Productionalize a GEPA optimized Model on Databricks | by AI on Databricks | Jan, 2026 | Mediumの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
著者: Solutions Architect, Jordan Soldo
イントロダクション
(前回のブログ記事で)DatabricksでGEPAを用いて初めてのモデルを最適化することで、大規模な最先端モデルと同等、あるいはそれ以上に優れたパフォーマンスを示すことができる小規模なモデルを手に入れることができました!論理的な次のステップは、あなたのデータを処理するために最適化されたモデルを活用し、スケールさせることです。すると、大きな疑問は「私が最適化したモデルを本番運用に持っていくにはどうしたら?」ということになります。
ストリーミングやバッチ処理を通じて、我々のデータを処理することはできますが、自身のパフォーマンス教会に収まるように、両方の選択肢をどのようにスケールさせるのかを考える必要があります。我々の推論処理をスケールさせるもっとも効果的な方法は、推論を実施するワーカーを追加する水平スケーリングを通じてのものです。様々な色のついた大量のM&M'sがあるものとして、色の順で並び替えしなくてはならないケースを想像してください。これらのM&M'sを並び替える最も効果的な方法は、何人かの友達(ワーカー)を呼んで、それぞれに自身の色付きチョコレートを並び替えさせることでしょう。
Sparkがあなたのために同じ並列処理を適用することができます!Databricksでは、Sparkネイティブの分散処理能力を活用することで、大規模かつコスト効率高く、そしてあなたのユースケースにおけるパフォーマンス要件に応えられるように、あなたのLLMの呼び出しを並列化することができます。
なぜDatabricksで?
我々のデータを処理するためにクイックにスクリプトを準備することができますが、データエンジニアリングプロセス全体に注意を払うことが重要です。
マネージドの並列化 - 自動スケーリングクラスター
Databricksを用いることで、容易にクラスターの規模を定義することができ、Databricksがどのようにクラスターをスケールするのかを管理します。データ処理の要件が変動すると、必要とする計算資源の量は変動するでしょう。このため、コストを最適な状態に保つために、Databricksはユースケースの需要に応じて、お使いのクラスターのサイズを自動でスケールすることができます。
Unity Catalogによるガバナンス
Unity Catalogによって、関数は自動で保護され、データに適用されるのと同様のエンタープライズレベルのセキュリティによってガバナンスが適用されます。これほど高コストな機能は、予算を超過しないよう厳密に管理する必要があります。さらに、DatabricksのSQLエディタを通じて、容易にこの関数を参照することができ、Databricksアカウントのどこでも利用することができます。
どこでも利用
あなたの関数はUnity Catalogに格納されることになるので、同じメタストアに接続された他のワークスペースでも、複雑な管理やプロモーションを必要とすることなしにこの関数を使用することができます!あなた方の開発者はがこの関数の作成を完了すると、適切な権限で持って本番運用ワークスペースで即座に使用を開始できます!
モデルの柔軟性、ガバナンス、制限 & モニタリング
Databricksでは、コントロールのためのAIゲートウェイを提供しているので、モデルを使用する際の支出の暴走が起きないようにすることができます。AIゲートウェイでどのようにコストを制御できるのかを知るには、こちらのブログ記事をご覧ください!
モデルの本番運用
Sparkのユーザー定義関数(UDF)によって、GEPA最適化モデルを導入、スケールさせるための自分の変換ロジックを実装することができます。UDFによって、カスタムロジックを並列化する能力を解放できるように、Sparkが自動でワーカーに分散させるPythonコードをユーザーを提供することができます。これは、我々のレコードを処理する時間を削減するために、我々のモデルを呼び出せるワーカーをさらに必要とするので、GEPA最適化モデルを用いてデータを処理する際には重要となります。
どのようなパフォーマンスの違いが?
pandasのようなシングルコア前提のツールを使っていたのであれば、複数のワーカーが独立してモデルの呼び出しを行うのではなく、レコードの処理は繰り返し行われることになります。これを確認するために、1500レコードに対して一連のテストを行いました。
pandasを用いて上述のレコードを処理すると、データセットを完全に処理するには33分要することがわかりました。このシナリオにおいては、ボトルネックは基盤モデルのエンドポイントではなく、モデルを呼び出すコンピュートクラスターにありました。

しかし、SparkのUDFを実装すると、すぐに大きなブーストを目撃することになりました。シングルノードを使用していても、並列でデータを処理するためにノードの複数のコアを活用できます。4コアのシングルノードを使った際、約14分ですべての処理を行うことができました。これはなんと50%の改善です!
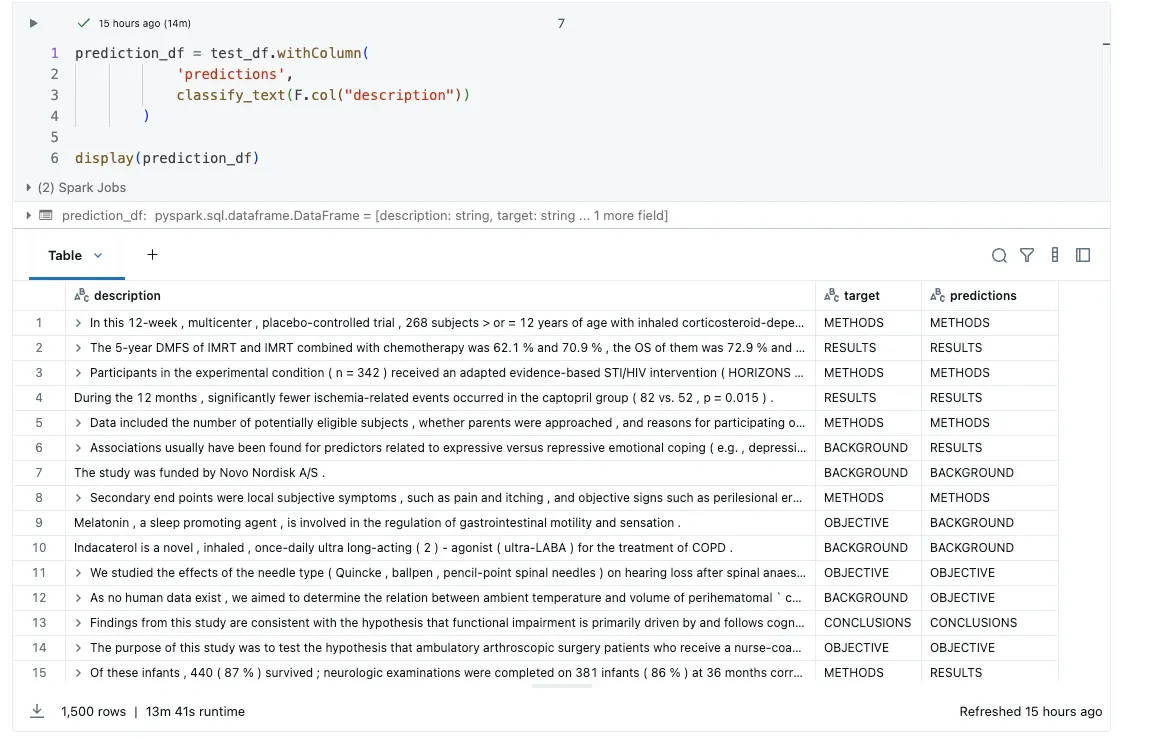
さらに先に進めて、12コアを活用できるように3つのワーカーにしてみましょう。こうすることで、合計処理時間は約7分となり、さらに50%の処理時間の削減を確認することができました。
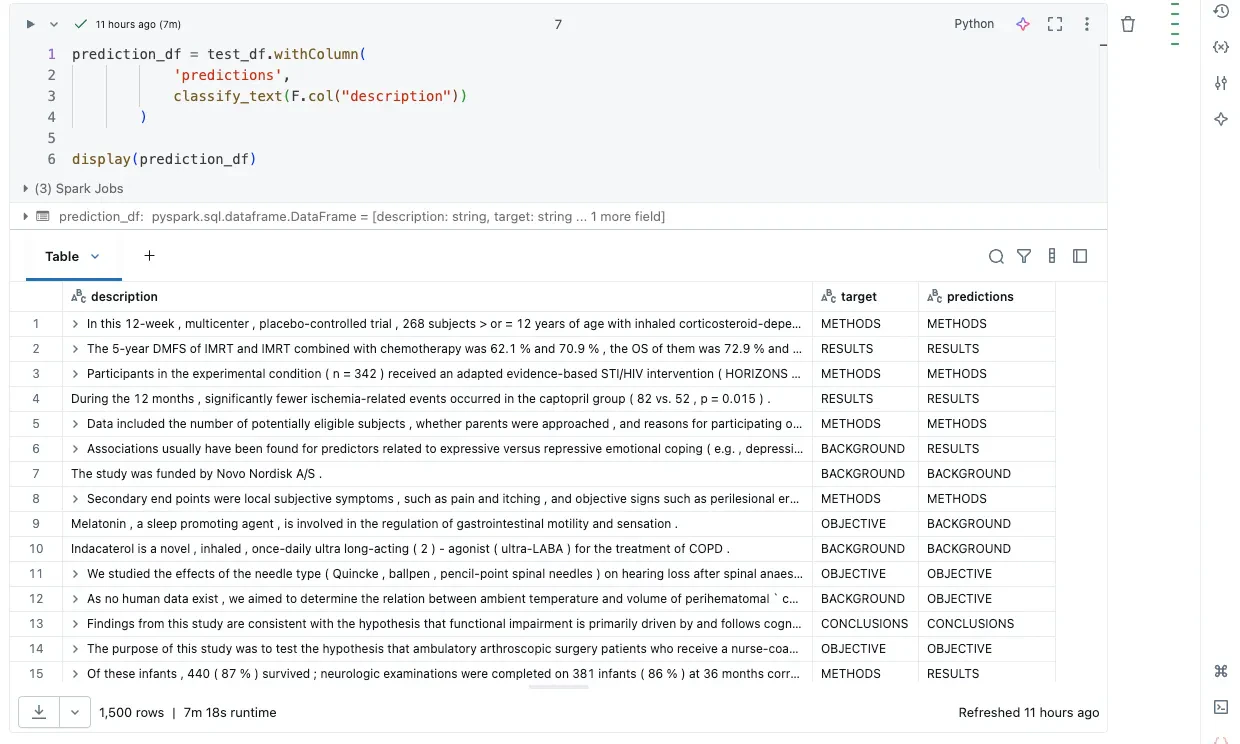
7分は以前として長い時間に見えるかもしれませんが、これらのテストは小規模なテスト環境で行われました。我々は、クラスター動作とモデルエンドポイント自身の両方において、水平スケーリングを継続することができます。あなたのデータがスケールし続けるに従い、どこにボトルネックが出現するのかをチェックすることが重要です。情報に基づいて、本番運用の要件に応えられるように、コンピュートあるいはモデルエンドポイントのいずれかをスケールさせることができます。
データを「どのように」処理するのかが、処理スピードに大きなインパクトを与えることを確認することは簡単です。このため、モデルを本番運用する際に、並列処理の重要性を思い出すことが重要となります。処理能力を分散させるためのSparkのネイティブの能力を用いることで、我々のLLM処理を並列化させることがどれだけ簡単なのかを知ることになります。
データの処理
ステップ1: データのセットアップ
はじめに、バッチ処理するデータをダウンロードして、セットアップしましょう。プロンプトを最適化するために、我々はすでにGEPAを使用し値得るので、テスとデータセットのみを使用します:
# Create our test dataframe using the pubmed-text-classification-cased dataset from hugging face
import numpy as np
import pandas as pd
from dspy.datasets.dataset import Dataset
from pandas import StringDtype
def read_data_and_subset_to_categories() -> tuple[pd.DataFrame]:
"""
Read the pubmed-text-classification-cased dataset. Docs can be found in the url below:
https://huggingface.co/datasets/ml4pubmed/pubmed-text-classification-cased/resolve/main/{}.csv
"""
# Read train/test split
file_path = "https://huggingface.co/datasets/ml4pubmed/pubmed-text-classification-cased/resolve/main/{}.csv"
test = pd.read_csv(file_path.format("test"))
test.drop('description_cln', axis=1, inplace=True)
return test
class CSVDataset(Dataset):
def __init__(
self, n_test_per_label: int = 20, *args, **kwargs
) -> None:
super().__init__(*args, **kwargs)
self.n_test_per_label = n_test_per_label
self._create_train_test_split_and_ensure_labels()
def _create_train_test_split_and_ensure_labels(self) -> None:
"""Perform a train/test split that ensure labels in `test` are also in `train`."""
# Read the data
test_df = read_data_and_subset_to_categories()
test_df = test_df.astype(StringDtype())
# Sample for each label
test_samples_df = pd.concat([
group.sample(n=self.n_test_per_label, random_state=1)
for _, group in test_df.groupby('target')
])
# Set DSPy class variables
self._test = test_samples_df.to_dict(orient="records")
# Sample a train/test split from the pubmed-text-classification-cased dataset
dataset = CSVDataset(n_test_per_label=10)
# Create test set containing DSPy examples
test_dataset = [example.with_inputs("description") for example in dataset.test]
print(f"test dataset size: \n {len(test_dataset)}")
print(f"Train labels: \n {set([example.target for example in dataset.test])}")
# Convert to list of dicts
test_records = [dict(x) for x in test_dataset]
# Create DataFrame
test_df = spark.createDataFrame(test_records)
# Lets check our test records
display(test_df)
大規模処理をテストしたいのであれば、テストデータセットサイズを増やすために、上のコードのdataset = CSVDataset(n_test_per_label=10)を編集することができます。大規模サイズをテストする際は、ペイパートークンで遭遇するリクエスト制限を回避するために、プロビジョン済みスループットエンドポイントを活用することをお勧めします。モデルを呼び出す際に、Databricksでエンドポイントを起動、編集するかに関しては、基盤モデルサービングエンドポイント作成のドキュメントをご覧ください。
ステップ2: GEPA最適化エージェントのセットアップ
以前のブログでGEPAで最適化したのと同じ分類エージェントを使用します。言語モデルにはAPIキーとベースを設定していることに注意することが重要です。これは、ワーカーはノートブックの資格情報を自動的にassumeしないためです。このため、gpt-oss-20bモデルを呼び出す権限を持つサービスプリンシパルのトークンを取得するためにDatabricksのシークレットマネージャを使用します(サービスプリンシパルのセットアップ方法に関してはこちらをご覧ください)。
さらに、GEPAで最適化されたプロンプトを活用するためには、.load(GEPAの.jsonファイルパス)を呼び出す必要があります。
# Create a signature for the DSPy module
class TextClassificationSignature(dspy.Signature):
description: str = dspy.InputField()
target: Literal[
'CONCLUSIONS', 'RESULTS', 'METHODS', 'OBJECTIVE', 'BACKGROUND'
] = dspy.OutputField()
# Create a module that will be used in our batch processing.
class TextClassifier(dspy.Module):
"""
Classifies medical texts into a previously defined set of categories.
"""
def __init__(self, api_key: str, api_base: str):
super().__init__()
# Define the language model. Note how an api key and base are passed
# This is required so that workers have credentials to access to the LLM.
self.lm = dspy.LM(model="databricks/databricks-gpt-oss-20b",
api_key=api_key,
api_base=api_base,
max_tokens = 25000,
cache=False,
reasoning_effort="medium")
# Define the prediction strategy
self.generate_classification = dspy.Predict(TextClassificationSignature)
def forward(self, description: str):
"""Returns the predcited category of the description text provided"""
with dspy.context(lm=self.lm):
return self.generate_classification(description=description)
response = TextClassifier(
api_key = dbutils.secrets.get(scope="secret_token", key="SP_token"),
api_base = f"https://{spark.conf.get('spark.databricks.workspaceUrl')}/serving-endpoints"
)
optimized_gepa_json = "{GEPA_JSON_FILE_PATH}.json"
# Load the optimized prompt
response.load(optimized_gepa_json)
ステップ3: UDFの作成
レコードを処理するために、それぞれのSparkワーカーが自身のレコードバッチを処理できるように、ユーザー定義関数(UDF)を活用します。
キャッシュを無効化していることに注意してください。これは、Sparkではデフォルトキャッシュがすぐに使えないためです。しかし、入力データに繰り返しが含まれることが想定される場合には、ワークスペースでキャッシュディレクトリをセットアップすることができます。
# Create the UDF
@pandas_udf("string")
def classify_text(batch_iter: Iterator[pd.Series]) -> Iterator[pd.Series]:
for questions in batch_iter:
answers = pd.Series([response(question).target for question in questions])
yield answers
# Disable the Cache to prevent errors. You can set a cache using a workspace directory if you expect there to be repeat responses.
dspy.configure_cache(enable_disk_cache=False)
ステップ4: データの処理
UDFを定義したら、先に進んでデータを処理しましょう。これは、対象の入力カラムを用いてUDFを呼び出すだけなので簡単です。Sparkは、データが並列に処理されるように、ワーカー間でのレコードの分散に対応します。
prediction_df = test_df.withColumn(
'predictions',
classify_text(F.col("description"))
)
display(prediction_df)
本番運用における検討事項
バッチとストリーミング処理
上の例では、アドホックな処理、バッチ処理ジョブ、ストリーミングワークフローで、ユーザー定義関数を活用することで、バッチとストリーミングパイプラインの両方でモデルを本番運用し始めることができます。SLAに基づき、Databricksでコンピュートをオートスケールする能力を手にすることで、SLAに収まるようにあなたのジョブのコンピューターを水平にスケールさせることができます。さらに、Databricksはデータ処理のコスト効率性を保証するように、基盤モデルのエンドポイントもオートスケールさせます。
本番運用の検討事項 - リクエストの制限
現時点では、小規模ユースケースに適したペイパートークンのエンドポイントを活用しています。しかし、大規模になるとレート制限に直面することになります。このシナリオにおいては、大規模にデータを処理するための専用コンピュートを確実に保持しつつも、コストと時間の効率性も保証する、Databricksのプロビジョン済みスループットを活用することができます。Databricksによって、予算内に収まり続けられるように、お使いのプロビジョン済みスループットエンドポイントの規模をコントロールすることができます。
プロビジョン済みエンドポイントを起動するには、dspy.LM(model=”databricks/databricks-gpt-oss-20b)をmodel=”databricks/{ENDPOINT_NAME}”に変更します。
コストの検討事項
ペイパートークンを使い続けることは魅力的ですが、リクエストの制限以外にも、プロビジョン済みスループットエンドポイントと比較してコストが効率的ではない場合があります。データセット全体を処理するなら、トークンごとに支払うよりも、モデルに対して時間課金する方がコストが最適になる場合があります。
さらに、大きなクラスターサイズが常により高価なジョブを意味するわけではありません。ジョブで二倍のコンピュートを使ったて二倍高速に処理を完了すれば、コストは同じままです。このため、SLAを確立し、様々なクラスターサイズをテストし、オートスケーリングを活用することは、最適なクラスター設定のチューニングの助けとなります。
まとめ
増大するパフォーマンス要件に応えるために、データの処理を並列化するSparkユーザー定義関数を用いて、どのようにLLMを本番運用できるのかをみてきました。ワーカーを追加することで、データセット処理に必要な時間を劇的に削減することができます。しかし、ボトルネックは使っているLLMのリクエスト制限の形で派生することを認識することが重要です。
Databricksを用いることで、パフォーマンス境界と予算に収まり続けられるように、データの処理を行うコンピュートと、LLMエンドポイントのサイズの両方をどのようにスケールさせるのかに関して選択できる能力を手にすることになります。
GEPA、DSPy、Databricksに関するインテグレーションや記事を楽しみにしていてください!革新的なプロンプトオプティマイザと膨大な並列処理を組み合わせることで、あなたの生成AIデータ処理アプリケーションを次のレベルに引き上げることができます!