Efficient Training on Multiple GPUs [2024/7/24時点]の翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
単一のGPUでのモデルのトレーニングが遅すぎたり、モデルの重みが単一のGPUのメモリーに収まらない場合、マルチGPU環境への移行が重要な選択肢になるかもしれません。この移行を行う前に、単一GPUにおける効率的なトレーニングのための手法やツールでカバーされている全ての戦略を徹底的に探索してください。これらは、任意の数のGPUにおけるモデルのトレーニングに普遍的に適用できるものです。これらの戦略を活用し、単一のGPUでは不十分であることが分かったら、マルチGPUへの移行を検討しましょう。
単一GPUからマルチGPUへの移行には、ワークロードがリソース横断に分散される必要があるため、いくつかの形態の並列処理を導入する必要があります。並列処理を達成するためには、データの並列処理、tensorの並列処理、パイプラインの並列処理のような複数のテクニックを活用することができます。one-size-fits-allのソリューションは存在せず、最適な設定は、お使いの固有のハードウェアに依存するということに注意することが重要です。
このガイドでは、並列処理のそれぞれのタイプの詳細な説明と、テクニックを組み合わせるための手法、適切なアプローチを選択する方法に関するガイドを提供します。分散トレーニングのステップバイステップのチュートリアルに関しては、🤗 Accelerate documentationをご覧ください。
このガイドで議論される主要なコンセプトはフレームワーク横断で適用できますが、ここでは、PyTorchベースの実装にフォーカスします。
それぞれのテクニックの詳細に踏み込む前に、大規模なインフラストラクチャで大規模なモデルをトレーニングする際のおおまかな意思決定プロセスを見ていきましょう。
スケーラビリティの戦略
あなたのモデルでどれだけのvRAMが必要なのかを見積もるところからスタートします。🤗 Hubでホストされているモデルに関しては、数%のマージンの正確な計算結果を提供するModel Memory Calculatorを使いましょう。
シングルノード / マルチGPU環境における並列化戦略
マルチGPUのシングルノードでモデルをトレーニングする際、あなたの並列化戦略の選択によって、パフォーマンスに重大な影響を与えます。以下で選択肢をブレークダウンします:
ケース1: モデルが単一のGPUに収まる
あなたのモデルが単一のGPUに問題なく収まるのであれば、2つの主要な選択肢が存在します:
- DPP - Distributed DataParallel
- Zero Redundancy Optimizer (ZeRO) - 状況と使用する設定によって、この手法は高速になったり、ならなかったりしますが、実験する価値はあります。
ケース2: モデルが単一のGPUに収まらない
あなたのモデルが単一のGPUに対して大きすぎる場合、検討すべきいくつかの代替案があります:
- PipelineParallel (PP)
- ZeRO
- TensorParallel (TP)
非常に高速なノード間接続(NVLINKやNVSwitchなど)によって、3つの戦略すべて(PP, ZeRO, TP)は、同様のパフォーマンスになるべきです。しかし、それらなしには、PPはTPやZeROよりも高速となります。TPの度数も違いを生み出します。最も適切な戦略を特定するために、ご自身固有の環境で実行することをお勧めします。
TPはシングルノードにおいては、ほとんどのケースで使用されます。このため、TPのサイズ <= ノードあたりのGPU数となります。
ケース3: モデルの最大のレイヤーが単一のGPUに収まらない
- ZeROを使っていない場合、PipelineParallel (PP)単体では大規模なレイヤーに対応するのが不十分なためTensorParallel (TP)を使うべきです。
- ZoROを使っているのであれば、単一GPUにおける効率的なトレーニングのための手法やツールから追加でテクニックを導入します。
マルチノード / マルチGPU環境における並列化戦略
-
高速なノード間接続があるのであれば、以下のいずれかのオプションを検討します:
- ZeRO - モデルに対する変更をほとんど必要としません
- PipelineParallel(PP)、 TensorParallel(TP)、DataParallel(DP)の組み合わせ - このアプローチによって通信を削減できますが、モデルの大幅な変更が必要となります
-
ノード間の接続が遅く、GPUメモリーでも遅い場合:
- PipelineParallel(PP)、 TensorParallel(TP)、DataParallel(DP)とZeROの組み合わせを活用
このガイドの以下のセクションでは、これらの並列処理手法がどのように動作するのかについてディープダイブします。
データの並列処理
2つのみのGPUであっても、DataParallel (DP)やDistributedDataParallel (DDP)のようなPyTorchのビルトインの機能によって提供される高速化トレーニング機能を活用することができます。PyTorch documentationでは、DistributedDataParallel (DDP)は全てのモデルで動作するので、マルチGPUにおいてはDataParallel (DP)よりも推奨されていることに注意してください。これら二つの手法がどのように動作し、何が違うのかを見ていきましょう。
DataParallel vs DistributedDataParallel
2つの手法におけるGPU間通信のオーバーヘッドにおける主な違いを理解するために、バッチごとのプロセスを確認しましょう:
DDP:
- 起動時、メインプロセスがGPU 0からモデルを他のGPUに複製する
- それぞれのバッチにおいて:
- それぞれのGPUがデータのみにバッチを直接処理する。
-
backwardの際、ローカルな勾配が準備できると、全てのプロセスで平均される。
DP:
それぞれのバッチにおいて:
- GPU 0がデータバッチを読み込み、それぞれのGPUにミニバッチを送信する。
- 最新のモデルがGPU 0からそれぞれのGPUに複製される
-
forwardが実行され、ロスを計算するためにそれぞれのGPUからの出力がGPU 0に送信される。 - ロスがGPU 0からすべてのGPUに分配され、
backwardが実行される。 - それぞれのGPUからの勾配がGPU 0に送信され平均される。
主な違いは以下の通りです:
- DDPはバッチごとに勾配の送信の一度の通信しか行いませんが、DPはバッチごとに5回のことなるデータ交換を実行します。DDPはtorch.distributedを用いてデータをコピーしますが、DPは(GILに関係する制限を持ち込む)Pythonのスレッド経由でプロセス内でデータをコピーします。このため、あなたの環境のGPUカード間接続が遅くない限り、通常はDistributedDataParallel(DDP)がDataParallel(DP)より高速となります。
- DPにおいては、GPU 0は他のGPUよりも多くの処理を行うため、GPUの利用率が低くなります。
- DDPでは、複数マシンんにおける分散トレーニングをサポートしていますが、DPではサポートしていません。
これは、DDPとDPの違いの完全なリストではありませんが、他の詳細についてはこのガイドのスコープ外となります。こちらの記事を読むことで、これらの手法をさらに深く理解することができます。
実験を通じて、DPとDDPの違いを説明しましょう。NVLinkがあるという文脈で、DPとDDPの違いをベンチマークします:
- ハードウェア: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (
NV2innvidia-smi topo -m) - ソフトウェア: pytorch-1.8-to-be + cuda-11.0 / transformers==4.3.0.dev0
ベンチマークの一つでNVLink機能を無効にするために、NCCL_P2P_DISABLE=1を使っています。
こちらがベンチマークのコードと出力です:
DP
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
DDP w/ NVlink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
DDP w/o NVlink
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
参照しやすいようにまとめたベンチマーク結果となります:
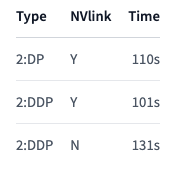
こちらからわかるように、このケースではNVlinkありのDDPよりもDPは約10%遅くなっていますが、NVlinkなしのDDPよりは約15%早くなっています。実際の違いは、GPUどれだけのデータを他のGPUと同期するのかに依存します - 同期すべきデータが多いほど、遅いリンクが全体的な実行時間を占有するようになります。
ZeROによるデータの並列処理
ZeRO-powered data parallelism (ZeRO-DP)は、こちらのブログ記事にある以下の図で説明されます。
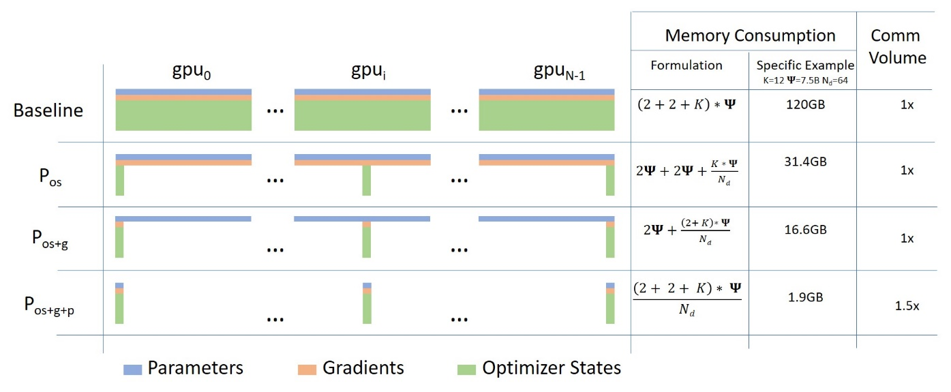
複雑に見えるかもしれませんが、これはDataParallel (DP)と非常に似たコンセプトとなっています。違いは、完全なモデルのパラメーター、勾配、オプティマイザの状態を複製するのではなく、それぞれのGPUはそれのスライスのみを格納するということです。このため、特定のレイヤーで完全なレイヤーのパラメータを必要とする際の実行時においては、保持していない他のパーツのそれぞれを提供するために、すべてのGPUが同期を行います。
この考え方を説明するために、それぞれのレイヤーが3つのパラメーターを有する3つレイヤー(La, Lb, Lc)のシンプルなモデルを考えてみます。例えば、レイヤーLaには重みa0, a1, a2があるとします:
| La | Lb | Lc |
|---|---|---|
| a0 | b0 | c0 |
| a1 | b1 | c1 |
| a2 | b2 | c2 |
3つのGPUがある場合、ZeRO-DPは以下のように3つのGPUにモデルを分割します:
GPU0:
| La | Lb | Lc |
|---|---|---|
| a0 | b0 | c0 |
GPU1:
| La | Lb | Lc |
|---|---|---|
| a1 | b1 | c1 |
GPU2:
| La | Lb | Lc |
|---|---|---|
| a2 | b2 | c2 |
ある意味では、レイヤーグループ全体を異なるGPUに配置するVerticalスライシングとは逆のtensor並列処理と同じものと言えます。どのように動作するのかを見てみましょう:
これらのGPUのそれぞれは、DPの動作と同じように通常のミニバッチを受け取ります:
x0 => GPU0
x1 => GPU1
x2 => GPU2
オリジナルのモデルで処理されるかのように、変更なしに入力は引き渡されます。
はじめに、入力はレイヤーLaに到達します。この時点で何が起きるのでしょうか?
GPU0: x0のミニバッチははレイヤーを通じたフォワードパスを行うためにa1とa2のパラメータを必要としますが、GPU0にはa0しかありません。GPU1からa1、GPU2からa2を取得し、モデルのすべてのピースをまとめます。
並行して、GPU1には別のミニバッチx1があります。GPU1にはa1パラメータがありますが、a0とa2が必要なので、GPU0とGPU2からそれらを取得します。ミニバッチx2を受け取るGPU2でも同様のことが起きます。GPU0とGPU1からa0とa1を取得します。
このように、3つのGPUそれぞれが完全なtensorを再構築し、自分のミニバッチでforward passを行います。計算が完了すると、不要となったデータは削除されます - 計算時にのみ使用されるのです。再構築はpre-fetchを通じて効率的に行われます。
レイヤーLbでもプロセス全体が繰り返され、forward-wiseでLcでも実行され、Lc -> Lb -> Laにbackwardします。
このメカニズムは効率的なグループバックパッキング戦略と似ています: person Aがテントを運び、person Bがストーブ、person Cが斧を運びます。それぞれの夜に、彼らは持っているものを他の人と共有し、持っていないものを他の人から借り、朝になると割り当てられたタイプのギアをパッキングし、道のりを続けます。これがまさにZeRO DP/Sharded DDPです。この戦略を、より非効率的な各人が自分のテント、ストーブ、斧を持ち運ぶ(PyTorchのDataParallel (DP and DDP)と類似した)シンプルな戦略と比較してみてください。
このトピックに関する文献を読んでいると、Sharded、Partitionedのような類義語に遭遇するかもしれません。ZeROがモデルの重みをパーティショニングする方法に注意を払うと、後ほど議論するTensorの並列処理に非常に似ていることがわかります。これは、次に議論する垂直モデル並列処理とは異なり、それぞれのレイヤーの重みをパーティショニング/シェーディングするためです。
実装には以下があります:
- DeepSpeed ZeRO-DP stages 1+2+3
- Accelerate integration
- transformers integration
ナイーブなモデル並列処理からパイプラインの並列処理へ
パイプラインの並列処理を説明するために、はじめに垂直MPとしても知られているナイーブなモデル並列処理(MP)を見ていきます。このアプローチには、.to()を用いて特定のGPUに特定のレイヤーを割り当てることで、複数のGPUに対してモデルレイヤーのグループを分散する処理が含まれます。データがこれらのレイヤーを流れていくと、レイヤーと同じGPUに移動し、他のレイヤーでは何も起きません。
モデルがビジュアライズされる様子から、このモデルの並列処理を"垂直"と呼んでいます。例えば、以下の図では、レイヤー0-3がGPU0、4-7がGPU1に割り当てられ、2つのスライスに垂直に分割された8レイヤーのモデルを示しています:
================
| Layer | |
| 0 | |
| 1 | GPU0 |
| 2 | |
| 3 | |
================
| Layer | |
| 4 | |
| 5 | GPU1 |
| 6 | |
| 7 | |
================
この例では、レイヤー0から3にデータが移動する際、通常のforward passとの違いはありません。しかし、レイヤー3から4へのデータの引き渡しには、GPU0からGPU1への移動が必要となり、コミュニケーションのオーバーヘッドが発生します。使用しているGPUが同じコンピュートノードにある場合(同じ物理マシンなど)には、このコピーは高速ですが、異なるコンピュートノード(複数マシンなど)にGPUが分散している場合、コミュニケーションのオーバーヘッドが非常に大きくなる場合があります。
これと同じように、レイヤー4から7もオリジナルのモデルのように動作します。7番目のレイヤーが完了すると、多くの場合、ラベルが存在するレイヤー0にデータが戻されます(あるいは、ラベルを最終レイヤーに送信します)。これで、ロスを計算することができ、オプティマイザが自身の仕事を行うことができます。
ナイーブなモデルの並列処理にはいくつかの欠点があります:
- 特定のタイミングで一つ以外のGPUがアイドル状態になる: 4GPUが使用されている際、シングルGPUの四倍のメモリーにほぼ等しくなり、残りのハードウェアを無視しています。
- デバイス間のデータ転送のオーバーヘッド: 例えば、4xの6GBカードでは、ナイーブなMPを用いた1xの24GBカードと同じ能力を持ちますが、単一の24GBカードは、データコピーのオーバーヘッドがないためトレーニングをより早く完了することになります。しかし、40GBのカードが手元にあり、45GBモデルにフィットさせる必要がある場合、4xの40GBカードで行うことができます(しかし、勾配とオプティマイザの状態のためギリギリとなります)。
- 共有エンべディングのコピー: 共有エンべディングは、GPU間でコピーする必要があるかもしれません。
モデルの並列処理に対するナイーブなアプローチがどのように動作するのか、その欠点に慣れ親しんだので、パイプラインの並列処理(PP)を見ていきましょう。PPはナイーブMPとほとんど同じですが、到着するバッチをマイクロバッチにチャンキングし、異なるGPUが計算プロセスに同時に参加できるようにするパイプラインを人工的に作成することで、GPUのアイドル問題を解決します。
GPipe paperの以下の図では、上にナイーブなMP、下にPPを示しています:
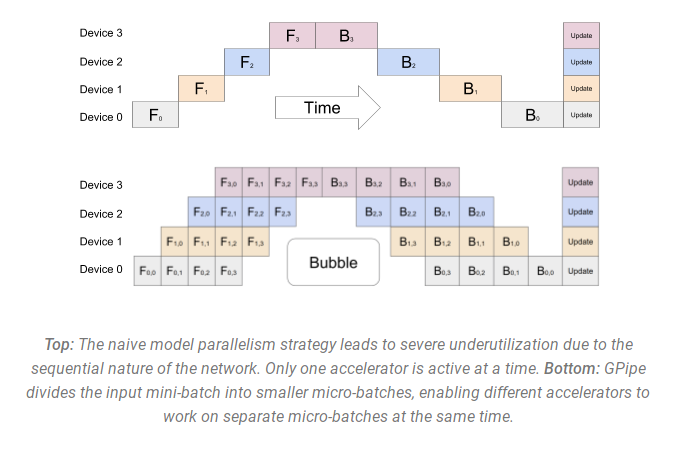
図の下部では、パイプラインの並列処理(PP)が'bubles'と呼ばれるGPUのアイドル領域の数を最小化していることを観測できます。図の両方のパーツでは、パイプラインに4つのGPUが関係していることを意味する度数4の並列度レベルを示しています。4つのパイプステージのフォワードパス(F0, F1, F2, F3)に続いて逆の順のバックワードパス(B3, B2, B1, B0)を確認できます。
PPでは、チューニングする新たなハイパーパラメータを導入します - 同じパイプラインステージを通じて順にどれだけのデータチャンクを送信するのかを決定するchunksです。例えば、図の下部ではchunks=4を確認できます。GPU0は、チャンク0、1、2、3で同じフォワードパス(F0,0, F0,1, F0,2, F0,3)を実行し、他のGPUが自分の作業を完了するのを待ちます、他のGPUが自身の作業を完了し始めた時のみ、GPU0はチャンク3、2、1、0のバックワードパス(B0,3, B0,2, B0,1, B0,0)を再開します。
これは、gradient accumulation stepsと同じコンセプトであることに注意してください。PyTorchではchunksを使いますが、DeepSpeedでは同じハイパーパラメータをgradient accumulation stepsと呼びます。
chunksによって、PPではマイクロバッチ(MBS)の概念を導入しています。DPでは、グローバルのデータバッチサイズをミニバッチに分割するので、DPを度数4にした場合、グローバルバッチサイズが1024の場合は、それぞれ256(1024/4)の4つのミニバッチに分割されることになります。そして、チャンクの数(GAS)が32の場合、マイクロバッチのサイズは8(256/32)になります。それぞれのパイプラインステージは、一度に単一のマイクロバッチを取り扱います。DP + PP環境のグローバルバッチサイズを計算するには、数式: mbs * chunks * dp_degree (8 * 32 * 4 = 1024)を使います。chunks=1では、非効率なナイーブMPになってしまいます。チャンクの数を大きくしても、非効率的な小さいマイクロバッチサイズになってしまいます。このため、もっともGPU使用効率の高いものにつながるものを見つけ出すために、chunksで実験を行うことをお勧めします。
パイプラインを完了するには、最後のforwardステージがbackwardを待たなければいけないため、図にバブルの"死んでいる"時間があることに気付いたかもしれません。chunksのベストな値を見つける目的は、バブルのサイズの最小化につながる、参加するGPUすべてにおけるGPUの同時利用率を高めることになります。
パイプラインAPIのソリューションは以下で実装されています:
- PyTorch
- DeepSpeed
- Megatron-LM
これらにはいくつかの欠点があります:
- パイプラインはモジュールの通常のフローを
nn.Sequentialのシーケンスの同じものに書き換える必要があり、モデルの設計に合わせた変更を必要とする場合があるため、モデルを大幅に変更しなくてはなりません。 - 現時点では、Pipeline APIは非常に限定的です。パイプラインの最初のステージに一連のPython変数が引き渡される場合には、回避策を見つけ出さなくてはなりません。現時点では、パイプラインのインタフェースには入出力のみにおいて、単一のTensorやTensorのタプルのいずれかが必要となります。パイプラインはミニバッチをマイクロバッチにチャンキングすることになるため、これらのTensorの最初の次元としてバッチサイズを有する必要があります。可能性のある改善点に関しては、こちらで議論されています https://github.com/pytorch/pytorch/pull/50693
- パイプステージのレベルにおいて条件分岐のフローは不可能です。T5のようなEncoder-Decoderモデルでは、条件分岐のエンコーダーステージに対応するために特殊なワークアラウンドが必要となります。
- あるレイヤーの出力が別のレイヤーへのインプットになるように、それぞれのレイヤーをアレンジする必要があります。
さらに最新のソリューションには以下のようなものがあります:
- Varuna
- Sagemaker
VarunaやSagemakerで実験していませんが、彼らの論文では上述の一連の問題を解決し、ユーザーのモデルへの変更は小規模であると報告しています。
実装には以下のようなものがあります:
- PyTorch (pytorch-1.8で初期サポートされ、1.9で改善され、1.10でさらに改善されています) いくつかのサンプル
- DeepSpeed
- Megatron-LMには内部実装がありますが、APIはありません。
- Varuna
- SageMaker - これはAWSでのみ使用できるプロプライエタリなソリューションです。
- OSLO - これはHugging Face Transformersをベースに実装されています。
🤗 Transformersのステータス: こちら記事の執筆時点では、完全にPPをサポートしているモデルはありません。GPT2とT5モデルはナイーブなMPサポートをしています。主な障壁は、モデルをnn.Sequentialに変換し、すべての入力をTensorにするという点です。これは、現時点ではモデルに変換を複雑にする数多くの機能が含まれているためであり、これを達成するためにはこれらを削除する必要があります。
🤗 AccelerateではDeepSpeedとMegatron-LMインテグレーションを利用できます。
他のアプローチには以下のようなものがあります:
DeepSpeed、Varuna、SageMakerでは、Interleaved Pipelineのコンセプトを採用しています。

ここでは、バックワードパスを優先度づけることで、さらにバブル(アイドル時間)が最小化されています。Varunaでは、最も効率的なスケジューリングを発見するためにシミュレーションを用いることで、スケジュールの改善をさらに試みます。
OSLOには、nn.Sequential変換なしのTransformersをベースとしたパイプライン並列処理実装があります。
Tensorの並列処理
Tensorの並列処理では、それぞれのGPUがTensorのスライスを処理し、それを必要とするオペレーションでのみ完全なTensorを集約します。この手法を説明するために、このガイドのこのセクションではMegatron-LMの論文: Efficient Large-Scale Language Model Training on GPU Clustersの図とコンセプトを活用します。
すべてのTransformerの主要なビルディングブロックは、非線形アクティベーションGeLUがつながる、完全に接続されたnn.Linearです。Megatronの論文の記述に従うと、そのdot dot-productのパートはY = GeLU(XA)と記述することができ、Xは入力ベクトル、Yは出力ベクトル、Aは重みの行列となります。
行列における計算処理を見ると、行列の操作が複数のGPU間でどのように分割されるのかを確認できます:
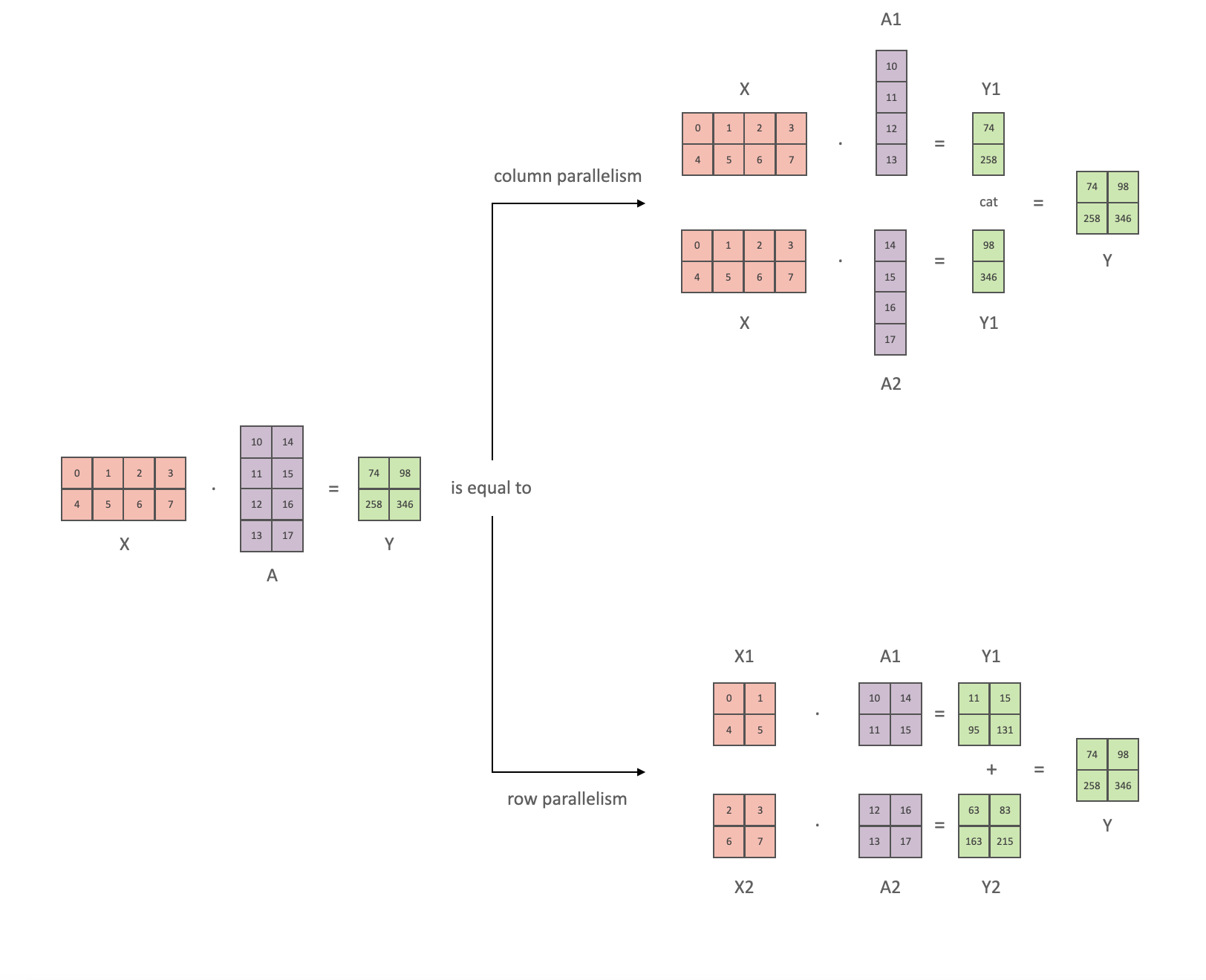
重みのマトリクスAをN個のGPUにおけるカラムワイズに分割し、並列でXA_nを通じてマトリクスの積算XA_1を実行すると、独立してGeLUに投入可能なN個の出力ベクトルY_1, Y_2, ..., Y_nが得られることになります:
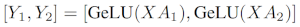
この原則を用いることで、シャードから出力ベクトルの再構築が必要となるGPU間の同期を最後まで必要とすることなしに、任意の深さのマルチレイヤーのパーセプションを更新することができます。Megatron-LMの論文の著者はこれに対する有用なイラストレーションを提供しています:
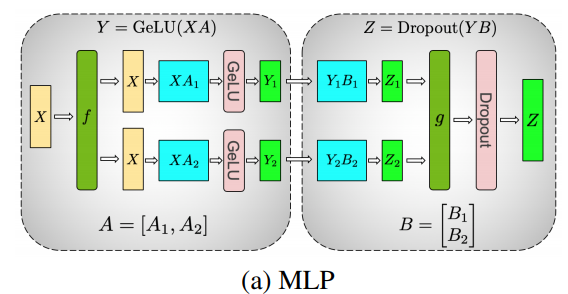
マルチヘッドのあるアテンションレイヤーの並列化は、それらが複数の独立したヘッドを持っており元々並列になっているので、さらにシンプルなものとなります!
特別な検討事項: TPでは非常に高速なネットワークが必要となり、このため、1ノード以上でTPを行うことはお勧めしません。実際、ノードに4つのGPUがある場合、最高のTPの度数は4となります。8の度数のTPが必要な場合、少なくとも8つのGPUを持つノードが必要となります。
このセクションは、@anton-lによるdetailed TP overviewをベースとしています。
別名:
- DeepSpeedではtensor slicingと呼んでいます。
実装:
- Megatron-LMには内部実装があり、非常にモデル固有のものとなっています
- parallelformers (現時点では推論のみ)
- SageMaker - AWSでのみ利用できるプロプライエタリなソリューションです
- OSLOには、Transformersをベースとしたtensor並列処理実装があります
SageMakerではより効率的な処理のためにDPとTPを組み合わせています。
🤗 Transformersのステータス:
- core: コアでは実装されていません
- しかし、推論で必要であれば、parallelformersは、モデルの多くに対するサポートを提供しています。coreで実装されるまでは、それらを使うことができます。また、間もなくトレーニングもサポートされることになります。
- Deepspeed-Inferenceでは、彼らの非常に高速なCUDA-kernelベースの推論モードで、BERT、GPT-2、GPT-Neoモデルもサポートしています。詳細はこちらをご覧ください。
🤗 AccelerateはTP from Megatron-LMとインテグレーションしています。
データの並列処理 + パイプラインの並列処理
以下の図は、DeepSpeedのpipeline tutorialからのもであり、DPとPPをどのように組み合わせているのかを説明しています。
Efficient Training on Multiple GPUs
ここで重要なのは、DPランク0がGPU2を認識せず、DPランク1がGPU3を認識しないことです。DPにおいては、あたかも2つのGPUが存在するかのように、データをフィードするGPU0と1があるだけです。GPU0は"隠れて"、PPを用いてGPU2にいくつかのロードをオフロードします。そして、GPU1もGPU3に助けを求めることで同様のことを行います。
それぞれのディメンションでは少なくとも2つのGPUが必要となるので、最低でも4つのGPUが必要となります。
実装:
🤗 Transformersのステータス: まだ実装されていません
データの並列処理 + パイプラインの並列処理 + Tensorの並列処理
より効率的なトレーニングを行うために、PPがTPやDPと組み合わせられる3Dの並列処理が用いられます。これは以下の図で表現されます。
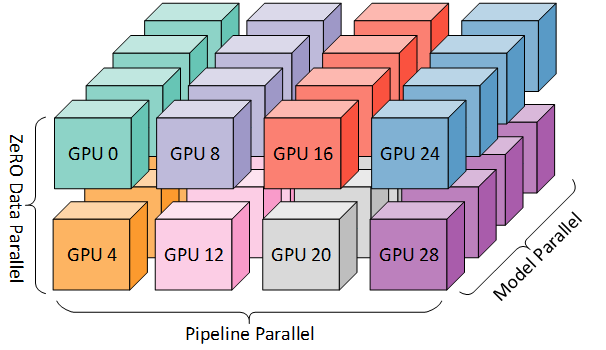
この図は、読むのに適した3D parallelism: Scaling to trillion-parameter modelsのブログ記事から持ってきています。
それぞれの次元では、少なくとも2つのGPUが必要となるので、ここでは少なくとも8つのGPUが必要となります。
実装:
- DeepSpeed - DeepSpeedには、ZeRO-DPと呼ばれる、より効率的なDPも含まれています
- Megatron-LM
- Varuna
- SageMaker
- OSLO
🤗 Transformersのステータス: PPやTPがないのでまだ実装されていません。
ZeROのデータ並列処理 + パイプラインの並列処理 + Tensorの並列処理
DeepSpeedの主要機能の一つが、非常にスケーラブルなものにDPを拡張したZeROです。これはすでにZeROによるデータの並列処理で議論しています。通常、これはPPやTPを必要としないスタンドアローンの機能です。しかし、PPやTPと組み合わせることは可能です。
ZeRO-DPがPP(オプションでTP)と組み合わせると、通常はZeROのステージ1(オプティマイザのシャーディング)のみを有効化します。
理論的には、パイプラインの並列処理を用いることで、ZeROのステージ2を使うことは可能ですが、ネガティブなパフォーマンスの影響が起こります。シェーディングの前に勾配を集約するために、すべてのマイクロバッチに、reduce-scatterの追加の収集が必要となり、大きなコミュニケーションのオーバーヘッドを持ち込むことになります。パイプライン並列処理の性質上、小規模なマイクロバッチが使用され、パイプラインのバブル(マイクロバッチの数)を最小化することで計算的な強度(マイクロバッチのサイズ)をバランスすることにフォーカスします。このため、これらのコミュニケーションのコストがパフォーマンスに影響を与えることになります。
さらに、PPによって通常よりもレイヤーが少なくなっているので、メモリーの節約はそれほどにもなりません。PPはすでに1/PPまで勾配のサイズを削減しているので、それに追加の勾配のシェーディグによる削減は、純粋なDPよりも非常に少ないものとなります。
ZeROステージ3は同じ理由から優れた選択肢とは言えません - より多くのノード間通信が必要となります。
そして、ZeROを使っている際の別のメリットしてZeRO-Offloadがあります。これはステージ1のオプティマイザなので、状態をCPUにオフロードすることができます。
実装:
- Megatron-DeepSpeedと、前者のレポジトリのフォークであるMegatron-Deepspeed from BigScience
- OSLO
重要な論文:
🤗 Transformersのステータス: PPやTPがないのでまだ実装されていません。
FlexFlow
FlexFlowも、若干異なるアプローチで並列処理の問題を解決します。
Sample-Operator-Attribute-Parameterに対する一種の4D並列処理を実行します。
- Sample = データ並列処理(サンプルワイズの並列処理)
- Operator = 単一のオペレーションをいくつかのサブオペレーションに並列化
- Attribute = データの並列処理(長さワイズの並列処理)
- Parameter = モデルの並列処理(次元 水平や垂直に関係なし)
例:
- Sample
シーケンス長512の10個のバッチを取りましょう。2つのデバイスにサンプルディメンションで並列化する際、5 x 2 x 512になる10 x 512を得ることになります。
- Operator
レイヤーの正規化を実行する際、最初にstdを計算し、次に平均を計算することでデータを正規化することができます。Operatorの並列処理によって、並列でstdと平均を計算することができます。2つの次元(cuda:0, cuda:1)にOperatorの次元を並列化する際、両方のデバイスに入力データをコピーし、cuda:0でのstdの計算、cuda:1での平均の計算を同時に行うことができます。
- Attribute
512長の10個のバッチがあります。attributeの次元を2つのデバイスに並列化すると、10 x 512は10 x 2 x 256になります。
- Parameter
Tensorモデルの並列処理やナイーブなレイヤーワイズの並列化と似たものとなります。
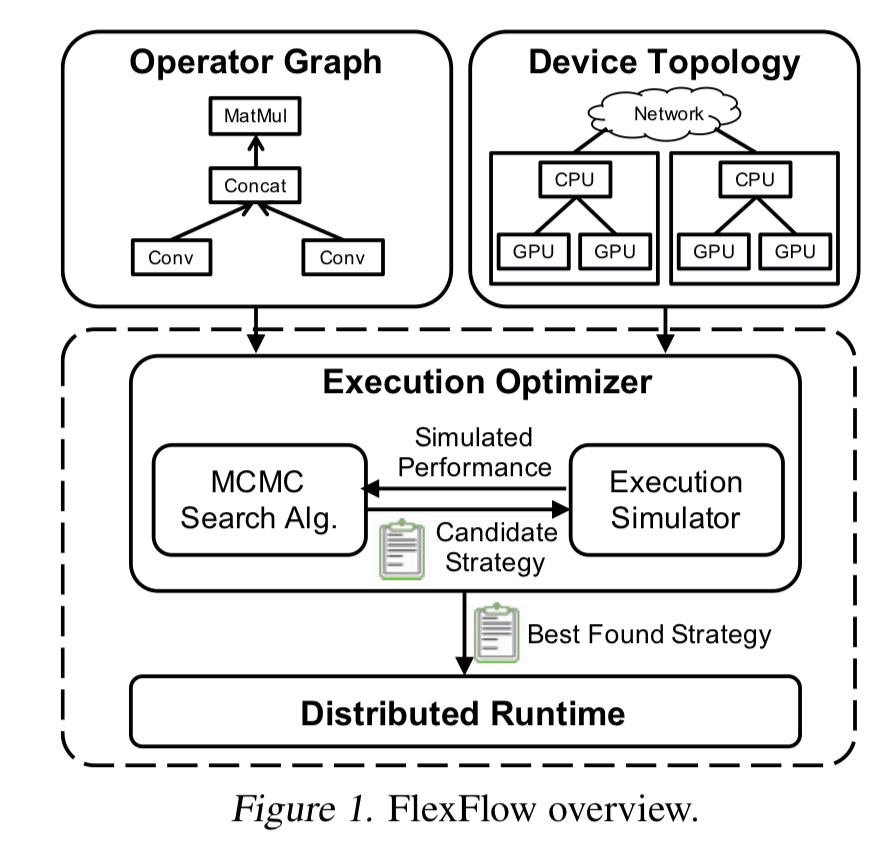
このフレームワークの重要なところは、(1) GPU/TPU/CPU vs. (2) RAM/DRAM vs. (3) fast-intra-connect/slow-inter-connectのようにリソースを取得し、どの並列化処理をどこで使うのかをすべてアルゴリズム的に決定して、自動で最適化を行うという点です。
非常に重要な側面の一つとして、FlexFlowは静的かつ固定のワークロードを持つモデルのDNN並列化の最適化のために設計されたということがあるので、動的な挙動を持つモデルにおいては、イテレーションを通じた別の並列化戦略の方が適しているかもしれません。
この可能性は非常に魅力的です - お好きなクラスターに対して30分のシミュレーションを実行すると、この固有の環境を活用するベストな戦略を導き出します。任意のパーツを追加/除外/置き換えることで、そのための計画を再度最適化することができます。そして、トレーニングを行うことができます。環境が違えば、自身のカスタムの最適化を行うことになります。
🤗 Transformersのステータス: Transformersモデルは、FlexFlowの前提条件であるtransformers.utils.fxを通じたFXでのトレースが可能ですが、Transformersモデルで動作するようにFlexFlowサイドでの変更が必要です。
GPUの選択
複数のGPUでトレーニングを行う際、いくつのGPUを使うのか、どの順番で使うのかを指定することができます。異なる計算パワーを持つGPUがあり、高速なGPUを最初に使いたい場合には有益となります。この選択のプロセスは利用可能なGPUのサブセットのみを使うために、DistributedDataParallelとDataParallelの両方で動作し、AccelerateやDeepSpeedのインテグレーションは不要です。
GPUの数
例えば、4つのGPUがあり、最初の2つのみを使いたい場合には:
torchrun
いくつのGPUを使うのかを選択するために--nproc_per_nodeを使います。
torchrun --nproc_per_node=2 trainer-program.py ...
Accelerate
いくつのGPUを使うのかを選択するために--num_processesを使います。
accelerate launch --num_processes 2 trainer-program.py ...
DeepSpeed
いくつのGPUを使うのかを選択するために--num_gpusを使います。
deepspeed --num_gpus 2 trainer-program.py ...
GPUの順序
どのGPUをどの順番で使うのかを選択するには、CUDA_VISIBLE_DEVICES環境変数を使います。~/bashrcや他のスタートアップ設定ファイルに環境変数を設定するのが一番簡単です。CUDA_VISIBLE_DEVICESは、どのGPUを使うのかをマッピングするために使用されます。例えば、4つのGPU(0, 1, 2, 3)があり、GPU 0と2のみを使いたい場合には:
CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
PyTorchには2つの物理的なGPU(0と2)のみが見え、これらはそれぞれcuda:0とcuda:1にマッピングされます。また、2を最初に使うように順番を逆転することができます。この場合、マッピングはGPU 0がcuda:1、GPU 2がcuda:0になります。
CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
また、GPUなしの環境を作成するために、CUDA_VISIBLE_DEVICES環境変数に空の値を設定することもできます。
CUDA_VISIBLE_DEVICES= python trainer-program.py ...
他の環境変数と同様、コマンドラインに追加するのではなくエクスポートすることができます。これは、環境変数がどのように設定されているのかを失念して、間違ったGPUを使うことになりかねず、混乱を招くためお勧めしません。代わりに、同じコマンドラインで特定のトレーニングに対して環境変数を設定することが一般的なプラクティスとなります。
GPUがどのような順序になるのかをコントロールするために、CUDA_DEVICE_ORDER環境変数を使うこともできます。以下にすることで並び替えを行うことができます:
-
NVIDIAやAMDのGPUのそれぞれに対するnvidia-smiやrocm-smiの順序にマッチするPCIeバスのID
export CUDA_DEVICE_ORDER=PCI_BUS_ID -
GPUの計算能力
export CUDA_DEVICE_ORDER=FASTEST_FIRST
あなたのトレーニング環境に古いGPUと新しいGPUがあり、古いGPUが最初に表示されますが、新しいGPUが最初に表示されるように物理的に入れ替えられない場合には、CUDA_DEVICE_ORDERは特に有用です。この場合、新しくて高速なGPUを常に最初に使うようにするために、CUDA_DEVICE_ORDER=FASTEST_FIRSTを設定します(nvidia-smiやrocm-smiは以前として自身のPCIeの順序でGPUをレポートします)。あるいは、export CUDA_VISIBLE_DEVICES=1,0を設定することもできます。