllib.request.urlretrieve(url, save_path)
# 解凍
archive_file = "./weights/bert-base-uncased.tar.gz"
tar = tarfile.open(archive_file, 'r:gz')
tar.extractall('./weights/')
tar.close()
データセットは,SIGNATE Student Cup 2020からダウンロードし,ディレクトリ「data」に置く.(train.csv, test.csv, submit_sample.csv)
train.csvは「id(int)」,「description(str)」,「jobflag(int)」をカラムに持つ.
test.csvは「id(int)」,「description(str)」をカラムに持つ.
submit_sample.csvは,1列目に評価用データの"id",2列目に"職種 (1 or 2 or 3 or 4)"がランダムに記入されているヘッダ無しのcsv.test.csvとidの順番が一致している.
https://github.com/YutaroOgawa/pytorch_advanced/tree/master/8_nlp_sentiment_bert/utils
から「utils」をダウンロードする.
以下のようなディレクトリ構造となる.(太字がディレクトリ)
signate
--bert.ipynb
--make_folders_and_data_downloads.ipynb
--data
--vocab
--weights
--utils
SIGNATE Student Cup 2020の概要
タスク説明
英語圏の求人情報に含まれるテキストデータ(職務内容に関する記述)をもとに,その職務内容が
①データサイエンティスト(DS)
②機械学習エンジニア(ML Engineer)
③ソフトウェアエンジニア(Software Engineer)
④コンサルタント(Consultant)
のどの職種に該当するものかを判別
英語圏の求人情報であるため,テキストデータは英語.
テキストを用いた4値分類.
学習データは2931あるが,テキストが短いものが多いと感じた.
また,学習データのラベルが不均衡.(1: 624, 2: 348, 3: 1376, 4: 583)
評価はF1Score(Macro).
bert.ipynb
8-4_bert_IMDb.ipynbを参考にしました.
とりあえず,使いそうなモジュールのimportとseedの設定
import random
import time
import numpy as np
import math
from tqdm import tqdm
import torch
from torch import nn
import torch.optim as optim
import torchtext
from sklearn.metrics import f1_score
import pandas as pd
import re
import string
from utils.bert import BertTokenizer
seed = 42
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
データの読み込み&前処理
前処理のための関数
def preprocessing_text(text):
'''前処理'''
# 改行コードを消去
text = re.sub('<br />', '', text)
# カンマ、ピリオド以外の記号をスペースに置換
for p in string.punctuation:
if (p == ".") or (p == ","):
continue
else:
text = text.replace(p, " ")
# ピリオドなどの前後にはスペースを入れておく
text = text.replace(".", " . ")
text = text.replace(",", " , ")
return text
# 単語分割用のTokenizerを用意
tokenizer_bert = BertTokenizer(
vocab_file="./vocab/bert-base-uncased-vocab.txt", do_lower_case=True)
# 前処理と単語分割をまとめた関数を定義
def tokenizer_with_preprocessing(text, tokenizer=tokenizer_bert.tokenize):
text = preprocessing_text(text)
ret = tokenizer(text) # tokenizer_bert
return ret
データを読み込んだときに、読み込んだ内容に対して行う処理を定義
max_length = 256
TEXT = torchtext.data.Field(sequential=True, tokenize=tokenizer_with_preprocessing, use_vocab=True,
lower=True, include_lengths=True, batch_first=True, fix_length=max_length, init_token="[CLS]", eos_token="[SEP]", pad_token='[PAD]', unk_token='[UNK]')
LABEL = torchtext.data.Field(sequential=False, use_vocab=False)
ID = torchtext.data.Field(sequential=False, use_vocab=False)
「data」から各csvファイルを読み込み
train_val_ds, test_ds = torchtext.data.TabularDataset.splits(
path='./data/', train='original_train.csv',
test='original_test.csv', format='csv',
skip_header=True,
fields=[('Id', ID), ('Text', TEXT), ('Label', LABEL)])
train_ds, val_ds = train_val_ds.split(
split_ratio=0.9, random_state=random.seed(seed))
辞書をBERT用のものに変更
(そのため訓練データからボキャブラリーは作成しない)
from utils.bert import BertTokenizer, load_vocab
vocab_bert, ids_to_tokens_bert = load_vocab(
vocab_file="./vocab/bert-base-uncased-vocab.txt")
TEXT.build_vocab(train_ds, min_freq=1)
TEXT.vocab.stoi = vocab_bert
DataLoaderを作成
batch_size = 32 # BERTでは16、32あたりを使用するらしいです
train_dl = torchtext.data.Iterator(
train_ds, batch_size=batch_size, train=True)
val_dl = torchtext.data.Iterator(
val_ds, batch_size=batch_size, train=False, sort=False)
test_dl = torchtext.data.Iterator(
test_ds, batch_size=batch_size, train=False, sort=False)
dataloaders_dict = {"train": train_dl, "val": val_dl}
事前学習済みのBERTモデルを読み込みパラメータをセット
from utils.bert import get_config, BertModel, set_learned_params
config = get_config(file_path="./weights/bert_config.json")
net_bert = BertModel(config)
net_bert = set_learned_params(
net_bert, weights_path="./weights/pytorch_model.bin")
[CLS]の特徴量を使用して、多値分類できるように層と活性化関数を追加したモデルを作成
・活性化関数はgelu使ってみました
・768次元を一気に4次元に落とすのが気になったので,層を二層にしてみました
def gelu(x):
'''Gaussian Error Linear Unitという活性化関数です。
LeLUが0でカクっと不連続なので、そこを連続になるように滑らかにした形のLeLUです。
'''
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
class BertForClassify(nn.Module):
def __init__(self, net_bert):
super(BertForClassify, self).__init__()
# BERTモジュール
self.bert = net_bert # BERTモデル
# 入力はBERTの出力特徴量の次元、出力は1:Data scientist, 2:Machine learning engineer, 3:Software engineer, 4:Consultantの4つ
self.cls1 = nn.Linear(in_features=768, out_features=64)
self.cls2 = nn.Linear(in_features=64, out_features=4)
# 重み初期化処理
nn.init.normal_(self.cls1.weight, std=0.02)
nn.init.normal_(self.cls1.bias, 0)
nn.init.normal_(self.cls2.weight, std=0.02)
nn.init.normal_(self.cls2.bias, 0)
self.dropout = nn.Dropout(0.1)
# 活性化関数gelu
self.intermediate_act_fn = gelu
def forward(self, input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=False, attention_show_flg=False):
'''
input_ids: [batch_size, sequence_length]の文章の単語IDの羅列
token_type_ids: [batch_size, sequence_length]の、各単語が1文目なのか、2文目なのかを示すid
attention_mask:Transformerのマスクと同じ働きのマスキングです
output_all_encoded_layers:最終出力に12段のTransformerの全部をリストで返すか、最後だけかを指定
attention_show_flg:Self-Attentionの重みを返すかのフラグ
'''
# BERTの基本モデル部分の順伝搬
# 順伝搬させる
if attention_show_flg == True:
'''attention_showのときは、attention_probsもリターンする'''
encoded_layers, pooled_output, attention_probs = self.bert(
input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg)
elif attention_show_flg == False:
encoded_layers, pooled_output = self.bert(
input_ids, token_type_ids, attention_mask, output_all_encoded_layers, attention_show_flg)
# 入力文章の1単語目[CLS]の特徴量を使用して、多値分類
vec_0 = encoded_layers[:, 0, :]
vec_0 = self.dropout(vec_0.view(-1, 768)) # sizeを[batch_size, hidden_sizeに変換
hidden = self.cls1(vec_0)
out = self.cls2(self.intermediate_act_fn(self.dropout(hidden)))
# attention_showのときは、attention_probs(1番最後の)もリターンする
if attention_show_flg == True:
return out, attention_probs, hidden
elif attention_show_flg == False:
return out, hidden
モデル構築&訓練モードに設定
net = BertForClassify(net_bert)
net.train()
print('ネットワーク設定完了')
学習させるパラメータを決める
・CPU環境でのfine-tuningのため,BertLayerの最終層と追加した分類のための2層を学習させることにさせました.
・今回のコンペでは,もう少し深く学習させるべきだったかもしれませんが,これでもそれなりの結果が出ました.
# 1. まず全部を、勾配計算Falseにしてしまう
for name, param in net.named_parameters():
param.requires_grad = False
# 2. 最後のBertLayerモジュールを勾配計算ありに変更
for name, param in net.bert.encoder.layer[-1].named_parameters():
param.requires_grad = True
# 3. 識別器を勾配計算ありに変更
for name, param in net.cls1.named_parameters():
param.requires_grad = True
for name, param in net.cls2.named_parameters():
param.requires_grad = True
GPUが使えるかを確認
最適化手法の設定
損失関数の設定
・不均衡データであるため,損失関数にweightを与えた
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
optimizer = optim.Adam([
{'params': net.bert.encoder.layer[-1].parameters(), 'lr': 5e-5},
{'params': net.cls1.parameters(), 'lr': 5e-5},
{'params': net.cls2.parameters(), 'lr': 5e-5}
], betas=(0.9, 0.999))
weights = np.array([0, 0, 0, 0])
for example in train_ds:
weights[int(example.Label) - 1] += 1
weights = 1 / weights
weights /= np.sum(weights)
weights = torch.tensor(weights, dtype=torch.float32, device=device)
criterion = nn.CrossEntropyLoss(weight=weights)
モデルを学習させる関数を作成
def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用デバイス:", device)
print('-----start-------')
net.to(device)
torch.backends.cudnn.benchmark = True
batch_size = dataloaders_dict["train"].batch_size
for epoch in range(num_epochs):
for phase in ['train', 'val']:
if phase == 'train':
net.train()
else:
net.eval()
epoch_loss = 0.0
epoch_corrects = 0
iteration = 1
# macro_f1
predlist=torch.zeros(0, dtype=torch.long, device='cpu')
lbllist=torch.zeros(0, dtype=torch.long, device='cpu')
t_epoch_start = time.time()
t_iter_start = time.time()
for batch in (dataloaders_dict[phase]):
inputs = batch.Text[0].to(device)
labels = batch.Label.to(device)
labels -=
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs, hidden = net(inputs, token_type_ids=None, attention_mask=None,
output_all_encoded_layers=False, attention_show_flg=False)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward()
optimizer.step()
if (iteration % 10 == 0):
t_iter_finish = time.time()
duration = t_iter_finish - t_iter_start
acc = (torch.sum(preds == labels.data)
).double()/batch_size
print('イテレーション {} || Loss: {:.4f} || 10iter: {:.4f} sec. || 本イテレーションの正解率:{}'.format(
iteration, loss.item(), duration, acc))
# print(preds[0:10])
t_iter_start = time.time()
iteration += 1
epoch_loss += loss.item() * batch_size
epoch_corrects += torch.sum(preds == labels.data)
# macro_f1
predlist=torch.cat([predlist,preds.detach().view(-1).cpu()])
lbllist=torch.cat([lbllist,labels.view(-1).cpu()])
t_epoch_finish = time.time()
epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)
epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset)
print('Epoch {}/{} | {:^5} | Loss: {:.4f} Acc: {:.4f}'.format(epoch+1, num_epochs,
phase, epoch_loss, epoch_acc))
# macro_f1
print('Macro_f1 {:^5}'.format(f1_score(lbllist, predlist, average='macro')))
t_epoch_start = time.time()
return net
学習・検証を実行
num_epochs = 10
net_trained = train_model(net, dataloaders_dict,criterion, optimizer, num_epochs=num_epochs)
出力例
使用デバイス: cpu
-----start-------
イテレーション 10 || Loss: 1.4068 || 10iter: 471.4296 sec. || 本イテレーションの正解率:0.4375
イテレーション 20 || Loss: 1.4239 || 10iter: 427.7281 sec. || 本イテレーションの正解率:0.40625
:
イテレーション 80 || Loss: 1.3781 || 10iter: 388.2995 sec. || 本イテレーションの正解率:0.34375
イテレーション 90 || Loss: 1.3696 || 10iter: 377.9352 sec. || 本イテレーションの正解率:0.3125
Epoch 1/10 | train | Loss: 1.3952 Acc: 0.2955
Macro_f1 0.25144529676014216
:
学習したネットワークパラメータを保存
・実際には,関数train_modelに,エポックごとに保存できるようにして,良さげなものを後からロードし直して,予測に使っていました.
save_path = './weights/bert_fine_tuning.pth'
torch.save(net_trained.state_dict(), save_path)
テストデータの予測
pred_label_list = torch.zeros(0, dtype=torch.long, device='cpu')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net_trained.eval()
net_trained.to(device)
for batch in tqdm(test_dl):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
inputs = batch.Text[0].to(device)
with torch.set_grad_enabled(False):
outputs, hidden = net_trained(inputs, token_type_ids=None, attention_mask=None,
output_all_encoded_layers=False, attention_show_flg=False)
_, preds = torch.max(outputs, 1)
pred_label_list = torch.cat([pred_label_list,preds.detach().view(-1).cpu()])
提出ファイルを作成
sub_df = pd.read_csv('./data/submit_sample.csv', header=None)
sub_df[1] = np.array(pred_label_list) + 1
sub_df.to_csv('./data/submit.csv', header=False, index=False)
結果
一番最初に,10エポック学習させたものを提出したのですが,public score private scoreともに良好な結果が得られてました.
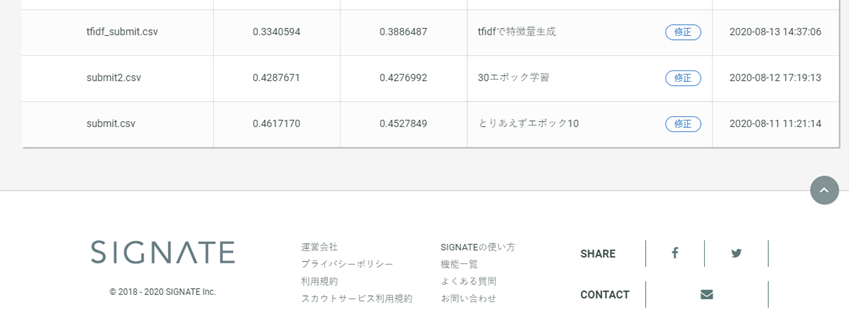
この結果だけでも,最終順位50位くらいなので,BERTすごいなと実感しました.
おわりに
自分自身,BERT使うのにハードルを感じていたのですが,とりあえず動かすだけであれば,半日くらいで実装できたので,これから使ってみたい人に,この記事が少しでも役に立ったらいいなと思っています.
詳しく学びたい方は,「つくりながら学ぶ!PyTorchによる発展ディープラーニング」がとても参考になったので,ぜひ購入して読んでみてください!
他にも隙間時間で試したいくつかの手法や,最終的に弱弱なスコアを提出することになった理由などは,はてなブログに書いてあります.
SIGNATE Student Cup 2020 [予測部門] 参加レポート
最後まで記事を読んでいただきありがとうございました.