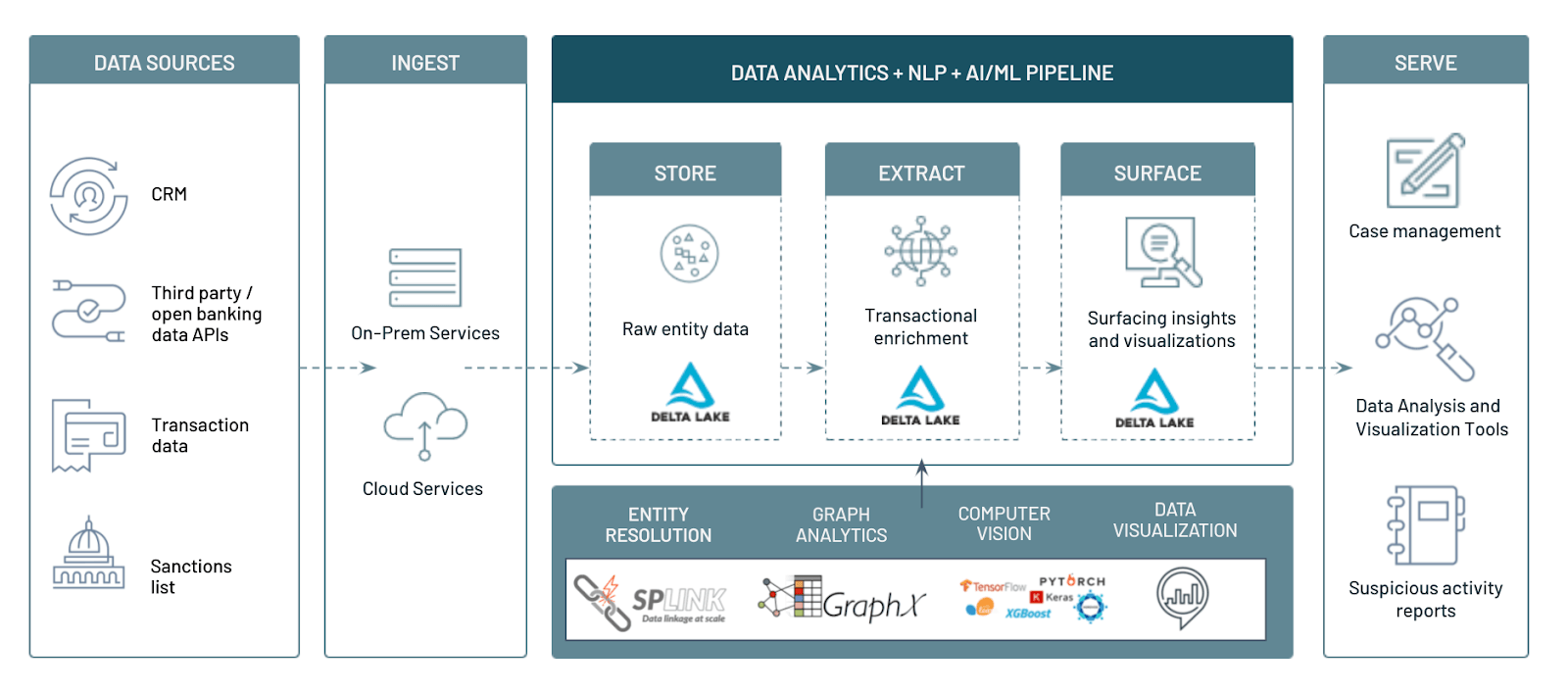
Enhanced AML Transaction Monitoring With the Lakehouse Platform - The Databricks Blogの翻訳です。
金融犯罪ソリューション構築における主要な課題の解決
アンチマネーロンダリング(AML)のコンプライアンスは、世界中の金融機関を監視する規制機関にとって最重要事項であることは間違いありません。この数十年でAMLは進化し、より洗練されてきているため、規制の要件はモダンなマネーロンダリングやテロリストによる金融犯罪に対抗できるように設計される必要があります。Bank Secrecy Act of 1970では、金融機関が金融トランザクションを適切にモニタリングし、疑わしい会計操作を適切な機関に報告する際のガイドラインとフレームワークを提供しています。
なぜアンチマネーロンダリングは複雑なのか
現状のAMLオペレーションは、これら過去十年間の取り組みにほとんど対応できていません。デジタルバンキングへのシフトによって、金融機関は1日あたり数十億のトランザクションを取り扱うことになった結果、マネーロンダリングのスコープも拡大し続けており、より厳密なトランザクションモニタリングシステムや、堅牢なKnow Your Customer(KYC)ソリューションも求められています。この記事では、モダンなオンラインマネーロンダリングの脅威の真実を受け入れ、強力な監視、および革新的、スケーラブルなソリューションを提供するために、我々が金融機関のお客様とレイクハウスプラットフォームにエンタープライズ規模のAMLソリューションを構築した際の体験談をシェアします。
レイクハウスによるAMLソリューションの構築
1日あたり数十億のトランザクションを処理するオペレーションの負荷は、様々なソースからのデータを蓄積し、計算リソースを必要とする次世代AMLソリューションの必要性に起因しています。これらのソリューションは、偽陽性を削減し、後段での調査の効率を改善するために先進的な機械学習モデルをサポートすることで、強力なリスク分析、レポーティング機能を提供します。金融機関はすでに、膨大な量のデータを蓄積するのに求められるスケールのセキュリティ、俊敏性、経済性を得るために、オンプレミスからクラウドに移行することで、インフラストラクチャ、スケーラビリティの課題を解決するための一歩を踏み出しています。
しかし、安価なオブジェクトストレージに収集、蓄積された膨大な構造化、非構造化データをどのように活用するのかに関して課題が存在します。クラウドプロバイダーはデータを蓄積するための安価な方法を提供しますが、後段でのAMLリスク管理、コンプライアンスに関わるアクティビティは、アクティビティで利用できるような高品質かつ高性能なフォーマットのデータの蓄積からスタートします。Databricksのレイクハウスプラットフォームは、まさにこのためのものです。データレイクの低コストストレージのメリットと、データウェアハウスの堅牢なトランザクション機能を組み合わせることで、金融機関はモダンAMLプラットフォームを構築することができます。
上述したデータ格納の問題に加え、AMLアナリストは以下のようなドメイン固有の問題に直面しています。
- 画像、テキストデータ、ネットワークのつながりなどの非構造化データのパースに要する時間の改善
- エンティティ解決、コンピュータービジョン、エンティティメタデータに対するグラフ分析などの重要なML機能をサポートする際のDevOps負荷の削減
- AMLトランザクション、拡張されたテーブルに対する分析エンジニアリング、ダッシュボードを導入することによるサイロの打破
幸運にも、Databricksはエンティティ間の関係性を構築するために非構造化データ、構造化データの両方を蓄積、結合するためにDelta Lakeを活用することで、これらの問題の解決をサポートします。さらに、テーブルに対するBIクエリーを高速化するために新たなPhotonを用いることで、DatabricksのDeltaエンジンは効率的なアクセスを提供します。これらの機能に加え、MLはレイクハウスにおける一級市民であり、このことは、アナリストやデータサイエンティストがダッシュボードを共有し、悪者の一歩先を行くために、サブサンプリングやデータの移動に時間を費やす必要はないことを意味します。
グラフ機能によるAMLパターンの検知
AMLアナリストがケースの一部に使用する主たるデータソースの一つは、トランザクションデータです。このデータは表形式で、SQLで容易にアクセスできますが、SQLクエリーで三層以上のトランザクションの連鎖を追跡するのは面倒です。このため、一緒になって不正なトランザクションを行っていると疑われる個人のネットワークのようなシンプルなコンセプトを表現できるような柔軟性のある言語、APIのスイートを持つことが重要となります。幸運なことに、これはDatabricks機械学習ランタイムでプレインストールされているグラフAPIであるGraphFramesを用いることでシンプルに達成することができます。
このセクションでは、偽造IDやレイヤリング・ストラクチャリングのようなAMLの企みを検知するために、どのようにグラフ分析を活用できるのかを説明します。Apache Spark™、GraphFrames、Delta Lakeを用いてこれらのパターンの存在を検知するために、トランザクション、トランザクションから作成したエンティティから構成されるデータセットを活用します。これらの発見に対するゴールドレベルの集計結果にDatabricks SQLを適用し、グラフ分析のパワーをエンドユーザーに提供できるように、永続化されたパターンはDelta Lakeに保存されます。
シナリオ1 - 偽造ID
上で述べたように、偽造IDの存在はアラームの原因となりえます。グラフ分析を活用することで、リスクレベルを検知するためにトランザクションの全てのエンティティをバルクで分析します。
- トランザクションデータに基づきエンティティを抽出
- 住所、電話番号、メールアドレスに基づきエンティティ間のリンクを作成
- (IDと上記属性で識別される)複数エンティティに一つ以上のリンクがあるかどうかを決定するために接続されたコンポーネントにGraphFramesを適用
エンティティ間に幾つのコネクションがあるのかに基づき、低い、あるいは高いリスクスコアを割り当て、高いスコアを示したグループに対してアラートを発呼します。このアイデアの基本的な考え方を以下に示します。
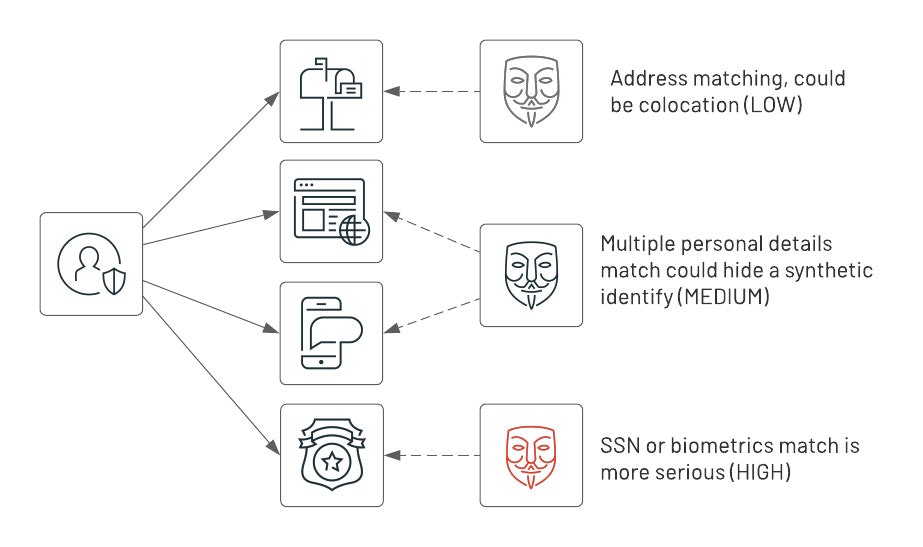
まず初めに、属性に一致がある場合には個人をリンクするために、住所、メールアドレス、電話番号を用いてグラフを作成します。
e_identity_sql = '''
select entity_id as src, address as dst from aml.aml_entities_synth where address is not null
UNION
select entity_id as src, email as dst from aml.aml_entities_synth where email_addr is not null
UNION
select entity_id as src, phone as dst from aml.aml_entities_synth where phone_number is not null
'''
from graphframes import *
from pyspark.sql.functions import *
aml_identity_g = GraphFrame(identity_vertices, identity_edges)
result = aml_identity_g.connectedComponents()
result \
.select("id", "component", 'type') \
.createOrReplaceTempView("components")
次に、個人IDとスコアがオーバーラップする2つのエンティティを特定するためのクエリーを実行します。グラフコンポーネントをクエリーした結果に基づき、1つの属性(住所など)のみが一致する個人から構成される集団を期待する場合もありますが、これはさほど大きな問題ではありません。しかし、より多くの属性が一致した場合には、アラートを出すことを考えるべきです。以下に示すように、SQLアナリストは全てのエンティティに対するグラフ分析の結果を日次で得ることができ、3つの属性全てが一致したケースでアラートを出すことができます。
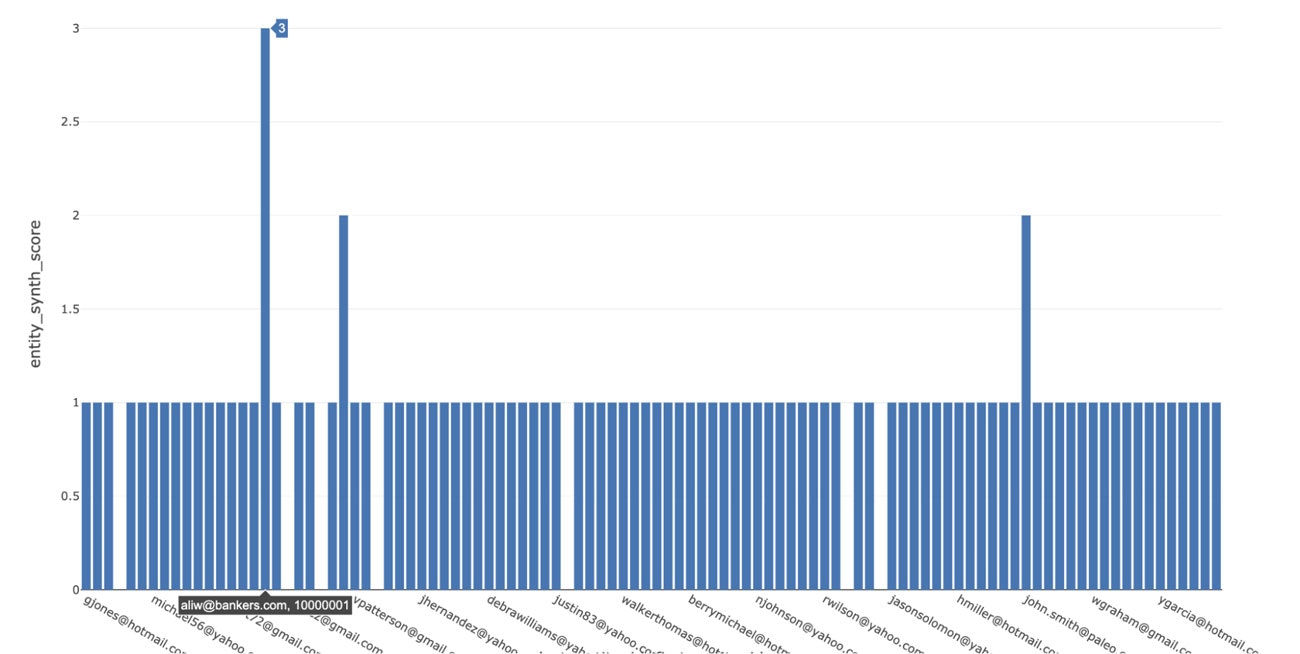
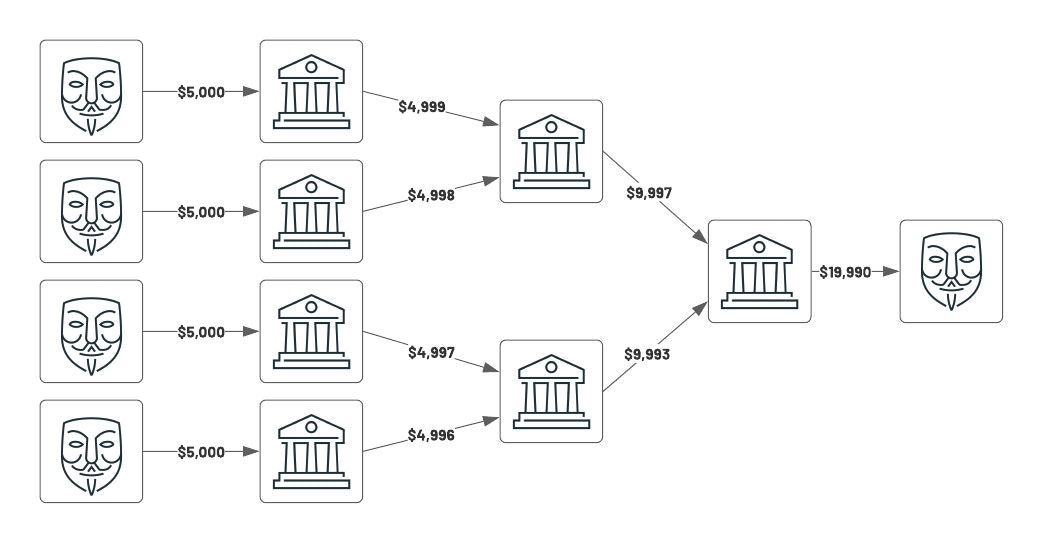
シナリオ2 - ストラクチャリング
別の一般的なパターンはストラクチャリングと呼ばれるものです。これは、複数のエンティティが共謀し、一連の銀行に対して小規模の「レーダーをかいくぐる」支払いを送信し、最終的な機関(以下の図における一番右)に大量の金額を集めるというものです。このシナリオにおいては、全ての登場人物は$10,000ドルの閾値以下に留まっていますが、多くの場合アラートを出すべきです。グラフ分析で容易に対応できるだけでなく、別のネットワークの組み合わせを拡張し、同様の方法で疑わしいトランザクションを特定するために、モチーフ探索技術を自動化することもできます。
グラフ機能を用いて上述のシナリオを検知するための基本的なモチーフ探索コードを書いてみます。ここでのアウトプットは準構造化データのJSONであることに注意してください。非構造化データを含むあらゆる種類のデータは、レイクハウスでは容易にアクセスすることができます。SQLでのレポーティングのために特定の結果を保存しておきます。
motif = "(a)-[e1]->(b); (b)-[e2]->(c); (c)-[e3]->(d); (e)-[e4]->(f); (f)-[e5]->(c); (c)-[e6]->(g)"
struct_scn_1 = aml_entity_g.find(motif)
joined_graphs = struct_scn_1.alias("a") \
.join(struct_scn_1.alias("b"), col("a.g.id") == col("b.g.id")) \
.filter(col("a.e6.txn_amount") + col("b.e6.txn_amount") > 10000)
モチーフ探索を用いることで、異なる4つのエンティティによる$10,000の閾値以下でのトランザクションからなる興味深いパターンを抽出しています。AMLアナリストがさらに調査できるように、洞察を作成するためにグラフのメタデータを構造化データセットに結合しなおしています。

シナリオ3 - リスクスコアの伝播
特定された高リスクエンティティは、彼らのサークルでの影響力(ネットワーク効果)を持つことでしょう。このため、やりとりがある全てのエンティティのリスクスコアは、影響範囲を反映するように調整される必要があります。繰り返しアプローチを用いることで、あらゆる深さまでトランザクションの流れを追跡することができ、ネットワークで影響を受けている他の人のリスクスコアを調整することができます。以前述べたように、グラフ分析を行うことで、複数繰り返されるSQLのJOINと複雑なビジネスロジックを回避することができ、メモリーの制限によるパフォーマンスへのインパクトを与えます。グラフ分析とPregel APIはまさにこの目的のために開発されたものです。当初Googleによって開発されたPregelを用いることで、ユーザーはあらゆる頂点から対応する隣人に再帰的にメッセージを「伝播」し、それぞれのステップで頂点の状態(ここではリスクスコア)を更新することができます。以下のようにPregel APIを用いて動的にリスクアプローチを表現することができます。
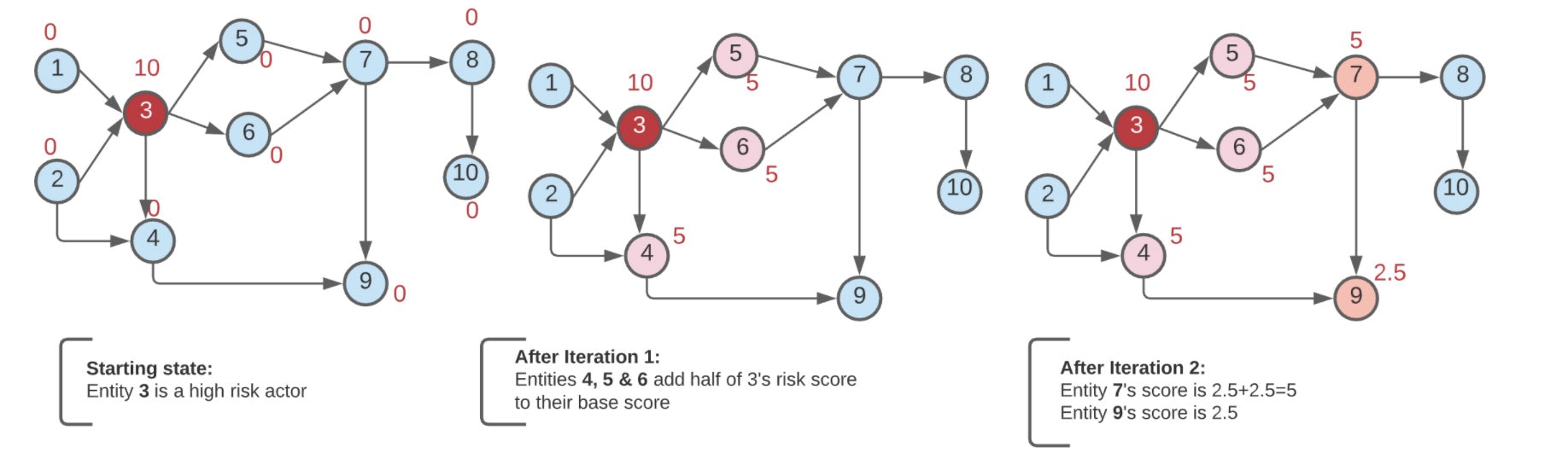
上の図はネットワークの初期状態とその後の2つのイテレーションを示しています。リスクスコア10を持つ1人の悪者(#3ノード)がいる状態からスタートするとします。このノードとのトランザクションがある全ての人々(この場合、ノード4、5、6)に対して、例えば、悪者のリスクスコアの半分を引き渡し、彼らのベーススコアに追加することでペナルティを与えたいとします。次のイテレーションでは、ノード4、5、6から下流の全てのノードのスコアも調整されます。
| ノード | イテレーション #0 | イテレーション #1 | イテレーション #2 |
|---|---|---|---|
| 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 |
| 3 | 10 | 10 | 10 |
| 4 | 0 | 5 | 5 |
| 5 | 0 | 5 | 5 |
| 6 | 0 | 5 | 5 |
| 7 | 0 | 0 | 5 |
| 8 | 0 | 0 | 0 |
| 9 | 0 | 0 | 2.5 |
| 10 | 0 | 0 | 0 |
GraphFrameのPregel APIを用いることで、他のアプリケーションで利用できるように計算処理と永続化を行うことができます。
from graphframes.lib import Pregel
ranks = aml_entity_g.pregel \
.setMaxIter(3) \
.withVertexColumn(
"risk_score",
col("risk"),
coalesce(Pregel.msg()+ col("risk"),
col("risk_score"))
) \
.sendMsgToDst(Pregel.src("risk_score")/2 ) \
.aggMsgs(sum(Pregel.msg())) \
.run()
住所マッチング
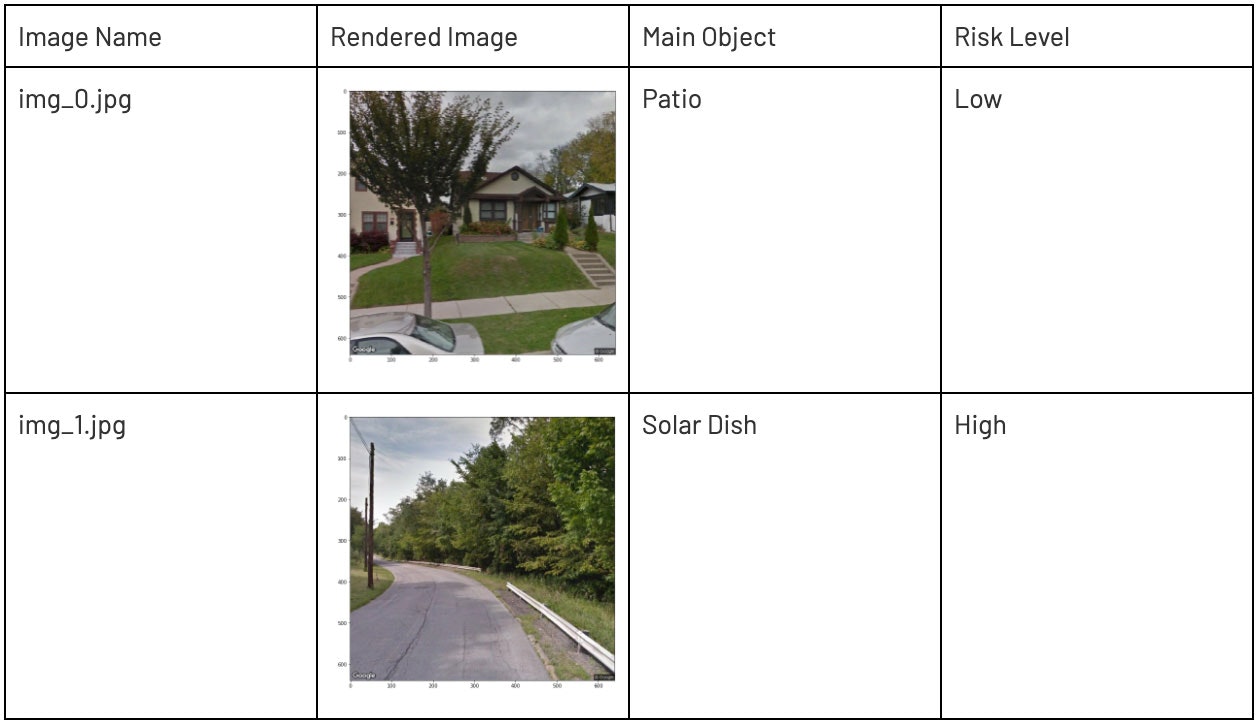
簡単に触れたいパターンとしては、テキストの住所と実際のストリートビューの画像のマッチングがあります。多くの場合、AMLアナリストは、ファイル上のエンティティにリンクされている住所の正統性を検証する必要があります。この住所は商業ビルあるいは居住エリア、それともシンプルな郵便箱なのでしょうか?しかし、写真の分析は多くの場合、面倒かつ時間を浪費し、写真の取得、クレンジング、検証はマニュアルの作業となります。レイクハウスのデータアーキテクチャでは、PyTorchと事前学習済みオープンソースモデルとPython、MLランライムを用いることで、これらのタスクの大部分を自動化することができます。以下は、人間の目で見て適切と見做せる住所の例となります。検証を自動化するために、住居を検知するために使用できる、適切な数百のオブジェクトに対して事前トレーニング済みのVGGモデルを使用します。

以下のコードを日次で自動実行することで、ラベルがアタッチされた画像を取得することができます。シンプルなクエリーが行えるように、我々は全ての画像リファレンスとラベルをSQLテーブルにロードしました。画像に含まれるオブジェクトに対してクエリーを行う際に、以下のコードがどれだけシンプルなのか注意してください。このように、Delta Lakeによる非構造化データに対するクエリー能力は、アナリストにとって多大なる時間削減となり、数日、数週間かかっていた検証プロセスを数分にまで高速化します。
from PIL import Image
from matplotlib import cm
img = Image.fromarray(img)
...
vgg = models.vgg16(pretrained=True)
prediction = vgg(img)
prediction = prediction.data.numpy().argmax()
img_and_labels[i] = labels[prediction]
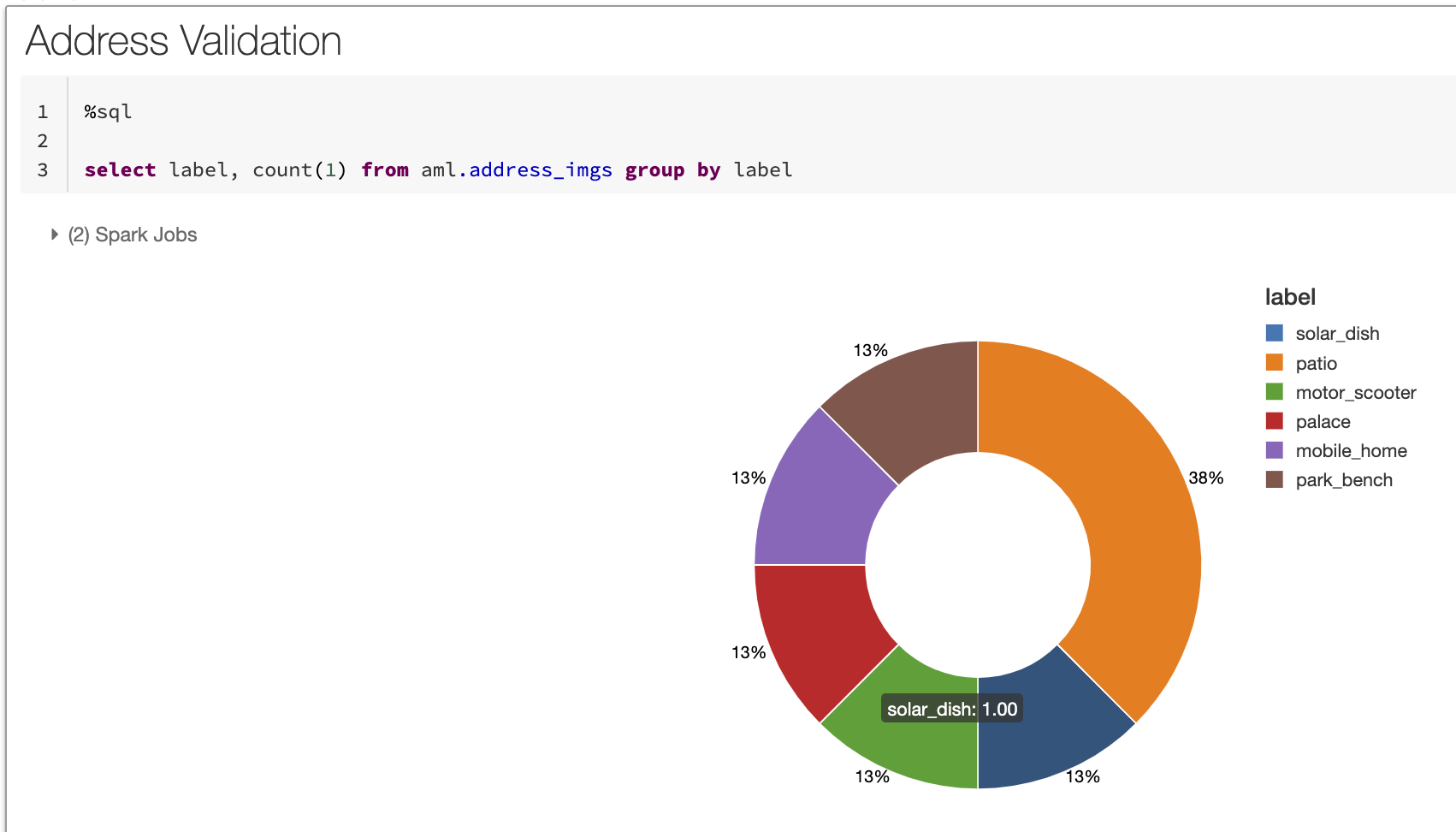
要約を進めるに従い、いくつかの興味深いカテゴリーが見えてくることに気づきました。以下のようにブレークダウンを行うことで、住居として検知されるだろうと期待するパティオ、モバイルホーム、モータースクーターのような明確なラベルがある一方、CVモデルはある画像の周辺オブジェクトから「太陽光パネル」とラベルをつけています(注意:カスタム画像でトレーニングしていないオープンソースモデルに限定しているので、太陽光パネルというラベルは正確ではありません)。画像に対してさらに分析を行うために、ドリルダウンを行うとすぐに以下のことがわかりました。
- そこには本当の太陽光パネルはありませんでした。さらに重要なことに
- この住所は本当の住居を示していませんでした(上の横並びの写真)。
Delta Lakeフォーマットを用いることで、以下のような分類結果のブレークダウンに対してシンプルなクエリーを行えるようにするためのラベルとともに、非構造化データへのリファレンスを蓄積することができます。
エンティティ解決
ここでフォーカスするAMLの課題の最後のカテゴリはエンティティ解決です。数多くのオープンソースライブラリがこの問題、いくつかの基本的なエンティティファジーマッチングに取り組んでおり、我々は大規模なリンケージを達成し、マッチするカラム、ブロッキングルールを指定できるSplinkをハイライトすることにしました。
トランザクションから得られるエンティティの文脈においては、Delta LakeのトランザクションをSplinkにインサートするシンプルな作業となります。
settings = {
"link_type": "dedupe_only",
"blocking_rules": [
"l.txn_amount = r.txn_amount",
],
"comparison_columns": [
{
"col_name": "rptd_originator_address",
},
{
"col_name": "rptd_originator_name",
}
]
}
from splink import Splink
linker = Splink(settings, df2, spark)
df2_e = linker.get_scored_comparisons()
Splinkはエンティティの属性が非常に類似しているトランザクションを特定するのに用いられるマッチ確率を割り当てることで動作し、報告された住所、エンティティ名、トランザクションの総量に関して潜在的なアラートを発呼します。エンティティの解決においては、アカウント情報のマッチングを行う際に膨大な手作業が必要になる場合があることから、このタスクを自動化し、Delta Lakeに情報を保存するオープンソースライブラリを活用することで、調査官がケースを解決する際の生産性を劇的に改善することができます。エンティティマッチングを行うには、いくつかの選択肢がありますが、この作業のために適切なアルゴリズムを特定するLocality-Sensitive Hashing(LSH)を使用することをお勧めします。LSHの詳細及びメリットに関しては、こちらのブログ記事を参照ください。
上でお伝えした通り、NY Melon銀行のアドレスにおいて、“Canada Square, Canary Wharf, London, UK”と類似した“Canada Square, Canary Wharf, London, United Kingdom”という幾つかの一貫性の欠如を迅速に発見しました。AMLの調査に使えるように、重複を排除したレコードをDeltaテーブルに書き戻すことができます。

AMLレイクハウスダッシュボード
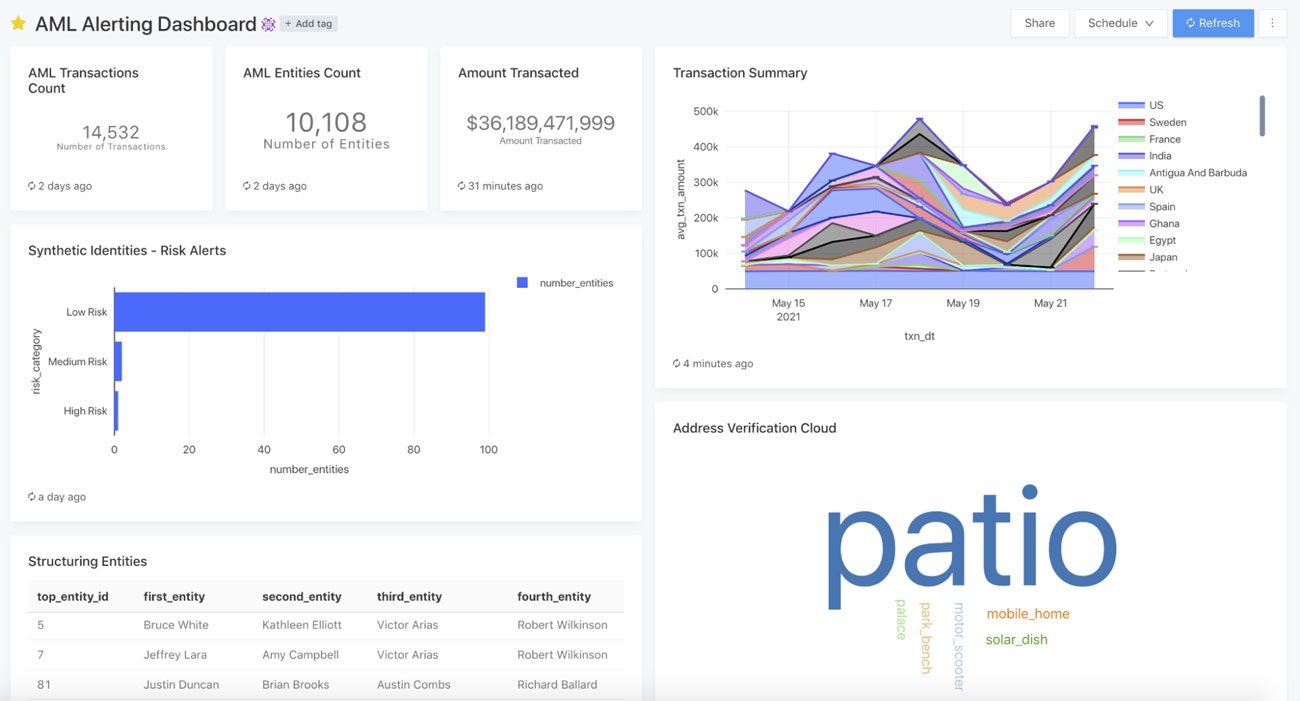
レイクハウスにおけるDatabricks SQLは、新たなクエリーエンジンであるPhotonとユーザーの同時実行性を活用して、シンプルなデータ管理、パフォーマンスに関する従来のデータウェアハウスにおけるギャップを埋めるものです。多くの企業においては、高価なプロプライエタリAMLソフトウェアで金融犯罪との闘いをサポートするCFT(Combatting the financing of terrorism)のような数多くのユースケースをサポートする予算がないため、これは重要となります。市場においては、上述のグラフ分析に特化したソリューション、ウェアハウスにおけるBIに特化したソリューション、MLに特化したソリューションは存在しています。AMLレイクハウスのデザインは、これら3つ全てを統合します。AMLデータプラットフォームチームは、グラフ技術によって整理されたレポートを作成するためのオープンソース技術、コンピュータービジョン、SQLアナリティクスエンジニアリングと容易に統合しつつも、安価なクラウドストレージ上のDelta Lakeを活用することができます。以下で、AMLにおけるレポーティングを具現化した結果をお見せします。
添付のノートブックはトランザクションオブジェクト、エンティティオブジェクトを生成し、可能性のあるストラクチャリング、偽造ID、事前学習済みモデルを用いた住所の分類に関するサマリーを作成します。以下に示すDatabricks SQLのビジュアライゼーションにおいては、これらに対する要約処理を実行するためにPhoton SQLエンジンと、数分でレポート用ダッシュボードを作成するためのビルトインのビジュアライゼーションを使用しました。テーブル、ダッシュボードに対する完全なACLを適用できるので、ユーザーはこれらを経営陣やデータチームと共有することができます。定期的なレポートの実行のためのスケジューラもビルトインされています。このダッシュボードは、AMLソリューションに組み込まれたAI、BI、分析エンジニアリングの集大成と言えます。
オープンバンクの変換
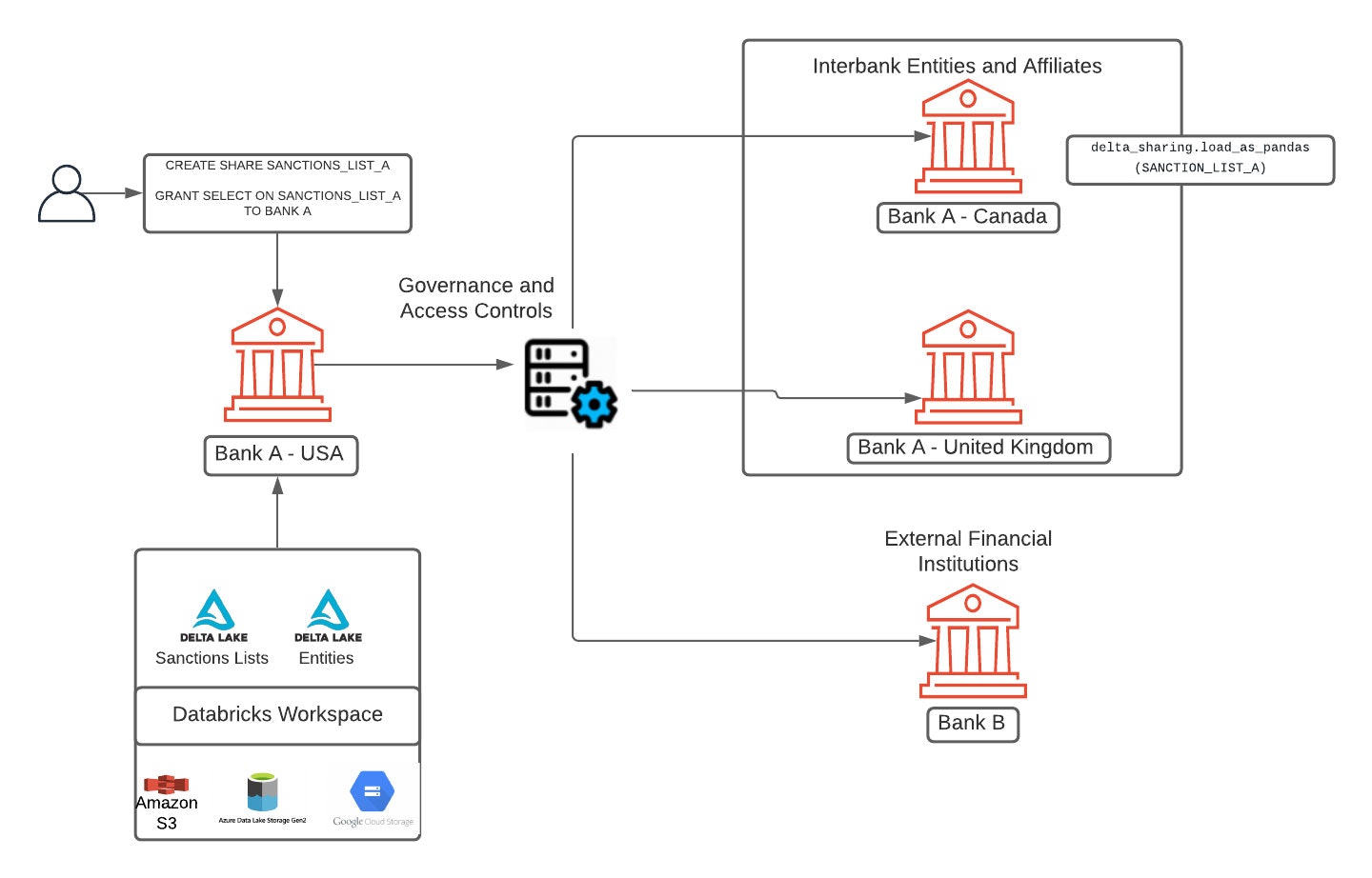
オープンバンキングの勃興により、APIを通じた顧客、金融機関、サードパーティのサービスプロバイダとのデータ共有によってより良い顧客体験を提供できるようになりました。この例の一つとして、EUの金融サービスをOpen Banking Europe規制の一部として変換するPayment Services Directive (PSD2)が挙げられます。結果として、金融機関は様々な銀行、サービスプロバイダーと顧客アカウント、トランザクションデータを含む様々なデータにアクセスできるようになりました。このトレンドは、米国愛国者法によるsection 314(b)の元でのFinCENからの最新のガイダンスによって、世界中の不正、金融犯罪に展開されています。これでカバーされている金融機関は他の金融機関と、潜在的なマネーロンダリングに関与している個人、エンティティ、組織などに関して情報を共有することができます。
情報共有の促進は透明性を改善し、米国の金融システムをマネーロンダリングや金融テロリズムから防御しますが、情報交換は適切なデータセキュリティ保護を用いたプロトコルを使用すべきです。情報共有のセキュリティ保護の問題を解決するために、Databricksはデータ共有のためのオープンかつセキュアなプロトコルであるDelta Sharingを最近発表しました。PandasやSparkのような慣れ親しんだオープンソースのAPIを用いて、データの提供者と消費者はセキュアかつオープンなプロトコルを用いてデータを共有することができ、FinCEN規制への準拠できるように、全てのデータトランザクションに対する完全な監査を維持することができます。
まとめ
レイクハウスアーキテクチャは、AMLアナリティクスにおけるアナリストを支援する最もスケーラブル、かつ多才なプラットフォームです。レイクハウスは、ファジーマッチングから画像解析、ビルトインダッシュボードによるBIまで幅広いユースケースをサポートし、これらの機能全てを活用することで、企業はプロプライエタリなAMLソリューションよりもTCOを削減することができます。Databricksにおける金融サービスチームは、金融サービスの領域で様々なビジネス上の問題に取り組んでおり、AMLのようなソリューションアクセラレータを通じてデータエンジニアリング、データサイエンスの専門家がDatabricksのジャーニーを始めることを支援しています。
AML開発戦略を加速するために、Databricks上で以下のノートブックを試してみてください。そして、同様なユースケースの支援が必要であれば、是非お問い合わせください。
- Introduction to graph theory for AML
- Introduction to computer vision for AML
- Introduction to entity resolution for AML