はじめに
本記事は Location Tech Advent Calendar 2021 by LBMA Japan 5日目の投稿で、昨日の続き です。
BigQuer Omni は直接クエリを実行できる利便性があるとはいえ、Google Cloud Anthos Cluster から AWS S3 といった外部ストレージに保管されているデータを読み込むため、ビッグデータにおいても実用に耐えうるのかという疑問があったのでテストしてみました。
パフォーマンステスト条件
BigQuery テーブル(以下、native)と AWS S3 テーブル(以下、omni)で処理時間を比較してパフォーマンスを評価しました。
用いたデータ
当社が保有する位置情報ビッグデータからテスト用に一部だけ切り出し、native と omni に保存しました。
用いたのは以下の2種類のデータです。
- POI:約135MB 約200万件(テストにより一部を抽出)
- ログ:約20GB 約1.4億件
BigQuery Omni 環境
特に選択肢はありませんが、一応記載しておきます。
- スロット:100固定
- リージョン:AWS us-east-1 / US
テスト条件(5回実行結果の平均で比較)
- レコードカウント<ログのみ>
- 円形ログ抽出<POI x ログ>
- 最近傍探索(各POIに最も近い位置にある別のPOIの算出)<POI のみ>
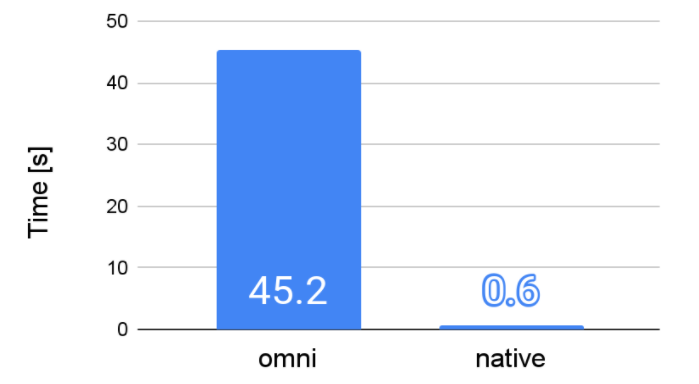
テスト結果①:レコードカウント
- クエリ内容
- ログのレコードを単純にカウント(約20GB / 約1.4億件)
- 結論
- omni はデータ転送時間分、単純なクエリほどパフォーマンスが悪い
- omni でカウント対象列を変えてのテストも行ったが処理時間はほぼ変わらず、読み込むデータ量は変化しない(全データが読み込まれる)
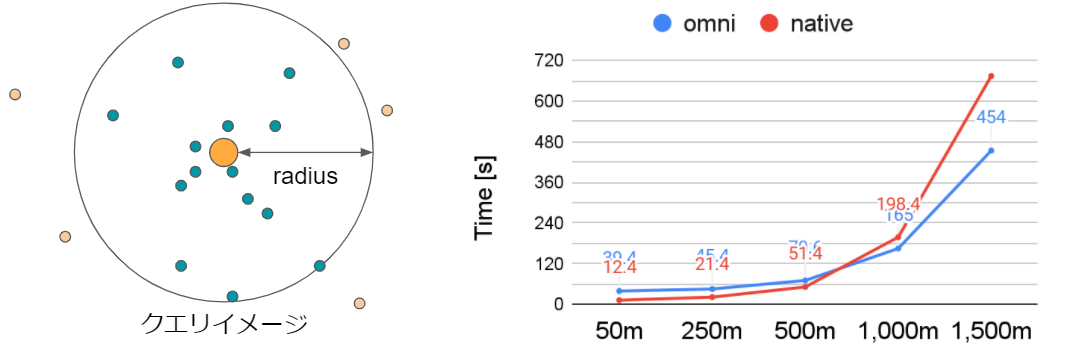
テスト結果②:円形ログ抽出
-
クエリ内容
- 各POI中心から円形でログを抽出
- POI:全国コンビニ約5.8万件
- ログ:約1.4億件
-
結論
- 読み込むデータ量が同じで、抽出対象範囲を広げるほど Omni の方がパフォーマンスが良くなる傾向
-
【参考】クエリイメージと結果比較
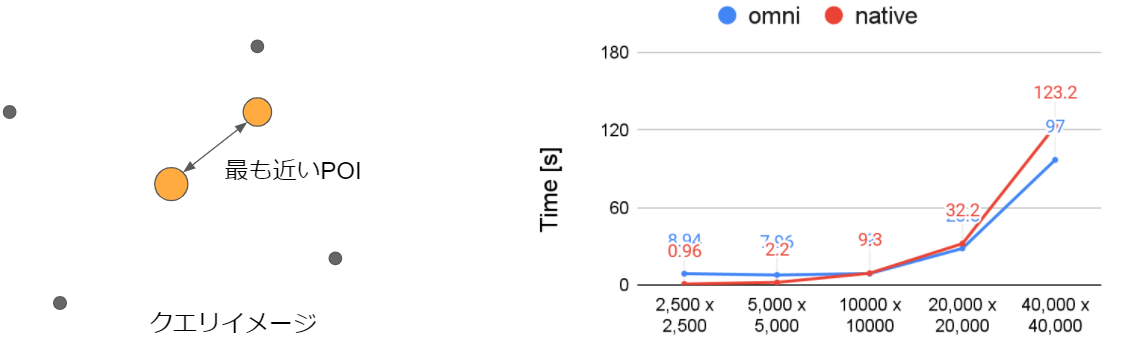
テスト結果③:最近傍探索
- クエリ内容
- 各 POI と最も近い異なる POI を算出(デカルト積)
- POI のみ(2,500件~40,000件の幅でランダム抽出)
- 結論
- 読み込むデータ量が同じで、件数を増やすほど Omni の方がパフォーマンスが良くなる傾向
- 【参考】クエリイメージと結果比較
使ってみてわかったこと(個人的見解)
総括:ユースケースは限定的ながら、使ってみる価値アリ
- 【〇】最初の設定の手間はかかるが、外部ストレージに保存したデータを転送することなく1つの環境で分析ができるのはとても利便性が高い。
- 【〇】アクセス制御を AWS と GC で分けて設定を行うため、異なるクラウド環境を導入している社外とのデータ連携においても使えそう。
- 【〇】意外な結果だったが処理が複雑になるほど、Omni の方がパフォーマンスが上がる傾向。(Anthos Cluster の仕組みによる?)
- 【△】スキャンするカラムによらずテーブルの全データを一度クラスター上に呼び込むため大量データは転送時間がかかる。インタラクティブ分析よりはバッチ分析向き?
- 【×】計算リソースがデフォルトで100スロット固定のため、課金はスキャンするデータ量に依存しないがスケーラブルでない。(今後の拡張に期待!)
- 【×】使えるリージョンが aws-us-east-1 に保存されているデータのみしか使えない。(今後の拡張に期待!!)
- 【×】インタラクティブクエリで表示できる結果が2MBまでに制限されている(今後の拡張に期待!!!)