
はじめに
4月26日に「Re:ゼロから始めるweb開発 (GAS使用) Part0」を投稿しましたが,現状すぐに作りたいものがなかったので,GASの練習も兼ねて,簡単なスクレイピング処理を書いてみました.
普段はpythonのプログラム書いて,cronで定期実行することでスクレイピングしていて不自由は感じていなかったのですが,パソコンの電源をずっとつけておかないといけないため,自宅のパソコンずっとつけっぱなしなのは嫌なので,GAS使ってやってみようかなと思いました.
GASについて
GASについてや,メリットに関しては,「Re:ゼロから始めるweb開発 (GAS使用) Part0」ですでに書いたので,そちらを見てもらえたと思います.
GASによるwebスクレイピングのアウトライン
- データの保存先となるGoogleSpreadSheetを作成
- スクリプトファイルを作成し,いろいろ書いて保存
- 関数を定期実行するためにトリガーを設定
とりあえず,ざっくりこんな感じです.
GoogleSpreadSheetを作成
まずは,グーグルドライブ開いて,新規作成を押して,新しくGoogleスプレッドシートを作成しましょう.
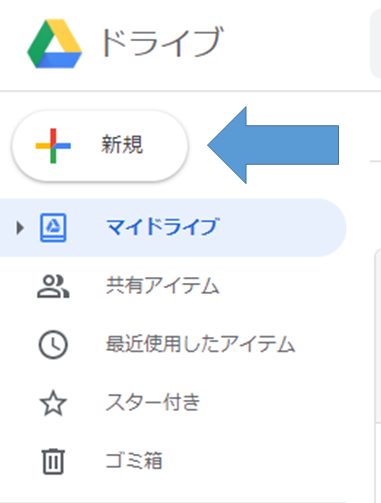
名前は何でもいいと思います.適当に「****DataBase」とかつけておくといいかなと思います.
今回の紹介では,ニュース記事の「タイトル」「本記事へのURL」「公開日時」を取得しようと思うので,下の画像のような感じにheaderを作りました.
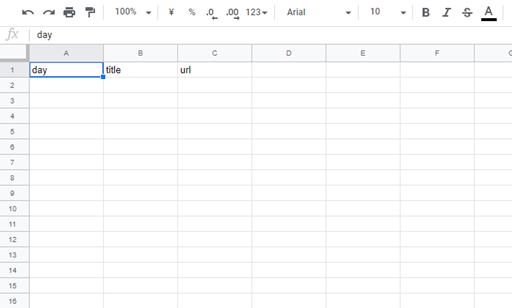
いろいろ細かい処理をしようとするならば,管理用のシートとか作るべきですが,とりあえず最初はこれだけ作っておけば大丈夫です.
スクリプトファイルを作成
「ツール」→「スクリプトエディタ」を選択すれば作成できます.
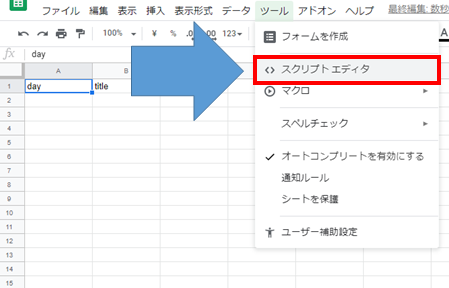
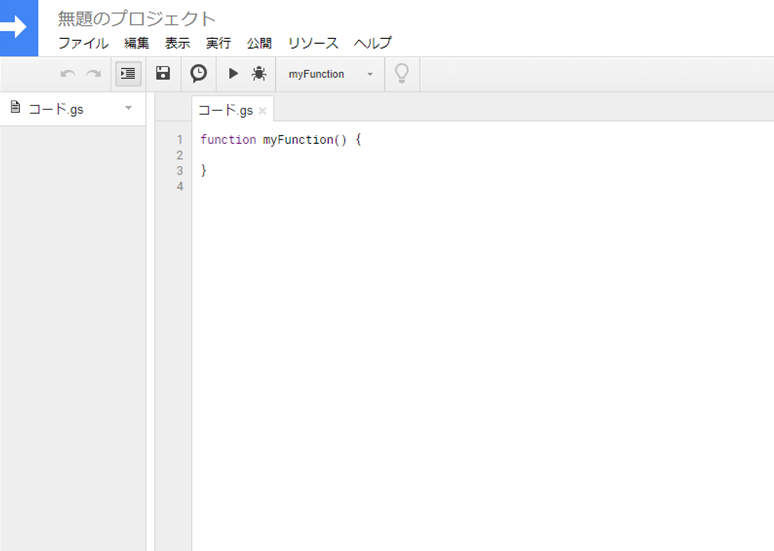
このような画面が開けば大丈夫です.
html情報の取得
まず,html情報を取得する必要がありますが,GASではUrlFetchApp.fetch("URL")で簡単に対象リンクのhtmlの情報を取得することができます.
var getUrl = "ここに対象としたいurlを入れる";
var html = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
}
これだけで大丈夫なので,ここでつまずくことはないかなと思います.
(注意書き)
webスクレイピングが禁止されているサイトも多いので,禁止されているページは対象にしないようにしましょう.
また,禁止されていなくても,実行時間の間隔をおいたりするなどして,サイトに対して負担がかからないようしましょう.
繰り返し文など使ったりしてると,意図せず連続してアクセスしてしまったりするため,for文の間にスリープ関数入れたり,実装している間は3周程度にして,問題がないか確認しながら進めましょう.
ネチケットを守ることが大事ですね.
html情報から抽出したい情報を抽出
普段なら正規表現でゴリゴリ書いていくのですが,今回は適当にライブラリ使って,簡略化して書きました.
使ったパッケージはParserです.
「Easy data scraping with Google Apps Script in 5 minutes」の記事で紹介されてたので,とりあえず使ってみました(簡単な抽出であれば十分).
まずは,パッケージのインストールですが,「リソース」→「ライブラリ」を選択すると以下のウィンドウが出ます.
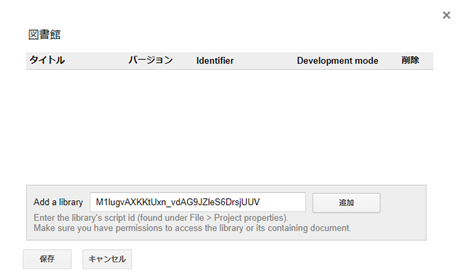
図の「Add a library」と同様にM1lugvAXKKtUxn_vdAG9JZleS6DrsjUUVをコピーしてペーストしてから追加を押してください.
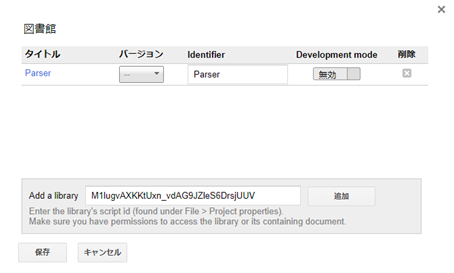
そうすると,ライブラリにParserが追加されるので,バージョンは「7」を選択し,保存を押せば完了です.
これで,Parserが使えるようになりました.
Parserは以下のようにコードを書くことで情報を抽出できます.
var data = Parser.data(html).from('<li>').to('</li>').build();
var data_list = Parser.data(html).from('<li>').to('</li>').iterate();
}
「GASで簡単WEBスクレイピング!HTMLを簡単にパースできるライブラリParserを使ってみた」という記事で使い方の例がわかりやすく載ってました.
簡単に言えば,"
.build()であれば,一番最初にヒットするもののみ取得することができ,.iterate()であれば,リスト形式で全て取得することができます.
今回自分は,ニュース記事の一覧ページから,「タイトル」「本記事へのURL」「公開日時」を複数取得したいので.iterate()を使いました.
データをスクレイピングし,GoogleSpreadSheetに書き込む
このあたりはGASにGoogleSpreadSheetを操作するための記事がいくらでもあるので,説明は省略します.
@ryan5500 さんの「GASでSpreadsheetを操作する自分的ベストプラクティス」とか,細かくいろいろ載ってるので参考にしてみてください.
「Re:ゼロから始めるweb開発 (GAS使用)」の続編書くときには,自分もちゃんと説明入れます.
とりあえずのコード.
function get_title_link() {
// 対象ページのURL
var getUrl = 'https://****************';
// htmlをテキスト情報にして抽出
var html = UrlFetchApp.fetch(getUrl).getContentText('UTF-8');
// ニュースのタイトルを抽出
var title_list = Parser.data(html).from('<div class="newsFeed_item_title">').to('</div>').iterate();
// ニュースの公開された時間を抽出
var time_list = Parser.data(html).from('<time class="newsFeed_item_date">').to('</time>').iterate();
// 記事へのリンクを抽出
var url_list = Parser.data(html).from('<a class="newsFeed_item_link" href="').to('" data-ylk="').iterate();
// シートの指定.GoogleスプレッドシートのURLの「https://docs.google.com/spreadsheets/d/***************************************/edit#gid=0」の部分を使う.
var spreadsheet = SpreadsheetApp.openById('***************************************');
// シート1をスポーツに命名(スポーツニュースのみに絞ってスクレイピング)
var sheet = spreadsheet.getSheetByName('スポーツ');
// 最終行を取得
var lastrow = sheet.getLastRow();
// 書き込む行は最終行の次の行から
var recordrow = lastrow + 1;
// 過去の記録を確認
var oldurl_list = [];
var start = 2;
if (lastrow > 26){
start = lastrow - 25;
}
for(var i = start; i <= lastrow; i++){
oldurl_list.push(sheet.getRange("C" + i).getValue());
}
for(var i = url_list.length-1; i >= 0; i--){
if(oldurl_list.indexOf(url_list[i]) == -1){
sheet.getRange("A" + recordrow).setValue(time_list[i]);
sheet.getRange("B" + recordrow).setValue(title_list[i]);
sheet.getRange("C" + recordrow).setValue(url_list[i]);
recordrow++;
}
}
}
少しちょっとした工夫もしていますが,簡単に紹介します.
まず,書き込むGoogleスプレッドシートを指定する必要がありますが,これはGoogleスプレッドシートのURLのhttps://docs.google.com/spreadsheets/d/****************/edit#gid=0 のアスタリスク部分で特定することができます.
「d/」と「/edit」の間ですね.
Parser使って,リストで「タイトル」「公開日時」「記事へのリンク」を取得しています.
1pageあたりに表示される記事が25記事で,半日に一回プログラムを実行する予定ですが,半日で対象としているサイトのスポーツ記事は25記事以上増えないので,重複して保存しないように,過去に取得したリンクを,一度シートから取得し,重複しないもののみ,新たにシートに書き込んでいます.
また,抽出先のページは新しい記事が上に来るため,for文を後ろからまわすことで,最新のものが一番最後に追加されるようになってます.
抽出した結果はこんな感じになります.
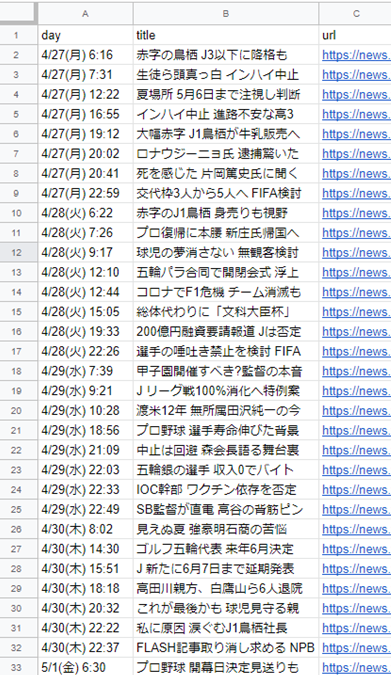
非常にいい感じです.
このリンクをさらに対象にし,ニュースの本文もとれるようにしているので,今後いろいろ解析ができそうで楽しみです.
トリガーの設定
毎日,手動で関数を実行するのは馬鹿らしいので,トリガーを設定して,関数を毎日10時と22時に自動で実行できるようにします.
トリガーの設定は,「編集」→「現在のプロジェクトのトリガー」を選択し,「+トリガーを追加」を押すことで,以下のようなウィンドウを開くことができます.
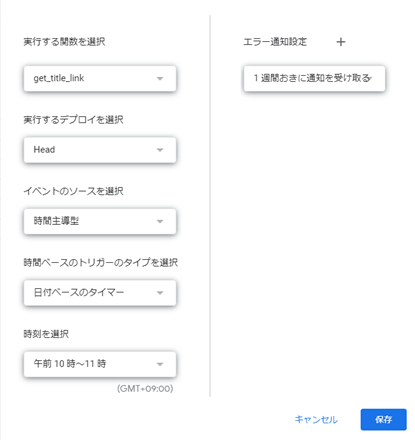
これで上記のコードを毎日,午前10時から11時で実行することができるようになります.
こんな感じで設定して保存を押せば,パソコンが起動してなくても,自動で毎日情報を取ってきてくれます!
午後も同様に,「+トリガーを追加」を押して,新たに追加すれば,完璧です.
おわりに
この記事では,GASを用いたデータ収集の基礎を扱いました.
テキストデータの解析は,取得のしやすさで言えば他の分野に比べて恵まれてるなってホントに思います.
企業分析の研究で,集めよう集めようと思っていたプレスリリースのデータも無事集められそうなので満足してます.
途中でも触れましたが,スクレイピングなどの行為は,迷惑のかからない範囲で行うようにしましょう.
何事もマナーを守ることが大切だと思います.
GASだいぶ慣れてきたので,論文投稿終わったら,「Re:ゼロから始めるweb開発 (GAS使用)」の続編書いていけたらと思います.
まだ,続き何をしていくか決めてないので,コメントでどういうものを作って紹介してほしいかなど教えてもらえたら,時間が許す範囲で実装して紹介してみたいと思うので,気軽にコメントください!
記事書きなれておらず,読みにくかったり至らない点も多かったと思いますが,最後まで読んでいただきありがとうございました.
少しでも「参考になった」,「続きが読みたい」と思ってくれた方は,いいねしてもらえると嬉しいです.(モチベになるので)
参考サイト一覧
GASでSpreadsheetを操作する自分的ベストプラクティス
GASで簡単WEBスクレイピング!HTMLを簡単にパースできるライブラリParserを使ってみた
「Easy data scraping with Google Apps Script in 5 minutes」
Re:ゼロから始めるweb開発 (GAS使用) Part0