こちらは株式会社 POL テックカレンダー 2021 の 10 日目の記事です。
前回の記事はこちらで、某ジブリ作品の主人公と同じ名前だからという理由で「千」とあだ名をつけられてしまった(名前を奪われてしまった)牛木の全力ラズパイパッケージング記事でした。
こんにちは!
株式会社 POL でエンジニアをしている山田です。
今日は AWS Glue を用いて Amazon Aurora MySQL から BigQuery にデータを Export する方法について紹介したいと思います。
概要
図にするまでもないかもですが、イメージ図としては以下のようになります。
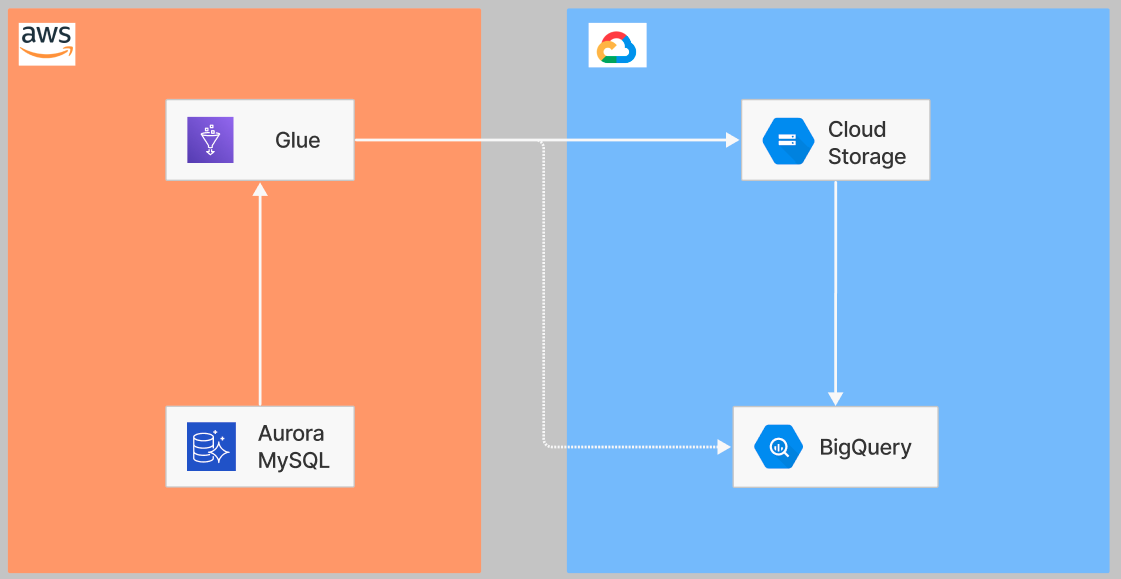
図からも分かる通り、シンプルな構成になっています。
白実線が実際のデータの流れになっていますが、Cloud Storage に対する書き込み、Cloud Storage から BigQuery への読み込みは後で紹介する AWS Glue Connector for Google BigQuery が担っているため、白点線のように Glue から直接 BigQuery に書き込まれているように見えます。
Aurora MySQL のデータを BigQuery にデータを Export する他の方法については、例えば BigQuery Data Transfer Service を利用する方法があります。しかしながら、BigQuery Data Transfer Service を利用する場合、Aurora MySQL にあるデータを一度 S3 に export してあげる必要があり、Aurora MySQL → S3 に関する追加のコストがかかること、更に BigQuery Data Transfer Service では一つの転送設定で一つのテーブルしか設定できないため、テーブルの数が多い場合や、Aurora MySQL で新しくテーブルが作れらた場合の考慮が必要な点が煩雑であるかと思います。
Glue を利用した方法では、Aurora MySQL の INFORMATION_SCHEMA テーブルから MySQL 上のテーブル一覧を列挙することで新規にテーブルが作られた場合も対処することが可能です。また、Glue は Serverless なサービスとなっているため、インフラ管理についても最低限に抑えることができます。
前準備
GCP 側
以下 2 つの準備が必要です。
- GCS バケット: Aurora MySQL のデータは Glue からロードされたあと、一度 GCS 上に配置されるため、GCS バケットが必要です。一時的にデータがロードされるだけ、かつ GCS から BigQuery にデータがロードされたあとはデータが消えます。
- サービスアカウント: BigQuery と GCS へアクセスするために必要となります。また JSON サービスアカウントキーも発行します。
AWS 側
Glue Connection の作成
以下 2 つの Connection が必要です
- Glue から Aurora MySQL へ接続するための Connection
- Glue から BigQuery へ接続するための Connection
Glue から Aurora MySQL へ接続するための Connection についてはこちらの AWS ドキュメント を参照してください。Glue から BigQuery へ接続するための Connectionについては、AWS Glue Connector for Google BigQuery を利用します。Glue 上で AWS Glue Connector for Google BigQuery のためのコネクションを作る必要があるのですが、こちらの手順は AWS のブログに記載があるのでこちら を参考にしてください(AWS ブログは BigQuery → S3 の手順が書かれています)。
S3 に必要なファイルを保存する
下記 2 つのファイルを S3 に保存しておく必要があります。
- Cloud Storage connector の jar
- GCP JSON サービスアカウントキー ([GCP 側の前準備](### GCP 側) で作成したもの)
それぞれ、Glue Job を作成するときにアップロードした S3 のパスが必要となります。
Glue Job の作成
Glue PySpark Job を作成しますが、作成時の設定に以下を指定する必要があります。
- 依存 JARS パス: Cloud Storage connector の jar の S3 パス
- 参照されるファイルパス: GCP JSON サービスアカウントキー
- 接続: [Glue Connection の作成](#### Glue Connection の作成) で作成したもの 2 つ
- ジョブパラメータ
- --BQ_PROJECT: BigQuery の GCP プロジェクト ID
- --BQ_DATASET: BigQuery のデータセット名
- --BQ_CREDENTIAL_FILE: GCP JSON サービスアカウントキーのファイル名 (S3 パスではなく、*.json といった形式のもの)
- --GCS_BUCKET_NAME: GCS バケット名
- --CONNECTION_NAME: Glue から Aurora MySQL へ接続するための Connection 名(接続情報を取得するのに利用する)
- --DB_SCHEMA: データを取得元となる Aurora MySQL スキーマ名
Glue のコードは下記のようになります。
GCS 周りの設定についてはこちらを参考にさせていただきました。
import sys
import datetime
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
arg_keys = ['JOB_NAME', 'BQ_PROJECT',
'BQ_DATASET', 'BQ_CREDENTIAL_FILE', 'GCS_BUCKET_NAME', 'CONNECTION_NAME', 'DB_SCHEMA']
args = getResolvedOptions(sys.argv, arg_keys)
BQ_PROJECT = args['BQ_PROJECT']
BQ_DATASET = args['BQ_DATASET']
BQ_CREDENTIAL_FILE = args['BQ_CREDENTIAL_FILE']
GCS_BUCKET_NAME = args['GCS_BUCKET_NAME']
CONNECTION_NAME = args['CONNECTION_NAME']
DB_SCHEMA = args['DB_SCHEMA']
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# 取り込み日でシャーディング
now = datetime.datetime.now()
date = [now.year, now.month, now.day]
# GCS の設定
spark.conf.set("temporaryGcsBucket", "<GCS バケット名>")
spark._jsc.hadoopConfiguration().set(
'fs.gs.impl', 'com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem')
spark._jsc.hadoopConfiguration().set('fs.gs.auth.service.account.enable', 'true')
spark._jsc.hadoopConfiguration().set(
'google.cloud.auth.service.account.json.keyfile', BQ_CREDENTIAL_FILE)
# INFORMATION_SCHEMA からテーブル情報を取得
src_jdbc = glueContext.extract_jdbc_conf(
connection_name=CONNECTION_NAME)
df = glueContext.create_dynamic_frame_from_options(
'mysql', connection_options={
"url": src_jdbc['url'] + "/information_schema", "user": src_jdbc['user'], "password": src_jdbc['password'], "dbtable": "tables"
}
)
target_tables = df.toDF().filter(
"TABLE_SCHEMA = '{0}'".format(DB_SCHEMA)).collect()
# テーブルごとに書き出し
for row in target_tables:
table_name = row['TABLE_NAME']
source_dyf = glueContext.create_dynamic_frame_from_options('mysql', connection_options={
"url": src_jdbc['url'] + "/" + DB_SCHEMA, "user": src_jdbc['user'], "password": src_jdbc['password'], "dbtable": table_name
})
glueContext.write_dynamic_frame.from_options(
frame=source_dyf,
connection_type="marketplace.spark",
connection_options={
"temporaryGcsBucket": GCS_BUCKET_NAME,
"parentProject": BQ_PROJECT,
"table": BQ_DATASET + "." + table_name + "__{0[0]:0>4}{0[1]:0>2}{0[2]:0>2}".format(date),
"connectionName": "BigQueryConnectorForCompassWithoutCredentials",
# BigQuery のテーブルをパーティションテーブルにする場合は下記のパラメータを利用する
# "datePartition": "{0[0]:0>4}{0[1]:0>2}{0[2]:0>2}".format(date),
# "partitionType": "DAY",
},
transformation_ctx="AWSGlueConnectorforGoogleBigQuery",
)
job.commit()
上記コードでは、BigQuery 上のテーブルをシャーディングテーブルにしていますが、パーティションテーブルにする場合は「BigQuery のテーブルをパーティションテーブルにする場合は下記のパラメータを利用する」とコメントされている箇所の下 2 行をコメントアウトして、BigQuery のテーブル名から日付の suffix を除去すれば対応できます。
まとめ
AWS Glue を利用して Amazon Aurora MySQL から BigQuery にデータを Export する方法について紹介しました。BigQuery Data Transfer Service などを利用する場合に比べて、シンプルな構成に、かつ、Glue を用いているため、Serverless な構成にすることができました。
そもそも今回の記事は、最近発表された BigQuery Omni をご存じの方にとっては、AWS 上にあるデータをわざわざ GCP に移動させる必要もないんじゃない?と思われるかもしれません。ただ、BigQuery Omni を気軽に触れない場合(定額プランでなければならないため)や、その他諸々の制約(こちらの Advent Calendar が面白かったです)に悩まれている方にとって役に立てるかなと思います。
今後取り組みたいこととしては、今回利用した AWS Glue Connector for Google BigQuery は、Glue 上のログを見る限り こちらの Connector を利用しているみたいです。ここ最近 (3 日前) Version 0.23.0 がリリースされ、このバージョンでは、BigQuery Storage Write API が利用されるようになったため、GCS を一切介さず、Glue (Spark) から直接 BigQuery にデータを書き込むことができるみたいです。この機能を利用すればより Glue の設定を少なくして、Amazon Aurora MySQL から BigQuery にデータを Export できるようになると思います。まだ preview 版なので、挙動を確かめつつ試してみたいです。
次回は @ryu19-1 ことトマト大好きリコピンさんの「AppSyncでの競合解決を頑張った話」です。お楽しみに!