マーケットプレイスを眺めていたらFoursquareのデータセットを見つけました。十数年前にこちらのサービスの開発・運営に携わっていたこともあり、当時はFoursquareにも注目して、結構使っていました。

無料のサンプルなのでこちらを試してみます。
データへのアクセスを取得
カタログを指定してデータにアクセスできるようにします。

データにアクセスできるようになりました。


サンプルノートブックもあるのでインポートします。
ノートブックのウォークスルー
h3を使うのでライブラリをインストールします。ちなみに、Databricksではネイティブでh3の機能をサポートしていますが今回はサンプルノートブックに従います。
%pip install h3
import pyspark.sql.functions as F
import h3
PySparkでテーブルを表示
テーブルを読み込みます。カタログ名は上の手順で設定したものを指定します。こちらはPySparkの例。
places_nyc = spark.sql("SELECT * FROM `taka_foursquare_places_free_new_york_city_sample`.`quickstart_schema`.`places_us_nyc`")
display(places_nyc)

SQLでテーブルを表示
SQLの例です。
%sql
SELECT * FROM `taka_foursquare_places_free_new_york_city_sample`.`quickstart_schema`.`places_us_nyc`;
同じ結果が返ってきます。

New York DMA(Direct Marketing Area)におけるすべてのスターバックスの位置を教えて (PySpark)
# NYCのサンプルデータ
display(
places_nyc.filter(
(F.array_contains(F.col("fsq_chain_name"), "Starbucks"))
))

New York DMA(Direct Marketing Area)におけるすべてのスターバックスの位置を教えて (SQL)
これもSQLの例ですが、PySparkと同じ結果が返ってきます。
%sql
SELECT * FROM `taka_foursquare_places_free_new_york_city_sample`.`quickstart_schema`.`places_us_nyc` WHERE ARRAY_CONTAINS(fsq_chain_name, 'Starbucks')

ZIPコード10010のエリアにはいくつのカフェがある?(PySpark)
places_nyc.filter(
(F.arrays_overlap(F.col("fsq_category_ids"), F.array([F.lit(id) for id in range(10032, 10037)]))) & # Dining and Drinking > Cafes, Coffee, and Tea Houses
(F.col("postcode") == '10010'))\
.count()
28
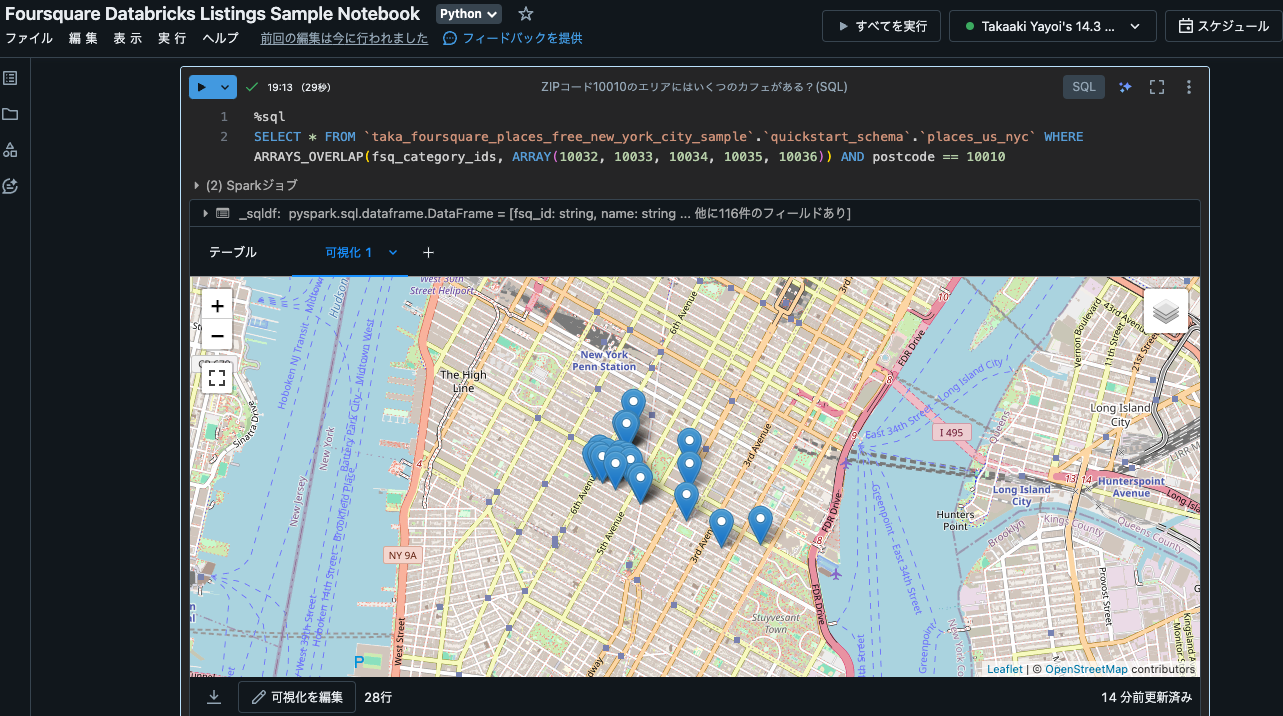
ZIPコード10010のエリアにはいくつのカフェがある?(SQL)
%sql
SELECT * FROM `taka_foursquare_places_free_new_york_city_sample`.`quickstart_schema`.`places_us_nyc` WHERE ARRAYS_OVERLAP(fsq_category_ids, ARRAY(10032, 10033, 10034, 10035, 10036)) AND postcode == 10010

なお、結果を表示した状態で可視化を追加するとこれらのカフェを地図上にプロットすることができます。

ノートブックにはこれ以外のサンプルコードも入っているのですが、それらを試すには有料のデータが必要でした。東京で人気のラーメン店はどこ? みたいな質問も入っています。試してみたい…。