アドベントカレンダーということで、日曜大工的に。
こちらのページは、Databricksリリースノートのページをパーシングして自動で更新されるようになっています。
注意
- こちらのページの更新は予告なく停止される可能性があります。
- こちらのページをストックしても更新の通知は来ません。更新APIにそのオプションがありませんでした。
モチベーション
- Databricksの機能更新の頻度は高く、頻繁にリリースノートが更新されるのですが英語のみです。
- 通知の仕組みの一つとして、更新情報を翻訳してQiitaのページに反映させようと思いました。本当はRSSとかにしたいのですが、今後の宿題ということで。
以降で実装を説明します。スクレイピングを行ないますので用法用量にはご注意ください。
データベースの準備
db_name = "takaaki_yayoi"
# specify catalog name
spark.sql(f"USE CATALOG users")
spark.sql(f"CREATE DATABASE IF NOT EXISTS {db_name}")
spark.sql(f"USE {db_name}")
print(f"database_name: {db_name}")
%sql
CREATE TABLE IF NOT EXISTS databricks_release_notes_jpn (
year INT,
month INT,
date DATE,
title STRING,
id STRING,
url STRING,
inserted TIMESTAMP,
title_japanese STRING,
summary STRING,
summary_japanese STRING,
user_impact STRING
);
from pyspark.sql.types import *
def is_exists_in_db(year, month, id):
"""テーブルに格納済みかどうかをチェック
"""
sql = f"SELECT * FROM databricks_release_notes_jpn WHERE year={year} AND month={month} AND id='{id}'"
# print(sql)
result = spark.sql(sql)
if result.count() == 0:
return False
else:
return True
def insert_into_db(
year, month, date, title, id, url, title_japanese, summary, summary_japanese, user_impact
):
"""テーブルに格納
"""
sql = "INSERT INTO databricks_release_notes_jpn(year, month, date, title, id, url, inserted, title_japanese, summary, summary_japanese, user_impact) VALUES (:year, :month, to_date(:date), :title, :id, :url, current_timestamp(), :title_japanese, :summary, :summary_japanese, :user_impact)"
#print(sql)
result = spark.sql(
sql,
args={
"year": year,
"month": month,
"date": date,
"title": title,
"id": id,
"url": url,
"title_japanese": title_japanese,
"summary": summary,
"summary_japanese": summary_japanese,
"user_impact": user_impact
},
)
ヘルパー関数
import calendar
def month_index(month_name):
"""月の英語表記を数字に変換
"""
# https://stackoverflow.com/questions/3418050/how-to-map-month-name-to-month-number-and-vice-versa
return list(calendar.month_name).index(month_name.capitalize())
基盤モデルAPIによる翻訳、文の生成
基盤モデルAPIを使ってサクッと翻訳します。せっかくなので、新機能がユーザーに与えるインパクトの文章も生成してもらいます。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
def translate(text):
"""翻訳
"""
response = w.serving_endpoints.query(
name="databricks-meta-llama-3-3-70b-instruct",
messages=[
ChatMessage(
role=ChatMessageRole.SYSTEM, content="あなたは有能な翻訳家です。与えられた英語を日本語に翻訳します。HTML文字列には変更を加えません。"
),
ChatMessage(
role=ChatMessageRole.USER, content=text
),
],
max_tokens=500,
)
return response.choices[0].message.content
def generate_user_impact(text):
"""ユーザーへのインパクトを記述
"""
response = w.serving_endpoints.query(
name="databricks-meta-llama-3-3-70b-instruct",
messages=[
ChatMessage(
role=ChatMessageRole.SYSTEM, content="あなたはDatabicksの専門家です。与えられたリリースノートを読んで、Databricksユーザーに対する影響を簡潔に回答します。"
),
ChatMessage(
role=ChatMessageRole.USER, content=text
),
],
max_tokens=500,
)
return response.choices[0].message.content
BS4によるリリースノートのスクレイピング
ある意味、ここが処理の肝です。以下の記事を参考にさせて頂きながら実装しました。
- 図解!Python BeautifulSoupの使い方を徹底解説!(select、find、find_all、インストール、スクレイピングなど) - ビジPy
- [Python入門]Beautiful Soup 4によるスクレイピングの基礎:Python入門(2/2 ページ) - @IT
- [解決!Python]re.search/re.match関数と正規表現を使って文字列から部分文字列を抽出するには:解決!Python - @IT
import requests, bs4
import re
import urllib
import datetime
def parse_release_note(year, month):
return_list = []
target_url = f'https://docs.databricks.com/ja/release-notes/product/{year}/{month}.html'
# ページの存在確認
response = requests.get(target_url)
if response.status_code == 404:
print('Page not found')
else:
# 文字列の月を数値に変換
month_no = month_index(month)
res = requests.get(target_url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
sections = soup.select("div.section")
for section in sections:
# skip the first div
if section.get("id") != f"{month}-{year}":
#print("##################")
#print(section.getText())
#print("##################")
# 要素の抽出
id = section.get("id")
url = target_url + "#" + id
title = section.select("h2")[0].getText()
title_japanese = translate(title)
date = section.select('p > strong')[0].getText().replace("th", "").strip()
date = datetime.datetime.strptime(date, "%B %d, %Y").strftime('%Y-%m-%d') # Y-M-Dに変換
summary = str(section.select('p')[1])
# 新規リリースの場合
if is_exists_in_db(year, month_no, id) == False:
# 相対パスを絶対パスに変換
results = re.finditer('href="([^"]+)"', summary)
#print(result.group(1))
if results is not None:
for result in results:
relative_url = result.group(1)
absolute_url = urllib.parse.urljoin(target_url, relative_url)
summary = summary.replace(relative_url, absolute_url)
summary_japanese = translate(summary)
user_impact = generate_user_impact(title_japanese + ":" + summary_japanese)
#print(title_japanese, date, summary_japanese, user_impact)
return_list.append({"title": title, "date": date, "summary": summary})
# DBに登録
insert_into_db(year, month_no, date, title, id, url, title_japanese, summary, summary_japanese, user_impact)
return return_list
あとでジョブにするので、処理を行う日付の情報をパラメーターとして渡すようにしています。
import datetime
dt_now = datetime.datetime.now()
current_year = dt_now.strftime('%Y')
current_month = dt_now.strftime('%B').lower()
print(current_year, current_month)
2024 december
こちらが処理のエントリーポイントになります。
return_list = parse_release_note(current_year, current_month)
print("新着記事:", len(return_list))
# 新着記事がない場合には終了
if len(return_list) == 0:
dbutils.notebook.exit("no new articles found")
Qiitaへの投稿
参考記事
リリースノートを格納しているテーブルからデータを取り出します。
release_notes = spark.sql("SELECT * FROM databricks_release_notes_jpn ORDER BY DATE DESC LIMIT 100").toPandas().to_dict("recoreds")
release_notes
あとは記事本文を組み立てて投稿するだけです。
post_str = "Databricksのリリースノートをスクレイピングし、生成AIによる翻訳を行い、ユーザーへのインパクトを説明する文を生成しています。すべての処理は自動で行われています。\n\n:::note\n**注意**\n翻訳やインパクトの説明文は生成AIによるものですので、詳細は原文を確認ください。\n:::\n\n"
for release in release_notes:
#print(release)
url = ""
post_str += f"# [{release['title_japanese']}]({release['url']})\n**{release['date']}**\n{release['summary_japanese']}\n\n**ユーザーへのインパクト**\n\n{release['user_impact']}\n\n"
post_str
import requests
import pprint
url_items = 'https://qiita.com/api/v2/items/57923e2d159a65a22118'
headers = {'Authorization': 'Bearer <Qiita APIトークン>'}
item_data = {
'title': 'Databricksリリースノート(毎日更新)',
'body': post_str,
'private': False,
'tags': [{'name': 'Databricks'}],
'coediting': False,
}
r_post = requests.patch(url_items, headers=headers, json=item_data)
pprint.pprint(r_post.json())
ジョブの作成
これでロジックが固まったので、ノートブック右上のScheduleボタンでジョブ化します。
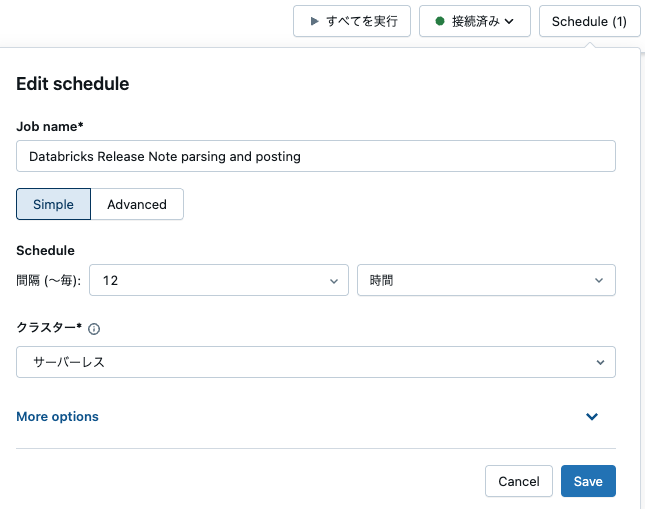
これで定期的にリリースノートページを解析し、翻訳と拡張を行いQiitaに記事として反映されるようになりました。
