はじめに
Databricks Agent Bricks の4つのエージェントタイプ (Knowledge Assistant、Information Extraction、Custom LLM、Multi-Agent Supervisor) のうち、本記事では Knowledge Assistant を取り上げます。
Knowledge Assistant は、社内ドキュメントに対する Q&A チャットボットをノーコードで構築できるサービスです。「製品ドキュメント上の Q&A」「人事ポリシーの Q&A」「サポートナレッジベースの Q&A」といったよくあるユースケースを、Vector Search インデックスの構築・RAG パイプラインの実装・評価データセットの整備を意識せずに作れます。
参考ドキュメント: Agent Bricks: Knowledge Assistantを使用して、ドキュメント上に高品質のチャットボットを作成します | Databricks on AWS
公式には英語のみがサポート対象ですが、日本語対応の精度改善は継続的に進められています。本記事では、東京リージョンのワークスペースから日本語ドキュメントで動作確認した結果も含めて、Knowledge Assistant の構築手順を紹介します。
Knowledge Assistant とは
Knowledge Assistant は、ユーザーが提供したドキュメントに基づいて、引用付きの高品質な回答を返すチャットボットを作成するサービスです。
従来の RAG (Retrieval Augmented Generation) で構築する場合、以下を自前で整える必要がありました。
- ドキュメントのチャンク分割
- 埋め込みモデルの選定とインデックス作成
- リトリーバとリランカーのパイプライン構築
- プロンプトテンプレート設計
- 評価データセットの作成と継続的な品質改善
Knowledge Assistant はこれらをマネージドで提供し、内部的には Instructed Retriever と呼ばれるアプローチを採用しています。従来の RAG の限界 (検索精度のばらつき、ガイドラインへの追従の難しさ等) に対応する仕組みです。
作成されたエージェントはモデルサービングエンドポイントとしてデプロイされ、AI Playground、REST API、Python SDK、Databricks Apps から利用できます。
主なユースケース
公式ドキュメントが挙げているユースケースは以下です。
- 製品ドキュメントに基づいて、ユーザーの質問に回答する
- 人事ポリシーに関連する従業員の質問に回答する
- サポートナレッジベースに基づいて、顧客からの問い合わせに回答する
本記事のハンズオンは2つめの「人事ポリシー Q&A」を題材にします。
前提条件
Knowledge Assistant を使うには、以下のワークスペース要件を満たす必要があります。
- MLflow (ベータ版) の本番運用モニタリング機能が有効化済み (トレース機能に必要)
- サーバレスコンピュートが有効
- Unity Catalog が有効
- Mosaic AI Model Serving へのアクセス
- Unity Catalog の
system.aiスキーマ経由で基盤モデルにアクセス可能 - 非ゼロ予算のサーバレス予算ポリシーへのアクセス
- 利用可能なリージョン: 最新の機能リージョン対応表を参照。東京 (
ap-northeast-1) を含む多くのリージョンが対応 (一部はクロスジオルーティング必要)
日本リージョンでの利用可否と日本語ドキュメントの取り扱いについては、後述の「日本での利用に関する重要な注意点」を参照してください。
また、databricks-gte-large-en 埋め込みモデルエンドポイントの AI ガードレールとレート制限を無効化しておく必要があります (Vector Search インデックスを使う場合)。詳細はモデルサービングエンドポイントでのAIゲートウェイの構成を参照してください。
日本での利用に関する重要な注意点
Knowledge Assistant を日本のチーム・日本語ドキュメントで使う際の前提条件と運用上のポイントを整理します。リージョン対応と日本語対応 (改善が継続的に進められている領域) の2点を、ハンズオンに進む前に確認しておくことをおすすめします。
リージョン対応状況
Knowledge Assistant の最新のリージョン対応状況は Databricks 機能リージョン対応表 に集約されています。本記事執筆時点 (2026年5月) の状況は以下です。
制限なしで利用可能なリージョン
- 北米:
us-east-1、us-east-2、us-west-2、ca-central-1 - 欧州:
eu-central-1、eu-west-1、eu-west-2 - アジア・パシフィック:
ap-south-1(ムンバイ) - 南米:
sa-east-1(サンパウロ)
クロスジオルーティング有効化で利用可能なリージョン
-
ap-northeast-1(東京) ← 日本 -
ap-northeast-2(ソウル) -
ap-southeast-1(シンガポール) -
ap-southeast-2(シドニー)
日本拠点での利用
東京リージョン (ap-northeast-1) のワークスペースから、クロスジオルーティング を有効化することで Knowledge Assistant を利用できます。本記事のハンズオンも東京リージョンのワークスペースでの動作確認に基づいています。
クロスジオルーティングを使う場合、一部のワークロード (GPU リソース等を必要とする基盤モデル API ワークロード) は他リージョンで処理される可能性があります。データレジデンシー要件のある業界 (金融、医療、公共等) では、事前に法務・情報セキュリティ部門での確認をおすすめします。
補足: 公式ドキュメントとの差異について
Knowledge Assistant の公式ドキュメントページに掲載されているリージョン一覧には ap-northeast-1 が含まれていません。一方、より広範な 機能リージョン対応表 (2026年5月8日最終更新) では東京リージョンが対応リージョンとして明記されています。後者のほうが最新の状況を反映していると考えられますが、本番運用前に実際のワークスペースでの動作確認をおすすめします。
日本語対応
Knowledge Assistant の公式ドキュメントには、制限事項として「英語のみがサポートされています」と明記されています (出典)。
ただし、Databricks では Knowledge Assistant の 日本語対応の精度改善に継続的に取り組んでおり、日本語ドキュメントでも実用に耐える回答品質が得られるケースが増えてきています。本記事執筆にあたっては、東京リージョンのワークスペースで日本語の人事ポリシードキュメント (Markdown 形式) を対象に動作確認を行い、日本語の質問に対して引用付きの日本語回答が問題なく得られることを確認しています。
日本語ドキュメントで使う際のポイント
公式サポートが英語であることを踏まえると、日本語ドキュメントを扱う場合は以下の点を意識すると効果的です。
- エージェントの「指示」フィールドで日本語応答を明示する (例:「日本語で回答すること」)
- 「コンテンツの説明」を日本語で記述することで、ナレッジソースの内容をエージェントが正しく認識しやすくする
- 「例」タブで日本語の質問とガイドラインを登録し、品質を継続的に改善する
- 評価データセットを日本語で用意し、自社ユースケースでの回答精度を定量的に把握する
本番運用を見据える場合
日本語ドキュメントで本番運用を検討する場合、ユースケースの要求精度に応じて以下のアプローチを使い分けるとよいです。
- 一定の品質で十分なケース (社内 FAQ、参考情報提供等): Knowledge Assistant の UC ファイル方式で評価し、品質要件を満たせば採用
- 高精度・厳密な引用が求められるケース: Mosaic AI Agent Framework で自前 RAG を組み、日本語特化の埋め込みモデル (
databricks-qwen3-embedding-0-6b等) と組み合わせる選択肢を併せて検討
Knowledge Assistant の日本語精度は今後も改善が見込まれるため、現時点で要件を満たさない場合でも、定期的に再評価することをおすすめします。
入力データの選択肢
Knowledge Assistant に渡せるナレッジソースは2種類です。
1. Unity Catalog のボリューム配下のファイル
サポートされるファイルタイプ:
- txt
- md
- ppt/pptx
- doc/docx
50MB を超えるファイル、およびファイル名がアンダースコア (_) またはピリオド (.) で始まるファイルは取り込み時に自動スキップされます。
2. Vector Search インデックス
埋め込みモデルとして databricks-gte-large-en を使用しているインデックスのみサポートされます。日本語ドキュメントを扱う場合の取り扱いは前述の「日本語対応」を参照してください。
制限
Unity Catalog の テーブル は直接サポートされていないので、テーブル形式のデータを使いたい場合は事前に Vector Search インデックスを作成しておくか、ボリュームにテキストファイルとして書き出しておく必要があります。
ハンズオン
事前準備
Q&A の対象としたいドキュメントを、Unity Catalog のボリュームに配置しておきます。サポートされるファイルタイプは txt、pdf、md、ppt/pptx、doc/docx です。
-- カタログ・スキーマ・ボリュームの作成例
CREATE CATALOG IF NOT EXISTS your_catalog;
CREATE SCHEMA IF NOT EXISTS your_catalog.knowledge_assistant_demo;
CREATE VOLUME IF NOT EXISTS your_catalog.knowledge_assistant_demo.docs;
作成したボリューム (例: /Volumes/your_catalog/knowledge_assistant_demo/docs) に、Q&A対象としたいドキュメントをアップロードまたはコピーしておきます。本記事では人事ポリシー (就業規則、有給休暇、リモートワーク、福利厚生等の社内規程ドキュメント) を題材として動作確認した結果を紹介します。
ステップ 1: エージェントを構成する
左サイドメニューの エージェント から Knowledge Assistant タイルにアクセスし、ビルド をクリックします。
ビルド タブで以下を設定します。
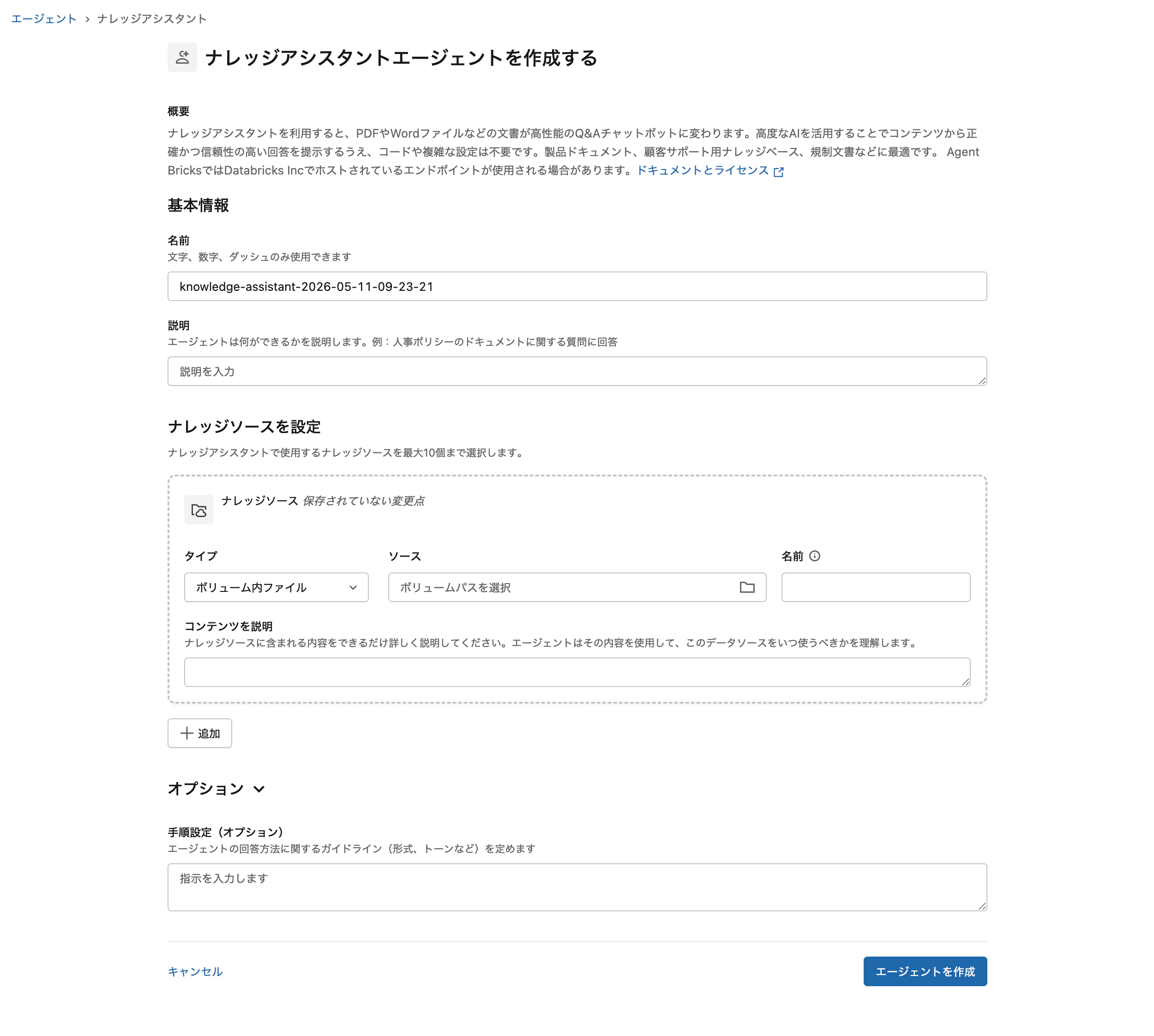
名前と説明
設定例 (人事ポリシー Q&A の場合):
-
名前:
hr-policy-assistant - 説明: 人事ポリシーに関する質問に回答するアシスタント
説明は後述する Multi-Agent Supervisor から呼び出される際に「いつこのエージェントに振り分けるか」の判断材料になるので、対象範囲を明確に書きます。
ナレッジソースの追加
ナレッジソース パネルで ナレッジソースの追加 をクリックします。
- タイプ: UC ファイル
-
ソース: 事前準備で作成したボリューム (例:
/Volumes/your_catalog/knowledge_assistant_demo/docs) -
名前:
hr_policies(任意) - コンテンツの説明: 「人事ポリシー、就業規則、福利厚生、休暇制度、リモートワーク制度、評価制度、情報セキュリティポリシー等の社内規程を含む」
ナレッジソースは最大10個まで追加できます。シンプルなユースケースなら1ソースで十分です。
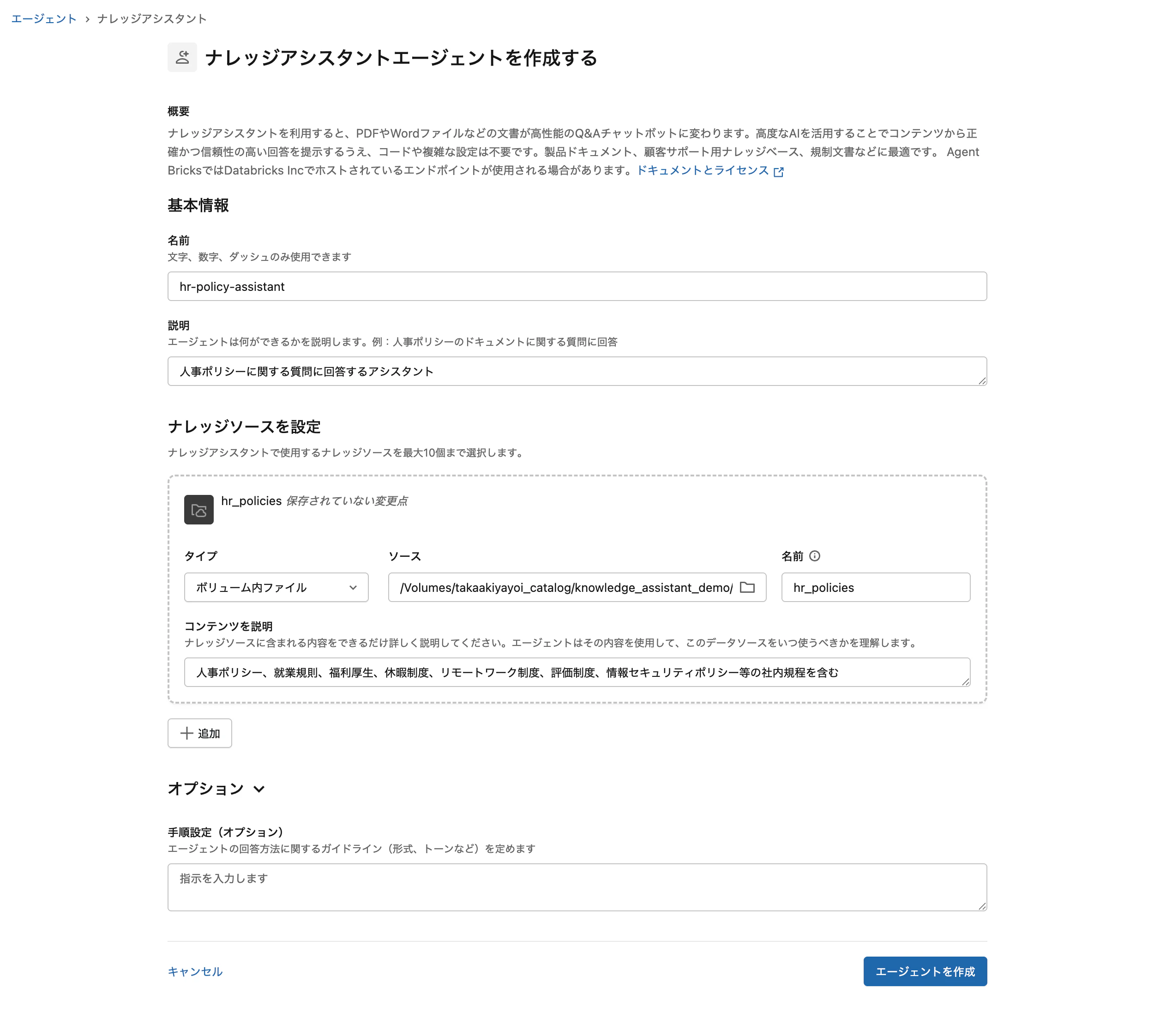
指示 (オプション)
指示 フィールドに、エージェントの応答方針を自然言語で書きます。日本語で応答させたい場合は、ここに明示するのが効果的です。
設定例:
- 質問に対しては、根拠となるポリシー条文または規程を引用すること
- 規程に明記されていない事項については、推測せず「人事部にお問い合わせください」と回答すること
- 改定履歴がある場合は、最新の内容に基づいて回答すること
- 日本語で回答すること
エージェントの作成
エージェントの作成 をクリックします。ナレッジソースの同期に最大数時間かかる場合があります。完了すると右側のパネルに同期済みのソースが表示されます。
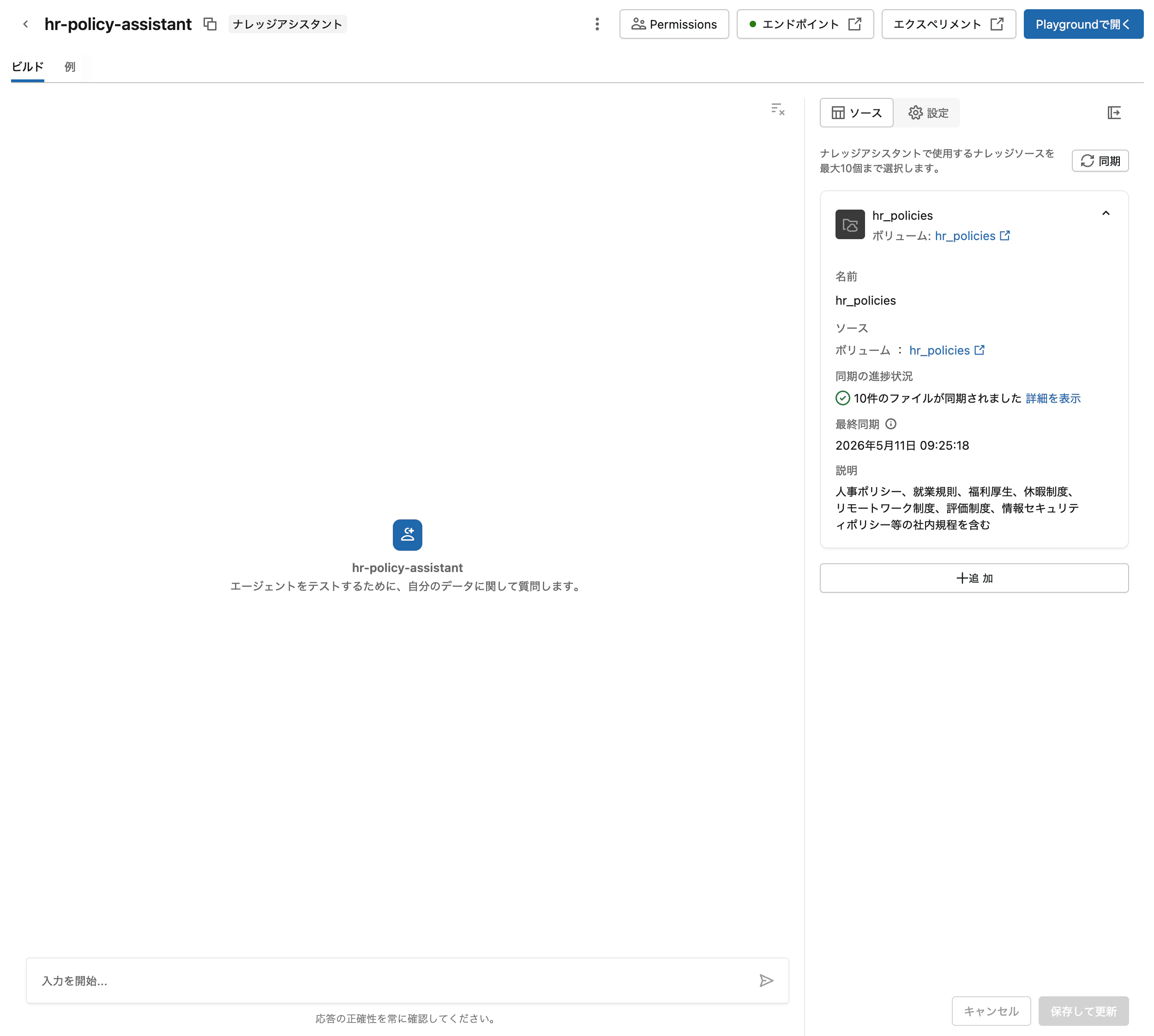
ステップ 2: エージェントをテストする
エージェントの準備ができたら、ビルド タブから直接チャットでテストできます。AI Playground でも同じエンドポイントにアクセスできます。
サンプル質問
人事ポリシーを題材にする場合、以下のような質問が動作確認に向いています。具体的な数値・条件が含まれる質問、表形式から情報を引き出す質問、規程外の質問を組み合わせることで、エージェントの引用精度と振る舞いを評価できます。
- 「リモートワーク中の在宅勤務手当はいくらですか?」
- 「有給休暇は入社からどのくらいで何日付与されますか?」
- 「育児休業中の社会保険料はどうなりますか?」
- 「東京23区での出張の宿泊費上限はいくらですか?」
- 「フレックスタイムのコアタイムは何時から何時までですか?」
- 「資格取得を支援する制度はありますか?」
- 「退職時に返却するものを教えてください」
- 「会社で副業はできますか?」 (規程に明記されていない質問の例)
回答の確認ポイントは以下です。
- 思考を表示: エージェントの推論プロセスを確認
- トレースの表示: 完全な MLflow トレースを確認 (UI 上で品質ラベルも付けられる)
- ソースの表示: エージェントが参照したファイルを確認
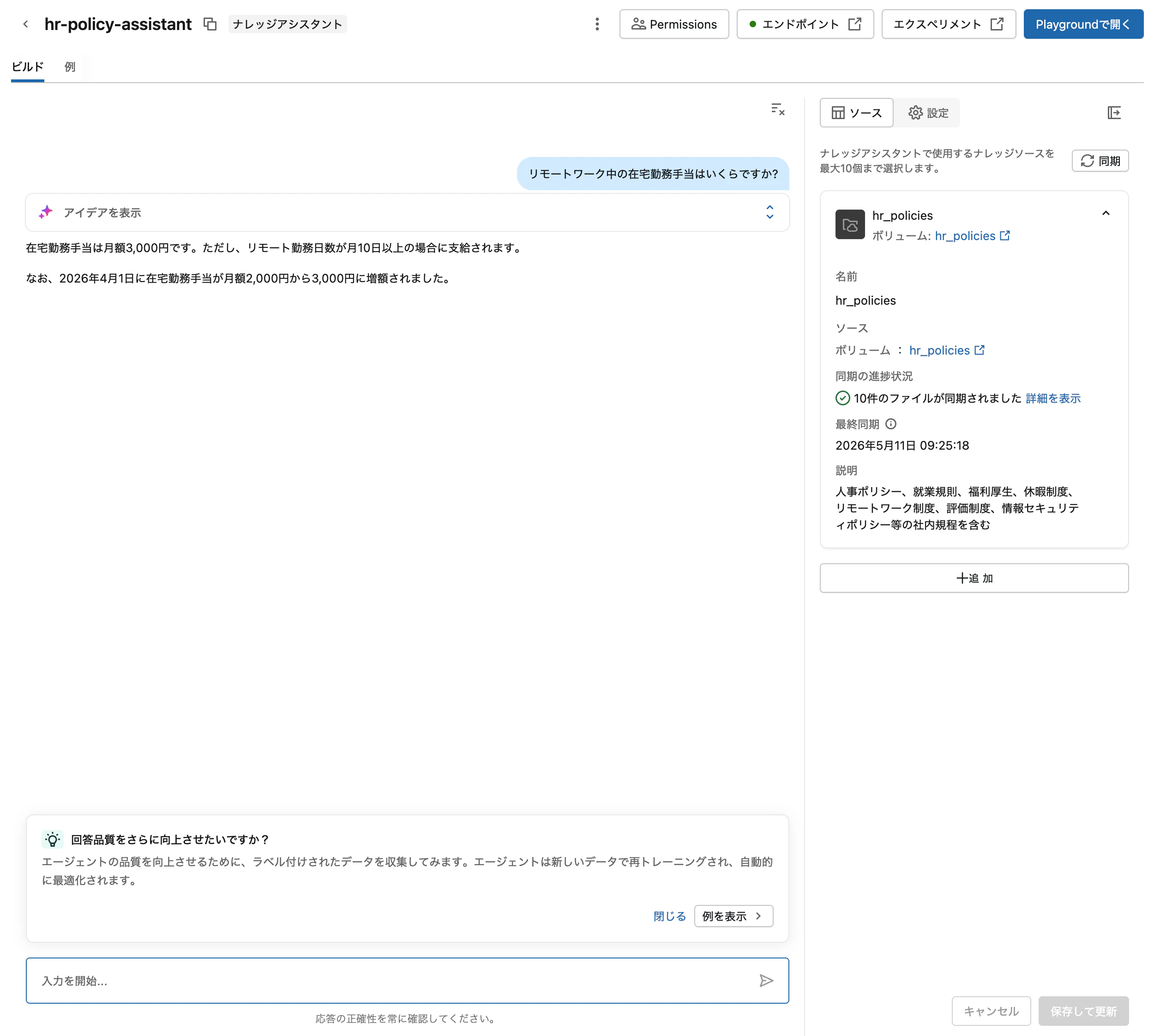
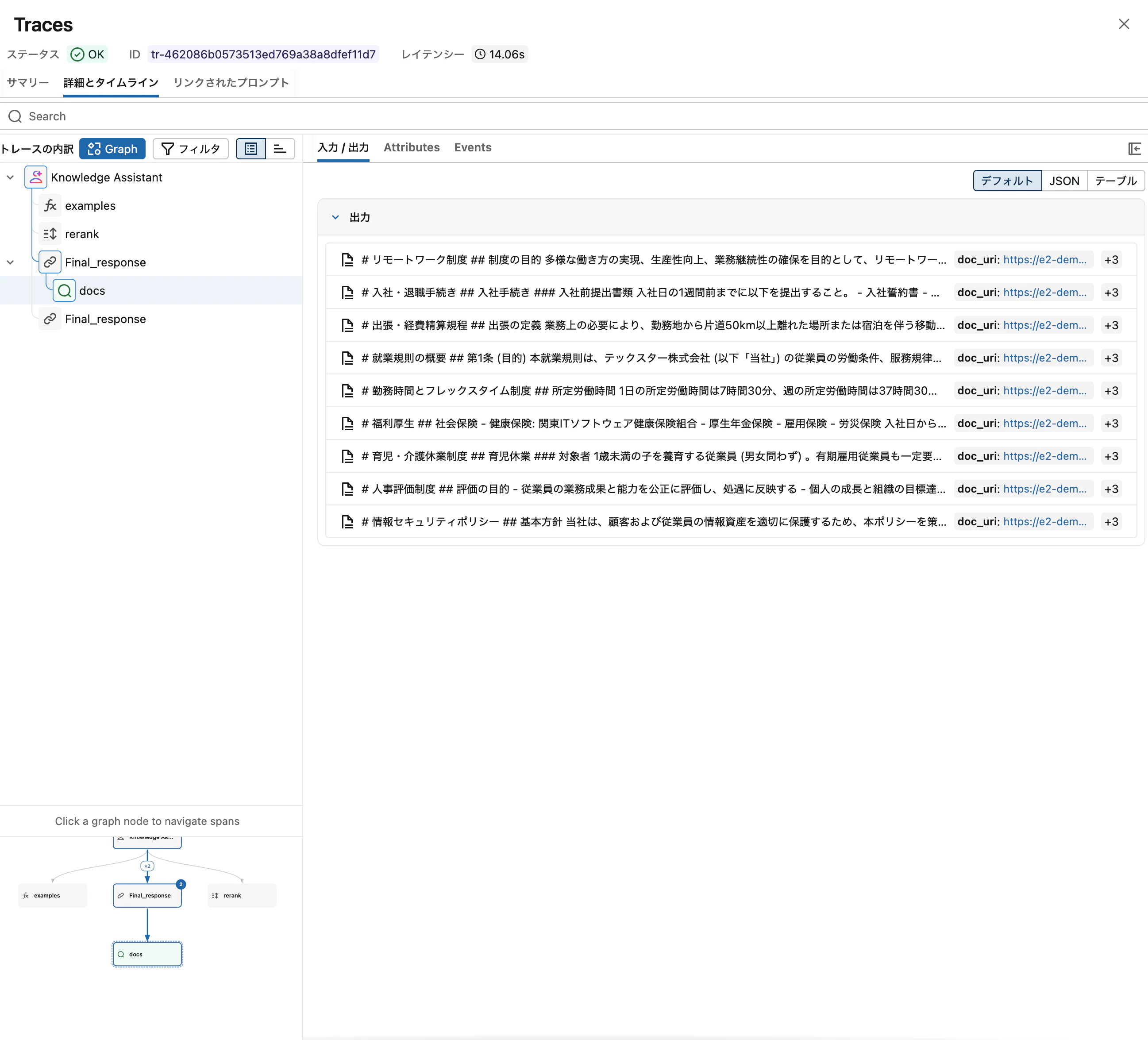
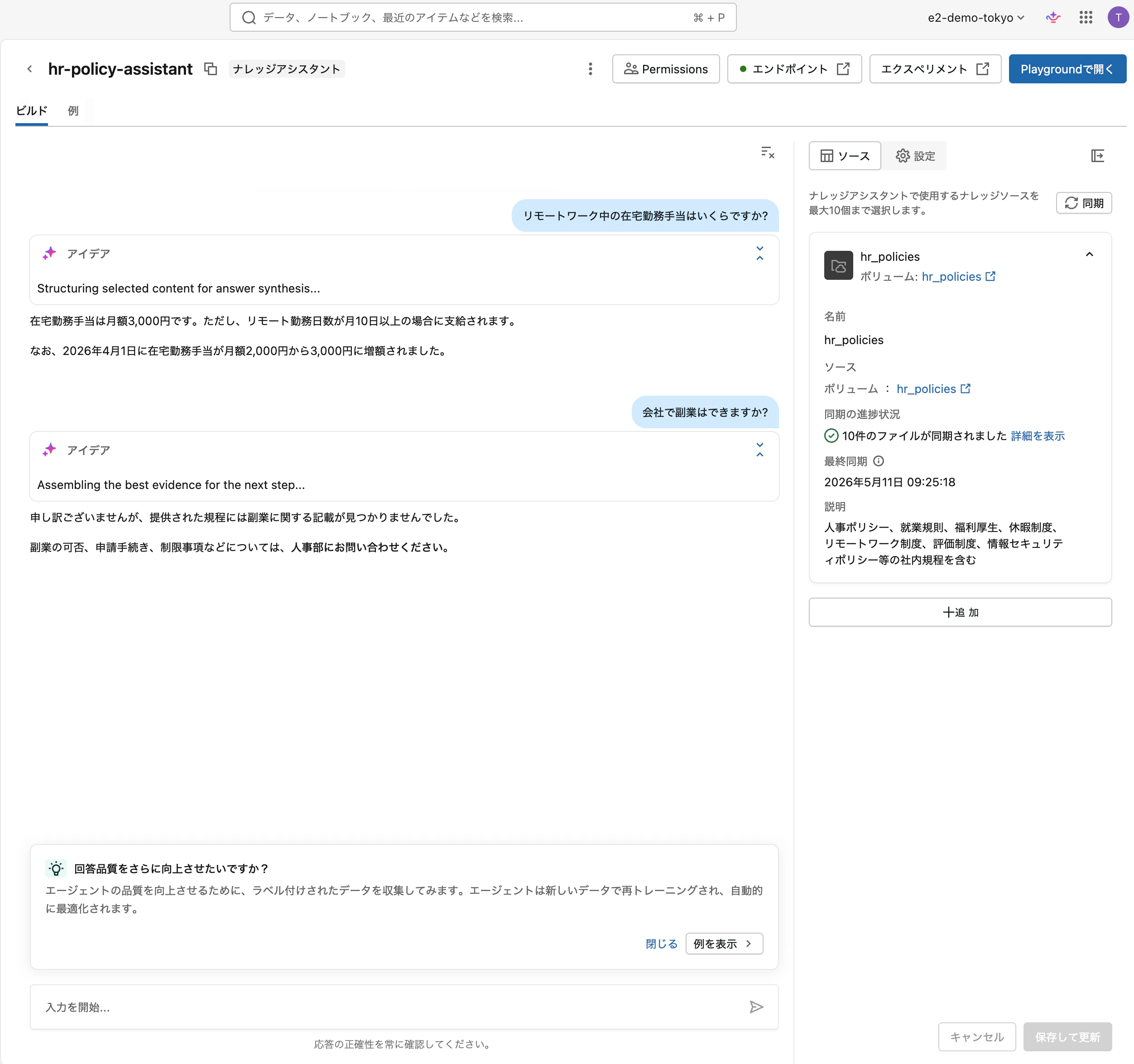
8番目のような規程に明記されていない質問に対して、エージェントが推測で答えるのか、指示通り「人事部にお問い合わせください」と返すのかは、指示 (instructions) フィールドの効果を見る重要なポイントです。
ステップ 3: 品質を向上させる
エージェントの回答品質に満足できない場合、例 タブから自然言語のフィードバックを追加して挙動を調整できます。
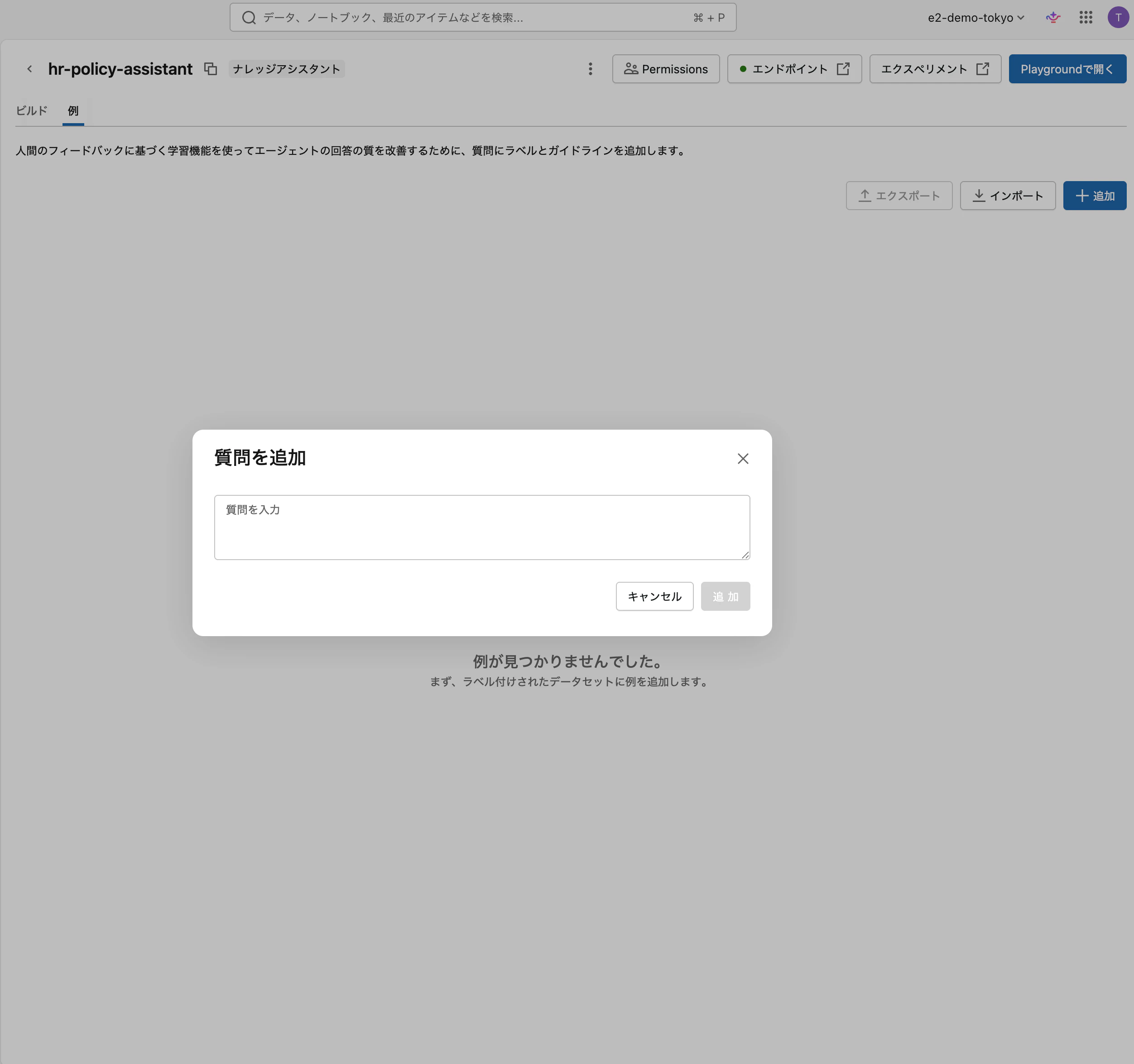
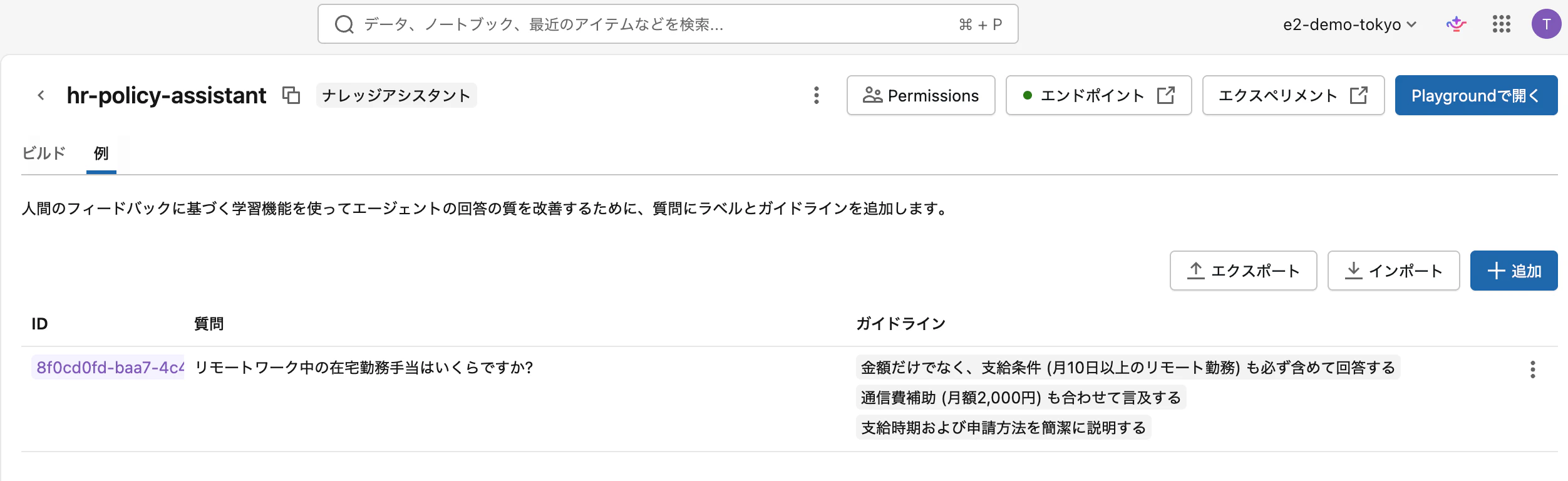
質問とガイドラインの追加
例 タブで + 追加 をクリックし、評価したい質問を入力します。
追加後、質問をクリックして ガイドライン を記述すると、エージェントの応答に反映されます。例えば「リモートワーク中の在宅勤務手当はいくらですか?」に対するガイドラインとして以下のように書けます。
- 金額だけでなく、支給条件 (月10日以上のリモート勤務) も必ず含めて回答する
- 通信費補助 (月額2,000円) も合わせて言及する
- 支給時期および申請方法を簡潔に説明する
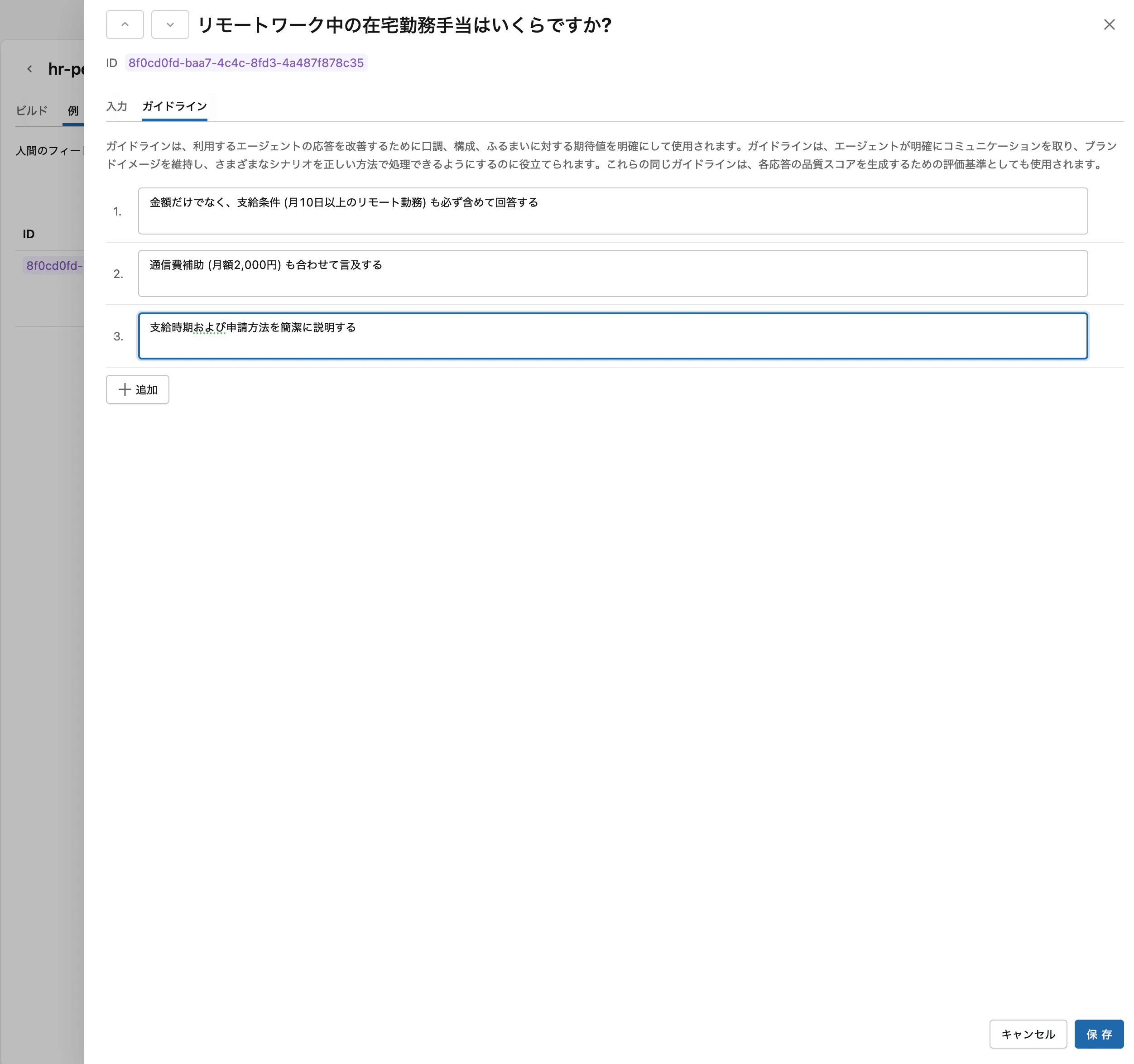
ガイドラインは保存後すぐに反映されます。
専門家からのフィードバック収集
エージェントの URL を人事部の専門家に共有して、ガイドラインを協力して整備することもできます。
- エージェント右上のケバブメニューから 権限の管理
- 専門家に CAN_MANAGE 権限を付与
- エージェント設定ページの URL を共有
ラベル付きデータのインポート・エクスポート
既存の FAQ データを Unity Catalog テーブルから一括インポートすることもできます。テーブルのスキーマは以下です。
-
eval_id:string -
request:string -
guidelines:array<string> -
metadata:string -
tags:string
逆に、整備したラベル付きデータを Unity Catalog テーブルにエクスポートし、別のエージェントの初期データとして使い回すこともできます。
エンドポイントへの問い合わせ
エージェント作成完了後、右上にデプロイされたモデルサービングエンドポイント名が表示されます。Playground で開く から コードを取得 で REST API および Python SDK の呼び出し例を確認できます。
Python からの呼び出し例
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="ka-techstar-hr-assistant-endpoint", # 実際のエンドポイント名に置き換え
messages=[
ChatMessage(
role=ChatMessageRole.USER,
content="リモートワーク中の在宅勤務手当はいくらですか?",
)
],
)
print(response.choices[0].message.content)
curl からの呼び出し例
curl -X POST \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "リモートワーク中の在宅勤務手当はいくらですか?"}
]
}' \
https://${DATABRICKS_HOST}/serving-endpoints/ka-techstar-hr-assistant-endpoint/invocations
Databricks Apps、Multi-Agent Supervisor、外部アプリケーションのいずれからも同じエンドポイントを呼び出せます。
権限管理
デフォルトでは、作成者とワークスペース管理者のみがエージェントにアクセスできます。他のユーザーに利用してもらうには明示的に権限を付与します。
エージェント右上のケバブメニュー → 権限の管理 から以下を設定できます。
- CAN_MANAGE: エージェント設定の編集、品質改善、権限管理が可能
- CAN_QUERY: AI Playground および API 経由でエージェントエンドポイントをクエリ可能 (エージェント設定画面の閲覧・編集は不可)
なお、ナレッジソースの同期は作成者のみ が実行できます。CAN_MANAGE 権限を持っていても、別のユーザーは同期ボタンを押せない点に注意してください。本番運用時は、ボリュームへのファイル追加と同期の責任者を明確にしておく必要があります。
ナレッジアシスタントを評価する
公式ドキュメントから 評価用ノートブック が提供されています。キュレーションされた評価データセットとカスタムスコアラーを使った評価方法のサンプルが含まれます。
本記事の人事ポリシーの場合、以下のような評価データセットを用意するのが現実的です。
- 想定質問 (人事部に実際に寄せられる質問のリスト)
- 期待される回答の要点 (金額、条件、手続き等の含まれるべきキーワード)
- 引用されるべきポリシードキュメント
MLflow 3 の make_judge() を使ったカスタムジャッジで「回答に金額が含まれているか」「引用ソースが正しいドキュメントか」を自動評価できます。
制限事項
公式ドキュメントに記載されている制限を整理しておきます。日本リージョン対応に関する情報は前述の独立セクションを参照してください。
- 英語のみがサポートされています
- 50MB を超えるファイルは取り込み時にスキップされる
- ファイル名がアンダースコアまたはピリオドで始まるファイルはスキップされる
- Unity Catalog テーブルは直接サポートされない
- Vector Search インデックスは
databricks-gte-large-enを埋め込みモデルとするもののみサポート -
databricks-gte-large-enエンドポイントの AI ガードレール・レート制限を無効化する必要がある - トレース機能のためには MLflow (Beta) の本番運用モニタリングを有効化する必要がある
- ナレッジソースの同期はエージェント作成者のみが実行可能
既存の RAG パイプラインとの使い分け
Knowledge Assistant を使うべきケース、自前で RAG を組むべきケースは以下のように整理できます。
Knowledge Assistant が向いているケース
- 既存ドキュメント (PDF、Word、PowerPoint、Markdown、テキスト) を素早くチャットボット化したい
- RAG パイプラインの構築・運用に工数をかけたくない
- 専門家からの自然言語フィードバックで継続的に品質改善したい
- 引用付きの回答が必須要件
自前 RAG が向いているケース
- 検索ロジックを細かく制御したい (ハイブリッド検索、独自リランキング等)
- ドキュメント以外のデータソース (DB、API) と組み合わせたい
- 埋め込みモデルを
databricks-gte-large-en以外で使いたい (例: 日本語特化のdatabricks-qwen3-embedding-0-6b) - 検索結果の前処理・後処理にカスタムロジックを挟みたい
日本語ドキュメントを扱う場合の意思決定フローは「日本での利用に関する重要な注意点」を参照してください。本記事のように Markdown 形式の社内ドキュメントであれば、まず Knowledge Assistant の UC ファイル方式で試し、評価データで精度を確認してから判断するアプローチが現実的です。
まとめ
Agent Bricks: Knowledge Assistant は、ドキュメント Q&A チャットボットをノーコードで構築するためのマネージドサービスです。本記事では人事ポリシーをテーマにしたハンズオン手順と、日本での利用に関する制限を解説しました。
要点は以下です。
- UC ボリュームに置いたドキュメントまたは Vector Search インデックスをナレッジソースとして指定するだけで構築可能
- 自然言語のガイドラインと専門家フィードバックで継続的に品質改善できる
- 作成されたエンドポイントは Apps、Multi-Agent Supervisor、外部アプリケーションから呼び出せる
- 東京リージョン (
ap-northeast-1) ではクロスジオルーティングの有効化で利用可能、対応状況は機能リージョン対応表を参照 - 公式の制限事項としては「英語のみがサポートされています」と明記されている一方、日本語対応の精度改善は継続的に進められており、日本語ドキュメントでも実用的な回答品質が得られるケースが増えている
- 本記事のハンズオンは東京リージョンのワークスペースで日本語ドキュメントの動作を確認しており、指示フィールドや例タブでのガイドライン整備が品質改善に有効
- 高精度・厳密な引用が必要なユースケースでは、Mosaic AI Agent Framework + 日本語対応埋め込みモデル (
databricks-qwen3-embedding-0-6b等) の自前 RAG も選択肢
参考リンク
- Agent Bricks: Knowledge Assistant 公式ドキュメント (日本語)
- Databricks 機能リージョン対応表 (AI エージェント機能)
- Databricks Geos: データ所在地とクロスジオ処理
- Agent Bricks 概要
- Instructed Retriever ブログ記事
- 評価用サンプルノートブック