Databricks Delta: A Unified Data Management System for Real-time Big Data - The Databricks Blogの翻訳です。2017年10月時点の記事のため一部修正しています。
データウェアハウス、データレイク、ストリーミングの長所を兼ね備えたDelta Lake
詳細な説明、デモをオンデマンドウェビナーで紹介しています。
大規模データ管理を簡素化する統合データ管理システムDatabricks Delta Lakeを発表できることを誇りに思います。現在、多くの企業は、データウェアハウス、データレイク、ストリーミングシステムなどの複数のシステムを組み合わせて、自身のビッグデータシステムを構築しています。これはコストを増加させることに加え、システムの維持、統合が難しくなるにつれて、運用の複雑性も引き上げることになります。
DatabricksのDelta Lakeは、はじめてデータレイクのスケーラビリティ、データウェアハウスの信頼性とパフォーマンス、ストリーミングシステムの反応速度を組み合わせた単一のデータ管理システムです。Databricksのレイクハウスプラットフォームと組み合わせることで、ビッグデータアプリケーションの構築、管理、実運用への移行を劇的に容易に行えるようになります。
現在のデータアーキテクチャの問題
Delta Lakeの詳細に入っていく前に、現在のビッグデータアーキテクチャのどの部分が構築、管理、維持を難しくしているのかを議論しましょう。最新のデータアーキテクチャは、少なくとも異なるタイプの3つのシステム、ストリーミングシステム、データレイク、データウェアハウスを組み合わせています。
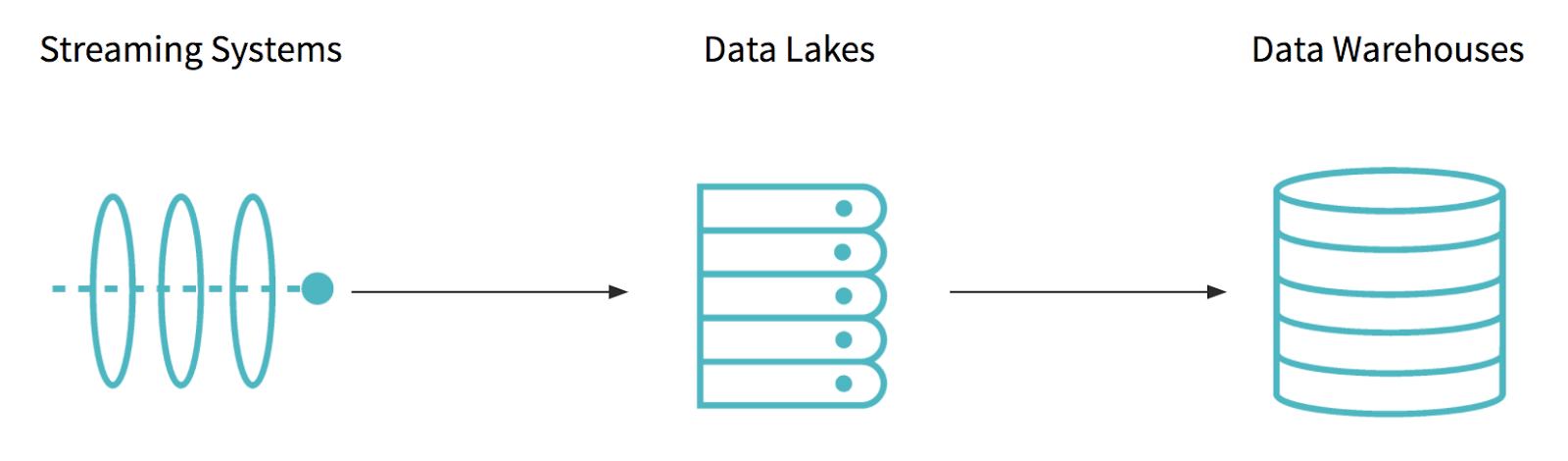
遅延のない配信に主眼を置いたAmazon KinesisやApache Kafkaといったストリーミングシステムを通してビジネスデータが到着します。そして、Apache Hadoop、Amazon S3のようなスケーラビリティ、低コストに特化したデータレイクに格納されます。残念ながら、データレイク単体では、ハイエンドのビジネスアプリケーションをサポートするのに必要な機能やパフォーマンスを提供することはできません。このため、価値のあるデータは、データレイクより高価なストレージで高信頼性、同時実行数、高いパフォーマンスを提供するデータウェアハウスにアップロードされます。
このありきたりなアーキテクチャは、多くの企業が苦戦しているいくつかの課題をもたらします。まず、これらのストレージシステム間のETL(抽出、変換、ロード)処理はエラーが混入しやすく、複雑になります。データチームはETLジョブの構築に多くの時間を費やすことになります。ある日、ジョブが入力データをすべて取り込めなかったり、エラーを含むデータをアップロードしてしまうと、後段のアプリケーションに問題が波及することになります。次に、このようなETL処理は非常に時間がかるものであり、これはレコードが到着してからデータウェアハウスに現れるまでに数時間かかるケースがあることを意味します。
Edmunds.comの技術担当執行役員であるGreg Rokitaは以下のように説明しています。「Edmundsにおいては、顧客や収益に関する洞察をリアルタイムで取得することは、ビジネス上非常に重要なことでした。そかし、複雑なETL処理が迅速なデータアクセスを妨げていました。」
Databricksにおいては、起業以来このような課題に直面しているお客様を数多く見てきました。この経験から、我々はデータ管理を劇的にシンプルにする方法を探していました。言い換えると、「どうすれば、データレイク、データウェアハウス、ストリーミングといった異なるシステムのメリットを、高いコスト、エラーが生じやすいETLを必要としない、一つの統合プラットフォームで提供できるか?」ということになります。これに対する我々の答えがDelta Lakeとなります。
Databricks Delta Lake: 統合データ管理
Delta Lakeは、データウェアハウス、データレイク、ストリーミングの長所を組み合わせた新たな_統合_データ管理システムです。DeltaはAmazon S3の上で動作し、Apache Parquetのようなオープンフォーマットでデータを蓄積します。しかし、Delta LakeはS3をいくつかの方法で拡張することで、以下のゴールを達成します。
- データウェアハウスの信頼性とパフォーマンス: Deltaは、インサート、削除、アップサート(アップデート + インサート)、検索のトランザクションをサポートします。これにより、数百のアプリケーションからの同時アクセスに対しても信頼性を保つことができます。また、Delta Lakeは自動でインデックス作成、圧縮、データキャッシュを行いますので、S3上のParquetやApache Hiveに対するApache Sparkの処理性能が100倍改善します。
- ストリーミングシステムのスピード: Delta Lakeは新たなデータをすぐに取り込み、即座にストリーミング、バッチ両方での高速クエリーが可能となります。
-
データレイクのコスト効率性、スケーラビリティ: Delta LakeはデータをS3のようなクラウドblobストレージに格納します。これにより、低コスト、スケーラビリティ、同時アクセスのサポート、読み書きの高いスループットといった特性を引き継いでいます。

Delta Lakeを活用することで、もはや企業はストレージシステム間のトレードオフを検討したり、複数システム間のデータ移動に労力を費やす必要はなくなります。数百のアプリケーションは、信頼性を保ったまま大規模データのアップロード、クエリー、データの更新を低コストで行えるようになります。
技術的観点においては、Delta LakeはS3に対して以下の拡張を行うことで課題を解決しています。
- ACIDトランザクション
- (Delta Lakeのトランザクションと連携した)自動データインデックス
これらの拡張によって、Delta Lakeがユーザーの代わりにアプリケーションに対して信頼性のあるデータアクセスを提供しながらも、様々な最適化が可能となります。Delta Lakeはデータソースとして、あらゆるSparkジョブと連携することができ、ユーザーそれぞれのS3アカウントにデータを格納し、完全なデータ管理プラットフォームを提供するために、Databricksのエンタープライズレベルのセキュリティと統合できます。
Delta Lakeの機能は日々追加・改善されていますので、今後のブログ記事にご期待ください。
サンプルユースケース: リアルタイム情報セキュリティ
Databricks CEOのAli GhodsiはSpark Summit Europeのキーノートで、すでにいくつかの大企業でDelta Lakeが利用されていると述べました。実際にDelta Lakeを活用して1日あたり数兆レコードを処理しているFortune 100のお客様の事例を見ていきましょう。
- 低いレイテンシーでの大量データ投入: 1日あたり数兆のレコードを、秒〜分のレイテンシーで登録する必要があります。
- データの正確性、トランザクションでサポートされたデータ更新: データは正確かつ一貫性が担保される必要があります。ユーザーのクエリーに対して部分的、不完全な書き込み結果が見えてはいけません。
- 現在、履歴データに対する高速、柔軟性のあるクエリー: 分析者は、Python、SQLのような汎用言語でペタバイトのデータを分析する必要があります。
データチームはこれらの要件に応えるために20人のエンジニア、6ヶ月を費やして、様々なデータレイク、データウェアハウス、ETLツールから構成されるレガシーなアーキテクチャを構築しました。その時点でも、コスト、過去のデータを参照する機能の制限から、2週間分のデータしか登録できていませんでした。さらに、選択されたデータウェアハウスで機械学習を行うことができませんでした。
Delta Lakeを活用することで、この企業は5人のエンジニアが2週間を費やすだけで、Delta Lakeベースの新たなアーキテクチャを実運用に移行できました。
新たなアーキテクチャはシンプルかつ高性能です。エンドツーエンドのレイテンシーは低く(数秒〜数分)、Parquetに対するオープンソースApache Sparkのクエリー処理性能は100倍に改善されました。さらに、Delta Lakeを活用することで、データチームは全ての履歴データに対してインタラクティブにクエリーを実行できるようになりました。さらにはApache Sparkを機械学習や高度分析にも活用しています。
Deltaを使ってみる
Databricks 無料トライアルからDatabricksにサインアップいただくだけでDelta Lakeを使用できます。
まとめ
全てのビジネスでビッグデータアプリケーションは重要になってきていますが、依然として構築は複雑で、提供するのに時間を要するものになっています。データ管理をシンプルにするために、データレイクやラムダアーキテクチャのような新たなモデルが提案され続けています。DatabricksのDelta Lakeを活用することで、このゴールに対して重大な第一歩を踏み出せると考えています。新たなストレージシステムやデータ管理のステップを_追加_するのではなく、Delta Lakeは一つのプラットフォームで複数のストレージシステムのメリットを提供し、複雑性を_削除_します。クラウドストレージの低コスト、スケーラビリティと既存システムの長所を組み合わせることで、Delta Lakeによってデータアーキテクチャを劇的にシンプルなものにし、お客様がデータから価値を抽出することにフォーカスできるようになると信じています。
参考情報
- Delta Lakeクイックスタートガイド - Qiita
- データレイクをDelta Lakeに移行すべき5つの理由 - Qiita
- Databricks Deltaを使って秒でペタバイトデータを処理する - Qiita
- Delta Lakeのベストプラクティス - Qiita