Databricks Liquid Clustering. Have you ever wondered if there’s a… | by Rahul Soni | Mediumの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
データレイクハウスの世界における過酷なデータパーティショニングの課題に対する動的なソリューションがあればと思ったことはありませんか?
ええ、やったのです!お話ししましょう。
固定データレイアウトの課題
このグラフを見てみましょう。
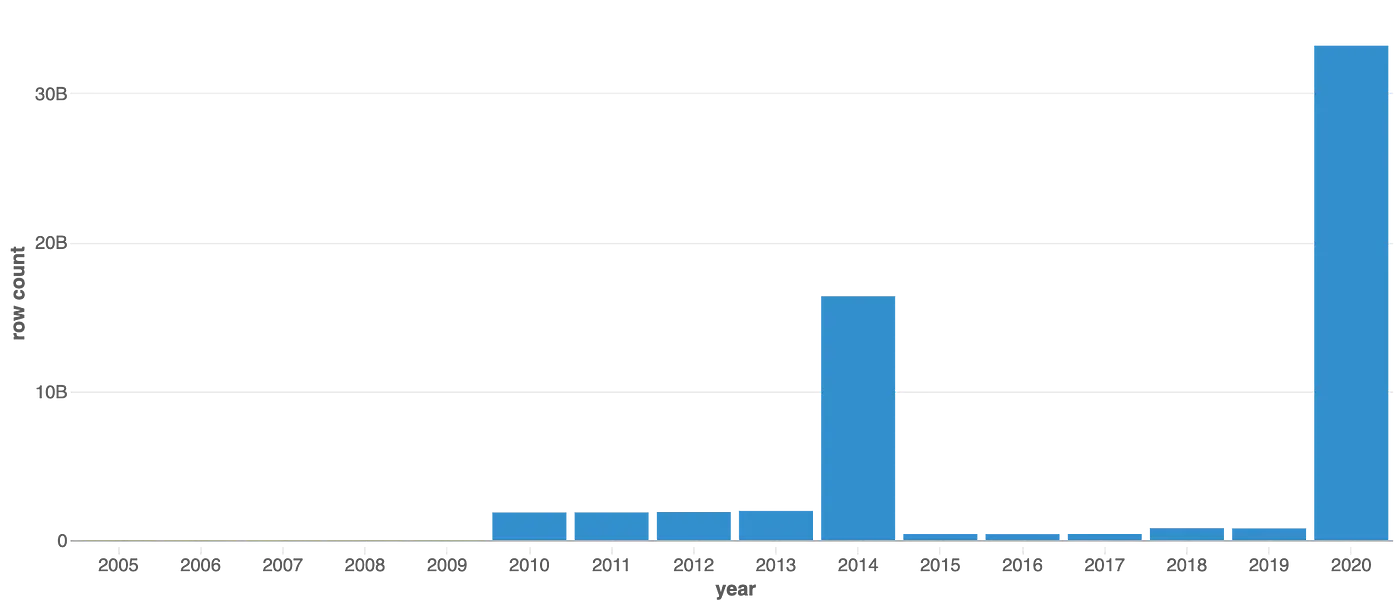
kaggle_partitioned tableの年ごとの行数
このグラフは、テーブルの年ごとの行数を反映しており、データの分布において大きな偏りがあることがわかります。データ利用者が自分達のクエリーでyearカラムを頻繁に使う場合には、この偏りは特に関係してきます。
このテーブルは、作成時にはyearとmonthカラムを用いてパーティションが作成されました。このためのDDLは以下のようなものになります。
%sql
CREATE TABLE kaggle_partitioned (
year_month STRING,
exp_imp TINYINT,
hs9 SMALLINT,
Customs SMALLINT,
Country BIGINT,
quantity BIGINT,
value BIGINT,
year STRING,
month STRING
) USING delta PARTITIONED BY (year, month);
ここで問題になるのは、テーブルの前データサイズの約83%が2つのパーティションによって占められるということです。
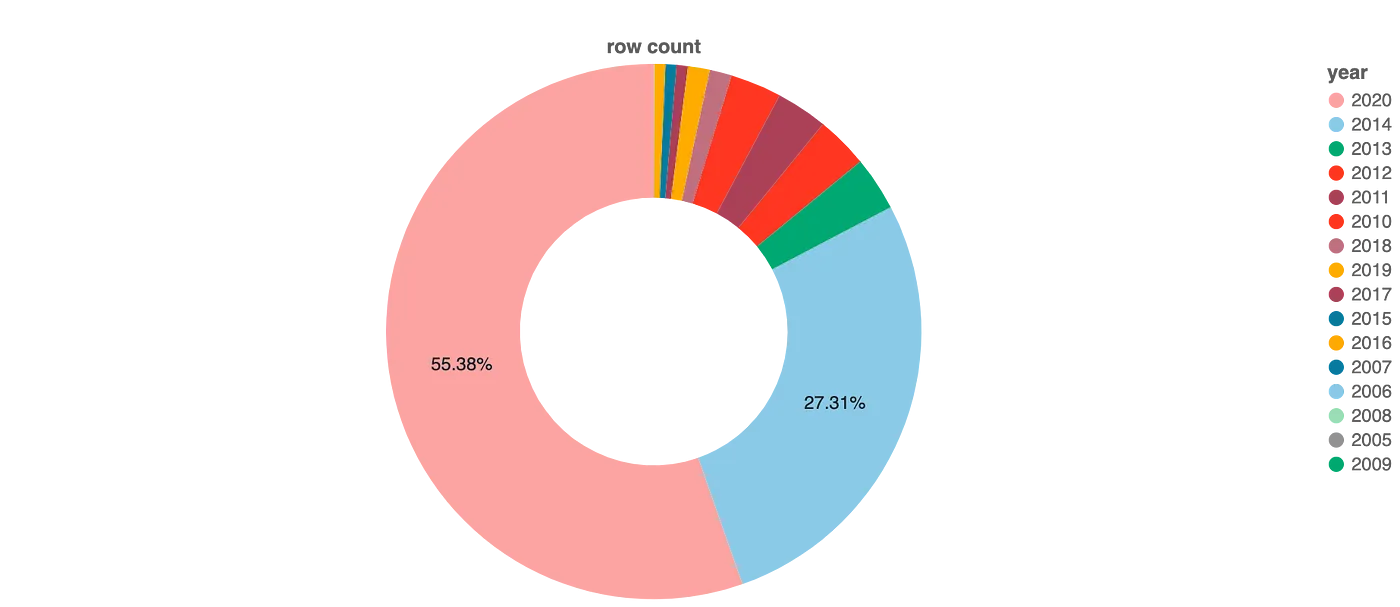
年ごとのデータ分割
上の情報に基づき、このテーブルはパーティション不足、あるいはパーティション過多だと思いますか?
このテーブルのデータ分布をより深くみてみましょう。以下のチャートは、それぞれの年における月毎のスプリットを示しています。
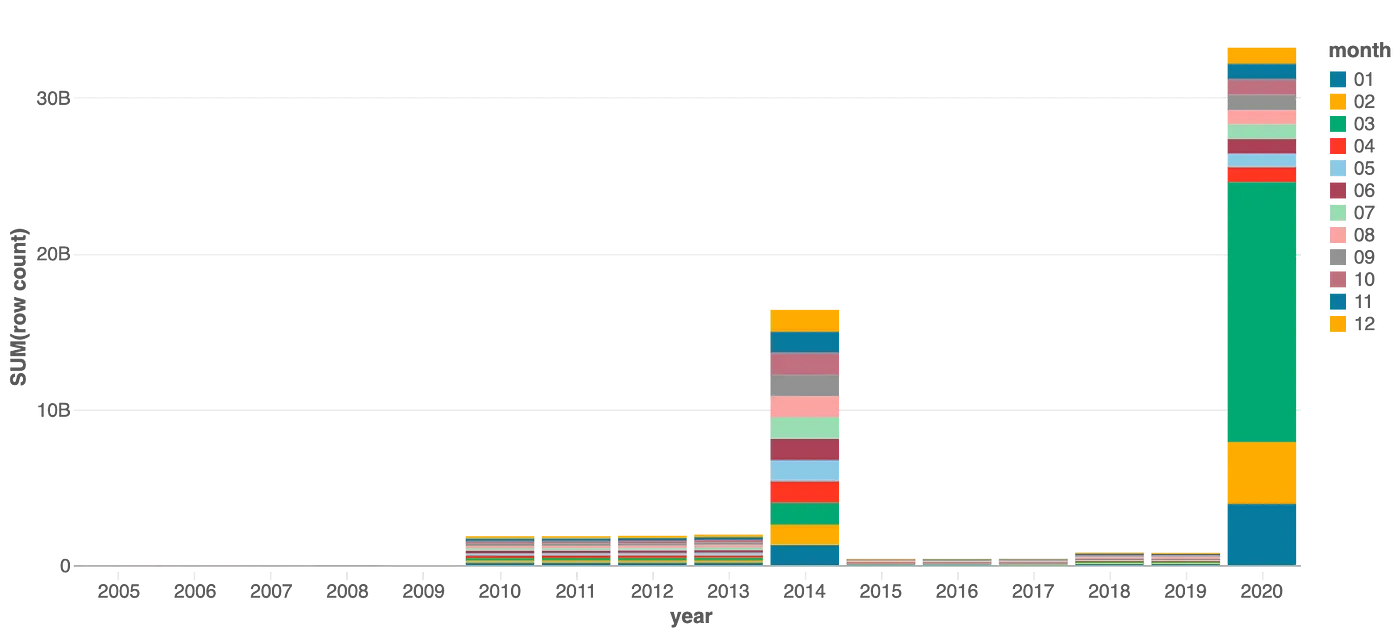
データ分布のビジュアル表現をさらにスライスすることで、2020年では多くのデータが3月に含まれており、1月と2月がそれに続き、他の月はさらに小さなパーティションを構成しています。
だとした場合、このテーブルは過度にパーティショニングされているでしょうか?パーティション不足でしょうか?あるいは両方でしょうか?
以下の図で何か思いつきますか?理解できますか?
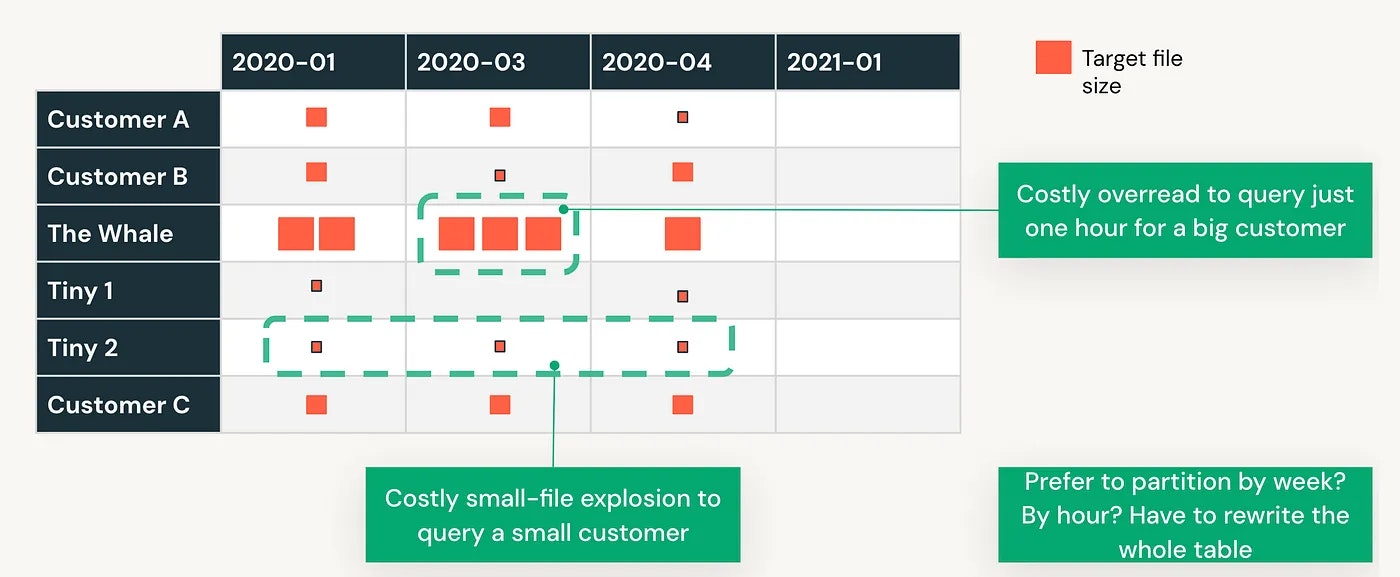
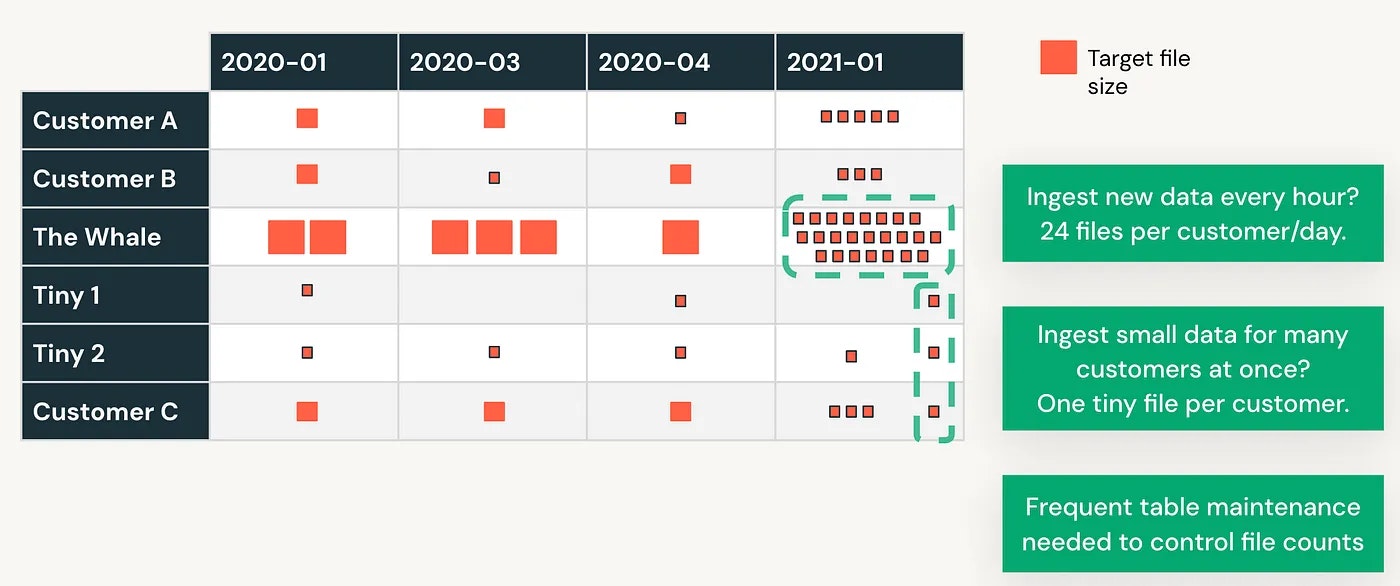
現行のパーティショニング戦略では、
- 2020-03のようなパーティションでは、例えば1時間のデータに対するクエリーのために大量のデータを読み込まなくてはなりません。
- 全く逆の視点では、データ量の少ない顧客向けのクエリーを提供するために、複数のパーティションを操作し、大量の小規模ファイルをスキャンしなくてはならないこともあります。
- 最後になりますが、週/日/月でこのテーブルを再パーティショニングする必要がある場合、テーブル全体を再書き込みしなくてはならないでしょう。再度です!
このテーブルにおけるデータ書き込みのシナリオを議論しましょう。以下の図では、指摘したいと思っていることを要約しているので、本文には記載しません;)
そこで!もう一度この記事の最初の行を繰り返しましょう!
データレイクハウスの世界における過酷なデータパーティショニングの課題に対する動的なソリューションがあればと思ったことはありませんか?
リキッドクラスタリングにようこそ!
過度の定常的な監視や調整を全く必要とすることなしにデータレイアウトに対する意思決定をシンプルにし、クエリーパフォーマンスを改善します。
どのように実現しているのでしょうか?
- 高速: 適切にチューニング、パーティショニングされたテーブルと比較して高速な書き込み、同等の読み込み
- 自己チューニング: パーティショニング過多、パーティショニング不足の回避
- インクリメンタル: 新規データに対する自動で部分的なクラスタリング
- 偏りに対する耐性: 一定のファイルサイズを生成し、書き込み増加を抑制
- 柔軟: クラスタリングカラムを変更したいですか?問題ありません!
- 同時実行性の改善: お使いのテーブルに対する行レベルの同時実行性を実現
より詳細を理解していきましょう。上で触れたサンプルのレイアウト図を使います。
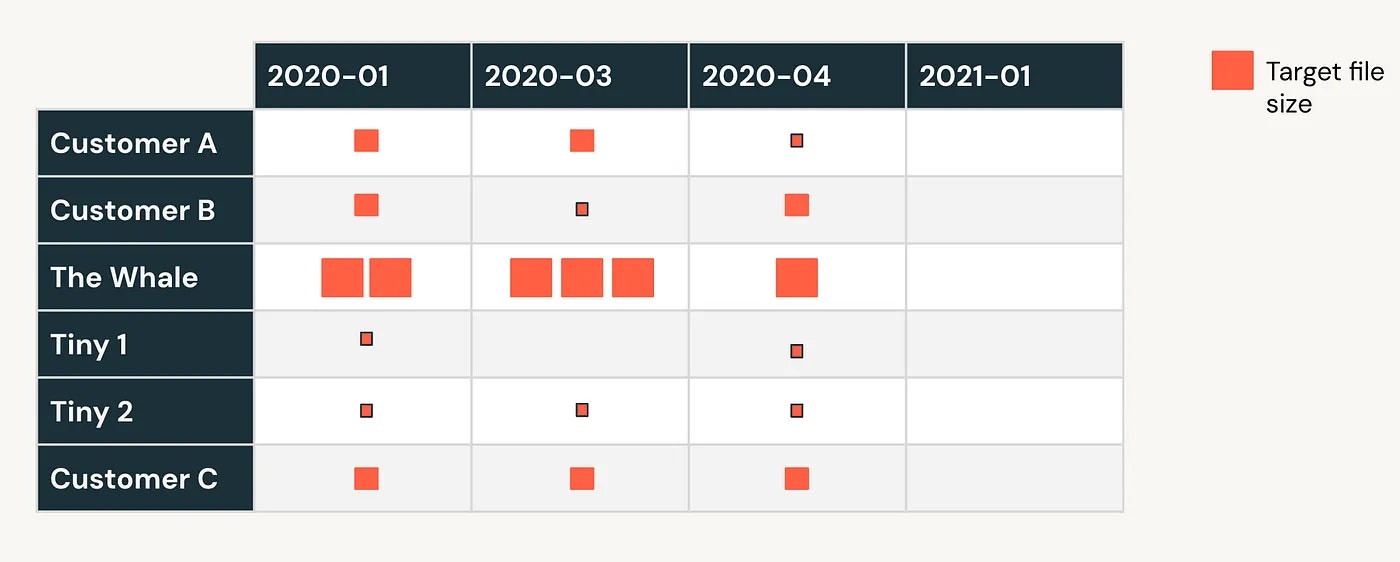
では、ここでリキッドクラスタリングはどのような助けになるのでしょうか?以下の図をご覧ください! リキッドクラスタリングは、効率的にクラスタリングとファイルサイズのバランスをとります。
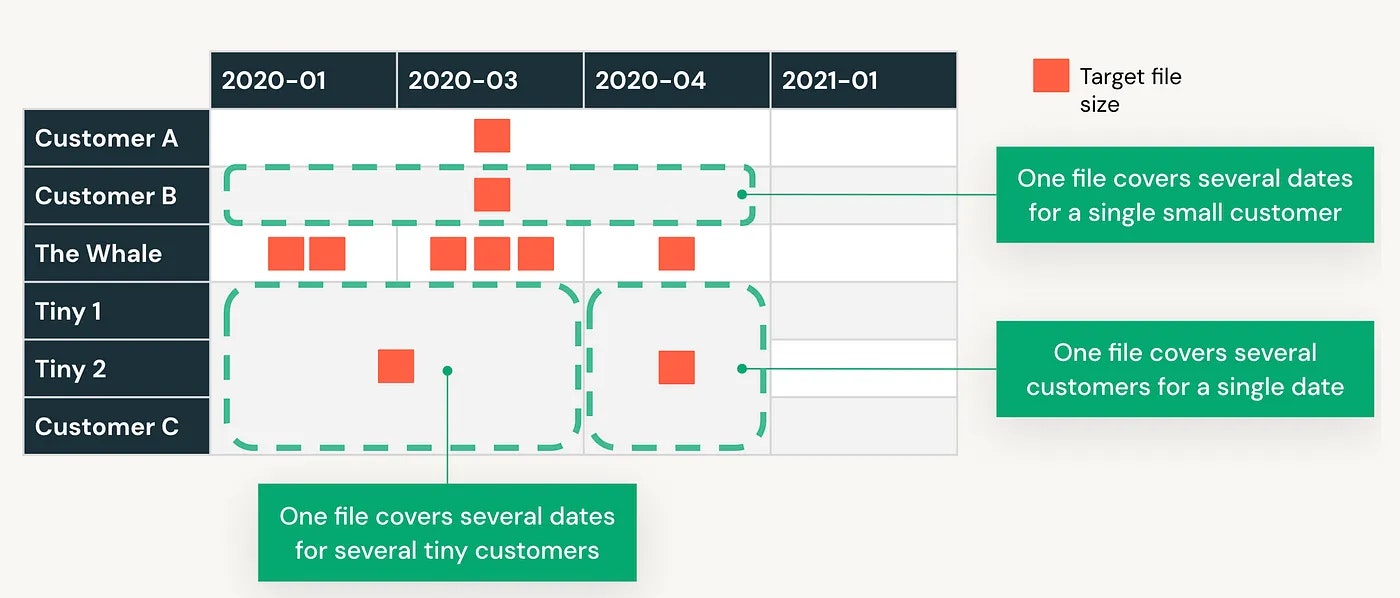
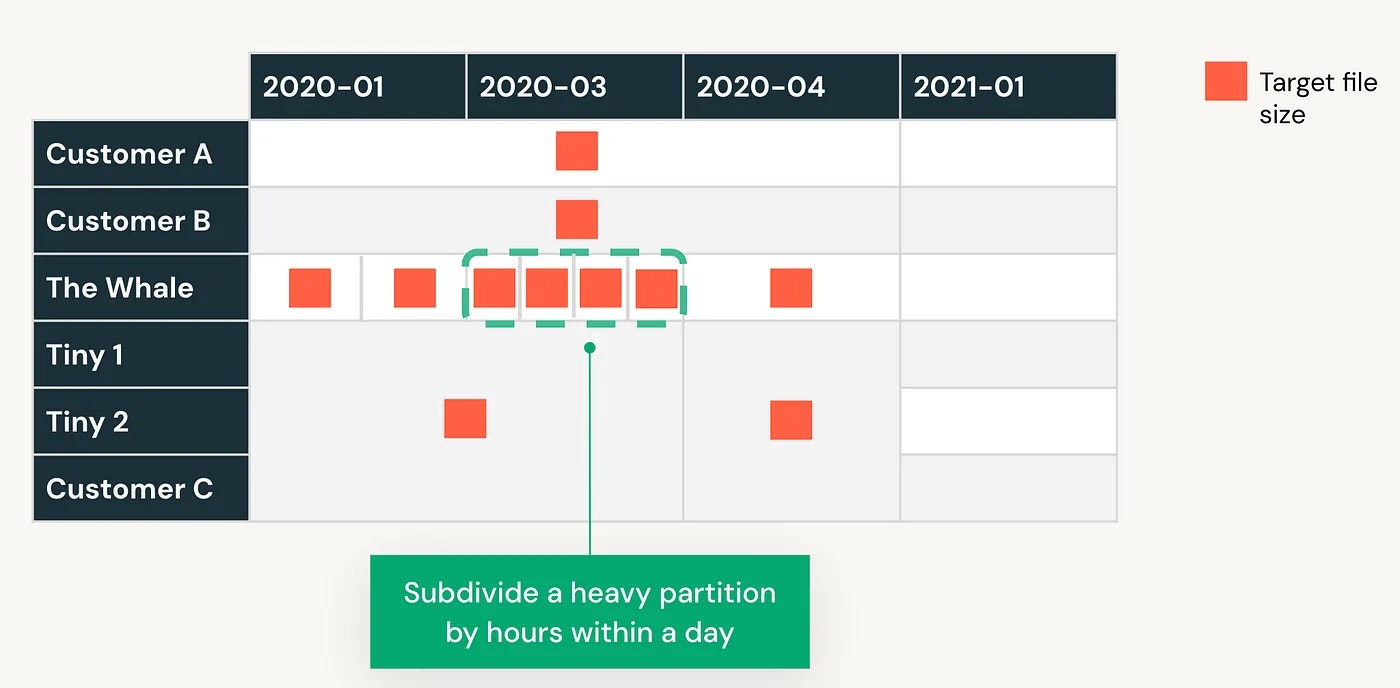
自動で小規模なパーティションを取り扱うだけではなく、大規模なパーティションから時間単位のデータだけを取得したい場合にクエリーをより効率的にするために、重いパーティションはさらに分割されます。
実践しましょう!パーティショニングされたテーブルのファイルサイズ分布はこちらとなります。
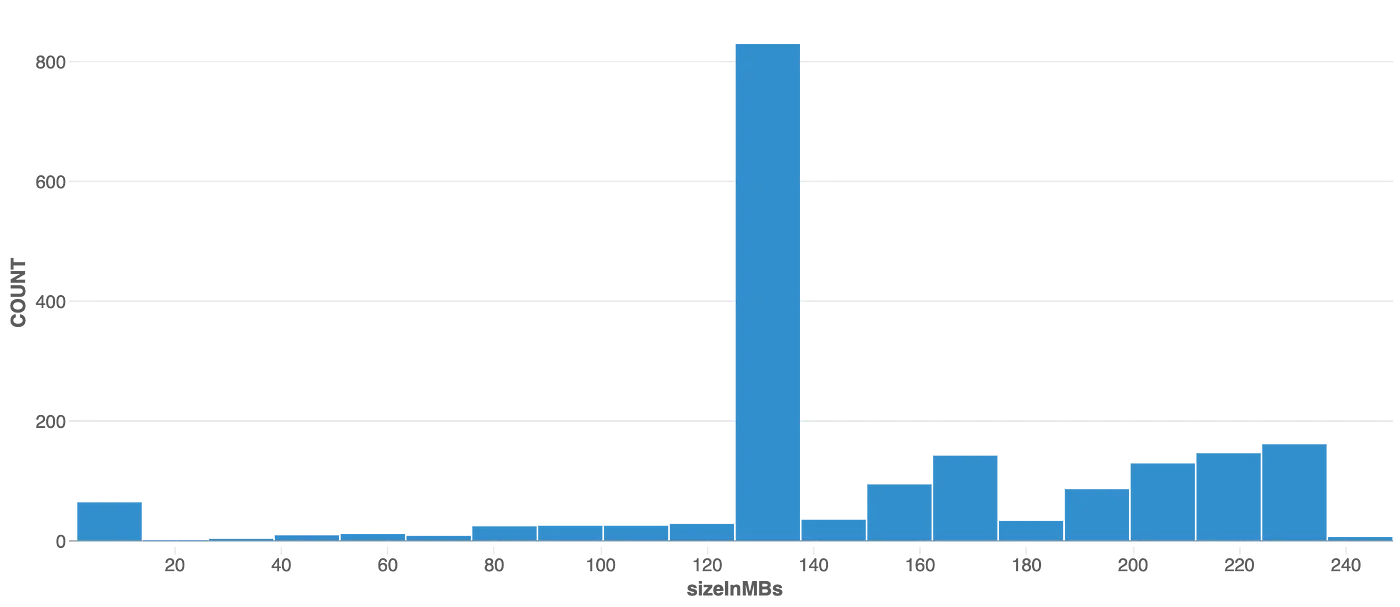
kaggle_partitionedテーブルのファイルサイズ分布
このパーティショニングされたテーブルからクラスタリングされたテーブルを作成しましょう。CTASを使います。
CREATE TABLE kaggle_clustered CLUSTER BY(year, month) AS
SELECT
*
FROM
kaggle_partitioned;
クラスタリングされたテーブルのファイルサイズの分布は以下のようになります。
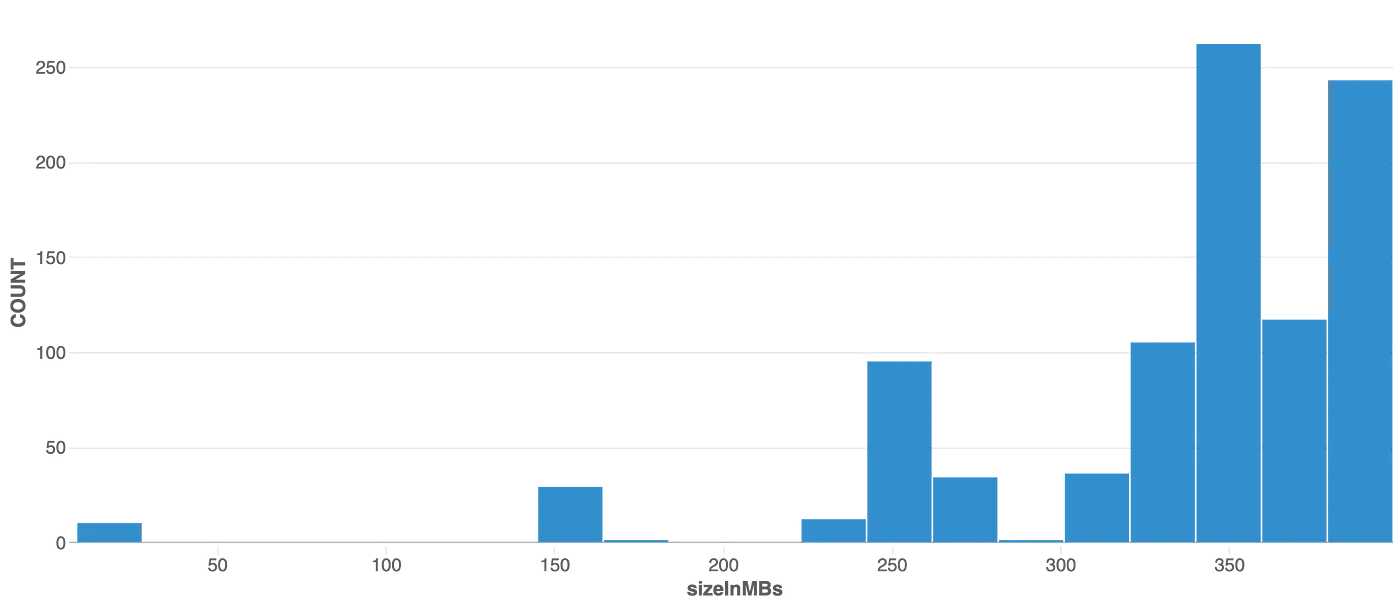
より最適化されたファイルを作成するために、小さなファイルの多くは一緒にマージされていることが明白です。
注意
両方のテーブルではOPTIMIZEが実行されています。
また、リキッドクラスタリングは、部分的/遅延クラスタリングを活用することで、データ取り込みをより効率的にする助けにもなります。
どのように動作するのかを理解しましょう。
- 2021-01は私のパーティショニングされたテーブルにおいてデータを持たないパーティションです。
- その日付レンジに対してデータの取り込みをスタートすると、すべての顧客をカバーする一つのファイルが作成されます。
- データサイズが増加し始めると、リキッドクラスタリングは顧客に対してファイルを分割し始めます。
- 分割オペレーションは、時には小規模なファイルを生み出しますが、テーブルのメンテナンス処理が自動でこれらの小規模なファイルを大規模なファイルにマージし、読み込みパフォーマンスにインパクトを与えないようにします。
よし!それでは自分のテーブルに適用するにはどうしたらいいですか?
注意してください!リキッドクラスタリングが有効化されたDeltaテーブルの作成、書き込み、OPTIMIZEの実行にはDatabricks Runtime 13.3 LTS以降が必要です。
まずは大事なことから始めましょう! クラスタリングは、パーティショニングやZORDERとは互換性がなく、Databricksのクライアントはお使いのテーブルのデータに対するすべてのレイアウトと最適化オペレーションを管理する必要があります。
リキッドクラスタリングが有効化されたDeltaテーブルの作成方法を見ていきましょう。
--Create an empty table
CREATE TABLE table1(col0 int, col1 string) USING DELTA CLUSTER BY (col0);
--Using a CTAS statement
CREATE EXTERNAL TABLE table2 CLUSTER BY (col0) --specify clustering after table name, not in subquery
LOCATION 'table_location' AS
SELECT
*
FROM
table1;
--Using a LIKE statement to copy configurations
CREATE TABLE table3 LIKE table1;
注意
リキッドクラスタリングを有効化して作成されたテーブルでは、作成時に様々なDeltaテーブルの機能が付与され、Delta writerバージョン7とreaderバージョン3が用いられます。テーブルのプロトコルのバージョンはダウングレードできず、クラスタリングが有効化されたテーブルは、すべての有効化されたDeltaリーダープロトコルテーブル機能をサポートしないDelta Lakeクライアントによって読み込むことができません。Azure Databricks で Delta Lake 機能の互換性を管理する方法をご覧ください。
クラスタリングの起動方法
テーブルに対してシンプルにOPTIMIZEコマンドを使います。以下の例をご覧ください。
OPTIMIZE table_name;
リキッドクラスタリングはインクリメンタルな処理なので、クラスタリングされる必要があるデータに対応するために、必要な分のみのデータが再書き込みされます。クラスタリングされるべきデータにマッチしないクラスタリングキーを持つデータファイルは再書き込みされません。
ベストなパフォーマンスを達成するために、データをクラスタリングするには定期的にOPTIMIZEジョブを実行すべきです。リキッドクラスタリングはインクリメンタル処理なので、クラスタリングされたテーブルに対するほとんどのOPTIMIZEジョブはクイックに実行されます。
どのような時にリキッドクラスタリングを使うべきですか?
Databricksドキュメントによると、すべての新規Deltaテーブルにリキッドクラスタリングを使うことが推奨されています。クラスタリングによってメリットを得られるシナリオの例を以下に示します:
- カーディナリティの高いカラムで頻繁にフィルタリングされるテーブル。
- データの分布に大きな偏りがあるテーブル。
- クイックに成長し、メンテナンスやチューニングの工数が必要となるテーブル。
- 同時書き込み要件のあるテーブル。
- 時間とともにアクセスパターンが変化するテーブル。
- 典型的なパーティションキーが多すぎる、あるいは少なすぎるパーティションになってしまうテーブル。
リキッドクラスタリングを使用する際に検討すべき事項
- クラスタリングキーには統計情報が収集されるカラムのみを指定できます。デフォルトでは、Deltaテーブルの最初の32カラムで統計情報が収集されます。
- クラスタリングキーには最大4カラムまでを指定できます。
- 構造化ストリーミングワークロードでは書き込み時のクラスタリングはサポートされていません。