Building Custom Code Agents on Databricks 2026 Edition | by AI on Databricks | Apr, 2026 | Mediumの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
ノートブックとプロンプトから、ツール、メモリー、評価、デプロイメントを含むリアルなエージェントシステムへ。
著者: Brian Law, Senior Specialist Solutions Architect
序文
Claude Sonnet 4.6やChatGPT 5.4 のような大規模言語モデルはさらにパワフルになっていますが、多くの企業においては依然としてモデル周辺にカスタムのラッパーを構築する必要があります。多くの場合エージェントと呼ばれるものにおいては、これらのラッパーは検証されたプロンプト、ツール、スキルを組み合わせます。これらは、組織の顧客やスタッフにとってモデルが価値あるもになるために、モデルのコンテキストを強化し、必要とされるビジネスシステムと連携するためには重要なものとなります。
最初にエージェントを構成するものを確認しましょう
それでは、エージェントのキーとなるコンポーネントはなんでしょうか?我々はこれらを大まかに3つのカテゴリーに分類することができます: プロンプト、コネクションとロジックです。これらがどこにフィットして、どのように動作するのかを説明するために、通信や金融機関で見かけるであろう顧客向けカスタマーサービスbotを例に取ります。
モデルとやり取りをするために、我々は基本的にはモデルと会話するか、プロンプトを与えます。モデルが推論できるように、背景の事実やロジックの全てを提供することで、モデルは複雑になる場合があります。複雑なビジネスワークフローでは、一つのプロンプトでは多くの場合不十分で、複数のプロンプトを必要とすることになります。
カスタマーサービスエージェントを見てみましょう、このエージェントは顧客からのリクエストのトリアージの助けとなり、シンプルなアカウントリクエストに対するアクションや、トリアージのために適切なチームにルーティングします。このため、最初のステップは顧客が既存の顧客かどうかを判断することになるでしょう。
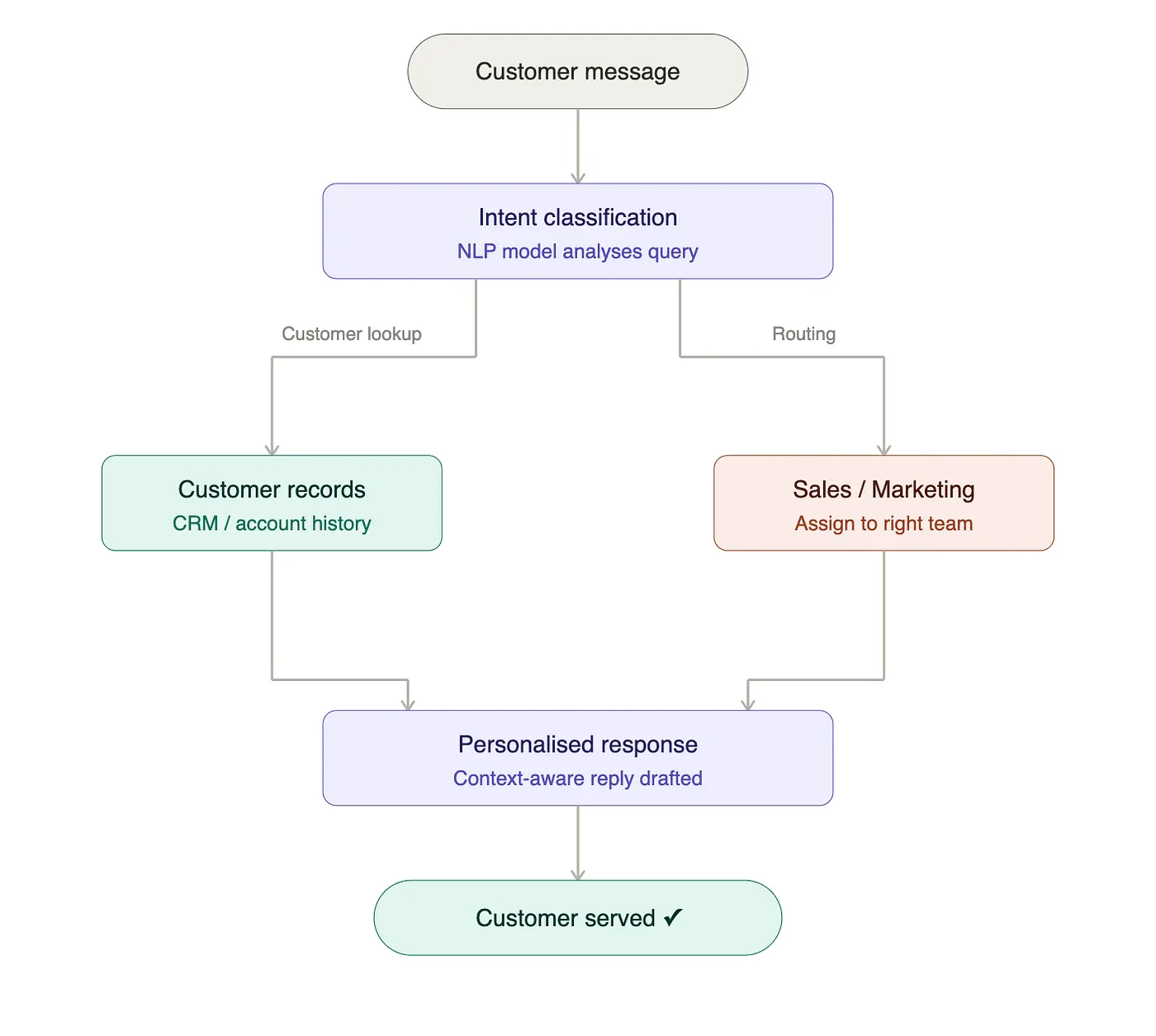
顧客の意図に応じて、パーソナライズされたレスポンスを返却する前に様々なフォローアップステップを必要とします。紫のボックスは異なるプロンプトを表現します。このフローのOKストレーションには、通常はCrewAI、PydanticAI、LanggraphやOpenAI / Anthropic model SDKのようなフレームワークを用いた何かしらのPythonコードを必要とします。フレームワークは、様々なステップをフローに繋ぎ合わせる助けとなり、外部システムとの連携を管理する役に立つので、フレームワークを用いることが一般的となっています。
我々の例では、顧客レコードを検索する必要があるため、ここでConnectivity(コネクティビティ)の要素が入ってきます。ソフトウェアに接続する一般的な手法がAPIであるのと同じように、Model Context Protocol (MCP)は、外部システムとAIエージェントの連携における標準的な手法になっています。
これで、上述のフローはより大規模なシステムの一部となります。完全なカスタマーサービスアプリケーションは以下のようなフローになることでしょう:

図を見ると、意図をさらに改善したり、顧客の問い合わせの理由を明確にするために、フォローアップメッセージがあることがわかります。顧客がフォローアップを送信した際、システムには会話の過去のすべてのコンテキストが保持されていることが期待されます。しかし、モデルは通常この「メモリー」を持っていないため、これを是正するには、メモリーモジュールとなる「データベース」を追加のコンポーネントとして我々のAIエージェントに追加する必要があります。
それでは、現時点で我々のAIエージェントは技術的に何から構成されているのでしょうか?メッセージを処理する基盤モデルがあります。到着するメッセージは、我々のCRMに検索を行うことができるロジックレイヤーによって処理され、メモリーを提供する自身のデータベースによって下支えされています。ロジックレイヤーは、フロントエンドに対するAPIを通じて接続されるアプリケーション、あるいはフロントエンドコードの一部として存在するモジュールとして機能します。
これで、我々の初めてのAIエージェントを概念的に構築したことになります。
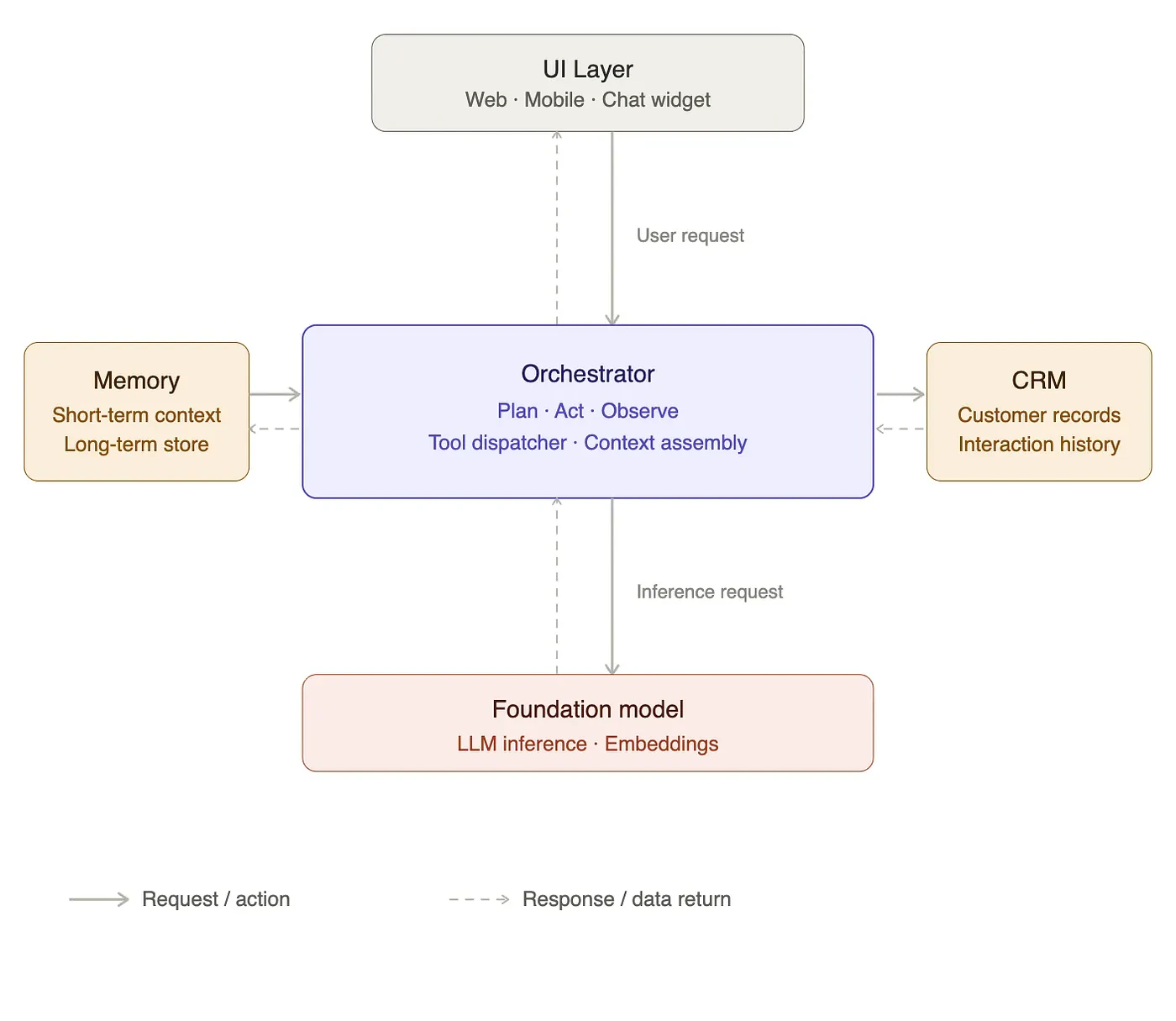
大規模エージェント管理
私がお見せしたものは複雑に見えるかもしれませんが、これは単なる短い単一のPythonスクリプトです。ここでの問題は、通常我々は一つのエージェントを作って終わりにしないということです。様々なビジネスプロセスを自動化するために構築したい数多くのエージェントが存在することになるため、それらを監視、統治できるようにしておく必要があります。
エージェントは、ビジネスエコシステムに大量のエントロピーを追加します。これらは、クエリーに対して常に同じ作法で回答するわけではなく、追加の句読点ですらレスポンスを変化させることがあります。人間のオペレーターのように、プロンプトインジェクションを通じたソーシャルエンジニアリングの被害を受けることがあり、プライベートデータの公開や、予期しないアクションの実行につながることがあり得ます。
このため、エージェントのデプロイメントを拡大しようとした際には、それらを監査するための方法、自身のアクションを統治する方法、フローで異なるロジックが起動されるのかを理解する方法を必要とします。それでは、我々はそれをどのようにして、「ベストプラクティス」な方法で達成できるのでしょうか?
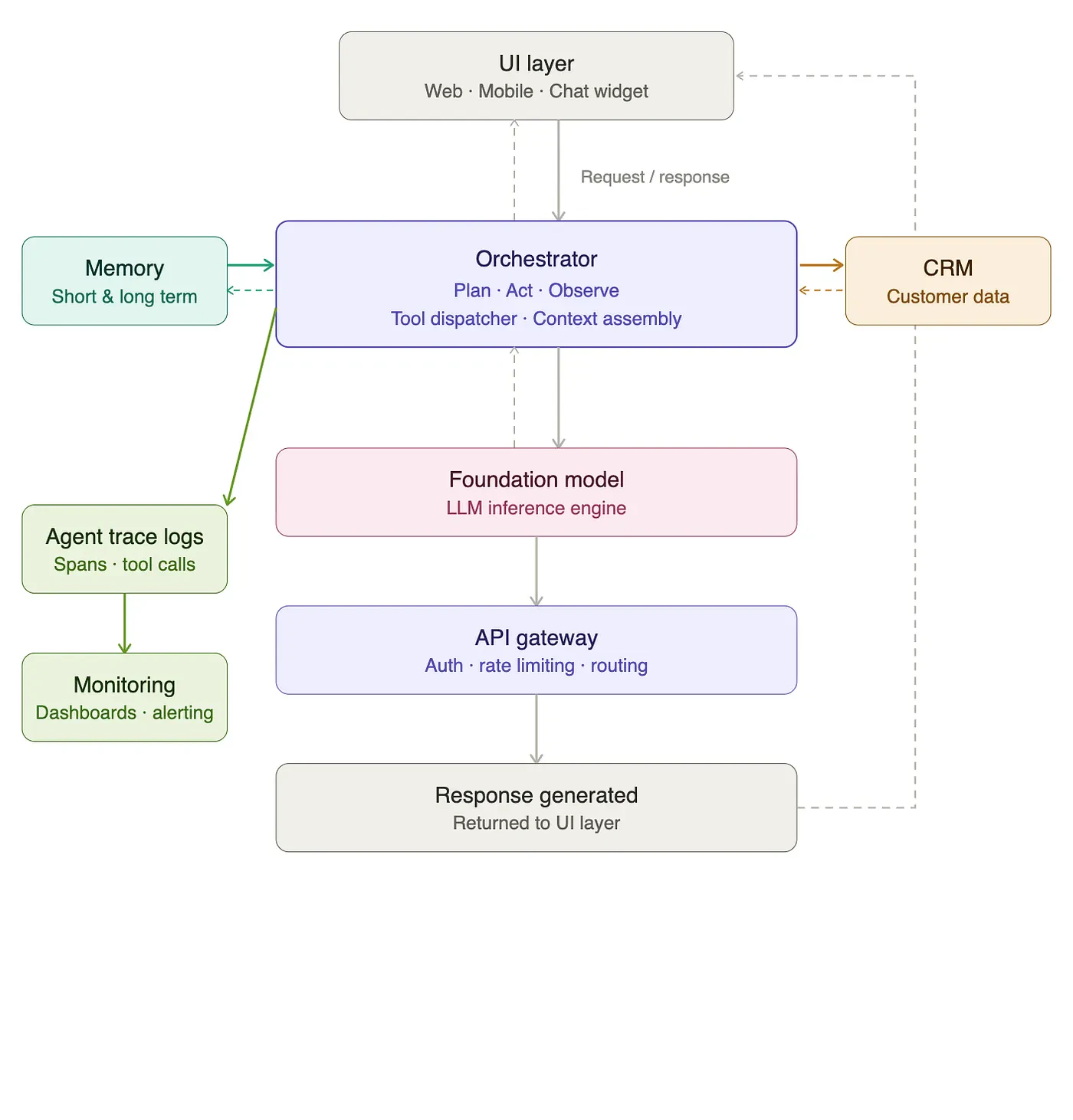
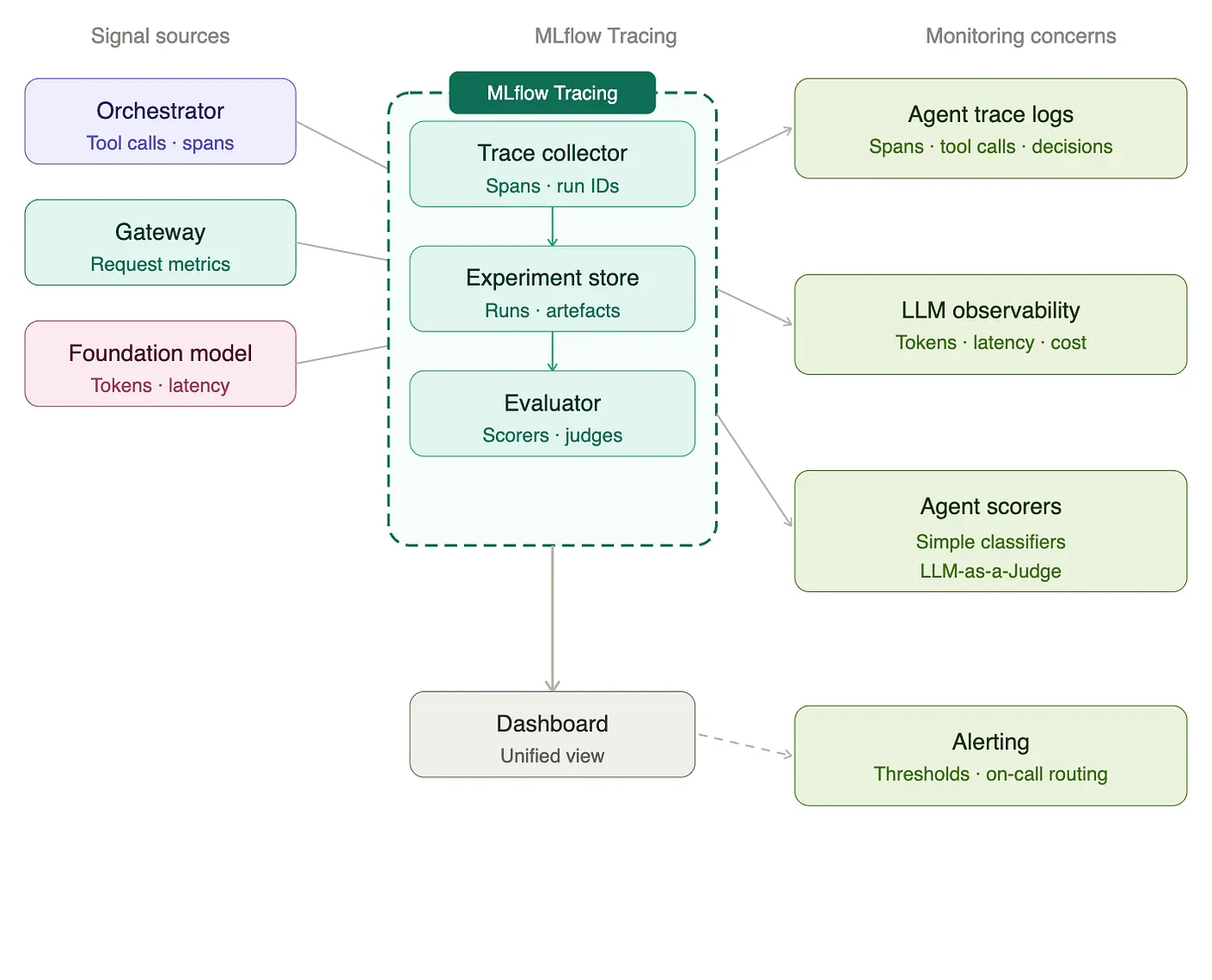
我々の技術的アーキテクチャに追加したキーとなるコンポーネントは、ゲートウェイ、トレースログ、モニタリングコンポーネントです。ゲートウェイからスタートしましょう。我々の現行の環境では、基盤モデルはより新しいモデルによって進化し、それらが行えるタスクや曖昧性への対応に関して、多くの場合ステップの変更を追加します。すぐにモデルを変更できる能力で、我々のエージェントをより柔軟にするためには、ゲートウェイを追加することが一般的です。このプロキシーサービスは、APIインタフェースの標準化の助けとなり、レート制限やフェイルオーバーの際のルーティング、管理者向けモニタリングダッシュボードのような機能を提供します。
次にトレースログです。上で見たように、オーケストレーションロジックには多くのステップが含まれることがあります。トレースログは、ここのステップの入力、出力をレイテンシーのような技術的パフォーマンス情報を記録します。これらのログは、エージェントがどのように動作しているのかを理解する際に重要なものとなります。通常、トレースログは品質のためにレスポンスを評価できるモニタリングツールによって処理され、以上を警告し、エージェントのパターンを特定する助けとなります。
Databricksでの構築
これで、エージェントと本番運用におけるキーコンポーネントを理解したことになりましたので、イケてる、信頼できるエージェントを構築する助けになるように、どのようにDatabricks Agent Bricksプラットフォームを活用できるのかを見てみましょう。
Databricksにおいては、AIエージェントの開発、デプロイ、監視のための完全なツールスイートを提供しています。コアコンポーネントからスタートするのであれば、REST APIだけでなくUIでホスティングできるDatabricks AppsにデプロイされるPythonコードベースがオーケストレーターとなります。

次に、基盤モデルを追加する必要があります。Databricksを用いることで、OpenAI、Anthropic、Googleからお好きなすべてのトップモデルにアクセスすることができ、これらはすべてDatabricks Model Servingで稼働しています。この上にガバナンスレイヤーを追加するために、Databricksではレート制限、コスト追跡、フェイルオーバーのような重要な機能を追加するAI Gatewayをホストしています。このゲートウェイは、接続するための機能を常に提供しており、外部システムで動作しているモデルの管理の助けにもなります。
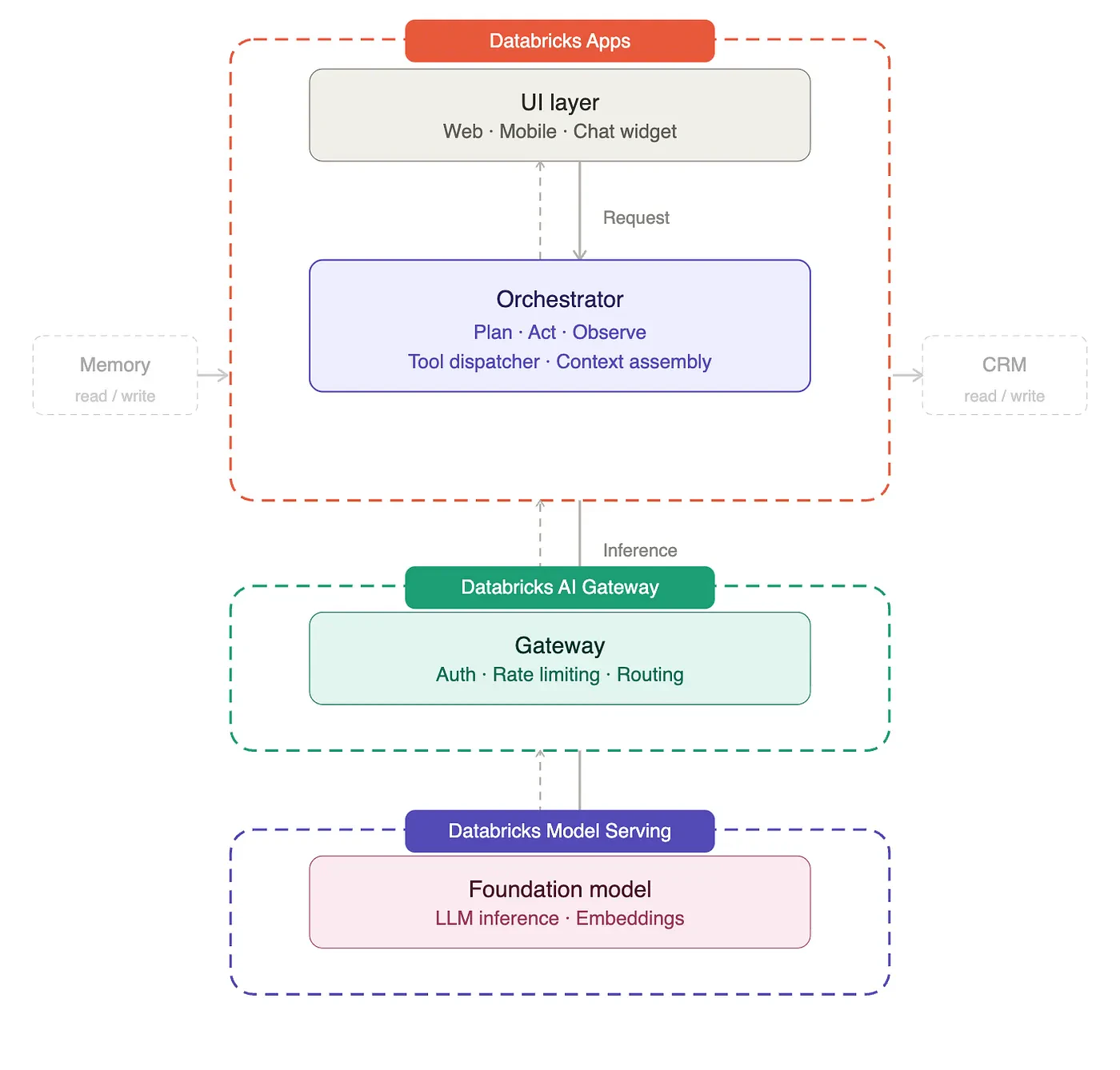
コアコンポーネントの最後のピースはメモリーです。このために、我々にはDatabricks Lakebaseがあります: レイクハウスに完全にインテグレーションされ、オートスケールするpostgres互換のデータベースです。

ご存知の通り、有用なAIエージェントの構築においてコアとなるパーツはコネクティビティです。関連する多数の外部システムの管理は複雑となる場合があります。接続するシステムに応じて、いくつかの共通するパターンが存在します。Databricksサービスに対しては、AIエージェントがデータや他のエージェントに接続できるようにするビルトインのMCPサーバーがあります。外部システムに対しては、Databricks Unity CatalogでMCPサーバーに対するコネクションをセットアップすることができます。今日の議論のスコープ外ではありますが、Databricks Appsでは、必要性が出てきた際には完全カスタムのMCPサーバーのホスティングもサポートしています。
これで、エージェントがセットアップされ動作するようになりましたので、それらを統治、管理し、エンドユーザーがどのように我々のエージェントとやり取りをし、活用しているのかを理解する必要があります。このために、我々にはMLflowエコシステムがあります。MLflowでAIの管理を行う際、すべてはトレースからスタートします。
Open Telemetryトレースは、オーケストレーターを通じてリクエストがどのように処理されるのか、どのようにプロンプトが送信され、レスポンスを受信するのかをMLflowから追跡するための業界標準です。これらのトレースから、我々は2つのことを行うことができます。トークン使用量のような標準的なパフォーマンスメトリクスの監視や、レイテンシーの理解です。また、直接トレースを参照するか、MLflowを活用することで、ユーザーの挙動の理解、リクエストの分類、失敗パターンやエッジケースの特定を行うことができます。
ここまで見てきたように、クイックなPOCがクイックで簡単であったとしても、コンセプトから本番運用レベルの現実に移行するには、それなりの量のエンジニアリングが必要となります。次の記事では、コードに踏み込み、Databricksでご自身のコードベースのエージェントをどのように開発できるのかを見てみます。