はじめに
本記事では、Databricks Free Editionを使ったデータサイエンス講座の内容を解説します。4.5時間の講義資料です。
スライドはこちら。
デモや実習のリポジトリ。
アジェンダ
本講座は3つのパートで構成されています。
Part 1: ノートブックによるモデル開発実践 (90分)
- 機械学習とは何か
- scikit-learnによるモデル開発
- MLflowによる実験管理
- デモ: パイプライン構築
Part 2: MLOpsによる業務品質のモデル開発 (90分)
- なぜMLOpsが必要か
- 這う・歩く・走るアプローチ
- Unity Catalog / MLflow
- デモ: Model Registry
実践演習 (90分): scikit-learn+MLflowで機械学習ワークフロー
- データ準備と特徴量エンジニアリング
- パイプライン構築とモデル学習
- 実験管理と結果比較
- モデル登録とバッチ推論
イントロダクション
生成AIの時代にデータサイエンスを学ぶ意義
生成AIが台頭する現代においても、データサイエンスを学ぶ意義は大きいです。その理由は3つあります。
1. 問いを立てる力
AIは「答え」を出すことは得意ですが、「問い」を立てるのは人間の役割です。何を解くべきか?を定義できる人材が必要です。
2. データを見極める力
「Garbage In, Garbage Out」という言葉が示すように、ゴミを入れればゴミが出ます。データの品質を判断する力は自動化できません。
3. AIを制御する力
AIを使いこなすにはAIの仕組みを理解する必要があります。ブラックボックスのままでは適切な判断ができません。
データサイエンスを学ぶことは、AIを「使われる側」から「使いこなす側」になることを意味します。



Part 1: ノートブックによるモデル開発実践
機械学習とは何か
機械学習の定義
機械学習はデータサイエンスで用いられる、応用統計学とコンピューターサイエンスを組み合わせた技術です。
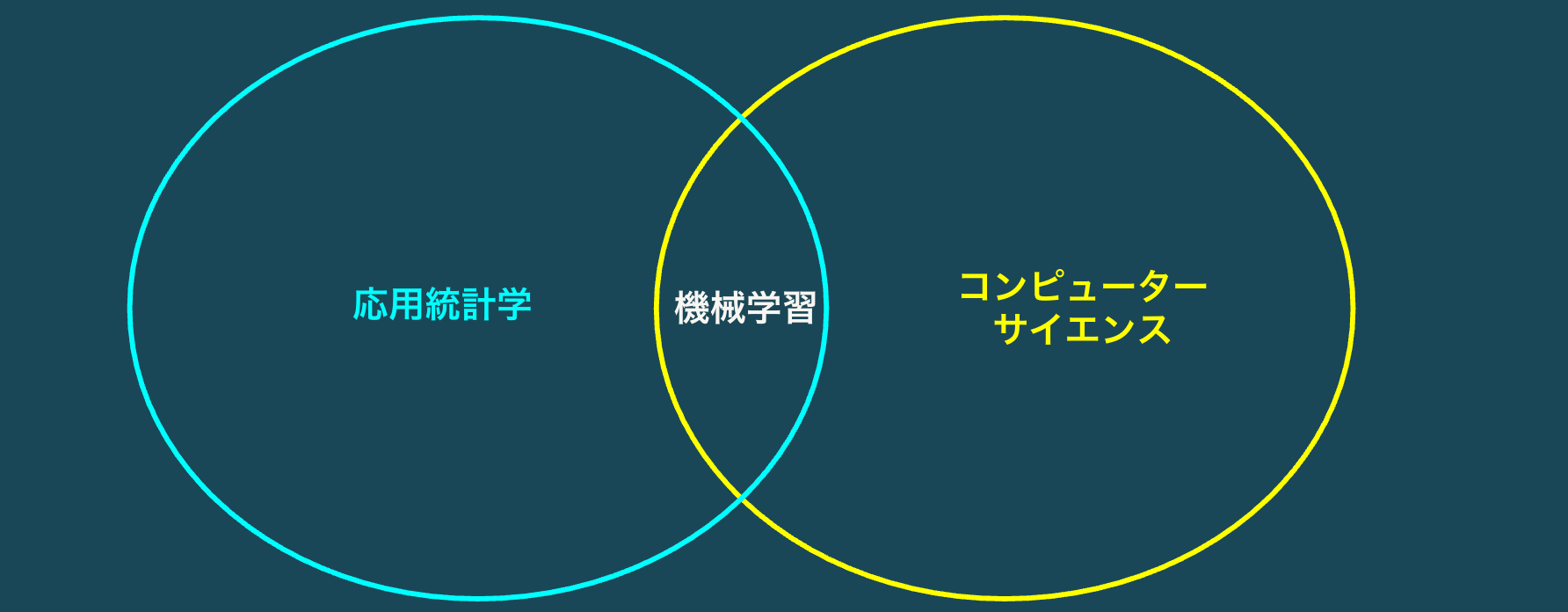
機械学習の種類
機械学習には大きく分けて3つの種類があります。
教師あり学習
正解データ(ラベル)を使って学習する手法です。以下のような問題に適用されます。
- 顧客の解約を予測する(分類)
- 住宅価格を予測する(回帰)
- スパムメールを検出する(分類)
教師なし学習
正解データなしでデータのパターンを発見する手法です。
- 購買行動に基づいて顧客をグルーピングする(クラスタリング)
- 症状に基づいて患者をグルーピングする
- 不正行為と思われるトランザクションを特定する(異常検知)
強化学習
試行錯誤を通じて最適な行動を学習する手法です。ゲームAIやロボット制御などに応用されています。


Databricksプラットフォーム概要
Databricks Free Editionとは
Databricks Free Editionは、無料でDatabricksの主要機能を試すことができるエディションです。以下の機能が利用できます。
- ノートブック環境
- Apache Spark
- Delta Lake
- MLflow
- Unity Catalog(一部機能)

scikit-learnによるモデル開発
scikit-learn概要
scikit-learnはPythonで最も広く使われている機械学習ライブラリです。以下の特徴があります。
- 豊富なアルゴリズム群
- Pipelineによる処理統合
- モデル学習と評価
- ハイパーパラメータ調整
MLワークフロー全体像
Databricksでの機械学習ワークフローは以下のステップで構成されます。
| Step | コンポーネント | 役割 |
|---|---|---|
| 1 | Delta Lake | データ読込 |
| 2 | Spark DataFrame | 前処理・変換 |
| 3 | .toPandas() | 変換 |
| 4 | scikit-learn | モデル学習 |
| 5 | MLflow | 記録・管理 |
このワークフローは3つの層で構成されています。
データ層 (Spark)
- 大規模データの効率的な読み込み
- 分散処理による前処理
- Delta Lakeによるデータ管理
- SQLによるデータ探索
ML層 (scikit-learn)
- 豊富なアルゴリズム群
- Pipelineによる処理統合
- モデル学習と評価
- ハイパーパラメータ調整
管理層 (MLflow)
- 実験の追跡と比較
- パラメータ・メトリクス記録
- モデルのバージョン管理
- Unity Catalog連携

パイプライン構築
scikit-learnのPipelineを使用すると、データの前処理からモデル学習までを一連の処理としてまとめることができます。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# パイプラインの構築
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', LogisticRegression())
])
# 学習
pipeline.fit(X_train, y_train)
# 予測
predictions = pipeline.predict(X_test)

MLflowによる実験管理
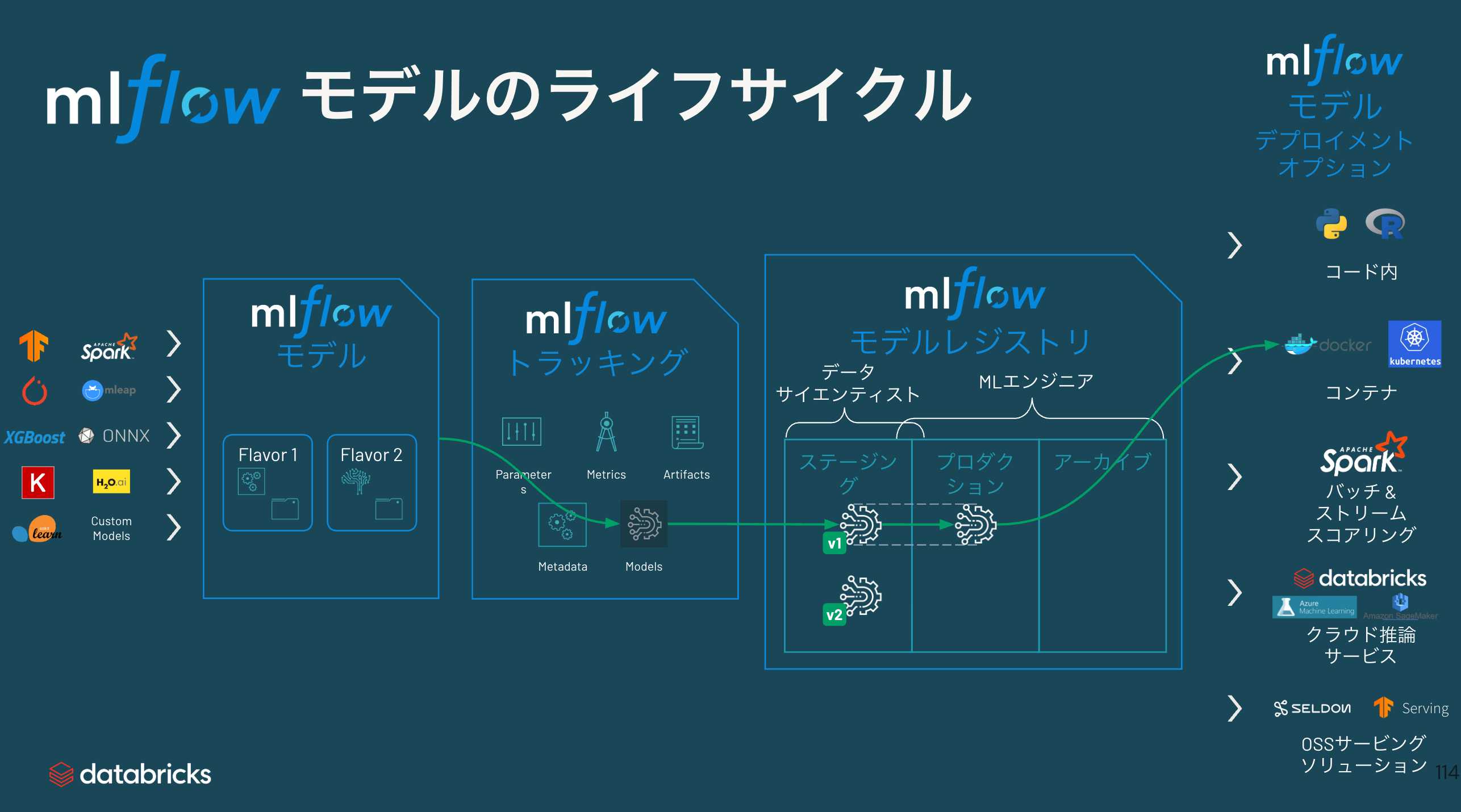
MLflow概要
MLflowは機械学習のライフサイクルを管理するためのオープンソースプラットフォームです。Databricksでは標準で統合されており、以下の機能を提供します。
- Tracking: 実験の記録と比較
- Models: モデルのパッケージングとデプロイ
- Model Registry: モデルのバージョン管理
- Projects: 再現可能なML実行環境

自動ロギング
MLflowのautolog機能を使用すると、学習時のパラメータやメトリクスが自動的に記録されます。
import mlflow
from sklearn.ensemble import RandomForestClassifier
# 自動ロギングを有効化
mlflow.sklearn.autolog()
# モデル学習(自動的にログが記録される)
with mlflow.start_run():
model = RandomForestClassifier(n_estimators=100, max_depth=5)
model.fit(X_train, y_train)

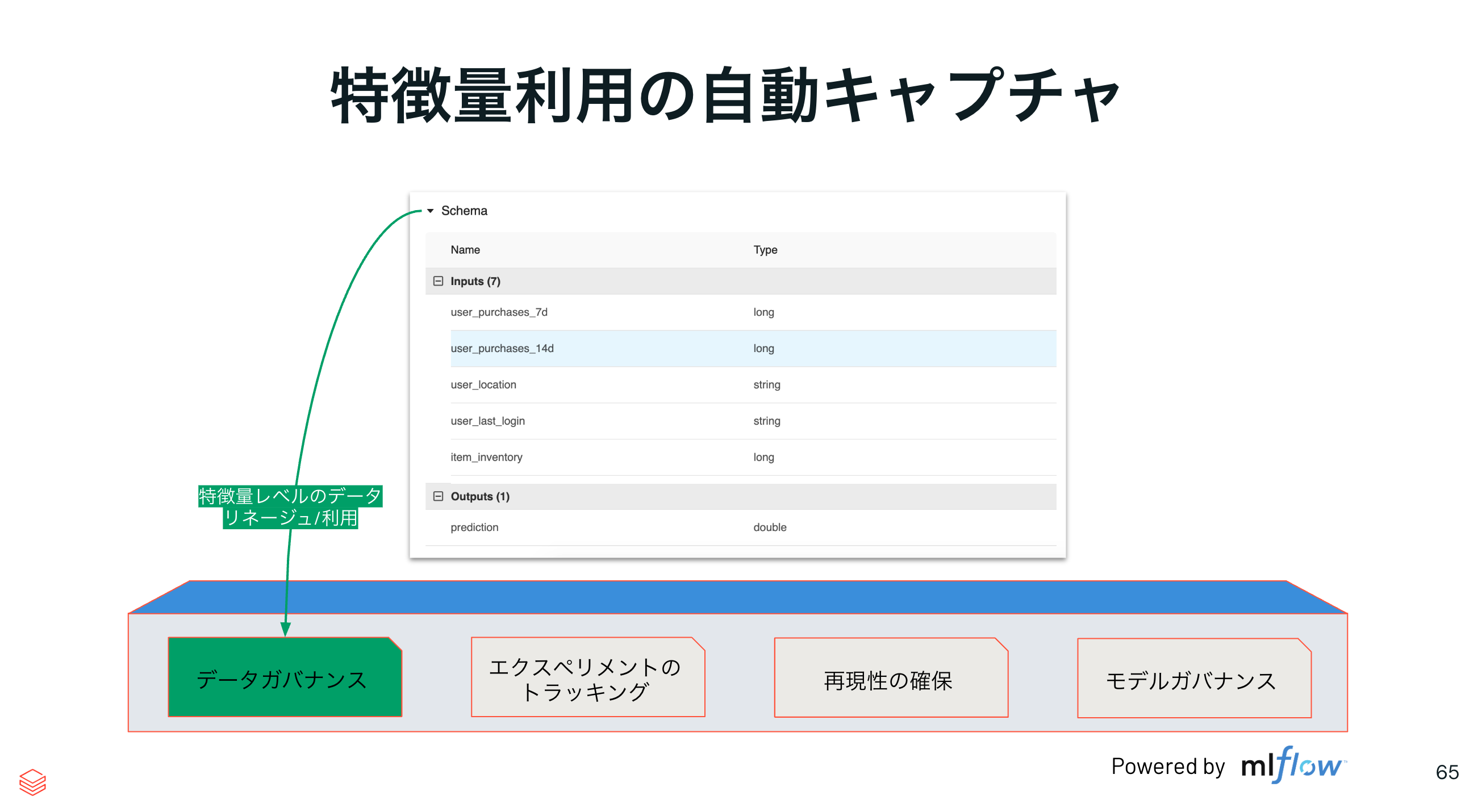
特徴量利用の自動キャプチャ
MLflowは学習に使用した特徴量の情報も自動的にキャプチャします。これにより以下のメリットがあります。
- データガバナンス: 特徴量レベルのデータリネージ/利用
- エクスペリメントのトラッキング
- 再現性の確保
- モデルガバナンス
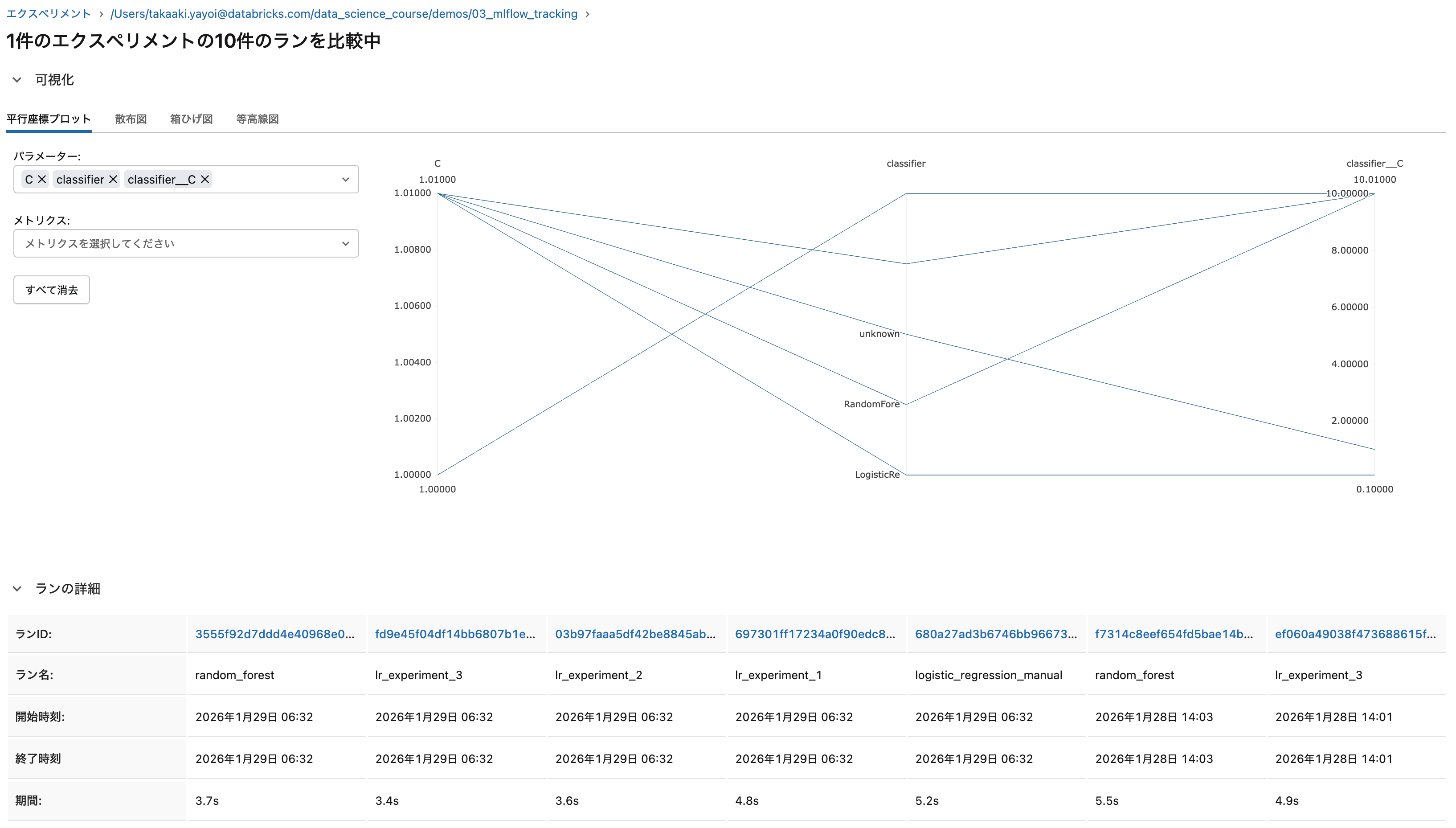
実験の比較
MLflow UIを使用して、複数の実験結果を比較することができます。
- パラメータの違い
- メトリクスの比較(精度、AUC、F1スコアなど)
- 学習曲線の可視化
Part 2: MLOpsによる業務品質のモデル開発
なぜMLOpsが必要か
機械学習システムの複雑さ
GoogleのNIPS 2015の論文「Hidden Technical Debt in Machine Learning Systems」で示されているように、実世界のMLシステムにおいてMLコードはほんの一部にすぎません。
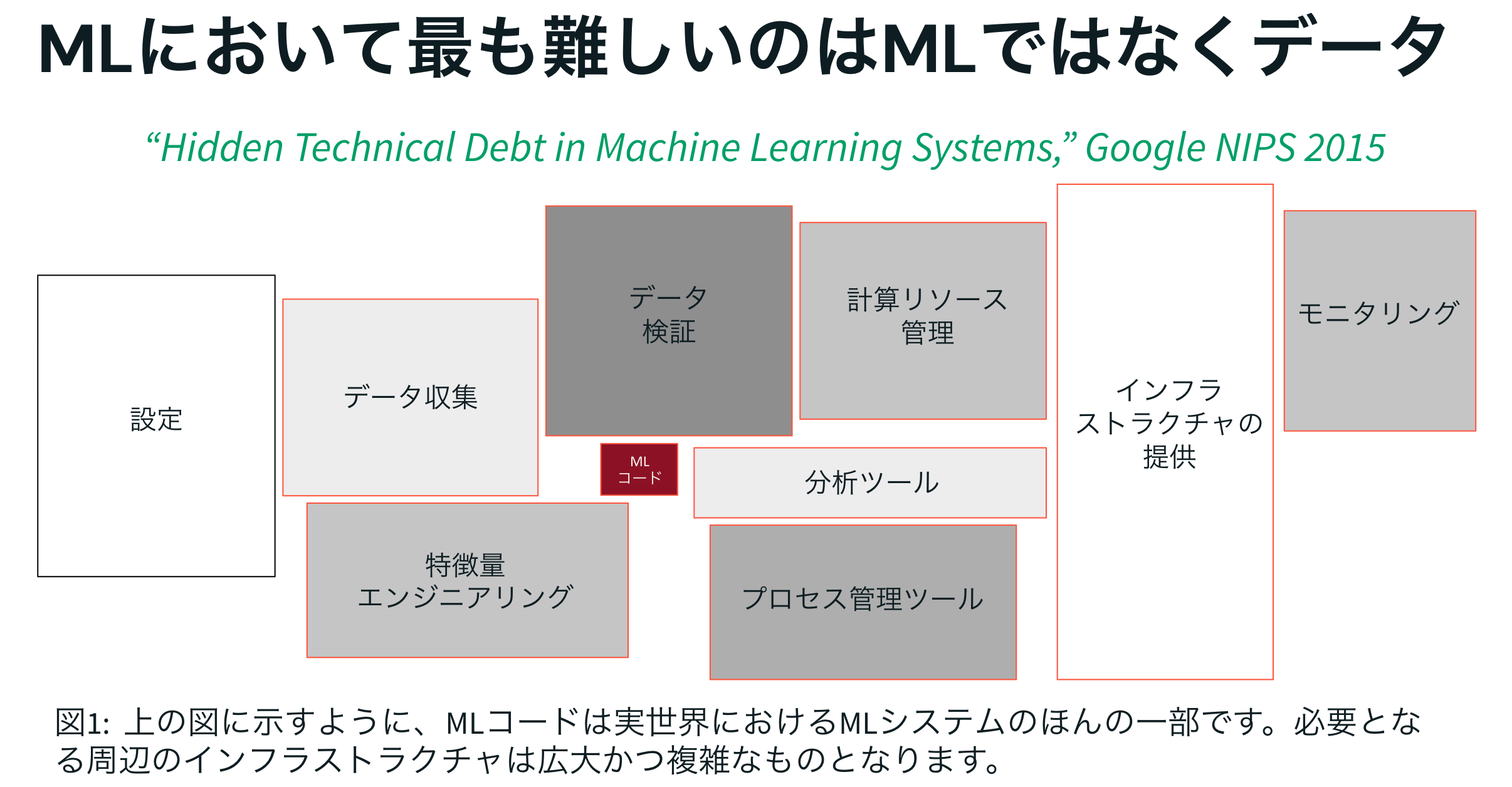
必要となる周辺のインフラストラクチャは広大かつ複雑です。
- 設定管理
- データ収集
- データ検証
- 特徴量エンジニアリング
- 計算リソース管理
- 分析ツール
- プロセス管理ツール
- インフラストラクチャの提供
- モニタリング
MLOpsとは
MLOpsとは、機械学習モデルの開発から本番運用までのライフサイクル全体を管理するためのプラクティスです。


「這う・歩く・走る」アプローチ
MLOpsを実践する際は、一度にすべてを導入するのではなく、段階的に成熟度を高めていくアプローチが推奨されます。
這う (Crawl)
最初のステップでは、基本的な実験管理とモデル登録を行います。
- MLflowで実験を記録
- 手動でモデルをデプロイ
- 基本的なモニタリング
歩く (Walk)
次のステップでは、ある程度の自動化を導入します。
- CI/CDパイプラインの構築
- モデルの自動テスト
- A/Bテストの実施
走る (Run)
成熟したステップでは、完全な自動化と継続的な改善を実現します。
- 自動再学習パイプライン
- リアルタイムモニタリング
- 自動ロールバック

Unity CatalogとMLflow
Unity Catalog概要
Unity Catalogは、Databricksの統合ガバナンスソリューションです。データとMLアセットを一元管理できます。
- データカタログ
- アクセス制御
- 監査ログ
- リネージ追跡

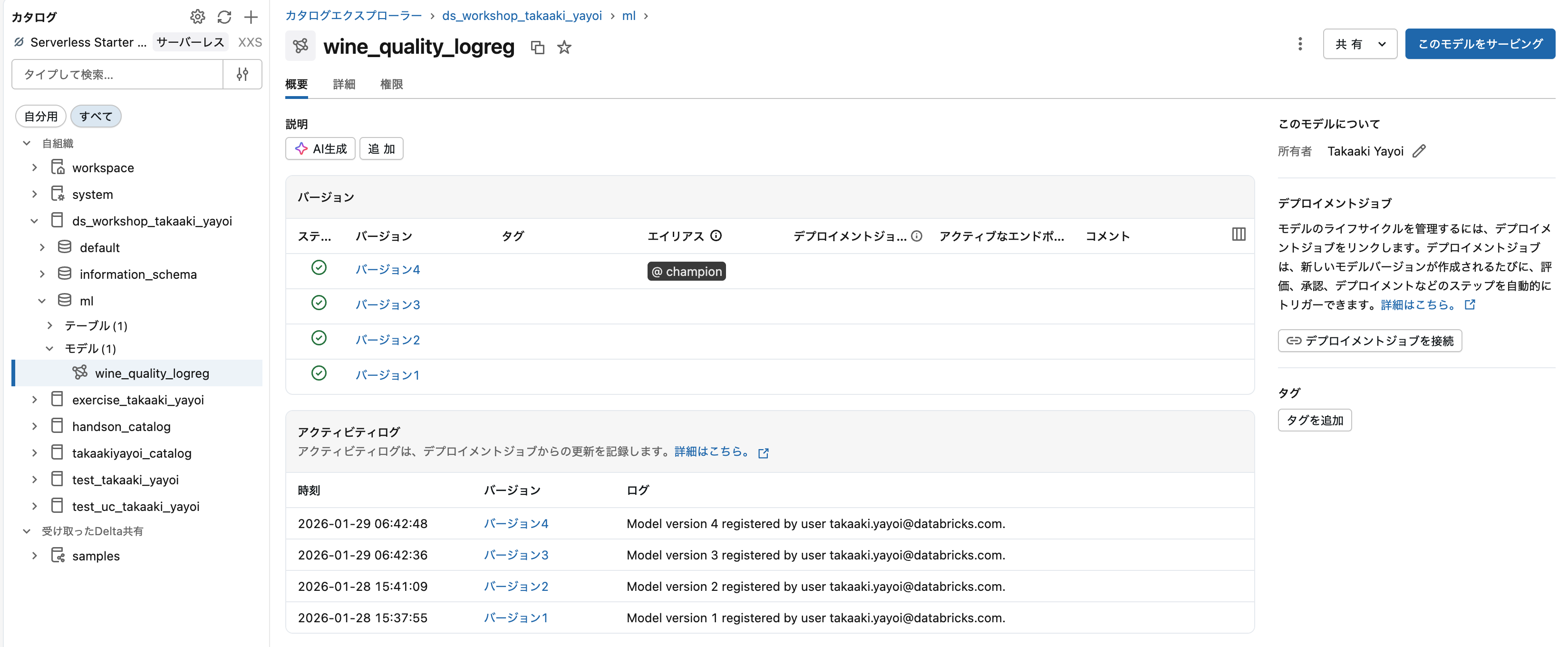
Model Registry in Unity Catalog
Unity CatalogにはModel Registryが統合されており、モデルのライフサイクル管理が可能です。
主な機能
- モデルのバージョン管理
- ステージ管理(None → Staging → Production → Archived)
- アクセス制御
- リネージ追跡(どのデータから作成されたか)
import mlflow
# Unity Catalogにモデルを登録
mlflow.set_registry_uri("databricks-uc")
model_name = "catalog.schema.my_model"
# モデルを登録
mlflow.register_model(f"runs:/{run_id}/model", model_name)
Feature Store
Feature Storeは特徴量を一元管理するための機能です。
特徴量の定義
- 再利用、共有可能な特徴量計算ロジックの定義
特徴量テーブル
- 任意の言語からクエリーできるテーブルとして特徴量を表現
- SQL、ACL、バージョン、パフォーマンス最適化
活用シーン
- トレーニングデータセットの生成
- バッチスコアリング
- オンラインサービング

企業内でスケールさせる
MLOpsを企業全体に展開する際は、以下のステップで進めます。
成功を繰り返す
新たなデータ問題に対して同じ様なツール、データアーキテクチャ、知識を適用します。組織内にDS/MLのCoEを構築します。
調整して構築する
様々なチームと連携した我々の経験を活用し、統合プラットフォームを構築します。
- DS/ML
- DE
- BI/アナリティクス
- セキュリティ/インフラ
- プラットフォーム
部門を超えてスケール
新たな問題を解決するために、皆様のチームの一員としてSMEや他のビジネスユニットと取り組みます。
- ビジネスリーダー
- 技術エキスパート
- ソリューションアクセラレータ
- カスタマーサクセスストーリー

実践演習: scikit-learn+MLflowで機械学習ワークフロー
実践演習では、以下の一連の流れを体験します。
データ準備と特徴量エンジニアリング
- データ読み込み
- SparkでEDAと前処理を実行
- 特徴量エンジニアリング

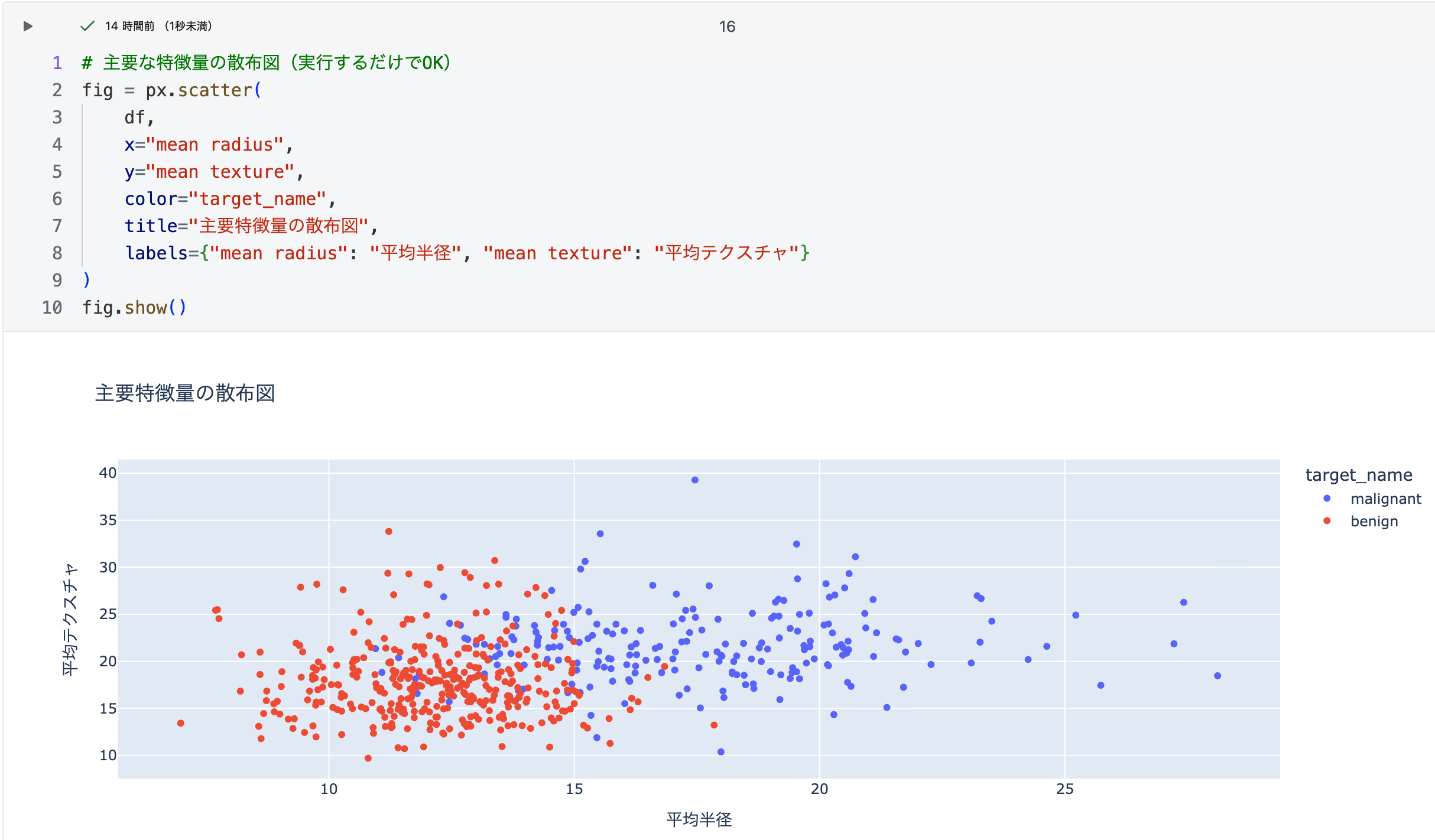
パイプライン構築とモデル学習
- scikit-learnでパイプラインを構築
- MLflowで自動ロギングを有効化
- モデルを学習

実験管理と結果比較
- MLflow UIで実験結果を確認
- 複数の実験を比較
- 最良のモデルを特定

モデル登録とバッチ推論
- 最良のモデルをModel Registryに登録
- モデルをロードしてバッチ推論を実行
- 結果をDelta Lakeに保存
import mlflow
# モデルをロード
model = mlflow.pyfunc.load_model(f"models:/{model_name}@production")
# バッチ推論
predictions = model.predict(X_test)
# 結果を保存
result_df.write.format("delta").saveAsTable("predictions")

まとめ
本講座では、Databricks Free Editionを使用したデータサイエンスの基礎から実践までを学びました。
Part 1 では、機械学習の基礎、scikit-learnによるモデル開発、MLflowによる実験管理を学びました。
Part 2 では、MLOpsの必要性、段階的なアプローチ、Unity CatalogとMLflowの連携について学びました。
実践演習 では、データ準備からモデル登録までの一連のワークフローを体験しました。
Databricks Free Editionを活用して、ぜひ実際に手を動かしながら学習を進めてください。