翻訳元ブログ(2017/5/23)
by Alex Kendall
https://alexgkendall.com/computer_vision/bayesian_deep_learning_for_safe_ai/
概要
機械学習のシステムにおいて、モデルが「推論できない」ものを理解するのはとても重要です。しかし、これまでのディープラーニングでは残念ながら「不確かさ」を排除できていませんでした。その成果が盲目的に取り上げられ、あたかも正確な推論ができるように言われていますが、必ずしもその通りではありません。例えば、これが悲惨な結果をもたらした例が以下の通りです。
1.2016年5月、電気自動車メーカーのテスラは運転支援システムで悲劇的な死亡事故を起こした。テスラ社の報告では、トレーラーの白い側面に明るい空が映り込み、「自動運転システムもドライバーも両方とも」トレーラーに気づかず、ブレーキをかけることができなかった、としている。
https://www.tesla.com/en_GB/blog/tragic-loss
2.2015年7月、米グーグルの写真編集アプリ「Googleフォト」の画像分類システムはアフリカ系アメリカ人の2人を「ゴリラ」と間違った認識をして、人種差別が問題となった。
https://www.usatoday.com/story/tech/2015/07/01/google-apologizes-after-photos-identify-black-people-as-gorillas/29567465/
調べれば他にも興味深いケースがたくさん出てくるでしょう。間違った推論に対してもっと「不確かさ」を正しく評価できていれば、上で述べたケースでも事故を避けられたかもしれません。
なぜ、不確かさを正確に理解することができていないのでしょうか?
その理由のひとつにガウス過程(ある確率分布にしたがう連続過程)における「不確かさ」を理解するための昔からある手法を、画像解析など高次元の入力を必要とするケースに適用できないためです。ディープラーニングは高次元データを効果的に理解するのには有効ですが、不確かさをモデル化することは困難です。
この投稿では**ベイジアン・ディープラーニング(Bayesian Deep Learning、BDL)**の研究分野を紹介し、不確かさをモデル化するディープラーニング・フレームワークを提供します。BDLを利用すれば不確かさを理解しつつ、最新鋭の結果を得ることができます。また、BDLはさまざまな種類の不確かさについてモデル化の手法を提案します。ここでは、主に以下の最近の論文を取り上げています。
What Uncertainties Do We Need in Bayesian Deep Learning for Vision? Alex Kendall and Yarin Gal, 2017.
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. Alex Kendall, Yarin Gal and Roberto Cipolla, 2017.


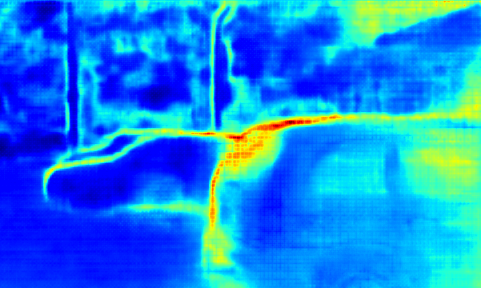
上図は深度(depth)推定の不確かさを理解することが重要な例を示しています。1つめの画像を入力としてベイジアン・ニューラルネットワークを通すと、2つ目の画像のように距離情報が得られます。それと同時に赤い車の光の反射や、透明な窓による「認識結果の不確かさ」も得られます。ありがたいことにベイジアン・ディープラーニングはシステムの認識が「どれくらい間違っているか(不確かさの度合い)」を認識してくれます。
不確かさのタイプ
不確かさにはいくつかタイプがあり、アプリケーションごとにどのタイプの不確かさが必要かを理解する必要があります。ここでは最も重要な以下の2種類の「不確かさ」を挙げます。
1.Epistemic uncertainty(認識における不確かさ)
2.Aleatoric uncertainty(偶発的な不確かさ)
認識における不確かさ
認識における不確かさは、訓練データには含まれないデータに対する不確かさを表現します。もし十分なデータがあればこの不確かさは減らすことができ、しばしば「モデルの不確かさ」とも呼ばれます。認識の不確かさは以下のようなケースにおいて重要となります。
- 安全性が重大な意味をもつアプリケーション(自動運転システムなど)
- 小さな訓練データセットで学習したモデルを使用するとき
偶発的な不確かさ
偶発的な不確かさは、データが説明できない情報に対する不確かさを表現します。例えば、オクルージョンの問題(物体に隠されて一部が見えないこと)や、光の加減(陰になっていたり露光が強すぎたり)などの問題があります。偶発的な不確かさは次のようなケースで重要となります。
- 十分に大量のデータセットで訓練し、認識の不確かさが除外できるモデルを使うとき
- リアルタイム処理のアプリケーション。入力データに対してモンテカルロサンプリングをする余裕がなく、決定論的に推論結果を出す必要があるとき。
偶発的な不確かさは、以下の2つのサブカテゴリに分類されます。
A.データ依存の不均一分散(Heteroscendastic)をもつ不確かさ:
この不確かさは入力データに依存し、不確かさの指標をモデルの出力として得ることができる。
B.タスク依存の均一分散(Homoscendastic)をもつ不確かさ:
この不確かさは入力データに依存せず、タスク毎に異なる不確かさ。入力データに依存しないためモデルの出力としては得られない。後述するようにマルチタスク学習において役立つ指標。
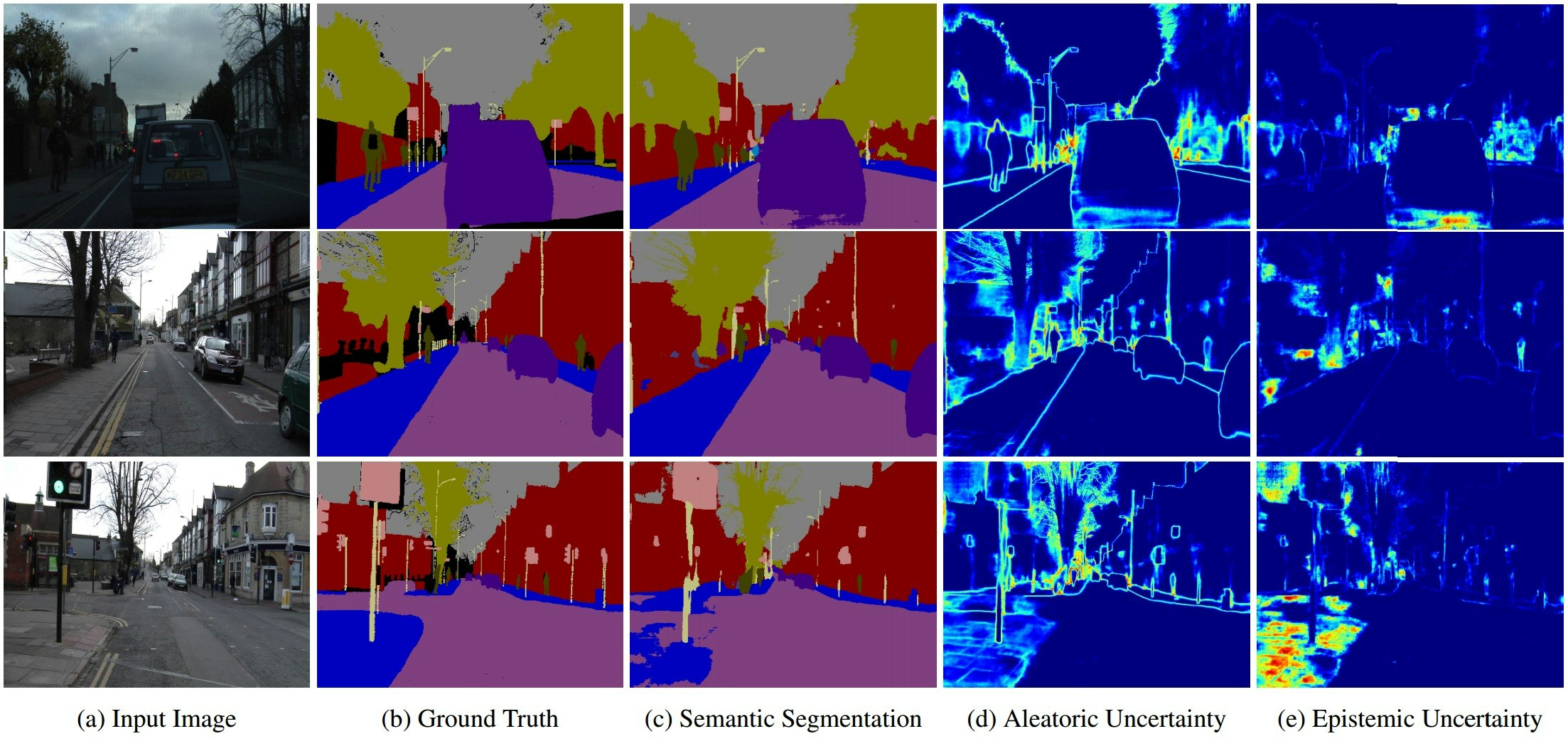
上図はセマンティックセグメンテーションにおける「偶発的な不確かさ」と「認識における不確かさ」の違いを示しています。偶発的な不確かさ(d)は、ラベルにノイズが乗るオブジェクト境界付近を捉えていることが分かります。また(c)と(e)の一番下の図は、モデルが歩道について学習不足のためにセグメンテーションに失敗している例と、それに相当する認識における不確かさの増加を示しています。
次の章ではベイジアン・ディープラーニングを用いて「不確かさ」のモデル化手法について述べます。
ベイジアン・ディープラーニング
ベイジアン・ディープラーニングは、ディープラーニングとベイズ確率論の交差点に位置する分野で、ディープラーニングのアーキテクチャから原理的に不確かさを推論します。ディープラーニングが深い階層的表現によって複雑なタスクをモデル化する一方で、ベイジアン・ディープラーニングはマルチモーダルに事後分布を推論することができます。
ベイジアンディープラーニングは典型的には以下の方法によって不確かさを推論します。
- モデルの重みを確率分布で表す
- 出力の確率分布そのものを学習する
以下では、不確かさのモデル化の手法について述べます。
不確かさのモデル化
データ依存の偶発的な不確かさは、損失関数を変更することによりモデル化できます。回帰問題タスクでは、通常「ユークリッドL2損失」などが使われますが、不均一分散をもつ不確かさを学習するには損失関数を以下のように置き換える必要があります(訳注:モデリングは基本的には均一分散性を仮定している。つまり、モデルの推論結果と観測結果との誤差は一定の分散をもつことを意味している。この仮定が満たされない観測結果を説明するためには、不均一分散の概念を導入する必要がある。):
\begin{align}
Loss &= \frac{|| y - \hat{y} ||_2}{2 \sigma ^2} + \log (\sigma ^2)\\
\end{align}
モデルは観測値 $y$ の平均値 $\hat{y}$ と分散値 $\sigma^2$ を推論します。
この式からわかることは、何か異常なデータが来たときにモデルは $\sigma^2$ の大きな値を推論し、残差項の損失への影響を減衰させます。(訳注:このことにより正常なデータの推論と、偶発的な異常データかどうかの推論を分離して学習することができる、と解釈した。)$log(\sigma^2)$ にすることにより不確かさが無限大に発散することを防いでいます。上式を損失関数することにより、モデルはデータ依存の不均一分散を学習します。
均一分散の偶発的な不確かさも、同様にモデル化が可能ですが上記の $\sigma$ のような不確かさのパラメータをモデルに組込むことはできず、訓練のできないフリーパラメータとして調整する必要があります。
一方、認識の不確かさはモデル化することがはるかに困難で、ネットワークモデルおよびそのパラメータの確率分布をモデル化する必要があります。一般的な手法として、モデルのパラメータをベルヌーイ分布に置き換えたモンテカルロ・ドロップアウト・サンプリングがあります。以下の論文を参照して下さい。
Monte Carlo dropout sampling
http://proceedings.mlr.press/v48/gal16.pdf
この論文はドロップアウトによりモデルが学習できることを示しています。モデルのテスト時に出力を平均化するのではなく、複数の「ランダム・ドロップアウト・マスク」を用いてネットワークから確率的に出力をサンプリングします。このときの出力分布がモデルの「認識の不確かさ」を反映しています。
この前のセクションでは、偶発的な不確かさと認識の不確かさを定義する特性について説明しました。私たちの論文の興味深い結果のは、上記のモデル化によりこれらの特性を満たす結果が得られたことです。
以下では、単眼カメラによる深度の回帰モデルを、2つの異なるデータセットで学習させた例を示します。
| Training Data | Testing Data | 偶発的な不確かさ | 認識の不確かさ | |
|---|---|---|---|---|
| A | DataSet #1で学習 | DataSet #1でテスト | 0.485 | 2.78 |
| B | 25%のDataSet #1で学習 | DataSet #1でテスト | 0.506 | 7.73 |
| C | DataSet #1で学習 | DataSet #2でテスト | 0.461 | 4.87 |
| D | 25%のDataSet #1で学習 | DataSet #2でテスト | 0.388 | 15.0 |
この結果が示しているのは、少ないデータで学習したり、学習データセットと大きく異なるデータでテストすると「認識の不確かさ」が大幅に増加することです。それに対して「偶発的な不確かさ」は比較的一定となっていますが、同じセンサのデータで同じタスクのテスト結果なので当然の結果です。
マルチタスク学習の不確実性
次に、これらのアイデアをマルチタスク学習の応用した興味深い例を挙げましょう。
マルチタスク学習の目的は、ひとつの表現から複数の特徴を学習することにより、学習効率と予測精度を向上させることにあります。自然言語処理(Natural Language Processing, NLP)から音声認識、コンピュータビジョンまで機械学習の多くの分野で使われている技術です。マルチタスク学習は、ロボティクスのように処理速度に制約のあるシステムで非常に重要となります。全てのタスクを1つのモデルにまとめることで、計算量が削減され、システムをリアルタイムで処理することができます。
ほとんどのマルチタスクモデルは、各損失の加重和により異なるタスクを学習します。しかしこのモデルの予測精度は、各タスクの損失に対する相対的な重みに強く依存します。これらの重みを手動で調整することは困難で手間のかかるプロセスであり、そのためマルチタスク学習は実際には行われることが稀でした。
私たちの最近の論文では、均一分散の不確かさ(タスク依存の不確かさ)を利用してマルチタスク学習モデルの損失に対する重みづけをする方法を提案しています。均一分散は入力データに依存しないため、タスクの不確実性と解釈することができます。これにより、様々なタスクの同時学習における損失を、原理的に設定することができます。
私たちはシーン理解においてマルチタスク学習を研究しています。シーン理解のアルゴリズムは、シーンのジオメトリ(物体の構造や配置)とセマンティクス(物体のもつ意味)を同時に理解する必要があります。これは興味深いマルチタスク学習の問題となります。なぜなら、シーン理解には様々な単位や尺度での回帰タスク、分類タスクの協調的な学習が含まれるからです。驚くべきことに、私たちのモデルはマルチタスクの重みづけを学習し、個別のタスクで学習されたモデルよりも優れていることを示しました。
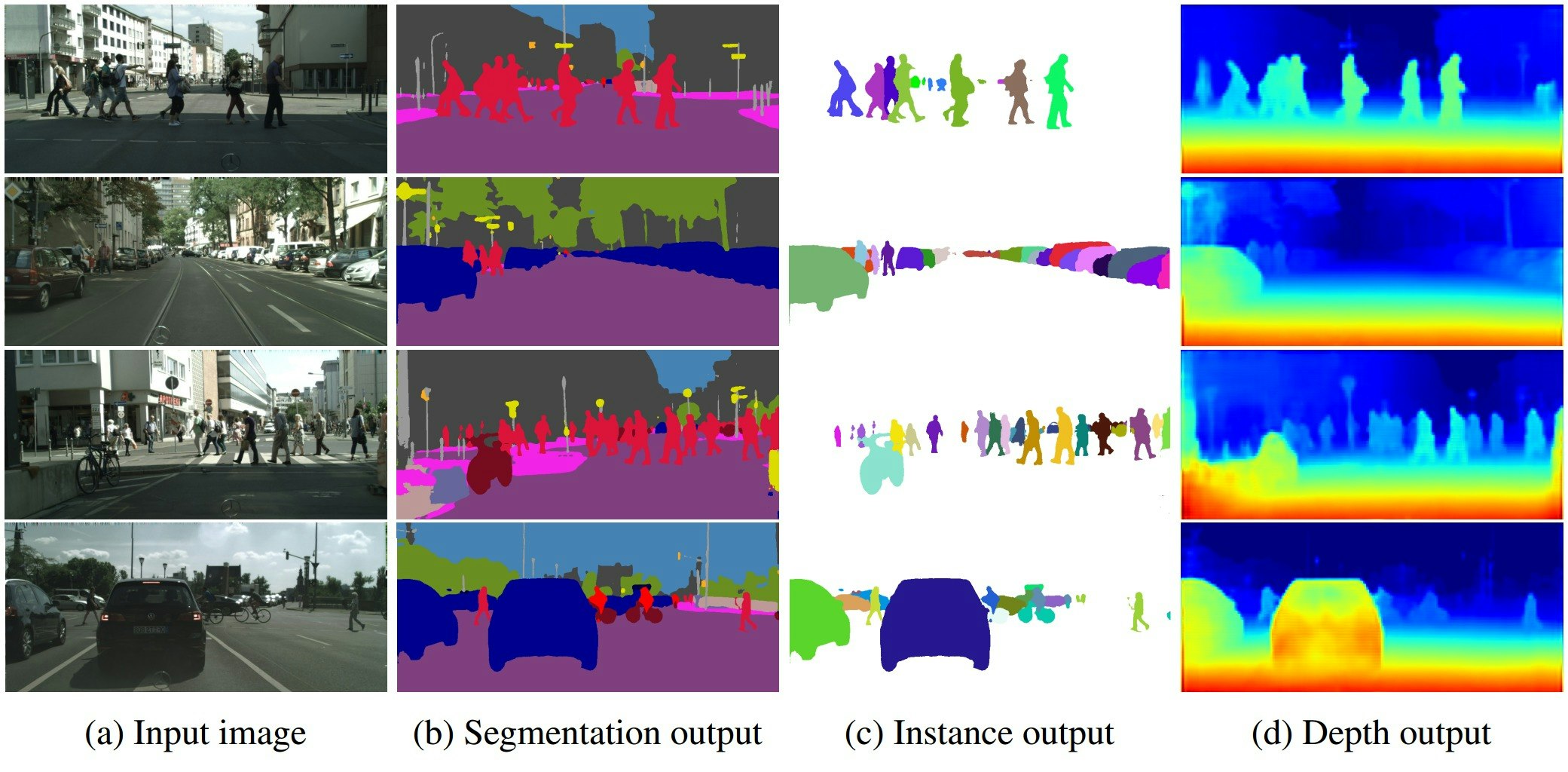
マルチタスク学習は、異なるタスクの結果を統合した表現を学習できるため、深度認識の滑らかさと精度を向上します。セグメンテーションの精度向上も同様に可能です。
挑戦的な研究課題
私はベイジアン・ディープラーニングは今日の全てのAIシステムに必要だと考えています。しかしいくつかの非常に困難な課題が残っています。
-
リアルタイムでの「認識の不確かさ」の予測は技術的に困難である。そのためロボット・アプリケーションに予測モデルを組込むことができていない。サンプリングの効率を上げる、モンテカルロを用いた推論に頼らない新手法があれば非常に有益だろう。
-
BDLのベンチマークが必要。ImageNetのようなベンチマークがコンピュータビジョンに与えた影響を見ると、モデルを迅速に開発するために精度が定量化して見えることは非常に重要である。BDLモデルの不確かさの精度を合わせるためのベンチマークが必要。
-
マルチモーダルな分布に対するよりよい推論のための技術が必要。たとえば以下の論文で設定したYarinのデモを参照のこと。ここではMCドロップアウトの推定がモデル化できないマルチモーダルデータを示しています。
http://htmlpreview.github.io/?https://github.com/yaringal/HeteroscedasticDropoutUncertainty/blob/master/demos/heteroscedastic_dropout_reg.html