前回の記事:
1/3,SDKを用いたアイトラッカー動作
2/3,動画再生中の視線追跡
はじめに
視線追跡に動画再生機能をドッキングしました.アイトラッカーからcsvが出力されるので,csv内の数値に従って画面上に図形を表示し注視点を可視化するプログラムも仕上がりました.しかし動画表示タイミングと視線記録タイミングがシンクロしていません.最後にこれを解決して,プログラムを完成させます.
動画再生についてもタイムスタンプ出力
動画表示タイミングと視線記録タイミングをシンクロさせたいので,「じゃあ動画のそれぞれのフレームは結局何時何分何秒に表示されたのか」という情報が必要になります.前回の最後で動画再生開始時刻だけは取得しました.これをさらに発展させ,全フレーム分表示時刻を取得します.
ここでは視線追跡データとは別のcsvファイルに書き出すことにしています.この時点ではシンクロしていないので,同じファイルにある必要なくない?という考えです.
動画再生-視線記録プログラムはこれで最終完成です!
(折り畳み:クリックで展開)
import tobii_research as tr
import keyboard
import csv
import time
import cv2
# 動画ファイルのパス
video_path = "sample.mp4"
# 時刻を格納するリスト
timestamps = []
# アイトラッカーセットアップ
found_eyetrackers = tr.find_all_eyetrackers()
my_eyetracker = found_eyetrackers[0]
gaze_data_list = [] # 視線データを格納するリスト
# 視線データのストリームコールバック関数
def gaze_data_callback(gaze_data):
gaze_data_list.append(gaze_data)
# キーボードのsキーでストリーミングを開始/停止する
def toggle_streaming():
# 動画をフルスクリーンで再生する
video_player = cv2.VideoCapture(video_path)
fps = video_player.get(cv2.CAP_PROP_FPS)
cv2.namedWindow("Video", cv2.WND_PROP_FULLSCREEN)
cv2.setWindowProperty("Video", cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
# アイトラッカー動作開始
my_eyetracker.subscribe_to(tr.EYETRACKER_GAZE_DATA, gaze_data_callback, as_dictionary=True)
print("ストリーミングを開始しました")
# マイクロ秒で開始時刻を取得
start_time = time.time()
frame_counter = 1
while video_player.isOpened():
ret, frame = video_player.read()
if ret:
# フレームが表示された時刻を取得
timestamp = time.time()
timestamps.append([timestamp, frame_counter])
cv2.imshow("Video", frame)
cv2.setWindowProperty("Video", cv2.WND_PROP_TOPMOST, 1) # ウィンドウを最前面に表示
wait_time = int(1000 / fps) # フレームレートの逆数をミリ秒に変換
if cv2.waitKey(wait_time) & 0xFF == ord("q"):
# アイトラッカー停止
my_eyetracker.unsubscribe_from(tr.EYETRACKER_GAZE_DATA, gaze_data_callback)
print("ストリーミングを停止しました")
# マイクロ秒で開始時刻を取得
break
frame_counter += 1
else:# アイトラッカー停止
my_eyetracker.unsubscribe_from(tr.EYETRACKER_GAZE_DATA, gaze_data_callback)
print("ストリーミングを停止しました")
# マイクロ秒で開始時刻を取得
break
# ウィンドウを閉じる
cv2.destroyAllWindows()
# CSVファイルに視線データを書き込む
with open('gaze_data.csv', 'w', newline='') as csvfile:
fieldnames = ['timestamp', 'left_eye_x', 'left_eye_y', 'right_eye_x', 'right_eye_y']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
record_start_time = gaze_data_list[0]["system_time_stamp"]
for data in gaze_data_list:
sample_time_from_start = (start_time + (data["system_time_stamp"]-record_start_time)/(10**6))
left_eye_x = data['left_gaze_point_on_display_area'][0]
left_eye_y = data['left_gaze_point_on_display_area'][1]
right_eye_x = data['right_gaze_point_on_display_area'][0]
right_eye_y = data['right_gaze_point_on_display_area'][1]
# csv書き込み
writer.writerow({
'timestamp': sample_time_from_start,
'left_eye_x': left_eye_x,
'left_eye_y': left_eye_y,
'right_eye_x': right_eye_x,
'right_eye_y': right_eye_y
})
with open('movie_timestamp.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Frame', 'Timestamp'])
writer.writerows(timestamps)
print("データをcsvに保存しました")
keyboard.add_hotkey('s', toggle_streaming)
# キーボード入力を監視
keyboard.wait()
差分は以下の,動画再生whileループ内でのタイムスタンプ取得と追加のcsv書き出しです:
# 時刻を格納するリスト
timestamps = []
# (while文まで略)
# フレームが表示された時刻を取得
timestamp = time.time()
timestamps.append([timestamp, frame_counter])
# (中略)
with open('movie_timestamp.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Frame', 'Timestamp'])
writer.writerows(timestamps)
2つのcsvに書き出されたタイムスタンプデータを比べてみます.横軸はデータ点数,縦軸はタイムsたんプで,オレンジが視線.青が動画です.取得されるデータ点数が動画と視線で異なるので右端位置は違いますが,上端終了位置は同じです.したがって開始と終了はほぼ同時刻であまり遅延ないようです.よかった.あと直線性はすこぶる良好で等間隔サンプルにはちゃんとなっているのもわかります.
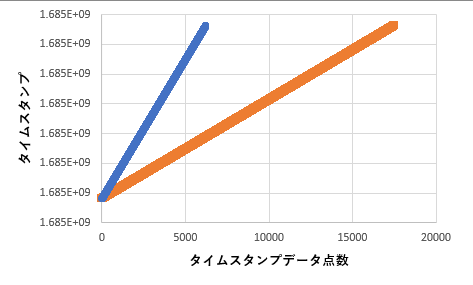
(念のため,ということで3分強程度の長めの動画でテストしました.そのためデータ点数が512どころではないです)
動画出力プログラムの改良
タイムスタンプの補間
以下のようにnp.interpを使って補間します:
import numpy as np
# CSVファイルを読み込む
gaze_data = np.genfromtxt('gaze_data.csv', delimiter=',')
sample_time_from_start = gaze_data[1:, 0]
left_eye_x = gaze_data[1:, 1]
left_eye_y = gaze_data[1:, 2]
right_eye_x = gaze_data[1:, 3]
right_eye_y = gaze_data[1:, 4]
movie_data = np.genfromtxt('movie_timestamp.csv', delimiter=',')
timestamps = movie_data[1:, 0]
framecount = movie_data[1:, 1]
# フレーム表示時刻に線形補間
left_eye_x_interp = np.interp(timestamps_cut, sample_time_from_start, left_eye_x)
left_eye_y_interp = np.interp(timestamps_cut, sample_time_from_start, left_eye_y)
right_eye_x_interp = np.interp(timestamps_cut, sample_time_from_start, right_eye_x)
right_eye_y_interp = np.interp(timestamps_cut, sample_time_from_start, right_eye_x)
・・・としたのですがこれだとうまくいきませんでした.視線追跡開始前/終了後の動画フレーム表示時刻には補間ができないためエラーが生じました.そこで補間可能な動画タイムスタンプだけを条件づけで取り出します:
# 視線追跡中に表示されたフレームのみ抽出
timestamps_cut = (timestamps[np.logical_and
(timestamps > sample_time_from_start[0],
timestamps < sample_time_from_start[-1])])
framecount_cut = (framecount[np.logical_and
(timestamps > sample_time_from_start[0],
timestamps < sample_time_from_start[-1])])
図形合成forループ実行インデックス範囲の修正
動画タイムスタンプcsvには,その時刻に表示されたフレームの番号n(=1,2,3,...)を2列目に書き出しています.それを上記でタイムスタンプと同じ条件でトリミングしました.これが,図形合成操作対象の動画フレームのインデックスとして役立ってくれます.
したがってforループの書式は以下のとおりになります:
for frame_index in framecount_cut:
ところがnを1からスタートさせてしまった仕様のせいでpythonのインデックスがゼロから始まるのとミスマッチします.さらに補間コマンドの使用上,-1しただけだと最後の値がインデックスの範囲外になるというエラーが生じてしまったので,便宜的に-2します. これはこのプログラムのバグで,解決が求められます が,とりあえずはこれで動くので先に進みます笑.提示される動画がどの程度激しく動くものかにもよりますが,可視化のためだけならそんなに決定的な欠陥ではないです:
framecount_cut = framecount_cut.astype(int)-2
for frame_index in framecount_cut:
nanの回避
視線データにはnanが含まれていることがあります.nanの場合は図形合成できませんのでスキップします.4つの数値(左右のXY座標)1つでもnanなら操作をスキップしてしまうことにします.これは簡単です:
if ret:
if not np.isnan(left_eye_x_interp[frame_index]) and not np.isnan(left_eye_y_interp[frame_index]):
x1 = int(left_eye_x_interp[frame_index] * width) # 視線座標を取得
y1 = int(left_eye_y_interp[frame_index] * height)
cv2.circle(frame, (x1, y1), 10, (0, 255, 0), -1) # 視点を丸で描画
if not np.isnan(right_eye_x_interp[frame_index]) and not np.isnan(right_eye_y_interp[frame_index]):
x2 = int(right_eye_x_interp[frame_index] * width)
y2 = int(right_eye_y_interp[frame_index] * height)
cv2.circle(frame, (x2, y2), 10, (0, 0, 255), -1)
完成!!
ようやく完成しました.最終版の動画-視線合成プログラムを下に掲載します.
(折り畳み:クリックで展開)
import cv2
import numpy as np
# CSVファイルを読み込む
gaze_data = np.genfromtxt('gaze_data.csv', delimiter=',')
sample_time_from_start = gaze_data[1:, 0]
left_eye_x = gaze_data[1:, 1]
left_eye_y = gaze_data[1:, 2]
right_eye_x = gaze_data[1:, 3]
right_eye_y = gaze_data[1:, 4]
movie_data = np.genfromtxt('movie_timestamp.csv', delimiter=',')
timestamps = movie_data[1:, 0]
framecount = movie_data[1:, 1]
# 視線追跡中に表示されたフレームのみ抽出
timestamps_cut = (timestamps[np.logical_and
(timestamps > sample_time_from_start[0],
timestamps < sample_time_from_start[-1])])
framecount_cut = (framecount[np.logical_and
(timestamps > sample_time_from_start[0],
timestamps < sample_time_from_start[-1])])
# フレーム表示時刻に線形補間
left_eye_x_interp = np.interp(timestamps_cut, sample_time_from_start, left_eye_x)
left_eye_y_interp = np.interp(timestamps_cut, sample_time_from_start, left_eye_y)
right_eye_x_interp = np.interp(timestamps_cut, sample_time_from_start, right_eye_x)
right_eye_y_interp = np.interp(timestamps_cut, sample_time_from_start, right_eye_x)
# 動画の読み込み
cap = cv2.VideoCapture('sample.mp4')
# 動画のプロパティを取得
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 出力動画の設定
out = cv2.VideoWriter('out.mp4', cv2.VideoWriter_fourcc(*'mp4v'), fps, (width, height))
# 動画のフレームごとに処理
framecount_cut = framecount_cut.astype(int)-2
for frame_index in framecount_cut:
# 動画からフレームを読み込む
ret, frame = cap.read()
if ret:
if not np.isnan(left_eye_x_interp[frame_index]) and not np.isnan(left_eye_y_interp[frame_index]):
x1 = int(left_eye_x_interp[frame_index] * width) # 視線座標を取得
y1 = int(left_eye_y_interp[frame_index] * height)
cv2.circle(frame, (x1, y1), 10, (0, 255, 0), -1) # 視点を丸で描画
if not np.isnan(right_eye_x_interp[frame_index]) and not np.isnan(right_eye_y_interp[frame_index]):
x2 = int(right_eye_x_interp[frame_index] * width)
y2 = int(right_eye_y_interp[frame_index] * height)
cv2.circle(frame, (x2, y2), 10, (0, 0, 255), -1)
# 出力動画にフレームを追加
out.write(frame)
# 画面にフレームを表示
cv2.imshow('Frame', frame)
else:
break
# リソースの解放
cap.release()
out.release()
cv2.destroyAllWindows()
できた動画が下になります.

緑が左目,赤が右目での注視点です.この被験者の効き目がどうやら左なので,緑の点はよく花火の中央をとらえています.赤はけっこうムチャクチャですが,効き目が右の人が被験者になると赤のほうがうまく動画内のオブジェクトに重なります.また,細かく振動しているように見えますが,これは固視微動といって確かにある眼球運動で,アイトラッカーの仕様ではないです.人間の脳は実は手振れ補正機能が備わっており,この固視微動を勝手にキャンセルして視覚情報を処理するので自分たちでこれに気づくことはありません.
おわりに
なんとか3回の連載でおわりました.こういうカタチでの自作ノート共有が,これからTobii製アイトラッカーをお仕事に利用される方のお力になれば幸いです.
そして今回もGPTあってよかったとおおいに実感しました笑.おそらくそれぞれのコマンド要素は真面目に調べればしっかり見つかるものなはずですが,それをさっとダイジェストして出力してくれるものがあるととにかく早くて楽です.これがない時代に同じ作業に挑戦しようとしていたら5-10倍は苦労していたかと.