本日Photonのパブリックプレビューを発表できることを嬉しく思います。Photonは、劇的にクエリ性能を改善するためにC++で開発された、ネイティブのベクトライズドエンジンです。Photonのメリットを享受するに必要なことは、それをオンにするだけです。Photonは処理、リソースとシームレスに連携し、透過的にSQLやSparkのクエリーを高速化します。チューニングやユーザーの介入は必要ありません。
この新たなエンジンは、究極的には全てのワークロードを高速化するために設計されていますが、プレビュー期間中、ワークロードあたりのトータルコストを引き下げながらも、PhotonはSQLワークロードを高速化することにフォーカスしています。Photonを活用するためには二つの方法があります。
- Databricks SQLのデフォルトクエリーエンジンとなっています。
- Databricksクラスターの高性能ラインタイムの一部として。なお、Photon対応ランタイムはPhoton非対応のランタイムと異なる価格帯となっています。
本記事では、Photonを開発するに至った背景を議論し、Photonの内部でどのような処理が行われているのか、Databricks SQLと従来型のDatabricksクラスターでどのようにクエリー実行をモニタリングするのかを説明します。
Photonによる高速化
なぜ新たなクエリーエンジンを開発したのかと不思議に思うかもしれません。1000の言葉よりも一つの棒グラフが雄弁に語ります。データにストーリーを語らせましょう。
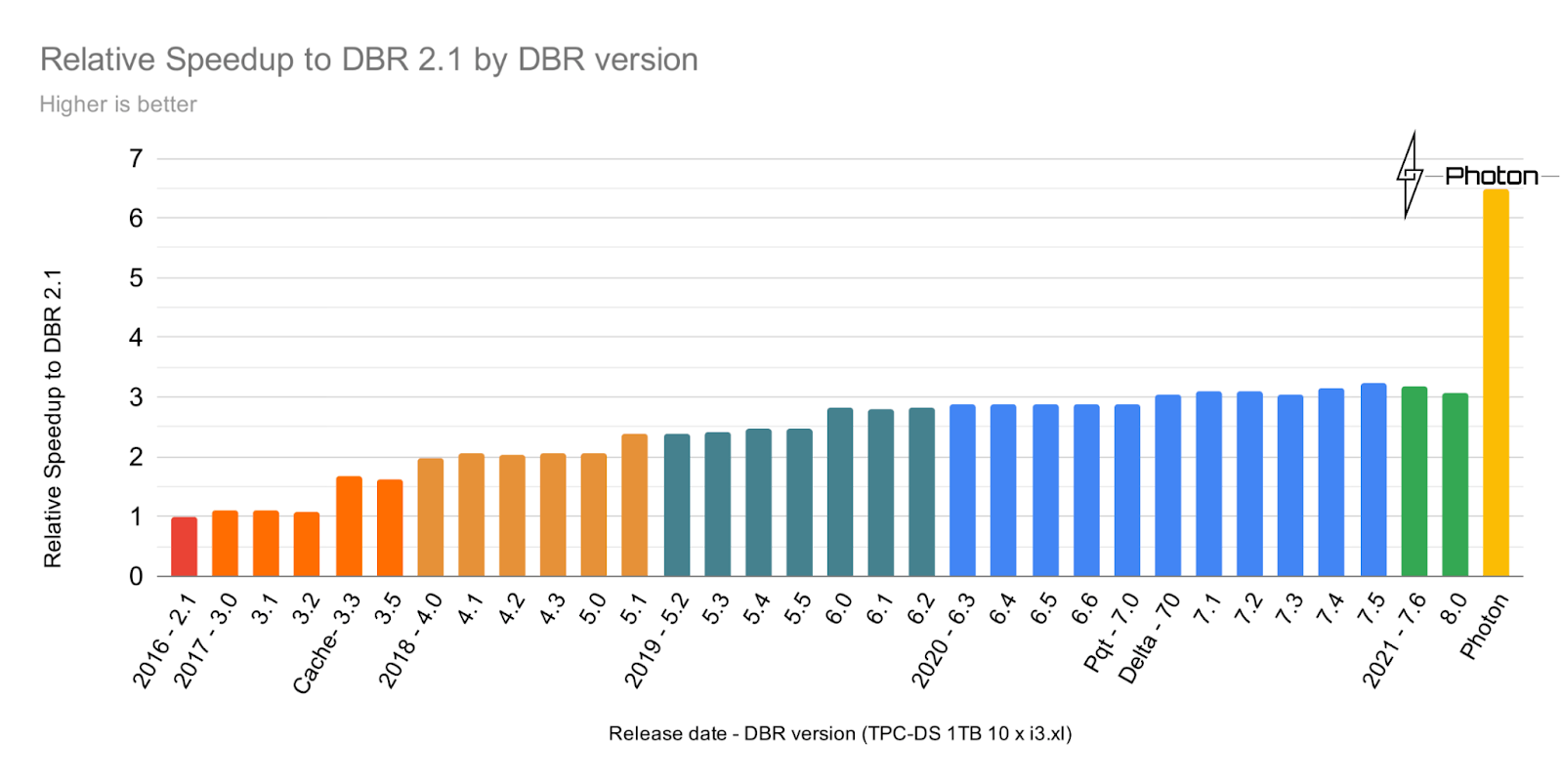
図1:TPC-DS 1TBを用いたバージョン2.1以降の相対的速度比較
TPC-DSベンチマーク(スケールファクターは1TB)を用いたパワーテストによるDatabricksランタイムパフォーマンスのチャートから分かるように、ここ数年間、性能は一定の割合で増加しています。しかし、Photonを導入することでクエリー性能が劇的に増加していることがわかります。PhotonはDatabricks Runtime 8.0の2倍高速です。これが我々がPhotonのポテンシャルに興奮している理由です。しかも、まだこれはスタートしたばかりなのです。Photonのロードマップには、さらに広いカバレッジとさらなる最適化が含まれています。
初期のPhotonプライベートプレビューを利用されたお客様は、以下のようなSQLワークロードにおいて2〜4倍の速度改善を体験されています。
- SQLベースのジョブ - SQL、Sparkデータフレームに対する大規模プロダクションジョブを高速化します。
- IoTユースケース - Sparkと従来型のDatabrikcsランタイムと比較して、Photonを活用することで時系列データの分析を高速化します。
- データプライバシー、コンプライアンス - Delta Lake、プロダクションジョブ、 Photonを活用することで、レコードを特定し削除するためにデータを複製することなしに、ペタバイト級のデータセットにクエリーを実行できます。
- Delta/Parquetへのデータロード - Photonのベクトル化されたI/Oによって、データエンジニアリングジョブの全体的なコストと実行時間を削減しつつ、Delta/Parquetへのデータロードを高速化します。
Photonの動作原理
PhotonはC++で記述されていますが、Databricksランタイム、Sparkと直接統合されています。これは、Photonを利用するためにコードの変更の必要がないことを意味しています。Photonがプラグインされた際の「クエリーのライフサイクル」を簡単にウォークスルーさせてください。
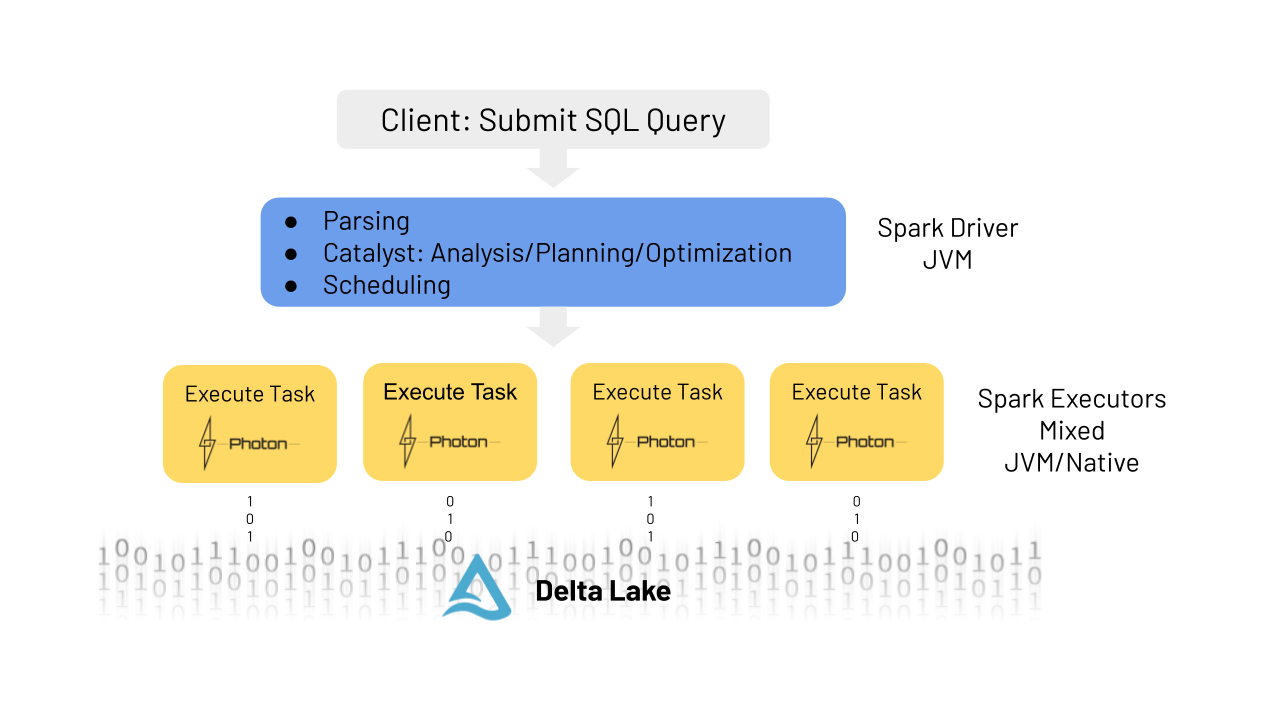
図2:Photonクエリーのライフサイクル
クライアントがSparkのドライバーノードにクエリーを送信した際、パースされ、Catalysオプティマイザーが分析を行います。そして、Photonが使用されていない場合同様、実行計画、最適化を行います。一つ違うのは、Photonがある場合、ランタイムのエンジンは物理的な実行計画を行わず、どの部分をPhotonに実行させるのかを決定します。Photonの実行計画においては、軽微な修正、例えばソートマージジョインをハッシュジョインに変更するといったことが行われるかもしれませんが、ジョインの順番を含む実行計画の全体的な構成は変更されません。まだ、PhotonはSparkのすべての機能をサポートしていませんので、一つのクエリーのある部分がPhotonで実行され、他の部分はSparkで実行されます。このハイブリッド実行モデルは、ユーザーに対して完全に透明性のあるものとなっています。
クエリープランは、データの特定のパーティションに対して処理を行うワーカーノードのスレッドで分散実行される、タスクと呼ばれる原子的なユニットに分割されます。このレベルにおいてPhotonは作業を行います。これは、Sparkの全体のステージのcodegenを、ネイティブなエンジン実装で置き換えるものだと考えることができます。PhotonライブラリがJVMにロードされ、SparkとPhotonはJNIを通じてやりとりを行い、データのポインターをオフヒープメモリーに渡します。また、Photonは、混成実行計画におけるスピル(溢れ)調整のためにSparkのメモリーマネージャと統合されています。SparkとPhotonの両方は、オフヒープメモリーを使用し、メモリーのプレッシャーに対応するように設定されています。
パブリックプレビューリリースにおいては、Photonは全てではありませんが多くのデータタイプ、オペレーター子、エクスプレッションをサポートしています。詳細はPhoton overviewを参照してください。
Photon実行の分析
現時点ではすべてのワークロード、オペレーターがサポートされていませんので、Photonを利用するのに適したワークロードをどう選択したらいいのか、実行計画でPhotonがどう利用されているのかを検知することに対して疑問に思うかもしれません。簡単にいうと、Photonの実行はボトムアップです。テーブルスキャンオペレーターから始まり、DAG(有向非巡回グラフ)へと移行し、サポートされていないオペレーションに達するまで続きます。この時点でオペレーションはPhotonの手を離れ、Photonなしで処理が行われます。
Databricks SQLのPhotonを利用している場合には、クエリーでPhotonがどのように使われているのかを容易に追跡できます。
- サイドバーのQuery Historyアイコンをクリックします。
- 分析したいクエリーを含むラインを選択します。
- クエリー詳細がポップアップしますので、Execution Detailsをクリックします。
- 下部にあるTask Time in Photonメトリックを参照します。
一般的には、Photonによるタスクの時間が大きいほど、Photonによる性能改善がされていることを意味します。
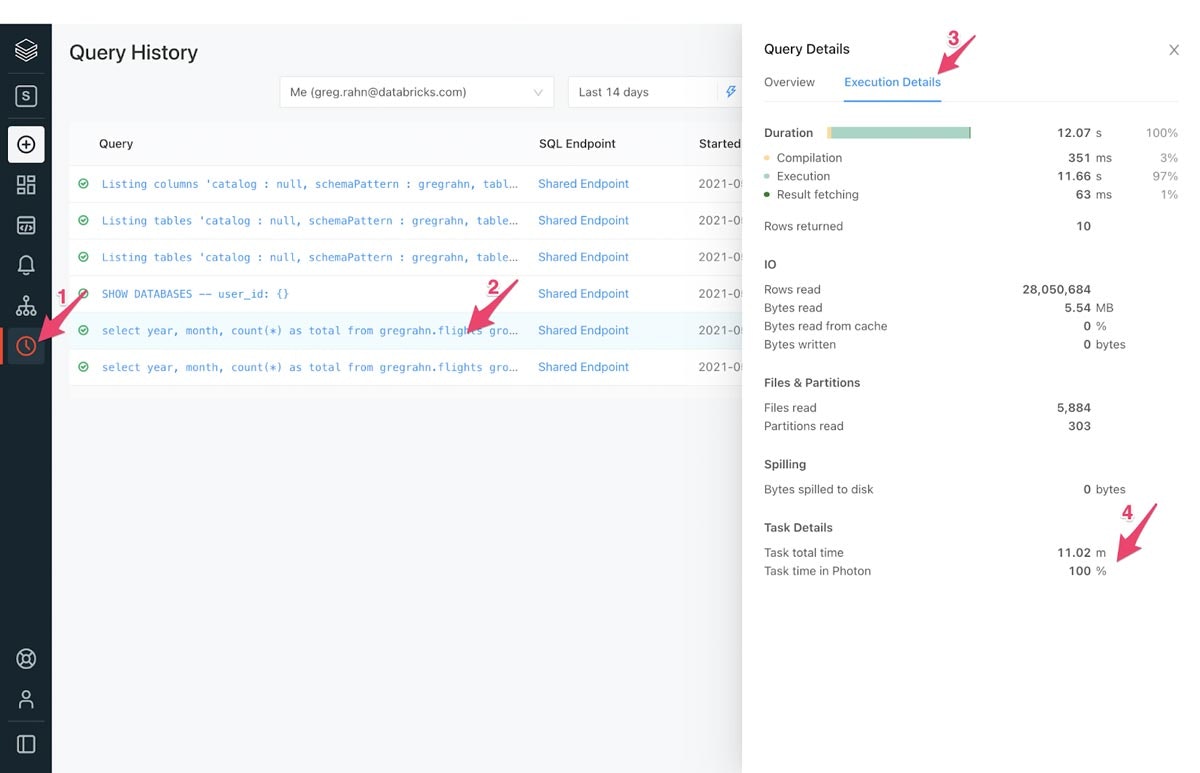
図3:Databricks SQLにおけるクエリー履歴の詳細
DatabricksクラスターのPhotonを使用している場合は、Spark UIでPhotonの動作を確認することができます。以下のスクリーンショットはクエリー詳細のDAGを示しています。DAGにおいて二箇所でPhotonを確認できます。まず、Photonオペレーターは、PhotonGroupingAggのようにPhotonの文字列から始まります。そして、非Photonのオペレーターとステージは青色であるのに対して、DAGのPhotonオペレーターとステージは桃色で表示されます。
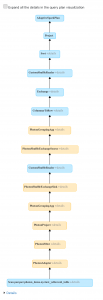
図4:Spark UIにおけるクエリー詳細DAG
ニューヨークタクシーデータの例で始めてみる
上で議論した通り、Photonを利用するには二つの方法があります。
- Databricks SQLエンドポイントにおいてはデフォルトでPhotonが有効化されています。SQLエンドポイントを作成し、クエリーを実行し、上の方法でPhotonがどのくらい性能を改善するのかを確認できます。
- (パブリックプレビューではAWSのみ)DatabricksクラスターでPhotonを利用するには、新規クラスターを作成する際にPhotonランタイムを選択します。非Photonのランタイムと同じインスタンスタイプであっても、Photonを使用する際には異なる価格帯となります。Photon対応のインスタンスとDBU消費に関しては、Databricks pricing page for AWSを参照ください。
Photonが有効化されたSQLエンドポイント、クラスターを作成すれば、ノートブックやSQLエディターでDatabricksのNYC Taxi datasetに対してクエリーを実行することができます。Databricks datasetsにはロード済みのデータがあり、アクセスすることができます。
まず、以下のSQLスニペットで既存データを参照するテーブルを新規に作成します。
CREATE DATABASE IF NOT EXISTS photon_demo;
CREATE TABLE photon_demo.nyctaxi_yellowcab_table
USING DELTA
OPTIONS (
path "/databricks-datasets/nyctaxi/tables/nyctaxi_yellow/"
);
以下のクエリーを実行してPhotonのスピードを楽しんでください!
SELECT vendor_id,
SUM(trip_distance) as SumTripDistance,
AVG(trip_distance) as AvgTripDistance
FROM photon_demo.nyctaxi_yellowcab_table
WHERE passenger_count IN (1, 2, 4)
GROUP BY vendor_id
ORDER BY vendor_id;
上記のクエリーのレスポンスタイムを、Photonと従来型のDatabricksランタイムとで比較しました。2台のi3.2xlargeエグゼキューターとi3.2xlargeのドライバーから構成されるウォームアップ済みのAWSクラスターで計測しています。以下が結果となります。
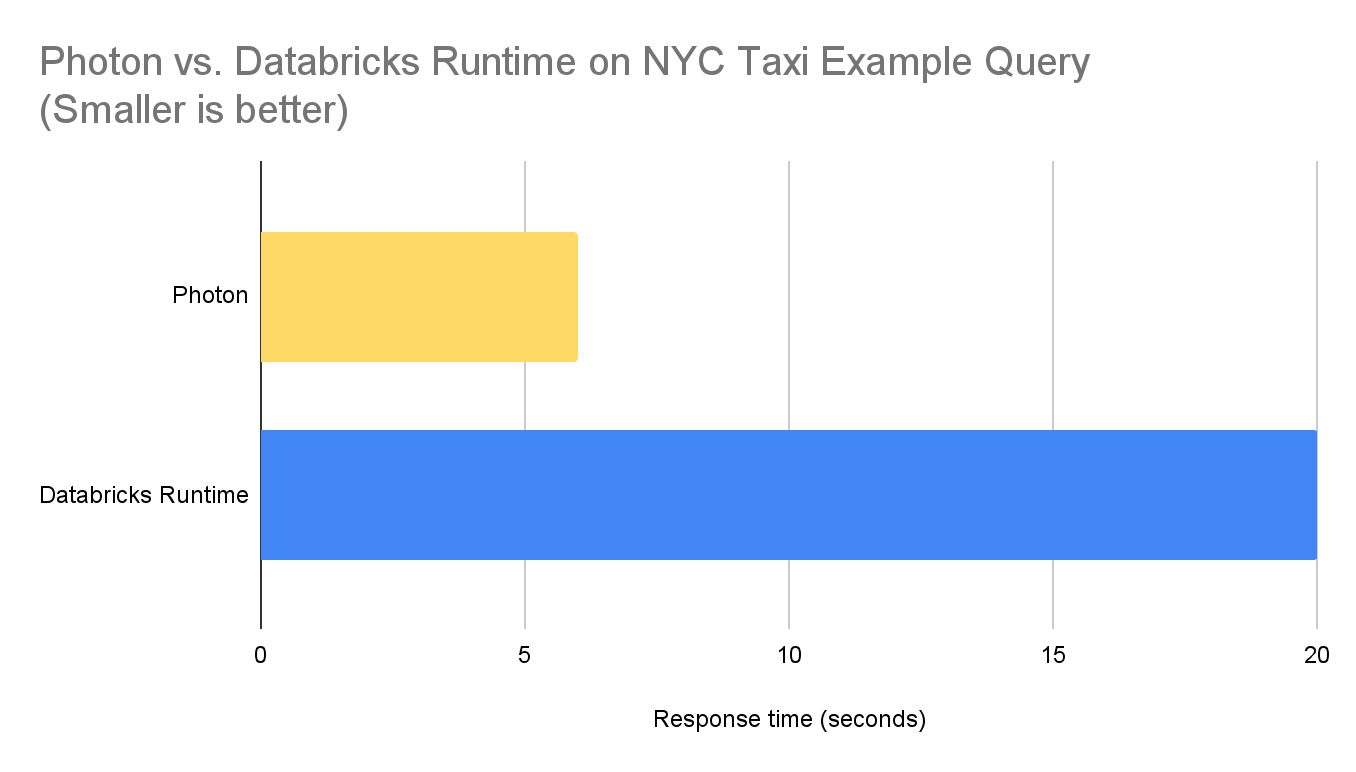
図5:NYCタクシーデータに対するクエリーにおけるPhoton対Databricksランタイム
Photonについてさらに学びたいのでしたら、Data+AIサミットのセッション:Radical speed for SQL Queries Photon Under the Hoodをご覧になってください。ここまでお読みいただきありがとうございます。皆様からのフィードバックを楽しみにしています!