こちらの手順を参考に、MCPサーバーにアクセスするエージェントを構築します。
ベースとしているのはこちらにあるRAGです。
具体的には、こちらの01-First-Step-RAG-On-Databricksノートブックです。
このRAGは直接Vector Search Indexにアクセスしていますが、今回は勉強を兼ねてマネージドMCPサーバーにアクセスするようにします。
Mosaic AI Agent Framework & Agent Evaluation を使った最初のRAGアプリケーションのデプロイ
データからチャットボットまで10分で
RAGアプリケーションは主に2つの部分に分かれています:
- 追加のコンテキストを提供し、ボットの回答を向上させるためのナレッジデータベース
- 実際のチャットボットアプリケーションとそのレビュー/フィードバック機構
RAGのためのデータ準備: Databricks Vector Searchへのナレッジベースの構築とインデックス作成
%pip install -U --quiet databricks-sdk databricks-langchain databricks-agents databricks-vectorsearch bs4==0.0.2 markdownify==0.14.1 pydantic==2.10.1 databricks-mcp mlflow mcp "databricks-sdk[openai]" databricks-agents
dbutils.library.restartPython()
%run ../_resources/00-init $reset_all_data=false
上のコマンドを実行するとdatabricks_documentationというテーブルが作成されますが、これは英語のDatabricksマニュアルなので、以下のクエリーで日本語にしておきます。
CREATE TABLE databricks_documentation_jpn AS
SELECT
id,
url,
ai_translate(content, "ja") AS content
FROM
databricks_documentation
ALTER TABLE databricks_documentation_jpn SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
%sql
SELECT * FROM databricks_documentation_jpn LIMIT 10

ベクター検索エンドポイント

ベクター検索エンドポイントは、インデックスが存在するエンティティです。検索リクエストを処理するためのエントリーポイントと考えてください。
最初のベクター検索エンドポイントを作成しましょう。作成後、ベクター検索エンドポイントUIで確認できます。エンドポイント名をクリックすると、そのエンドポイントで提供されるすべてのインデックスが表示されます。
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient(disable_notice=True)
if not endpoint_exists(vsc, VECTOR_SEARCH_ENDPOINT_NAME):
vsc.create_endpoint(name=VECTOR_SEARCH_ENDPOINT_NAME, endpoint_type="STANDARD")
wait_for_vs_endpoint_to_be_ready(vsc, VECTOR_SEARCH_ENDPOINT_NAME)
print(f"Endpoint named {VECTOR_SEARCH_ENDPOINT_NAME} is ready.")
Endpoint named dbdemos_vs_endpoint is ready.
1.2/ ベクター検索インデックスの作成
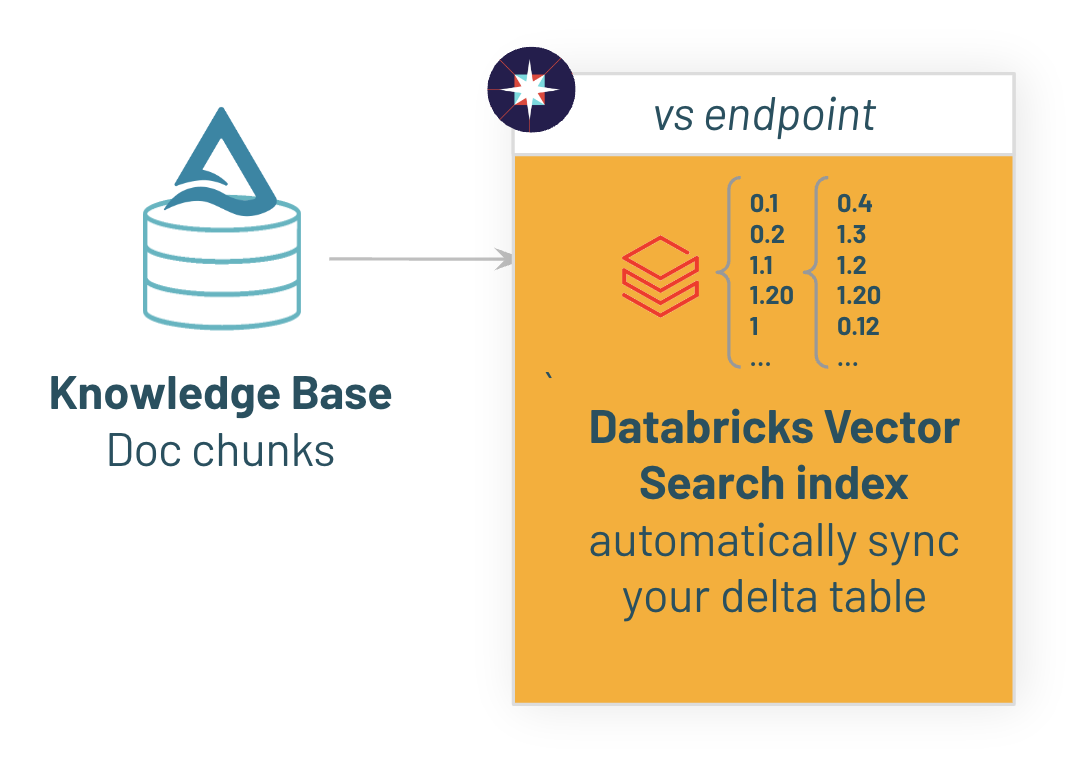
エンドポイントが作成されたら、あとは既存のテーブル上にインデックスを作成するようDatabricksに指示するだけです。
テキストカラムと埋め込み用のファウンデーションモデル(GTE)を指定するだけでOKです。Databricksが自動的にインデックスを構築し、同期してくれます。
これはAPIを使っても、Unity Catalog Explorerメニューから数クリックで実行することもできます。

from databricks.sdk import WorkspaceClient
import databricks.sdk.service.catalog as c
# インデックス化したいテーブル
source_table_fullname = f"{catalog}.{db}.databricks_documentation_jpn"
# インデックスを保存する場所
vs_index_fullname = f"{catalog}.{db}.databricks_documentation_vs_index"
if not index_exists(vsc, VECTOR_SEARCH_ENDPOINT_NAME, vs_index_fullname):
print(f"Creating index {vs_index_fullname} on endpoint {VECTOR_SEARCH_ENDPOINT_NAME}...")
vsc.create_delta_sync_index(
endpoint_name=VECTOR_SEARCH_ENDPOINT_NAME,
index_name=vs_index_fullname,
source_table_name=source_table_fullname,
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column='content', # テキストが格納されているカラム
embedding_model_endpoint_name='databricks-gte-large-en' # 埋め込み生成に使用するエンドポイント
)
# インデックスが準備でき、すべての埋め込みが作成・インデックス化されるまで待機
wait_for_index_to_be_ready(vsc, VECTOR_SEARCH_ENDPOINT_NAME, vs_index_fullname)
else:
# テーブルに保存された新しいデータでvsの内容を更新するために同期をトリガー
wait_for_index_to_be_ready(vsc, VECTOR_SEARCH_ENDPOINT_NAME, vs_index_fullname)
vsc.get_index(VECTOR_SEARCH_ENDPOINT_NAME, vs_index_fullname).sync()
print(f"index {vs_index_fullname} on table {source_table_fullname} is ready")
Creating index takaakiyayoi_catalog.rag_chatbot_jpn.databricks_documentation_vs_index on endpoint dbdemos_vs_endpoint...
Waiting for index to be ready, this can take a few min... {'detailed_state': 'PROVISIONING_INDEX', 'message': 'Delta sync Index creation is pending. Check latest status: https://xxxx.11.azuredatabricks.net/explore/data/takaakiyayoi_catalog/rag_chatbot_jpn/databricks_documentation_vs_index', 'indexed_row_count': 0, 'ready': False, 'index_url': 'xxxx.11.azuredatabricks.net/api/2.0/vector-search/indexes/takaakiyayoi_catalog.rag_chatbot_jpn.databricks_documentation_vs_index'} - pipeline url:xxxx.11.azuredatabricks.net/api/2.0/vector-search/indexes/takaakiyayoi_catalog.rag_chatbot_jpn.databricks_documentation_vs_index
index takaakiyayoi_catalog.rag_chatbot_jpn.databricks_documentation_vs_index on table takaakiyayoi_catalog.rag_chatbot_jpn.databricks_documentation_jpn is ready
関連コンテンツの検索
これで完了です。Databricksはテーブルの新しいエントリを自動的にキャプチャし、インデックスと同期します。
データセットのサイズやモデルのサイズによっては、インデックス作成が開始され、埋め込みがインデックスされるまでに数秒かかることがあります。
試してみて、類似のコンテンツを検索してみましょう。
注意
similarity_searchはフィルターパラメータもサポートしています。これはRAGシステムにセキュリティレイヤーを追加するのに便利です。誰が呼び出しているかに基づいて、特定のコンテンツをフィルタリングすることができます(例えば、ユーザーの好みに基づいて特定の部門をフィルタリングする)。
question = "クラスタ仕様を構成する方法は?"
results = vsc.get_index(VECTOR_SEARCH_ENDPOINT_NAME, vs_index_fullname).similarity_search(
query_text=question,
columns=["url", "content"],
num_results=1)
docs = results.get('result', {}).get('data_array', [])
docs
[['https://docs.databricks.com/en/archive/compute/configure.html',
'クラスターの構成 \n注 \nこれはレガシークラスター作成UIの手順であり、歴史的正確性のためにのみ含まれています。すべての顧客は、更新されたクラスター作成UIを使用する必要があります。 \nこの記事では、Databricks クラスターを作成および編集するときに使用可能な構成オプションについて説明します。UI を使用したクラスターの作成および編集に焦点を当てています。その他の方法については、Databricks CLI、クラスター API、および Databricks Terraform プロバイダーを参照してください。 \n必要な構成オプションの組み合わせを決定するためのヘルプについては、クラスター構成のベスト プラクティスを参照してください。 \nクラスター ポリシー \nクラスター ポリシー \nクラスター ポリシーは、ルールのセットに基づいてクラスターの構成を制限します。ポリシーのルールは、クラスター作成に使用可能な属性または属性値を制限します。クラスター ポリシーには、特定のユーザーとグループの使用を制限する ACL があり、クラスターを作成するときに選択できるポリシーを制限します。 \nクラスター ポリシーを構成するには、ポリシー ドロップダウンでクラスター ポリシーを選択します。 \n注 \nワークスペースにポリシーが作成されていない場合、ポリシー ドロップダウンは表示されません。 \nクラスター作成のアクセス許可がある場合、制限なしポリシーを選択し、完全に構成可能なクラスターを作成できます。制限なしポリシーは、クラスター属性または属性値を制限しません。 \nクラスター作成のアクセス許可とクラスター ポリシーのアクセス許可の両方がある場合、制限なしポリシーとアクセス許可のあるポリシーを選択できます。 \nクラスター ポリシーのアクセス許可のみがある場合、アクセス許可のあるポリシーを選択できます。 \nクラスター モード \nクラスター モード \n注 \nこの記事ではレガシークラスター UI について説明します。新しいクラスター UI (プレビュー) については、コンピューティング構成リファレンスを参照してください。これには、クラスター アクセス タイプとモードの用語の変更が含まれます。新しいクラスター タイプとレガシークラスター タイプの比較については、クラスター UI の変更とクラスター アクセス モードを参照してください。プレビュー UI では、次のようになります。 \nStandard モード クラスターは、No Isolation Shared アクセス モード クラスターと呼ばれます。 \nHigh Concurrency with Tables ACL は、Shared アクセス モード クラスターと呼ばれます。 \nDatabricks では、Standard、High Concurrency、Single Node の 3 つのクラスター モードがサポートされます。デフォルトのクラスター モードは Standard です。 \n重要 \nワークスペースが Unity Catalog メタストアに割り当てられている場合、High Concurrency クラスターは使用できません。代わりに、アクセス モードを使用してアクセス制御の整合性を確保し、厳格な分離保証を適用します。アクセス モードについては、こちらも参照してください。 \nクラスターを作成した後、クラスター モードを変更することはできません。別のクラスター モードを使用する場合は、新しいクラスターを作成する必要があります。 \nクラスター構成には、クラスター モードによって異なるデフォルト値を持つ自動終了設定が含まれます。 \nStandard クラスターと Single Node クラスターは、デフォルトで 120 分後に自動的に終了します。 \nHigh Concurrency クラスターは、デフォルトで自動終了しません。 \nStandard クラスター \n警告 \nStandard モード クラスター (No Isolation Shared クラスターとも呼ばれます) は、複数のユーザーによって共有できますが、ユーザー間の分離はありません。Table ACL または Credential Passthrough などの追加のセキュリティ設定を使用せずに High Concurrency クラスター モードを使用する場合、Standard モード クラスターと同じ設定が使用されます。アカウント管理者は、これらのタイプのクラスターで Databricks ワークスペース管理者に対して内部資格情報を自動生成するのを防ぐことができます。より安全なオプションについては、高並行度クラスターと Table ACL についての Databricks の推奨事項を参照してください。 \nStandard クラスターは、単一のユーザーのみに推奨されます。Standard クラスターは、Python、SQL、R、Scala で開発されたワークロードを実行できます。 \nHigh Concurrency クラスター \nHigh Concurrency クラスターは、管理されたクラウド リソースです。High Concurrency クラスターの主な利点は、最大のリソース使用率と最小のクエリ待機時間を実現するための細粒度の共有を提供することです。 \nHigh Concurrency クラスターは、SQL、Python、R で開発されたワークロードを実行できます。High Concurrency クラスターのパフォーマンスとセキュリティは、ユーザー コードを個別のプロセスで実行することによって提供されますが、これは Scala では不可能です。 \nさらに、High Concurrency クラスターのみがテーブル アクセス制御をサポートします。 \nHigh Concurrency クラスターを作成するには、クラスター モードを High Concurrency に設定します。 \nSingle Node クラスター \nSingle Node クラスターにはワーカー ノードはありません。Spark ジョブはドライバー ノードで実行されます。 \n一方、Standard クラスターでは、Spark ジョブを実行するために、ドライバー ノードに加えて少なくとも 1 つの Spark ワーカー ノードが必要です。 \nSingle Node クラスターを作成するには、クラスター モードを Single Node に設定します。 \nSingle Node クラスターの使用方法については、シングル ノードまたはマルチ ノード コンピューティングを参照してください。 \nプール \nプール \nクラスターの起動時間を短縮するために、クラスターを事前に定義されたアイドル インスタンスのプールに接続できます。これは、ドライバー ノードとワーカー ノードに適用されます。クラスターは、プール内のインスタンスを使用して作成されます。プールに十分なアイドル リソースがない場合、プールはインスタンス プロバイダーから新しいインスタンスを割り当てて拡張されます。接続されたクラスターが終了すると、使用したインスタンスはプールに返され、別のクラスターで再利用できます。 \nワーカー ノードのプールを選択し、ドライバー ノードのプールを選択しない場合、ドライバー ノードはワーカー ノードの構成からプールを継承します。 \n重要 \nドライバー ノードのプールを選択し、ワーカー ノードのプールを選択しないと、エラーが発生し、クラスターは作成されません。この要件は、ドライバー ノードがワーカー ノードの作成を待つ必要がある状況、またはその逆の状況を防ぎます。 \nプールの使用方法については、プール構成リファレンスを参照してください。 \nDatabricks Runtime',
0.0027712088]]
MCPを使ったエージェントの構築
Databricks上のMCPサーバーへの接続は、他のリモートMCPサーバーへの接続と同様です。標準的なSDK(例:MCP Python SDK)を使ってサーバーに接続できます。主な違いは、DatabricksのMCPサーバーはデフォルトでセキュアになっており、クライアント側で認証情報の指定が必要な点です。databricks-mcp Pythonライブラリを使うことで、カスタムエージェントコードでの認証が簡単になります。
次のスニペットを実行して、MCPサーバーへの接続を検証します。このスニペットは、Unity Catalogツールを一覧表示し、その後ベクトル検索インデックスをクエリします。
import asyncio
from mcp.client.streamable_http import streamablehttp_client
from mcp.client.session import ClientSession
from databricks_mcp import DatabricksOAuthClientProvider
from databricks.sdk import WorkspaceClient
# ワークスペースへの認証を構成
workspace_client = WorkspaceClient()
workspace_hostname = workspace_client.config.host
mcp_server_url = f"{workspace_hostname}/api/2.0/mcp/vector-search/{catalog}/{db}"
# 以下のスニペットは、Unity Catalog の関数 MCP サーバーを使用して Vector Search Index を公開します
async def test_connect_to_server():
async with streamablehttp_client(
f"{mcp_server_url}", auth=DatabricksOAuthClientProvider(workspace_client)
) as (read_stream, write_stream, _), ClientSession(
read_stream, write_stream
) as session:
# MCP サーバーからツールを一覧取得し、呼び出す
await session.initialize()
tools = await session.list_tools()
toolnames = [t.name for t in tools.tools]
print(
f"MCP サーバー {mcp_server_url} から検出されたツール: {toolnames}"
)
result = await session.call_tool(
toolnames[0], {"query": "Databricksとは何ですか?"}
)
print(
f"{toolnames[0]} ツールを呼び出し、結果を取得: {result.content}"
)
await test_connect_to_server()
MCP サーバー https://xxxx.11.azuredatabricks.net/api/2.0/mcp/vector-search/takaakiyayoi_catalog/rag_chatbot_jpn から検出されたツール: ['takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index']
takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index ツールを呼び出し、結果を取得: [TextContent(type='text', text='[{"id":"","url":"https://docs.databricks.com/en/partners/bi/power-bi.html","content":"Databricks コネクタでは、Databricks.Query データ ソースは DirectQuery モードと組み合わせて使用することはサポートされません。 Delta Sharing コネクタが読み込むデータは、コンピュータのメモリに収まる必要があります。 これを確実にするために、コネクタは、先ほど設定した行制限までの行数を読み込みます。","score":""},{"id":"","url":"https://docs.databricks.com/en/spark/index.html","content":"Apache Spark on Databricks \\nこの記事では、Apache SparkとDatabricksおよびDatabricks Data Intelligence Platformの関係について説明します。 \\nApache SparkはDatabricksプラットフォームの核であり、コンピューティングクラスターとSQLウェアハウスを動かす技術です。DatabricksはApache Sparkの最適化プラットフォームであり、Apache Sparkワークロードの実行に効率的でシンプルなプラットフォームを提供します。 \\nApache SparkとDatabricksの関係は何ですか?\\nApache SparkとDatabricksの関係は何ですか?\\nDatabricks社は、Apache Sparkのオリジナルクリエイターによって設立されました。オープンソースソフトウェアプロジェクトとして、Apache Sparkには、Databricksを含む多くのトップ企業からのコミッターがいます。 \\nDatabricksは、Apache Sparkに機能を開発し、リリースを続けています。Databricks Runtimeには、Apache Sparkを基にして拡張した追加の最適化と独自の機能、C++で書き直されたApache Sparkの最適化バージョンのPhotonが含まれています。\\n\\nDatabricksでApache Sparkはどのように動作しますか?\\nDatabricksでApache Sparkはどのように動作しますか?\\nDatabricksでコンピューティングクラスターまたはSQLウェアハウスをデプロイすると、Apache Sparkが仮想マシンに構成され、デプロイされます。SparkコンテキストまたはSparkセッションを構成または初期化する必要はありません。Databricksによってこれらは管理されます。\\n\\nApache Sparkを使用せずにDatabricksを使用できますか?\\nApache Sparkを使用せずにDatabricksを使用できますか?\\nDatabricksは、さまざまなワークロードをサポートし、Databricks Runtimeにオープンソースライブラリを含みます。Databricks SQLは、Apache Sparkを内部で使用しますが、エンドユーザーは、データベースオブジェクトを作成および照会するために、標準のSQL構文を使用します。 \\nDatabricks Runtime for Machine Learningは、MLワークロードに最適化されており、多くのデータサイエンティストが、Databricksで作業しながら、TensorFlowやSciKit Learnなどの主要なオープンソースライブラリを使用します。ワークフローを使用して、Databricksによってデプロイおよび管理されるコンピューティングリソースに対して、任意のワークロードをスケジュールできます。\\n\\nDatabricksでApache Sparkを使用する理由は何ですか?\\nDatabricksでApache Sparkを使用する理由は何ですか?\\nDatabricksプラットフォームは、ビジネスに合わせて拡張するエンタープライズソリューションを開発およびデプロイするための、セキュアでコラボレーション可能な環境を提供します。Databricksの従業員には、世界で最も知識のあるApache Sparkメンテナーおよびユーザーが多数含まれています。同社は、ユーザーがApache Sparkを実行するための最速の環境にアクセスできるように、新しい最適化を継続的に開発し、リリースしています。\\n\\nDatabricksでApache Sparkを使用する方法についてさらに詳しく知るにはどうすればよいですか?\\nDatabricksでApache Sparkを使用する方法についてさらに詳しく知るにはどうすればよいですか?\\nDatabricksでApache Sparkを使用するには、まずはじめに!Apache Spark DataFramesチュートリアルでは、Python、R、またはScalaでデータを読み込み、変換する方法について説明します。チュートリアル:Apache Spark DataFramesを使用してデータを読み込み、変換するを参照してください。 \\nPySpark on Databricks、SparkRの概要、Databricks for Scala開発者に関するセクション、およびApache Spark APIのリファレンスに、Python、R、Scala言語のサポートに関する追加情報が記載されています。","score":""},{"id":"","url":"https://docs.databricks.com/en/integrations/compute-details.html","content":"Databricks コンピュート リソースの接続詳細を取得する \\n参加アプリ、ツール、SDK、または API を Databricks コンピュート リソース (Databricks クラスターまたは Databricks SQL ウェアハウスなど) に接続するには、クラスターまたは SQL ウェアハウスに関する特定の情報を提供して、接続が正常に確立されるようにする必要があります。 \\nDatabricks クラスターの接続詳細を取得するには、次の手順を実行します。 \\nDatabricks ワークスペースにログインします。 \\nサイドバーで、[コンピュート] をクリックします。 \\n使用可能なクラスターのリストで、対象クラスターの名前をクリックします。 \\n[構成] タブで、[詳細オプション] を展開します。 \\n[JDBC/ODBC] タブをクリックします。 \\n必要な接続詳細 (サーバー ホスト名、ポート、HTTP パスなど) をコピーします。 \\nDatabricks SQL ウェアハウスの接続詳細を取得するには、次の手順を実行します。 \\nDatabricks ワークスペースにログインします。 \\nサイドバーで、[SQL] > [SQL ウェアハウス] をクリックします。 \\n使用可能なウェアハウスのリストで、対象ウェアハウスの名前をクリックします。 \\n[接続詳細] タブで、必要な接続詳細 (サーバー ホスト名、ポート、HTTP パスなど) をコピーします。","score":""},{"id":"","url":"https://docs.databricks.com/en/dev-tools/index.html","content":"デベロッパー向けツールとガイダンス \\nDatabricks リソースおよびデータを操作し、Databricks アプリケーションを開発するために使用できるツールとガイダンスについて学びます。 \\nセクション \\n以下の場合にこのセクションを使用します… \\n認証 \\nツール、スクリプト、アプリから Databricks に認証します。Databricks リソースおよびデータを操作する前に、Databricks に認証する必要があります。 \\nIDE \\nVisual Studio Code、PyCharm、IntelliJ IDEA、Eclipse、RStudio、JupyterLab などの人気のある統合開発環境 (IDE) に加えて、Databricks IDE プラグインを使用して Databricks Connect で Databricks に接続します。 \\nSDK \\nPython、Java、Go、R などの人気のある言語用に書かれたコード ライブラリから Databricks を自動化します。 \\nSQL コネクタ/ドライバー \\nPython、Go、JavaScript、TypeScript などの人気のある言語で書かれたコードから Databricks で SQL コマンドを実行します。ODBC および JDBC 接続を使用してツールおよびクライアントを Databricks に接続します。 \\nSQL ツール \\nDatabricks SQL CLI、Databricks Driver for SQLTools、および DataGrip、DBeaver、SQL Workbench/J などの人気のあるツールを使用して、Databricks で SQL コマンドおよびスクリプトを実行します。 \\nDatabricks CLI \\nDatabricks コマンドライン インターフェイス (CLI) を使用して Databricks の機能にアクセスします。 \\nユーティリティ \\nノートブック内から Databricks ユーティリティを使用して、オブジェクト ストレージを効率的に操作したり、ノートブックを連結およびパラメーター化したり、機密の資格情報情報を操作したりします。 \\nIaC \\nTerraform、Cloud Development Kit for Terraform、Pulumi などの人気のあるインフラストラクチャとしてのコード (IaC) 製品を使用して、Databricks インフラストラクチャおよびリソースのプロビジョニングおよびメンテナンスを自動化します。 \\nCI/CD \\nDatabricks Asset Bundles、および GitHub Actions、DevOps パイプライン、Jenkins、Apache Airflow などの人気のあるシステムおよびフレームワークを使用して、Databricks に対して業界標準の継続的インテグレーションおよび継続的デリバリー (CI/CD) プラクティスを実装します。 \\nヒント \\n多くの追加の第三者ツールをクラスターおよび SQL ウェアハウスに接続して、Databricks のデータにアクセスできます。テクノロジー パートナーを参照してください。","score":""},{"id":"","url":"https://docs.databricks.com/en/tables/partitions.html","content":"Databricksの組み込み最適化をカスタムパーティショニングで上回ることは可能か? Apache SparkおよびDelta Lakeの経験豊富なユーザーは、インジェスト時クラスタリングよりも優れたパフォーマンスを提供するパターンを設計および実装できる場合があります。悪いパーティショニング戦略を実装すると、ダウンストリームのパフォーマンスに非常に悪影響を及ぼし、データの完全な書き換えが必要になる場合があります。Databricksは、多くのユーザーがデフォルト設定を使用して高価な非効率性を導入しないようにすることをお勧めしています。","score":""}]', annotations=None, meta=None)]
上記のスニペットを基に、ツールを使う基本的なシングルターンエージェントを定義できます。後続のセクションでデプロイできるよう、エージェントのコードを mcp_agent.py という名前でローカルに保存してください。
注意
以下の実装では、こちらを参考にResponsesAgentを用いています。
ノートブックでMCPサーバーへのアクセスをテストする際には、ノートブックではイベントループが実行されていますがモデルサービングエンドポイントではそうではないことに注意してください。以下の実装でもノートブックでの実行かどうかに応じてロジックを切り替えています。
| 項目 | Databricksノートブック | Model Serving |
|---|---|---|
| 実行基盤 | Jupyter/IPythonカーネル | Flask/FastAPI |
| スレッド構成 | 単一のメインスレッド | HTTPリクエストごとにワーカースレッド |
| イベントループ | Jupyter環境で既存のイベントループが実行中 | ThreadPoolExecutor使用 |
| 実行方式 | インタラクティブ実行(セルごとに順次) | バックグラウンド実行(独立したスレッドで処理) |
| プロセス構成 | 単一のPythonプロセス内で実行 | 複数のワーカープロセス × 複数のスレッド |
%%writefile mcp_agent.py
import os
from contextlib import asynccontextmanager
import json
import uuid
import asyncio
from typing import Any, Callable, List
from pydantic import BaseModel
import threading
import mlflow
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import ResponsesAgentRequest, ResponsesAgentResponse
from databricks_mcp import DatabricksOAuthClientProvider
from databricks.sdk import WorkspaceClient
from mcp.client.session import ClientSession
from mcp.client.streamable_http import streamablehttp_client
# Databricksノートブック環境でのみnest_asyncioを適用
if os.getenv('DATABRICKS_RUNTIME_VERSION') and 'ipykernel' in os.environ.get('_', ''):
# Databricksノートブック内
import nest_asyncio
nest_asyncio.apply()
NOTEBOOK_ENV = True
else:
# Model Servingやその他の環境
NOTEBOOK_ENV = False
# 1) エンドポイント/プロファイルの設定
LLM_ENDPOINT_NAME = "databricks-claude-3-7-sonnet"
SYSTEM_PROMPT = "あなたは有能なアシスタントです。"
workspace_client = WorkspaceClient()
host = workspace_client.config.host
# カタログ・データベース名を設定
catalog = "takaakiyayoi_catalog"
db = "rag_chatbot_jpn"
# 必要に応じてMCPサーバーURLを追加
MCP_SERVER_URLS = [
f"{host}/api/2.0/mcp/vector-search/{catalog}/{db}",
]
# 2) ResponsesAgent形式の"message dict"をChatCompletions形式に変換するヘルパー
def _to_chat_messages(msg: dict[str, Any]) -> List[dict]:
"""
ResponsesAgent形式のdictを1つ以上のChatCompletions互換dictに変換
"""
msg_type = msg.get("type")
if msg_type == "function_call":
return [
{
"role": "assistant",
"content": None,
"tool_calls": [
{
"id": msg["call_id"],
"type": "function",
"function": {
"name": msg["name"],
"arguments": msg["arguments"],
},
}
],
}
]
elif msg_type == "message" and isinstance(msg["content"], list):
return [
{
"role": "assistant" if msg["role"] == "assistant" else msg["role"],
"content": content["text"],
}
for content in msg["content"]
]
elif msg_type == "function_call_output":
return [
{
"role": "tool",
"content": msg["output"],
"tool_call_id": msg["tool_call_id"],
}
]
else:
# {"role": ..., "content": "..."}等のプレーンなdictのフォールバック
return [
{
k: v
for k, v in msg.items()
if k in ("role", "content", "name", "tool_calls", "tool_call_id")
}
]
# 3) MCPセッションとツール呼び出しロジック
@asynccontextmanager
async def _mcp_session(server_url: str, ws: WorkspaceClient):
async with streamablehttp_client(
url=server_url, auth=DatabricksOAuthClientProvider(ws)
) as (reader, writer, _):
async with ClientSession(reader, writer) as session:
await session.initialize()
yield session
async def _list_tools_async(server_url: str, ws: WorkspaceClient):
async with _mcp_session(server_url, ws) as sess:
return await sess.list_tools()
def _run_async_in_thread(coroutine):
"""
非同期コルーチンを専用スレッドのイベントループで実行(Model Serving向け)
"""
result = None
exception = None
def run_in_thread():
nonlocal result, exception
try:
# 新しいイベントループを作成
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
result = loop.run_until_complete(coroutine)
finally:
loop.close()
except Exception as e:
exception = e
# 別スレッドで実行
thread = threading.Thread(target=run_in_thread)
thread.start()
thread.join()
if exception:
raise exception
return result
def _run_async_safely(coroutine):
"""
環境に応じて非同期コルーチンを安全に実行
"""
if NOTEBOOK_ENV:
# ノートブック: 既存イベントループを利用(nest_asyncio適用済み)
try:
loop = asyncio.get_running_loop()
return asyncio.run(coroutine)
except RuntimeError:
# フォールバック: スレッド方式
return _run_async_in_thread(coroutine)
else:
# Model Serving: 常にスレッド方式
return _run_async_in_thread(coroutine)
def _run_async_in_thread(coroutine):
"""
非同期コルーチンを専用スレッドのイベントループで実行(Model Serving向け)
"""
result = None
exception = None
def run_in_thread():
nonlocal result, exception
try:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
result = loop.run_until_complete(coroutine)
finally:
loop.close()
except Exception as e:
exception = e
thread = threading.Thread(target=run_in_thread)
thread.start()
thread.join()
if exception:
raise exception
return result
def _run_async_safely(coroutine):
"""
環境に応じて非同期コルーチンを安全に実行
"""
if NOTEBOOK_ENV:
try:
loop = asyncio.get_running_loop()
return asyncio.run(coroutine)
except RuntimeError:
return _run_async_in_thread(coroutine)
else:
return _run_async_in_thread(coroutine)
def _list_tools(server_url: str, ws: WorkspaceClient):
# 安全な非同期実行
return _run_async_safely(_list_tools_async(server_url, ws))
def _make_exec_fn(
server_url: str, tool_name: str, ws: WorkspaceClient
) -> Callable[..., str]:
async def call_it_async(**kwargs):
async with _mcp_session(server_url, ws) as sess:
resp = await sess.call_tool(name=tool_name, arguments=kwargs)
return "".join([c.text for c in resp.content])
def exec_fn(**kwargs):
# 安全な非同期実行
return _run_async_safely(call_it_async(**kwargs))
return exec_fn
def _sanitize_tool_name(name: str, max_length: int = 64) -> str:
"""
Databricks要件に合わせてツール名をサニタイズ
- 英数字、アンダースコア、ハイフンのみ
- 最大64文字
- 正規表現 ^[a-zA-Z0-9_-]{1,64}$ に一致
"""
import re
# 許可されていない文字をアンダースコアに置換
sanitized = re.sub(r'[^a-zA-Z0-9_-]', '_', name)
# 連続アンダースコアを1つに
sanitized = re.sub(r'_+', '_', sanitized)
# 先頭・末尾のアンダースコアを除去
sanitized = sanitized.strip('_')
# 空なら"tool"に
if not sanitized:
sanitized = "tool"
# 長さ制限
if len(sanitized) <= max_length:
result = sanitized
else:
# 長すぎる場合は分割して短縮
if "_" in sanitized:
parts = sanitized.split("_")
last_part = parts[-1]
first_part = parts[0]
available_chars = max_length - len(last_part) - 1
if available_chars > 0 and len(first_part) <= available_chars:
result = f"{first_part}_{last_part}"
elif available_chars > 0:
first_part = first_part[:available_chars]
result = f"{first_part}_{last_part}"
else:
result = last_part[:max_length]
else:
result = sanitized[:max_length]
# 最終バリデーション
pattern = r'^[a-zA-Z0-9_-]{1,64}$'
if not re.match(pattern, result):
# 最後の手段: 英数字のみ
result = re.sub(r'[^a-zA-Z0-9]', '', result)
if not result:
result = "tool"
result = result[:max_length]
return result
class ToolInfo(BaseModel):
name: str
spec: dict
exec_fn: Callable
def _fetch_tool_infos(ws: WorkspaceClient, server_url: str) -> List[ToolInfo]:
print(f"MCPサーバー {server_url} からツール一覧を取得")
infos: List[ToolInfo] = []
try:
mcp_tools_result = _list_tools(server_url, ws)
mcp_tools = mcp_tools_result.tools
for t in mcp_tools:
# ツール名をサニタイズ
original_name = t.name
sanitized_name = _sanitize_tool_name(t.name, 64)
# バリデーション
import re
pattern = r'^[a-zA-Z0-9_-]{1,64}$'
is_valid = re.match(pattern, sanitized_name)
print(f"元名: '{original_name}'")
print(f"サニタイズ後: '{sanitized_name}' (長さ: {len(sanitized_name)}, valid: {bool(is_valid)})")
if not is_valid:
print(f"エラー: サニタイズ名がパターンに一致しません!")
sanitized_name = "vector_search_tool"
schema = t.inputSchema.copy() if t.inputSchema else {}
if "properties" not in schema:
schema["properties"] = {}
# 説明が長すぎる場合は切り詰め
description = t.description
if len(description) > 500:
description = description[:497] + "..."
spec = {
"type": "function",
"function": {
"name": sanitized_name,
"description": description,
"parameters": schema,
},
}
infos.append(
ToolInfo(
name=original_name, # 実行時は元名を使う
spec=spec,
exec_fn=_make_exec_fn(server_url, original_name, ws)
)
)
print(f"{len(infos)}個のツールを正常にロード")
except Exception as e:
print(f"{server_url} からのツール取得エラー: {e}")
return infos
# 4) シングルターン型エージェントクラス
class SingleTurnMCPAgent(ResponsesAgent):
def __init__(self):
super().__init__()
self._tool_infos = None
self._tools_dict = None
self._workspace_client = None
def _initialize_tools(self):
"""モデルロード時に一度だけツールを初期化"""
if self._tool_infos is None:
try:
self._workspace_client = WorkspaceClient()
self._tool_infos = [
tool_info
for mcp_server_url in MCP_SERVER_URLS
for tool_info in _fetch_tool_infos(self._workspace_client, mcp_server_url)
]
self._tools_dict = {tool_info.name: tool_info for tool_info in self._tool_infos}
print(f"モデルロード時に{len(self._tool_infos)}個のツールを初期化")
except Exception as e:
print(f"警告: モデルロード時のツール初期化失敗: {e}")
self._tool_infos = []
self._tools_dict = {}
def _call_llm(self, history: List[dict], ws: WorkspaceClient, tool_infos):
"""
現在の履歴をLLMに送信し、生のレスポンスdictを返す
"""
client = ws.serving_endpoints.get_open_ai_client()
flat_msgs = []
for msg in history:
flat_msgs.extend(_to_chat_messages(msg))
# Databricksツール形式に変換
tools_param = None
if tool_infos:
tools_param = []
for ti in tool_infos:
function_spec = ti.spec["function"]
tool_dict = {
"type": "function",
"function": {
"name": function_spec["name"],
"description": function_spec["description"]
}
}
# パラメータが存在し空でなければ追加
if function_spec.get("parameters") and function_spec["parameters"].get("properties"):
tool_dict["function"]["parameters"] = function_spec["parameters"]
else:
# 空のパラメータ仕様
tool_dict["function"]["parameters"] = {
"type": "object",
"properties": {}
}
tools_param.append(tool_dict)
# ノートブック環境のみデバッグ出力
if NOTEBOOK_ENV:
print(f"LLMに{len(tools_param)}個のツールを送信")
for i, tool in enumerate(tools_param):
print(f"ツール {i}: {tool['function']['name']}")
import json
print(f"ツール構造: {json.dumps(tool, indent=2)}")
# 複数アプローチで実行
try:
# まずtoolsパラメータ付きで実行
if tools_param:
return client.chat.completions.create(
model=LLM_ENDPOINT_NAME,
messages=flat_msgs,
tools=tools_param,
)
else:
return client.chat.completions.create(
model=LLM_ENDPOINT_NAME,
messages=flat_msgs,
)
except Exception as e:
if NOTEBOOK_ENV:
print(f"最初の試行失敗: {e}")
print("ツールなしでフォールバック...")
# フォールバック: ツールなしで実行
return client.chat.completions.create(
model=LLM_ENDPOINT_NAME,
messages=flat_msgs,
)
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
# 未初期化ならツールを初期化
self._initialize_tools()
ws = self._workspace_client or WorkspaceClient()
# 1) system+userで初期履歴を構築
history: List[dict] = [{"role": "system", "content": SYSTEM_PROMPT}]
for inp in request.input:
history.append(inp.model_dump())
# 2) LLMを一度呼び出し
try:
# 事前ロード済みツールを利用
tool_infos = self._tool_infos
tools_dict = self._tools_dict
if NOTEBOOK_ENV:
print(f"事前ロード済みツール数: {len(tool_infos)}")
llm_resp = self._call_llm(history, ws, tool_infos)
raw_choice = llm_resp.choices[0].message.to_dict()
raw_choice["id"] = uuid.uuid4().hex
history.append(raw_choice)
tool_calls = raw_choice.get("tool_calls") or []
if tool_calls:
# (この例では単一ツールのみ対応)
fc = tool_calls[0]
requested_name = fc["function"]["name"]
args = json.loads(fc["function"]["arguments"])
# サニタイズ名から元名を検索
original_name = None
for tool_info in tool_infos:
if tool_info.spec["function"]["name"] == requested_name:
original_name = tool_info.name
break
if original_name and original_name in tools_dict:
try:
tool_info = tools_dict[original_name]
result = tool_info.exec_fn(**args)
except Exception as e:
result = f"{original_name}の呼び出しエラー: {e}"
else:
result = f"ツール {requested_name} が見つかりません"
# 4) "tool"出力を履歴に追加
history.append(
{
"type": "function_call_output",
"role": "tool",
"id": uuid.uuid4().hex,
"tool_call_id": fc["id"],
"output": result,
}
)
# 5) LLMを再度呼び出し、その返答を最終とする
followup = (
self._call_llm(history, ws, tool_infos=[]).choices[0].message.to_dict()
)
followup["id"] = uuid.uuid4().hex
assistant_text = followup.get("content", "")
return ResponsesAgentResponse(
output=[
{
"id": uuid.uuid4().hex,
"type": "message",
"role": "assistant",
"content": [{"type": "output_text", "text": assistant_text}],
}
],
custom_outputs=request.custom_inputs,
)
# 6) tool_callsがなければ元のassistant返答を返す
assistant_text = raw_choice.get("content", "")
return ResponsesAgentResponse(
output=[
{
"id": uuid.uuid4().hex,
"type": "message",
"role": "assistant",
"content": [{"type": "output_text", "text": assistant_text}],
}
],
custom_outputs=request.custom_inputs,
)
except Exception as e:
# エラー処理
error_message = f"リクエスト処理中のエラー: {str(e)}"
print(error_message)
return ResponsesAgentResponse(
output=[
{
"id": uuid.uuid4().hex,
"type": "message",
"role": "assistant",
"content": [{"type": "output_text", "text": error_message}],
}
],
custom_outputs=request.custom_inputs,
)
# MLflowモデルをセット
mlflow.models.set_model(SingleTurnMCPAgent())
# テスト実行
try:
print("エージェントリクエスト作成中...")
req = ResponsesAgentRequest(
input=[{"role": "user", "content": "Databricksとは?"}]
)
print("予測実行中...")
agent = SingleTurnMCPAgent()
resp = agent.predict(req)
print("レスポンス:")
for item in resp.output:
print(item)
except Exception as e:
print(f"実行中のエラー: {e}")
import traceback
traceback.print_exc()
注意
上のセルの最初行にある%%writefile mcp_agent.pyでセルの内容をファイルに保存しています。この行を削除してセルを実行するとエージェントの挙動を確認することができます。
エージェントリクエスト作成中...
予測実行中...
MCPサーバー https://xxxx.11.azuredatabricks.net/api/2.0/mcp/vector-search/takaakiyayoi_catalog/rag_chatbot_jpn からツール一覧を取得
元名: 'takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index'
サニタイズ後: 'takaakiyayoi_index' (長さ: 18, valid: True)
1個のツールを正常にロード
モデルロード時に1個のツールを初期化
レスポンス:
type='message' id='feafa06e49944a8492cf62b6961d78b4' role='assistant' content=[{'type': 'output_text', 'text': 'Databricksは、ビッグデータ分析とAI/機械学習のためのクラウドベースのデータプラットフォームです。以下はDatabricksの主な特徴と概要です:\n\n### Databricksの概要\n\n1. **Apache Sparkをベースとしたプラットフォーム**:\n - Databricksは、Apache Sparkのオリジナルクリエイターによって設立された会社が開発したプラットフォームです\n - Apache Sparkを核として、それを拡張・最適化したデータ処理環境を提供しています\n\n2. **Databricks Data Intelligence Platform**:\n - データ分析、機械学習、AIワークロードを統合的に扱えるプラットフォームを提供\n - ビッグデータの処理から高度な分析まで一貫して行える環境を実現\n\n3. **主要な構成要素**:\n - コンピューティングクラスター:データ処理のための分散処理環境\n - SQLウェアハウス:SQLベースのデータ分析機能\n - Databricks Runtime:Apache Sparkの最適化バージョンと追加機能を含む実行環境\n\n### Databricksの特徴\n\n1. **使いやすさ**:\n - Sparkコンテキストやセッションを手動で構成する必要がなく、自動的に管理される\n - ノートブックインターフェースによる対話的な開発環境\n\n2. **パフォーマンス最適化**:\n - Photon:C++で書き直されたApache Sparkの高速バージョン\n - Databricks独自の最適化により、標準のApache Sparkよりも高速に動作\n\n3. **多言語サポート**:\n - Python、R、Scala、SQLなど複数の言語をサポート\n - データサイエンティストや分析者が得意な言語で作業できる\n\n4. **コラボレーション機能**:\n - チーム間での共同作業をサポートするセキュアな環境\n - ノートブックの共有やバージョン管理機能\n\n5. **エンタープライズ対応**:\n - セキュリティ、ガバナンス、スケーラビリティに優れた設計\n - ビジネスニーズに合わせて拡張可能なソリューション\n\nDatabricksは、データエンジニアリング、データサイエンス、ビジネスアナリティクスのワークロードを統合的に扱うことができるため、企業のデータ活用基盤として広く採用されています。'}]
MCPを使用してエージェントをデプロイする
MCPサーバーに接続するエージェントをデプロイする準備ができたら、標準のエージェントデプロイメントプロセスを使用してください。
エージェントがアクセスする必要があるすべてのリソースをログイン時に指定することを確認してください。例えば、エージェントが以下のMCPサーバーURLを使用する場合:
https://<your-workspace-hostname>/api/2.0/mcp/vector-search/prod/customer_supporthttps://<your-workspace-hostname>/api/2.0/mcp/vector-search/prod/billinghttps://<your-workspace-hostname>/api/2.0/mcp/functions/prod/billing
エージェントが必要とするすべてのベクトル検索インデックス、およびすべてのUnity Catalog関数をリソースとして指定する必要があります。
例えば、上記で定義されたエージェントをデプロイするには、エージェントコード定義をmcp_agent.pyに保存したと仮定して、次のスニペットを実行できます。
Pythonカーネルを再起動してimportするファイルを認識できるようにします。
%restart_python
%run ../config
import os
from databricks.sdk import WorkspaceClient
from databricks import agents
import mlflow
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint, DatabricksVectorSearchIndex
from mcp_agent import LLM_ENDPOINT_NAME
workspace_client = WorkspaceClient()
# mcp_agent.pyで定義されたエージェントをログ
agent_script = "mcp_agent.py"
resources = [
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME),
# --- エージェントコード内のMCP_SERVER_URLSを介して参照される場合、以下の行をアンコメントしてベクトル検索インデックスや追加のUC関数を指定 ---
DatabricksVectorSearchIndex(index_name=f"{catalog}.{db}.databricks_documentation_vs_index"),
# DatabricksVectorSearchIndex(index_name="prod.billing.another_index"),
# DatabricksFunction("prod.billing.my_custom_function"),
# DatabricksFunction("prod.billing.another_function"),
]
with mlflow.start_run():
logged_model_info = mlflow.pyfunc.log_model(
name="mcp_agent",
python_model=agent_script,
resources=resources,
)
# TODO UCモデル名をここに指定
UC_MODEL_NAME = f"{catalog}.{db}.databricks_docs_mcp_agent"
registered_model = mlflow.register_model(logged_model_info.model_uri, UC_MODEL_NAME)
deployment_info = agents.deploy(
model_name=UC_MODEL_NAME,
model_version=registered_model.version,
)
エージェントリクエスト作成中...
予測実行中...
MCPサーバー https://xxxx.11.azuredatabricks.net/api/2.0/mcp/vector-search/takaakiyayoi_catalog/rag_chatbot_jpn からツール一覧を取得
元名: 'takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index'
サニタイズ後: 'takaakiyayoi_index' (長さ: 18, valid: True)
1個のツールを正常にロード
モデルロード時に1個のツールを初期化
レスポンス:
type='message' id='236447da16204b05a091133494c1316d' role='assistant' content=[{'type': 'output_text', 'text': 'Databricksは、ビッグデータ分析とAIのためのクラウドベースのプラットフォームです。以下がDatabricksの主な特徴です:\n\n1. **Apache Sparkベースのプラットフォーム**:\n - Databricksは、Apache Sparkの創設者によって設立された企業です\n - Apache Sparkを核としたデータ処理エンジンを提供しています\n\n2. **Databricks Data Intelligence Platform**:\n - データ分析、機械学習、AIワークロードを効率的に実行するための統合環境\n - データエンジニアリングからデータサイエンス、ビジネスインテリジェンスまでをカバー\n\n3. **主な機能**:\n - コラボレーション可能なノートブック環境\n - 自動スケーリングするクラスターとSQLウェアハウス\n - Delta Lakeによるデータレイクの管理\n - 複数のプログラミング言語をサポート(Python、R、Scala、SQL)\n - 機械学習ワークフローの最適化\n\n4. **Databricks Runtime**:\n - Apache Sparkの最適化バージョン\n - Photon(C++で書き直された高性能エンジン)を含む\n - 多数のオープンソースライブラリを統合\n\n5. **企業向け機能**:\n - セキュリティ機能\n - データ共有(Delta Sharing)\n - ワークスペース間連携(Lakehouse Federation)\n - CI/CDとDevOpsのサポート\n\nDatabricksは、大規模なデータ処理と分析、機械学習モデルの開発とデプロイメント、ビジネスインテリジェンスなど、データドリブンな意思決定を支援するための包括的なプラットフォームとして、多くの企業で採用されています。'}]
🔗 View Logged Model at: https://xxxx.11.azuredatabricks.net/ml/experiments/3532923256599563/models/m-d6f067f0588b41e1890660199c432e9a?o=984752964297111
エージェントリクエスト作成中...
予測実行中...
MCPサーバー https://xxxx.11.azuredatabricks.net/api/2.0/mcp/vector-search/takaakiyayoi_catalog/rag_chatbot_jpn からツール一覧を取得
元名: 'takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index'
サニタイズ後: 'takaakiyayoi_index' (長さ: 18, valid: True)
1個のツールを正常にロード
モデルロード時に1個のツールを初期化
2025/07/03 06:14:06 INFO mlflow.pyfunc: Predicting on input example to validate output
レスポンス:
type='message' id='7d908e1803d244b28a3c4b949ff5f9e7' role='assistant' content=[{'type': 'output_text', 'text': 'Databricksは、ビッグデータ処理とAI/機械学習のためのクラウドベースのデータプラットフォームです。以下にDatabricksの主な特徴を説明します:\n\n## Databricksとは\n\n1. **Apache Sparkベースのプラットフォーム**:\n - Databricksは、Apache Sparkのオリジナルクリエイターによって設立された会社が開発したプラットフォームです\n - Apache Sparkを核としており、それを最適化・拡張したサービスを提供しています\n\n2. **データ処理と分析の統合環境**:\n - ビッグデータ処理、データエンジニアリング、データサイエンス、機械学習のためのワークフローを一つのプラットフォームで提供\n - コラボレーション機能を備えたノートブック形式のインターフェースを提供\n\n3. **主な機能と特徴**:\n - **Databricks Runtime**: Apache Sparkの最適化バージョンと追加機能を含む\n - **Photon**: C++で書き直された高性能なApache Sparkエンジン\n - **SQL機能**: データベースオブジェクトの作成や照会のための標準SQL構文をサポート\n - **機械学習サポート**: TensorFlowやSciKit Learnなどの主要なライブラリをサポート\n\n4. **コンピューティングリソース管理**:\n - クラスターやSQLウェアハウスなどのコンピューティングリソースを自動的に管理\n - パーソナルコンピュートポリシーにより、個々のユーザーがシングルマシンのコンピュートリソースを簡単に作成可能\n\n5. **クラウド統合**:\n - 主要なクラウドプロバイダー(AWS、Azure、Google Cloud)と統合されており、それぞれのクラウド上でサービスを提供\n\nDatabricksは、企業がデータから価値を引き出すためのエンドツーエンドのデータ分析プラットフォームとして、データエンジニアリングからデータサイエンス、ビジネスインテリジェンスまでの幅広いユースケースをサポートしています。'}]
MCPサーバー https://xxxx.11.azuredatabricks.net/api/2.0/mcp/vector-search/takaakiyayoi_catalog/rag_chatbot_jpn からツール一覧を取得
元名: 'takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index'
サニタイズ後: 'takaakiyayoi_index' (長さ: 18, valid: True)
1個のツールを正常にロード
モデルロード時に1個のツールを初期化
エージェントリクエスト作成中...
予測実行中...
MCPサーバー https://xxxx.11.azuredatabricks.net/api/2.0/mcp/vector-search/takaakiyayoi_catalog/rag_chatbot_jpn からツール一覧を取得
元名: 'takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index'
サニタイズ後: 'takaakiyayoi_index' (長さ: 18, valid: True)
1個のツールを正常にロード
モデルロード時に1個のツールを初期化
レスポンス:
type='message' id='5f42fac755d14e0e803886ba47fe6d42' role='assistant' content=[{'type': 'output_text', 'text': 'Databricksは、ビッグデータ分析とAI/機械学習のためのクラウドベースのデータプラットフォームです。以下にDatabricksの主要な特徴と概要をご説明します:\n\n### Databricksの概要\n\n1. **起源と基盤技術**:\n - Apache Sparkのオリジナルクリエイターによって設立された企業です\n - Apache Sparkを核としたデータ処理プラットフォームを提供しています\n\n2. **Databricks Data Intelligence Platform**:\n - データレイクハウス(データレイクとデータウェアハウスの利点を組み合わせた)アーキテクチャを採用\n - 大規模なETL処理からインタラクティブなクエリまで、様々なデータワークロードをサポート\n\n3. **主要コンポーネント**:\n - **Databricks Runtime**: Apache Sparkを最適化し、拡張した実行環境\n - **Delta Lake**: オープンソースのストレージレイヤー(デフォルトのテーブル形式)\n - **コンピューティングクラスター/SQLウェアハウス**: データ処理のための計算リソース\n\n4. **主な用途と機能**:\n - データエンジニアリング(ETL処理)\n - データ分析とビジネスインテリジェンス\n - 機械学習とAI開発\n - コラボレーション機能を備えたノートブック環境\n - SQL分析のためのDatabricks SQL\n\n5. **最適化と性能**:\n - ディスクキャッシング、ダイナミックファイルプルーニングなど多数の自動最適化\n - コストベースのオプティマイザによるクエリパフォーマンス向上\n - 複雑なデータ型(配列、構造体、JSON)の効率的な操作\n\nDatabricksは、データエンジニア、データサイエンティスト、ビジネスアナリストなど様々なユーザーが協力して、大規模なデータ処理と分析を行うための統合プラットフォームとして機能します。クラウドネイティブで、主要なクラウドプロバイダー(AWS、Azure、Google Cloud)上で利用可能です。'}]
MCPサーバー https://xxxx.11.azuredatabricks.net/api/2.0/mcp/vector-search/takaakiyayoi_catalog/rag_chatbot_jpn からツール一覧を取得
元名: 'takaakiyayoi_catalog__rag_chatbot_jpn__databricks_documentation_vs_index'
サニタイズ後: 'takaakiyayoi_index' (長さ: 18, valid: True)
1個のツールを正常にロード
モデルロード時に1個のツールを初期化
Successfully registered model 'takaakiyayoi_catalog.rag_chatbot_jpn.databricks_docs_mcp_agent'.
Unity Catalogにモデルが登録されます。Vector Search Indexのリネージもキャプチャされています。

しばらく待つとモデルサービングエンドポイントにデプロイされます。

AI Playgroundでも動作確認できます。

RAGなので、検索結果が得られない質問には回答しません。

Mosaic AI Agent Evaluation を使用して RAG アプリケーションを評価する
ボットとチャットしてバリデーションデータセットを構築しよう!
チャットボットが稼働しました。Databricks には組み込みのチャットボットアプリケーションが用意されており、これを使ってチャットボットをテストし、その回答にフィードバックを与えることができます。
外部のドメインエキスパートにも簡単にアクセス権を付与し、ボットのテストやレビューを依頼できます。ドメインエキスパートは Databricks ワークスペースへのアクセス権がなくても問題ありません。SCIM を有効化していれば、SSO 上の任意のユーザーに権限を割り当てることができます。SCIM についてはこちら
これは評価データセットを構築・改善するための重要なステップです。ユーザーにボットへ質問してもらい、ボットが正しく回答できなかった場合は出力結果を提供しましょう。
チャットボットは、すべての関係者の質問とボットの応答を自動的にキャプチャし、それぞれに対する MLflow トレースも含めて Lakehouse の Delta テーブルに保存します。さらに、Databricks ではエンドユーザーからのフィードバックも簡単に追跡できます。チャットボットが良い回答を返せず、ユーザーが「サムズダウン」をした場合、そのフィードバックも Delta テーブルに記録されます。
評価データセットが準備できたら、それを活用してオフライン評価を行い、新しいチャットボットのパフォーマンスを測定したり、モデルのファインチューニングに利用したりできます。

注意
現在はMLflow 3.0の評価機能が推奨ですが、元のノートブックの親和性からAgent Evaluationを使っています。
Mosaic AI Agent Evaluation 専用の LLM ジャッジモデルでボットの品質を評価しよう
ボットが稼働しました。
RAG アプリケーションの運用には評価が重要です。Databricks では、専用の LLM モデルを使って、ボットの品質・コスト・レイテンシをグラウンドトゥルースがなくても評価できます。
Mosaic AI Agent Evaluation で評価できる項目は以下の通りです:
- 回答の正確性 - グラウンドトゥルースが必要
- 幻覚/根拠の有無 - グラウンドトゥルース不要
- 回答の関連性 - グラウンドトゥルース不要
- 検索精度 - グラウンドトゥルース不要
- (非)有害性 - グラウンドトゥルース不要
import mlflow
from mlflow.deployments import get_deploy_client
# 以下のガイドラインは、エージェントの応答を評価するために使用されます。
global_guidelines = {
"rejection": ["リクエストがDatabricksに関連していない場合、応答はリクエストを拒否する必要があります"],
"conciseness": ["リクエストがDatabricksに関連している場合、応答は簡潔である必要があります"],
"api_code": ["リクエストがDatabricksに関連しており、APIに関する質問の場合、応答にはコードが含まれている必要があります"],
"professional": ["応答はプロフェッショナルである必要があります"]
}
# 評価データセットを定義
eval_set = [{"inputs": {"question": "Databricksとは何ですか?"}},
{"inputs": {"question": "MLflowとは何ですか?"}},
{"inputs": {"question": "Delta LakeとParquetの違いは何ですか?"}}]
# 非常にシンプルなシステムプロンプトエージェントを定義
@mlflow.trace(span_type="AGENT")
def mcp_agent(payload):
return get_deploy_client("databricks").predict(
endpoint="agents_takaakiyayoi_catalog-rag_chatbot_jpn-databricks_docs_mcp",
inputs=payload
)
# mlflow.evaluateで使用するためのラッパー関数
def agent_wrapper(inputs):
# 入力辞書から質問を取得し、ペイロード形式に変換
question = inputs.get("question", "")
agent_payload = {
'input': [
{
'role': 'user',
'content': question,
'type': 'message'
}
]
}
return mcp_agent(agent_payload)
# 評価セットを使用してエージェントを評価し、MLFlowラン "system_prompt_v0" にログ
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=agent_wrapper, # ラッパー関数を使用
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
指定した観点での評価結果を得ることができました。


実際には、このあとは上の評価結果を踏まえてプロンプトやツール、データの見直しを行なっていくことになります。