この記事について
この記事は、DevFest Tokyo 2025のトーク「Androidifyで学ぶモダンAndroid開発」の補足資料として、特にAI機能の実装に焦点を当てた内容です。
Androidifyとは
Androidifyは、Googleが公開しているAndroid公式サンプルアプリです。オリジナルAndroidボット(Android ロボット)キャラクターを作成できるアプリで、最新のAI技術を活用した様々な機能が実装されています。
例えば、"カメラに人が映ると撮影ボタンが有効になる"、"プロンプトから画像を生成する"、"写真から背景を除去してステッカーを作る"など、さまざまなAI機能が体験できます。
Androidifyはオープンソース
このAndroidifyはGitHubでオープンソースにて公開されています。
https://github.com/android/androidify
この記事では、これらの機能について「体験(何ができるか)」→「裏側の技術(どう動くか)」の流れで解説します。実際に動くコードベースから学ぶことで、すぐに自分のアプリに応用できる実践的な知識が得られます。
対象読者
- Android開発の基礎知識がある方
- AndroidアプリにAI機能を統合したい方
- ML Kit、Gemini APIの実装方法を知りたい方
Androidifyの体験フロー
Androidifyアプリでは、以下のような流れでAI機能が使われています:
- カメラに人が映ると撮影ボタンが有効に
- テキストプロンプトを自動生成
- 安全でない画像をチェック
- テキストからAndroidボット生成
- 写真からAndroidボット生成
- ステッカー作成で背景を除去
- 好みの背景をAI生成
それぞれの機能について、「体験」「裏側の技術」「実装コード」を見ていきましょう。
1. カメラに人が映ると撮影ボタンが有効に。どうやってる?
Androidifyアプリのカメラ画面では、カメラに人が映ると撮影ボタンが自動的に押せるようになります。人がいないと撮影できません。リアルタイムで人物を検出して、撮影タイミングを制御しています。

裏側の技術:ML Kit Pose Detection API
ML KitのPose Detection APIを使用しています。PoseDetection.getClient()で取得したPose Detectorが、リアルタイムで人物の姿勢を検出します。33個のランドマーク(関節点)の位置を検出し、各ランドマークの信頼度(inFrameLikelihood)を0.0〜1.0で返します。
アプリサイズへの影響は~10.1MB程度だそうです。
NOSE, LEFT_SHOULDER, RIGHT_SHOULDER: 顔と肩の3点が検出されたら「人がいる」と判定します。

特徴:
- オンデバイス処理: デバイス上で完結、プライバシー保護
- STREAM_MODE: リアルタイム動画用の低レイテンシモード
実装コード
CameraViewModel.kt (feature/camera/src/main/java/com/android/developers/androidify/camera/CameraViewModel.kt)
以下では、理解しやすさのため、処理の流れに沿って説明します(実際のソースコードの順序とは異なります)。
1. Pose Detectorの初期化
// CameraViewModel.kt:320-337
@OptIn(ExperimentalGetImage::class)
private suspend fun runPoseDetection() {
PoseDetection.getClient(
PoseDetectorOptions.Builder()
.setDetectorMode(PoseDetectorOptions.STREAM_MODE) // リアルタイムモード
.build(),
).use { poseDetector ->
// カメラのImageAnalysisから画像を受け取る
cameraImageAnalysisUseCase.analyze { imageProxy ->
imageProxy.image?.let { image ->
val poseDetected = poseDetector.detectPersonInFrame(image, imageProxy.imageInfo)
_uiState.update { it.copy(detectedPose = poseDetected) }
}
}
}
}
ポイント:
-
STREAM_MODE: リアルタイム検出用のモード -
cameraImageAnalysisUseCase.analyze: CameraXのImageAnalysisからフレームを取得
2. 人物検出のロジック
// CameraViewModel.kt:302-318
private suspend fun PoseDetector.detectPersonInFrame(
image: Image,
imageInfo: ImageInfo,
): Boolean {
val results = process(InputImage.fromMediaImage(image, imageInfo.rotationDegrees)).await()
val landmarkResults = results.allPoseLandmarks
val detectedLandmarks = mutableListOf<Int>()
for (landmark in landmarkResults) {
if (landmark.inFrameLikelihood > 0.7) { // 信頼度70%以上
detectedLandmarks.add(landmark.landmarkType)
}
}
return detectedLandmarks.containsAll(
listOf(PoseLandmark.NOSE, PoseLandmark.LEFT_SHOULDER, PoseLandmark.RIGHT_SHOULDER),
)
}
ポイント:
-
inFrameLikelihood > 0.7: 信頼度70%以上のランドマークのみ採用 -
NOSE,LEFT_SHOULDER,RIGHT_SHOULDER: 顔と肩の3点が検出されたら「人がいる」と判定 - Coroutinesの
.await()でML Kitの非同期処理を待機
3. UIへの反映
// CameraViewModel.kt:347-360 (CameraUiState)
data class CameraUiState(
val surfaceRequest: SurfaceRequest? = null,
val cameraSessionId: Int = 0,
val imageUri: Uri? = null,
val detectedPose: Boolean = false, // Pose検出結果
// ...
)
UIではdetectedPoseを監視して撮影ボタンの有効/無効を切り替えます。
2. Androidボット生成用のテキストプロンプトを自動作成。どうやっている?

テキスト入力画面で「Write me a prompt」ボタンを押すと、AIが自動的に魅力的なAndroidボットの説明文を生成してくれます。例えば「麦わら帽子をかぶって、笑顔で手を振っている」のような具体的なプロンプトが作られます。生成されたプロンプトはテキスト欄に表示され、ユーザーはそれを編集することもできます。
裏側の技術:ML Kit Prompt API + Firebase AI Logic(フォールバック)
プロンプト自動生成はオンデバイス優先の戦略を採用しています:
- 第一選択:ML Kit Prompt API (Gemini Nano) - オンデバイスで高速・プライバシー保護
- フォールバック:Firebase AI Logic - Nanoが利用不可の場合はクラウドで処理
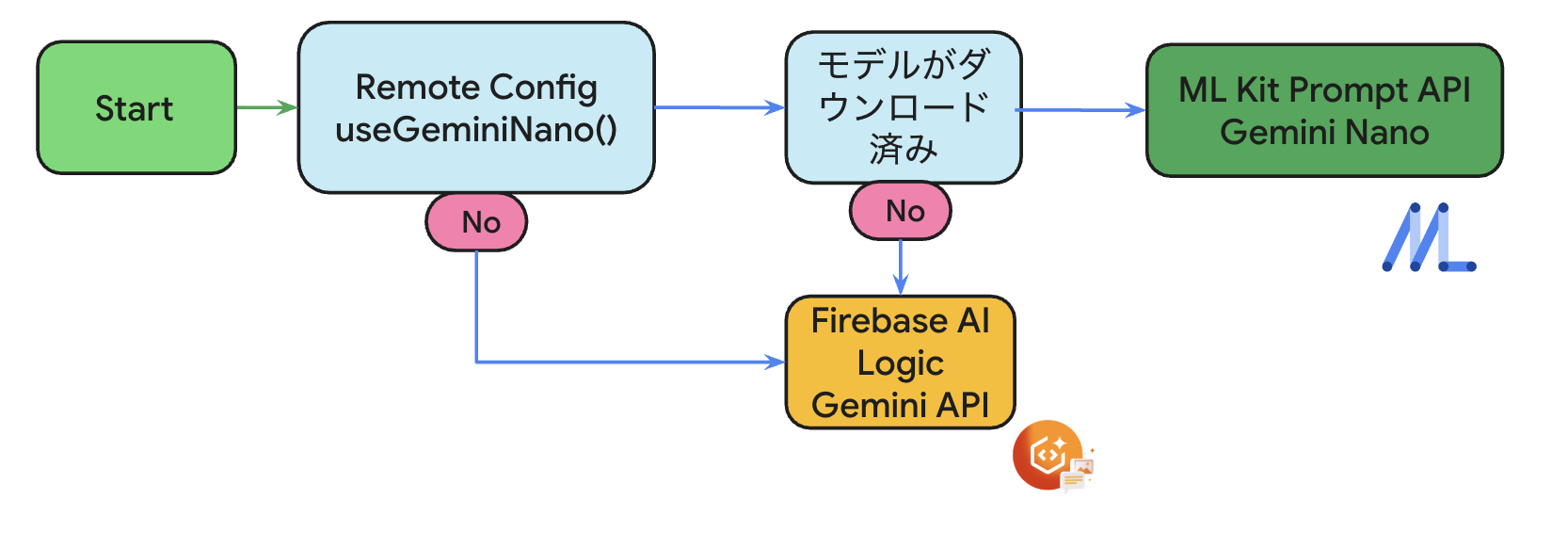
ML Kit Prompt API (Gemini Nano) - オンデバイス生成


特徴:
- オンデバイス: プライバシー保護、オフライン動作
- 軽量: バッテリー消費が少ない
- 低レイテンシ: クラウドAPIより高速
Firebase AI Logic - クラウド生成(フォールバック)


特徴:
-
Structured Output:
responseSchemaでJSON形式のレスポンスを定義 - 複数プロンプト生成: 1回のリクエストで複数のプロンプトを取得
実装コード
1. Gemini Nanoでのプロンプト生成(オンデバイス)
GeminiNanoGenerationDataSource.kt (data/src/main/java/com/android/developers/androidify/data/GeminiNanoGenerationDataSource.kt)
// GeminiNanoGenerationDataSource.kt:48-61
override suspend fun generatePrompt(prompt: String): String? {
if (!downloader.isModelDownloaded()) return null
val response = downloader.generativeModel.generateContent(
generateContentRequest(TextPart(prompt))
{
temperature = 0.2f
topK = 16
candidateCount = 1
maxOutputTokens = 256
},
)
Timber.d("generatePrompt: ${response.candidates[0].text}")
return response.candidates[0].text
}
ポイント:
-
generateContentRequest(TextPart(prompt)): ML Kit Prompt APIのリクエスト形式 -
temperature,topK,maxOutputTokens: 生成パラメータで品質を制御 -
isModelDownloaded(): モデルダウンロード状態を確認してからリクエスト
2. フォールバック戦略の実装
TextGenerationRepository.kt (data/src/main/java/com/android/developers/androidify/data/TextGenerationRepository.kt)
// TextGenerationRepository.kt:57-77
private suspend fun generateBotPrompts(): List<String> {
val prompt = remoteConfigDataSource.generateBotPrompt()
currentPromptIndex = 0
val nanoResult = if (remoteConfigDataSource.useGeminiNano()) {
// If Gemini Nano is not available, it will return null
geminiNanoDataSource.generatePrompt(prompt)
} else {
null
}
// If we're not getting a result from Nano, try with VertexAI
if (nanoResult.isNullOrEmpty()) {
val result = firebaseAiDataSource.generatePrompt(prompt).generatedPrompts
// if we're still not getting results, just return and empty list
return result ?: emptyList()
} else {
// use the Nano result
return listOf(nanoResult)
}
}
ポイント:
-
useGeminiNano(): Remote Configで機能を制御 - デバイス互換性の問題を緩和
3. Firebase AI Logicでのプロンプト生成(フォールバック)
FirebaseAiDataSource.kt (core/network/src/main/java/com/android/developers/androidify/vertexai/FirebaseAiDataSource.kt)
// FirebaseAiDataSource.kt:237-247
override suspend fun generatePrompt(prompt: String): GeneratedPrompt {
val jsonSchema = Schema.obj(
properties = mapOf(
"success" to Schema.boolean(),
"generated_prompt" to Schema.array(Schema.string()),
),
optionalProperties = listOf("generated_prompt"),
)
val generativeModel = createGenerativeTextModel(jsonSchema, temperature = 0.75f)
return executePromptGeneration(generativeModel, prompt)
}
ポイント:
-
temperature = 0.75f: 創造性を高めて多様なプロンプトを生成 - Structured OutputでJSON形式のレスポンス
3. 安全でない画像を入れられたときにエラーに。どうなっている?

写真を選択してStartボタンを押すと、画像が適切かどうかが自動でチェックされます。全身が写っていない写真や、不適切な内容の写真を選ぶと、エラーメッセージが表示されてAndroidボット生成が中断されます。
裏側の技術:ML Kit Prompt API + Firebase AI Logic(フォールバック)
画像検証はオンデバイス優先の戦略を採用しています:
- 第一選択:ML Kit Prompt API (Gemini Nano) - オンデバイスで高速・プライバシー保護
- フォールバック:Firebase AI Logic - Nanoが利用不可の場合はクラウドで処理
ML Kit Prompt API (Gemini Nano) - オンデバイス検証

特徴:
-
マルチモーダル:
ImagePartとTextPartで画像とテキストを同時処理 - オンデバイス: プライバシー保護、低レイテンシ
- シンプルな出力: エラー種別の文字列(例: "NOT_PERSON")または"null"(エラーなし)
Firebase AI Logic - クラウド検証(フォールバック)
実装コード
1. Gemini Nanoでの画像検証(オンデバイス)
GeminiNanoGenerationDataSource.kt (data/src/main/java/com/android/developers/androidify/data/GeminiNanoGenerationDataSource.kt)
// GeminiNanoGenerationDataSource.kt:63-83
override suspend fun validateImageHasEnoughInformation(image: Bitmap): ValidatedImage? {
if (!downloader.isModelDownloaded()) return null
val response = downloader.generativeModel.generateContent(
generateContentRequest(
ImagePart(image),
TextPart(remoteConfigDataSource.promptImageValidationNano()),
) {
temperature = 0.0f
maxOutputTokens = 20
},
).candidates[0].text
// モデルが"null"を返せば検証エラーなし
val successValue = response == "null"
return ValidatedImage(
successValue,
ImageValidationError.entries.find { it.description == response },
)
}
ポイント:
-
ImagePart(image)とTextPart(prompt): マルチモーダル処理 - エラーの種類しか返さないので、maxOutputTokens = 20
-
temperature = 0.0f: 決定的な出力(常に同じ結果) -
response == "null": エラーなしの判定(Nanoはシンプルな文字列を返す)
2. フォールバック戦略の実装
ImageGenerationRepository.kt (data/src/main/java/com/android/developers/androidify/data/ImageGenerationRepository.kt)
// ImageGenerationRepository.kt:58-69
private suspend fun validateImageIsFullPerson(file: File): ValidatedImage {
val bitmap = BitmapFactory.decodeFile(file.absolutePath)
val validateImageResult = if (remoteConfigDataSource.useGeminiNano()) {
geminiNanoDataSource.validateImageHasEnoughInformation(bitmap)
} else {
null
}
// Nanoでの検証が失敗した場合、Firebase AI Logicにフォールバック
return validateImageResult
?: firebaseAiDataSource.validateImageHasEnoughInformation(bitmap)
}
ポイント:
-
useGeminiNano(): Remote Configで機能を制御 - Nanoが
nullを返せば(利用不可)、Firebase AI Logicで処理 - デバイス互換性の問題を緩和
3. Firebase AI Logicでの画像検証(フォールバック)
FirebaseAiDataSource.kt (core/network/src/main/java/com/android/developers/androidify/vertexai/FirebaseAiDataSource.kt)
// FirebaseAiDataSource.kt:110-129
override suspend fun validateImageHasEnoughInformation(image: Bitmap): ValidatedImage {
val jsonSchema = Schema.obj(
properties = mapOf(
"success" to Schema.boolean(),
"error" to Schema.enumeration(
values = ImageValidationError.entries.map { it.description },
description = "Error message",
nullable = true,
),
),
optionalProperties = listOf("error"),
)
val generativeModel = createGenerativeTextModel(jsonSchema)
return executeImageValidation(
generativeModel,
remoteConfigDataSource.promptImageValidation(),
image,
)
}
ポイント:
-
Schema.enumeration(): エラーメッセージを列挙型で定義 - Structured OutputでJSON形式のレスポンス
-
NOT_PERSON,NOT_ENOUGH_DETAIL,POLICY_VIOLATION,OTHERなどのエラー種別
4. テキストからAndroidボットを生成。どうなっている?
入力したテキストプロンプトから、オリジナルのAndroidボット画像が生成されます。選択したボットの色(スキントーン)と組み合わせて、ユニークな画像が作られます。

裏側の技術:Firebase AI Logic (ImagenModel)
Firebase AI Logic SDKのImagenModel.generateImages()を使い、高品質な画像を生成します。Vertex AI経由でImagenモデル(imagen-4.0-ultra-generate-preview-06-06)に接続します。
特徴:
- 高品質: Imagenモデルによるリアルな画像生成
- プロンプトベース: テキストで細かく制御
-
Safety Filter:
ImagenSafetySettingsで不適切な画像を生成しない
実装コード
FirebaseAiDataSource.kt (core/network/src/main/java/com/android/developers/androidify/vertexai/FirebaseAiDataSource.kt)
1. Imagen Modelの初期化
// FirebaseAiDataSource.kt:84-95
private fun createGenerativeImageModel(): ImagenModel {
return Firebase.ai(backend = GenerativeBackend.vertexAI()).imagenModel(
remoteConfigDataSource.imageModelName(), // 例: imagen-4.0-ultra-generate-preview-06-06
safetySettings = ImagenSafetySettings(
safetyFilterLevel = ImagenSafetyFilterLevel.BLOCK_LOW_AND_ABOVE,
// ALLOW_ADULT filter (ALLOW_ALL requires special approval)
personFilterLevel = ImagenPersonFilterLevel.ALLOW_ADULT,
),
)
}
ポイント:
-
imagenModel(): Imagenモデルを取得 -
safetyFilterLevel: 不適切な画像をブロック -
personFilterLevel: 人物生成のフィルターレベル
2. プロンプトから画像生成
// FirebaseAiDataSource.kt:161-181
override suspend fun generateImageFromPromptAndSkinTone(
prompt: String,
skinTone: String,
): Bitmap {
val basePromptTemplate = remoteConfigDataSource.promptImageGenerationWithSkinTone()
val imageGenerationPrompt = basePromptTemplate
.replace("{prompt}", prompt)
.replace("{skinTone}", skinTone)
if (remoteConfigDataSource.useImagen()) {
val generativeModel = createGenerativeImageModel()
return executeImageGeneration(
generativeModel,
imageGenerationPrompt,
)
} else {
// Fine-tunedモデルを使用する場合
val fineTunedModel = createFineTunedModel()
val response = fineTunedModel.generateContent(imageGenerationPrompt)
return response.candidates.firstOrNull()?.content?.parts?.firstOrNull()?.asImageOrNull()
?: throw IllegalStateException("Could not extract image from fine-tuned model response")
}
}
// FirebaseAiDataSource.kt:229-235
private suspend fun executeImageGeneration(
generativeModel: ImagenModel,
prompt: String,
): Bitmap {
val response = generativeModel.generateImages(prompt)
return response.images.first().asBitmap()
}
ポイント:
-
promptImageGenerationWithSkinTone(): Remote Configからテンプレート取得 -
{prompt},{skinTone}: プレースホルダーを実際の値に置換 -
generateImages(): 画像生成API呼び出し -
asBitmap(): レスポンスをBitmapに変換
5. 写真からAndroidボットを生成 どうなっている?
撮影した写真から、自動でAndroidボット画像が生成されます。写真の人物の特徴(服装、ポーズ、雰囲気など)を認識して、それに合ったボット画像が作られます。

裏側の技術:ML Kit Prompt API + Firebase AI Logic
写真からの生成は2段階のプロセスで行われ、オンデバイス優先の戦略を採用しています:
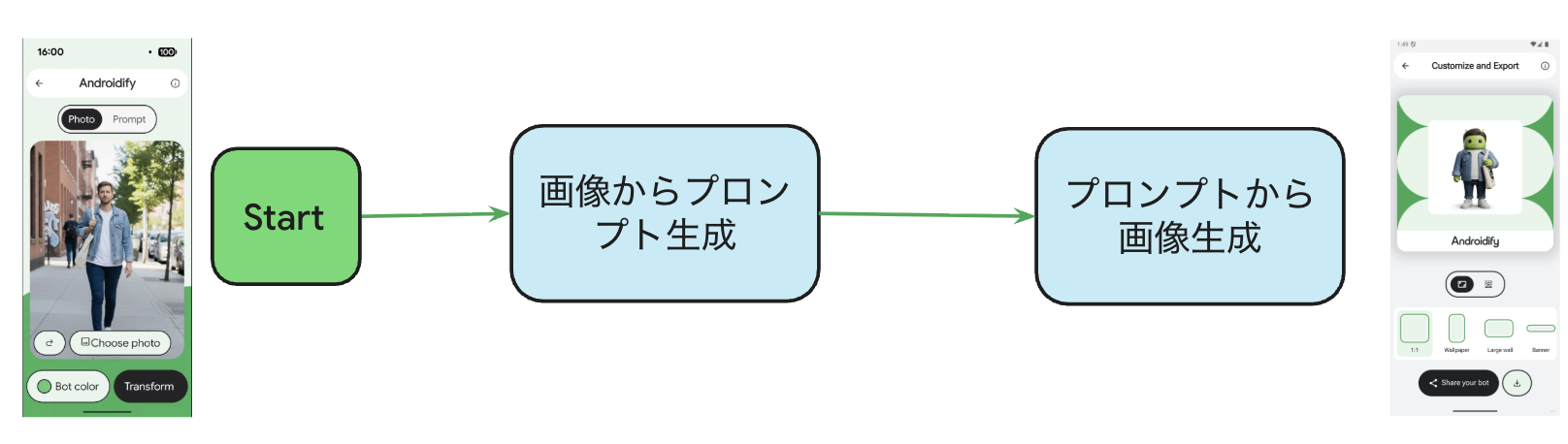
ステップ1: 写真を分析してプロンプトを自動生成
- 第一選択:ML Kit Prompt API (Gemini Nano) - オンデバイスで高速・プライバシー保護
- フォールバック:Firebase AI Logic - Nanoが利用不可の場合はクラウドで処理
ML Kit Prompt API (Gemini Nano) - オンデバイス分析
ステップ2: プロンプトからボット画像を生成
実装コード
1. Gemini Nanoでの画像分析(オンデバイス)
GeminiNanoGenerationDataSource.kt (data/src/main/java/com/android/developers/androidify/data/GeminiNanoGenerationDataSource.kt)
// GeminiNanoGenerationDataSource.kt:85-101
override suspend fun generateDescriptivePromptFromImage(image: Bitmap): ValidatedDescription? {
if (!downloader.isModelDownloaded()) return null
val generatedImageDescription = downloader.generativeModel.generateContent(
generateContentRequest(
ImagePart(image),
TextPart(remoteConfigDataSource.promptImageDescriptionNano()),
) {
temperature = 0.2f
},
)
return ValidatedDescription(
true,
generatedImageDescription.candidates[0].text,
)
}
ポイント:
-
ImagePart(image)とTextPart(prompt): マルチモーダル処理で写真から特徴抽出 -
temperature = 0.2f: ある程度の創造性を持たせつつ安定した出力 - オンデバイスで高速・プライバシー保護
2. フォールバック戦略の実装
ImageGenerationRepository.kt (data/src/main/java/com/android/developers/androidify/data/ImageGenerationRepository.kt)
// ImageGenerationRepository.kt:88-114
override suspend fun getDescriptionFromImage(file: File): ValidatedDescription {
checkInternetConnection()
val validatedImage = validateImageIsFullPerson(file)
if (!validatedImage.success) {
throw ImageValidationException(validatedImage.errorMessage?.toImageValidationError())
}
var imageDescription = if (remoteConfigDataSource.useGeminiNano()) {
geminiNanoDataSource.generateDescriptivePromptFromImage(
BitmapFactory.decodeFile(file.absolutePath),
)
} else {
null
}
Timber.d("nano generated image desc ${imageDescription?.userDescription}")
// Nanoでの生成が失敗した場合、Firebase AI Logicにフォールバック
if (imageDescription?.success != true) {
Timber.d("generating image description with Firebase AI Logic")
imageDescription = firebaseAiDataSource.generateDescriptivePromptFromImage(
BitmapFactory.decodeFile(file.absolutePath),
)
}
return imageDescription
}
ポイント:
-
useGeminiNano(): Remote Configで機能を制御 - Nanoが失敗すれば、Firebase AI Logicで処理
- ログで実際に使用されたモデルを確認可能
3. Firebase AI Logicでの画像分析(フォールバック)
FirebaseAiDataSource.kt (core/network/src/main/java/com/android/developers/androidify/vertexai/FirebaseAiDataSource.kt)
3-1. GenerativeModel の初期化
// FirebaseAiDataSource.kt:63-82
private fun createGenerativeTextModel(
jsonSchema: Schema,
temperature: Float? = null,
): GenerativeModel {
return Firebase.ai(backend = GenerativeBackend.vertexAI()).generativeModel(
modelName = remoteConfigDataSource.textModelName(), // 例: gemini-2.5-flash
generationConfig = generationConfig {
responseMimeType = "application/json" // JSON形式で返す
responseSchema = jsonSchema // レスポンスのスキーマ定義
this.temperature = temperature
},
safetySettings = listOf(
SafetySetting(HarmCategory.HARASSMENT, HarmBlockThreshold.LOW_AND_ABOVE),
SafetySetting(HarmCategory.HATE_SPEECH, HarmBlockThreshold.LOW_AND_ABOVE),
SafetySetting(HarmCategory.SEXUALLY_EXPLICIT, HarmBlockThreshold.LOW_AND_ABOVE),
SafetySetting(HarmCategory.DANGEROUS_CONTENT, HarmBlockThreshold.LOW_AND_ABOVE),
SafetySetting(HarmCategory.CIVIC_INTEGRITY, HarmBlockThreshold.LOW_AND_ABOVE),
),
)
}
ポイント:
-
GenerativeBackend.vertexAI(): Vertex AI上のGeminiを使用 -
responseMimeType = "application/json": Structured Outputでレスポンスを構造化 -
responseSchema: JSONスキーマでレスポンス形式を指定 -
safetySettings: 有害なコンテンツをブロック
3-2. 画像からプロンプト生成
// FirebaseAiDataSource.kt:131-146
override suspend fun generateDescriptivePromptFromImage(image: Bitmap): ValidatedDescription {
val jsonSchema = Schema.obj(
properties = mapOf(
"success" to Schema.boolean(),
"user_description" to Schema.string(),
),
optionalProperties = listOf("user_description"),
)
val generativeModel = createGenerativeTextModel(jsonSchema)
return executeImageDescriptionGeneration(
generativeModel,
remoteConfigDataSource.promptImageDescription(), // システムプロンプト
image,
)
}
// FirebaseAiDataSource.kt:212-227
private suspend fun executeImageDescriptionGeneration(
generativeModel: GenerativeModel,
prompt: String,
image: Bitmap,
): ValidatedDescription {
val response = generativeModel.generateContent(
content {
text(prompt)
image(image)
},
)
val jsonResponse = Json.parseToJsonElement(response.text!!)
val isSuccess = jsonResponse.jsonObject["success"]?.jsonPrimitive?.booleanOrNull == true
val userDescription = jsonResponse.jsonObject["user_description"]?.jsonPrimitive?.content
return ValidatedDescription(isSuccess, userDescription)
}
ポイント:
-
content { text(prompt); image(image) }: テキストと画像を同時に送信(マルチモーダル) - JSONレスポンスをパースして構造化データとして取得
4. プロンプトから画像生成
生成されたプロンプトを使って、セクション4と同じImagenの画像生成処理を実行します。
6. ステッカー作成で背景を消した画像作成。どうなっている?
生成されたAndroidボット画像をカスタマイズする画面で、サイズを「ステッカー」に変更すると、人物だけが切り抜かれ、背景が透明になります。髪の毛などの細かい部分も綺麗に切り抜かれます。

裏側の技術:ML Kit Subject Segmentation API
ML KitのSubject Segmentation APIを使用しています。SubjectSegmentation.getClient()で取得したSegmenterが、画像から人物領域を自動検出し、前景(人物)のBitmapを生成します。

特徴:
- オンデバイス処理: プライバシー保護、オフライン動作
-
自動モジュールダウンロード:
ModuleInstallClientで必要なモジュールを自動ダウンロード -
高精度:
enableForegroundBitmap()で髪の毛など細かい部分も切り抜き可能
使用箇所:
- CustomizeExport画面でStickerサイズを選択した時
- Watch Faceへの転送時
実装コード
LocalSegmentationDataSource.kt (core/network/src/main/java/com/android/developers/androidify/ondevice/LocalSegmentationDataSource.kt)
1. Subject Segmenterの初期化
// LocalSegmentationDataSource.kt:42-47
private val segmenter by lazy {
val options = SubjectSegmenterOptions.Builder()
.enableForegroundBitmap() // 前景(人物)のBitmapを取得
.build()
SubjectSegmentation.getClient(options)
}
ポイント:
-
enableForegroundBitmap(): 切り抜いた人物画像を取得
2. モジュールの自動ダウンロード
// LocalSegmentationDataSource.kt:49-99
private suspend fun isSubjectSegmentationModuleInstalled(): Boolean {
val areModulesAvailable = suspendCancellableCoroutine { continuation ->
moduleInstallClient.areModulesAvailable(segmenter)
.addOnSuccessListener {
continuation.resume(it.areModulesAvailable())
}
.addOnFailureListener {
continuation.resumeWithException(it)
}
}
return areModulesAvailable
}
private suspend fun installSubjectSegmentationModule(): Boolean {
val result = suspendCancellableCoroutine { continuation ->
val listener = CustomInstallStatusListener(continuation)
val moduleInstallRequest = ModuleInstallRequest.newBuilder()
.addApi(segmenter)
.setListener(listener)
.build()
moduleInstallClient
.installModules(moduleInstallRequest)
.addOnFailureListener {
continuation.resumeWithException(it)
}
}
return result
}
ポイント:
-
areModulesAvailable(): ML Kitモジュールがインストール済みか確認 -
installModules(): 未インストールの場合は自動ダウンロード -
suspendCancellableCoroutine: コールバックをCoroutinesで待機
3. 背景除去の実行
// LocalSegmentationDataSource.kt:101-128
override suspend fun removeBackground(bitmap: Bitmap): Bitmap {
val areModulesAvailable = isSubjectSegmentationModuleInstalled()
if (!areModulesAvailable) {
val result = installSubjectSegmentationModule()
if (!result) {
throw Exception("Failed to download module")
}
}
val image = InputImage.fromBitmap(bitmap, 0)
return suspendCancellableCoroutine { continuation ->
segmenter.process(image)
.addOnSuccessListener { result ->
if (result.foregroundBitmap != null) {
continuation.resume(result.foregroundBitmap!!)
} else {
continuation.resumeWithException(ImageSegmentationException("Subject not found"))
}
}
.addOnFailureListener { e ->
continuation.resumeWithException(e)
}
}
}
ポイント:
-
result.foregroundBitmap: 切り抜かれた人物画像(背景は透明) - エラーハンドリング: 人物が検出できない場合は例外
呼び出し元:
CustomizeExportViewModel.kt (feature/results/src/main/java/com/android/developers/androidify/customize/CustomizeExportViewModel.kt)
// CustomizeExportViewModel.kt:162-196
private fun triggerStickerBackgroundRemoval(bitmap: Bitmap, previousSizeOption: SizeOption) {
viewModelScope.launch {
try {
val stickerBitmap = imageGenerationRepository.removeBackground(
bitmap,
)
_state.update {
it.copy(
showImageEditProgress = false,
exportImageCanvas = it.exportImageCanvas.copy(imageBitmapRemovedBackground = stickerBitmap)
.updateAspectRatioAndBackground(
it.exportImageCanvas.selectedBackgroundOption,
SizeOption.Sticker,
),
)
}
} catch (exception: Exception) {
snackbarHostState.value.showSnackbar("Background removal failed")
// エラー時は前のサイズオプションに戻す
}
}
}
7. 好みの雰囲気の背景を加えて画像作成。どうなっている?
カスタマイズ画面で「Music Lover」「Pool Maven」などのBackground Vibesオプションを選択すると、その雰囲気に合った背景画像が生成されます。元のAndroidボット画像に、選んだテーマに沿った背景が追加されます。

裏側の技術:Firebase AI Logic Gemini API (Gemini 2.0 Image Generation)
Firebase AI Logic Gemini APIを使い、Gemini 2.0の画像生成機能で元画像とプロンプトから新しい背景画像を生成します。GenerativeModel.generateContent()でResponseModality.IMAGEを指定することで、画像レスポンスを取得します。
特徴:
-
画像編集:
content { text(); image() }で既存の画像に背景を追加 - プロンプトベース: テキストで背景の雰囲気を指定
-
ResponseModality:
ResponseModality.IMAGEで画像レスポンスを受信
実装コード
FirebaseAiDataSource.kt (core/network/src/main/java/com/android/developers/androidify/vertexai/FirebaseAiDataSource.kt)
画像編集(AI背景生成)
// FirebaseAiDataSource.kt:249-270
override suspend fun generateImageWithEdit(
image: Bitmap,
backgroundPrompt: String,
): Bitmap {
val model = Firebase.ai(backend = GenerativeBackend.googleAI()).generativeModel(
modelName = remoteConfigDataSource.getImageGenerationEditsModelName(), // gemini-2.0-flash-preview-image-generation
generationConfig = generationConfig {
responseModalities = listOf(
ResponseModality.TEXT,
ResponseModality.IMAGE,
)
},
)
val prompt = content {
text(backgroundPrompt)
image(image)
}
val response = model.generateContent(prompt)
val image = response.candidates.firstOrNull()
?.content?.parts?.firstNotNullOfOrNull { it.asImageOrNull() }
return image ?: throw IllegalStateException("Could not extract image from model response")
}
ポイント:
-
GenerativeBackend.googleAI(): Google AIを直接使用(画像編集機能) -
responseModalities: テキストと画像の両方を受け取る -
content { text(); image() }: 元画像 + プロンプトで背景生成
補足: Veo 3動画生成について
Google公式ブログでは、AndroidifyでVeo 3を使った動画生成機能が言及されています:
"Androidify uses Gemini 2.5 Flash to caption the photo, Imagen to generate your custom Android bot and (in some cases) Veo 3, Google latest video generation model, to animate your bot with different vibes."
しかし、執筆時点(2025年11月)のコードベースでは、動画生成機能の実装は確認できませんでした。この機能は限定的に提供されている、または今後実装予定の可能性があります。
まとめ
コードを読むときにまとめていたMiroを置いてきます。
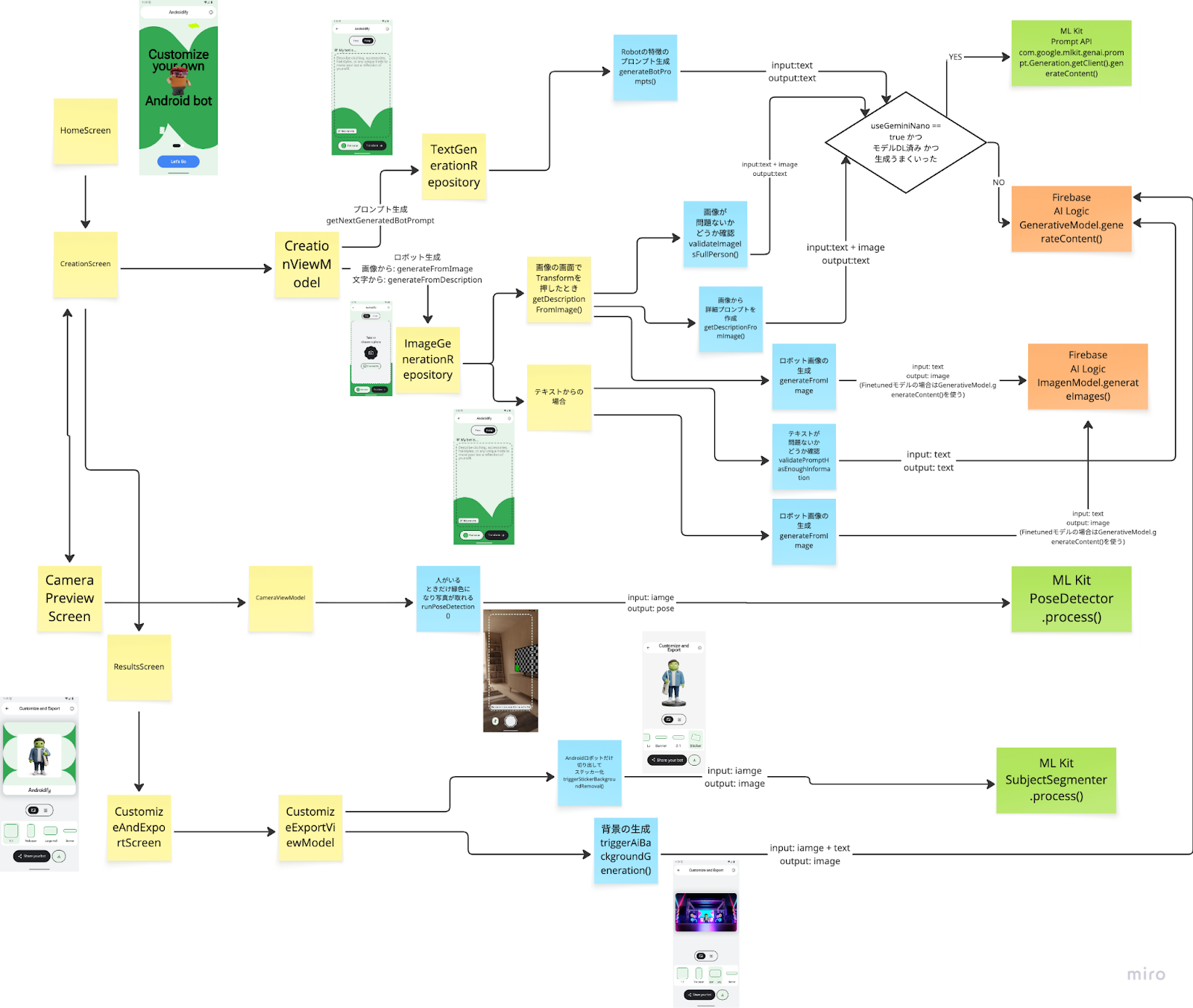
機能と技術の対応
| 機能 | 技術 |
|---|---|
| 1. カメラに人が映ると撮影ボタンが有効に | ML Kit Pose Detection |
| 2. テキストプロンプトを自動生成 | ML Kit Prompt API (Gemini Nano) → Firebase AI Logic |
| 3. 安全でない画像をチェック | ML Kit Prompt API (Gemini Nano) → Firebase AI Logic |
| 4. テキストからAndroidボット生成 | Firebase AI Logic (ImagenModel) |
| 5. 写真からAndroidボット生成 | ML Kit Prompt API (Gemini Nano) → Firebase AI Logic & ImagenModel |
| 6. ステッカー作成で背景を除去 | ML Kit Subject Segmentation |
| 7. 好みの背景をAI生成 | Firebase AI Logic (Gemini 2.0 Image Generation) |
※「→」はフォールバック(Gemini Nano利用不可時はFirebase AI Logicに切り替え)
気づき
- 生成AI以外のML
- 遅延が少ないなどで生成AI以外のMLの利用のしどころがあった
- 色々ML Kitでできることがあるので見てみると良さそう
- 生成AI
- プロンプトはNano向けと、クラウドLLM向けで分けることが役立つことがある
- Nano向けはプロンプトエンジニアリングのテクニックが役立つ
- Nanoが使えなかったらクラウドLLMにしたりなどうまくルーティングできるようにしておくと良さそう