Databricks Workflows Through Terraform - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Terraformを通じたワークフローのデプロイに関するブログシリーズのパート1です。TerraformのInfrastructure-as-Codeを用いてDatabricksでスクラッチから複雑なジョブやワークフローを作成する方法を説明します。
DatabricksワークフローのUIを通じてデータ加工プロセスをおーけストレートすることは簡単で直感的なことです。コードを選択し、計算資源を選び、タスク間の依存関係を定義し、ジョブやワークフローをスケジュールします。必要であれば、即座に起動することもできます。これが全てです。多くの場合、小規模なチームはワークフローを用いてデータエンジニアリングパイプラインや機械学習パイプラインを構築するスピードに驚くことになります。
しかし、ある日、これらの小規模なチームは成長します。そして、この成長によって、彼らのオーケストレーションも進化する必要が出てきます。彼らが遭遇する新たなシナリオや課題のサンプルを示します:
-
継続的インテグレーション / 継続的デリバリー (CI/CD)
- あるDatabricks環境から別の環境にどのようにジョブを複製するのか?
- ワークフローが同期され続けていることをどのように保障するのか?特にこれはディザスターリカバリーのシナリオで重要となります。
- ワークフローの設定が変更された際、全ての環境のレプリカに対して変更をどのようにロールアウトするのか?
-
アプリケーション開発とメンテナンス
- 開発サイクルを通じて、ワークフローをどのようにバージョン管理し、どのように変更を追跡するのか?
- どのようにワークフローをテンプレートとして活用し、それからさらに複雑なワークフローをフォークするのか?
- どのようにワークフローをモジュール化し、さまざまなチームが自身のパーツを持てるようにできるのか?
これらの問題に対するソリューションは、ワークフローの設定を 'コード' に変換し、リポジトリを用いてバージョン管理することをベースとしています。開発者は新たなワークフローを生成(あるいは既存のワークフローを更新)するために、リポジトリからフォークやブランチを作成し、CI/CDオートメーションを通じてデプロイします。十分にモジュール化されたら、異なるチームが異なるワークフローモジュールで同時に作業できるようになります。魅力的に聞こえると思いますが、実際に Workflow as Code はどのようなものなのでしょうか?これを理解するために、Databricksワークフローの可動パーツを最初に見ていきましょう。
歴史的にジョブはDatabricksで広く利用されていた、すぐに利用できるオーケストレーションエンジンであったことに注意してください。(最近ローンチされた)ワークフローの機能は、ジョブの機能をさらに前進させ、オーケストレーションツールのファミリーに組み込みました。ワークフローのもとでは、ジョブ、Delta Live Tablesパイプラインのオーケストレーション、高度な通知機能、実行履歴分析のためのダッシュボード、急速に追加される一連の機能を活用することができます。過去の機能との互換性のため、この記事ではワークフローとジョブというキーワードは同じように使用されます。
Databricksワークフロー
以下に、依存関係を持つ複数のタスクから構成される典型的なDatabricksワークフローの例を示します。
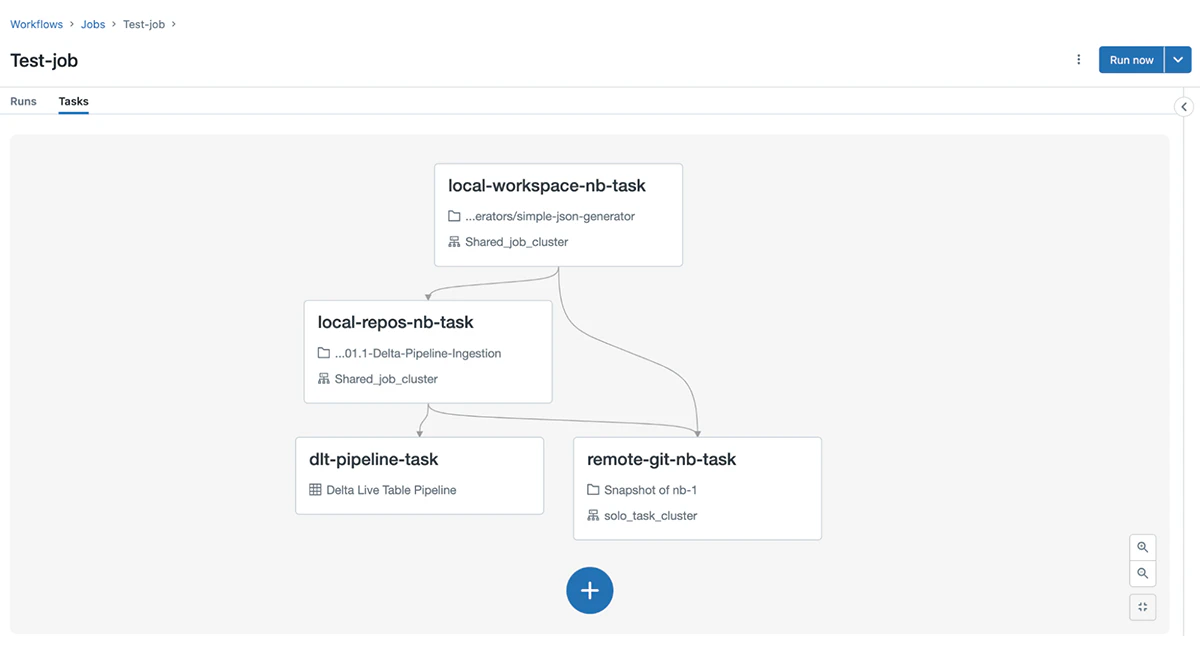
図1. 複数タスクを持つワークフロー
Tasksタブはタスク間のリレーションシップを非常にエレガントに表示しますが、現場ではさまざまな調整やプロビジョンが発生します。これらの調整やプロビジョンを効率的に管理する必要性は、大規模な作業を数多くのチームと行う企業にとって非常に高まっています。この課題の度合いを理解するためには、内部でワークフローがどのようになっているのかを理解する必要があります。
ワークフローはビジネスロジックを実装する1つ以上のタスクから構成されています。それぞれのタスクはコードにアクセスする必要があります。このコードは計算クラスター上で実行されます。次に、クラスターはDatabricksランタイム、インスタンスタイプ、インストールされるライブラリに関する詳細情報を必要とします。タスクが失敗すると何が起きるのでしょうか?誰に通知されるのでしょうか?リトライ機能を実装しなくてはならないのでしょうか?さらに、ジョブにはどのように起動されるのかをDatabricksに指示するためのメタデータが必要となります。手動でキックスタートするか、外部トリガー(時間ベースやイベントベース)で起動することができます。また、どれだけの同時実行を許容するのか、管理できる人に関する権限設定を行う必要があります。
全体としてジョブには多数の依存関係があり、スタートするには数多くの指示を行う必要があります。以下の一覧では、ワークフロー / ジョブに指定する必要がある様々なリソースと指示を示しています。

図2. ワークフロー依存関係のチャート
ワークフローのUIはこれらの指示を行うためのビジュアルかつ解釈が容易な手段を提供します。しかし多くのチームでは、バージョンを管理し、複数の環境にデプロイできるようなワークフローのコードバージョンを必要とすることでしょう。また、このコードをモジュール化し、そのコンポーネントが互いに独立して進化できるようにしたいと考えることでしょう。例えば、my_preferred_job_cluster_specificationsというような特定タイプのクラスターを作成するためのモジューつを維持したいと考えたとします。ジョブをプロビジョンする際は、毎回明示的にクラスター設定のメタデータを指定するのではなく、この仕様オブジェクトへのリファレンスを指定するだけで良くなります。
ソリューションは何でしょうか?Infrastructure-as-code (IaC)とTerraformにようこそ。
TerraformとIaC
通常、インフラストラクチャはコンソールやUIを通じてプロビジョンされます。しかし、記述された一連の指示を通じてインフラストラクチャがデプロイされると、このパラダイムは Infrastructure-as-code (IaC) と呼ばれるものになります。HashicorpのTerraformは、スケーラブルな方法でIaCを実現するための非常に人気のあるツールです。開発者やインフラエンジニアは、実行されることでインフラストラクチャを生成するコードを通じて、希望するインフラストラクチャの状態を表現できるようになります。すると、このツールは状態ファイルを保持することで、現在のインフラストラクチャの状態のリマインダーとなります。インフラストラクチャを変更するために新たなIaCの指示がTerraformに与えられると、Terraformは保持されている 現在の状態と希望する状態を比較し、変更点のみをデプロイします。このインクリメンタルなサイクルは以下の図でよりわかりやすく説明されています。
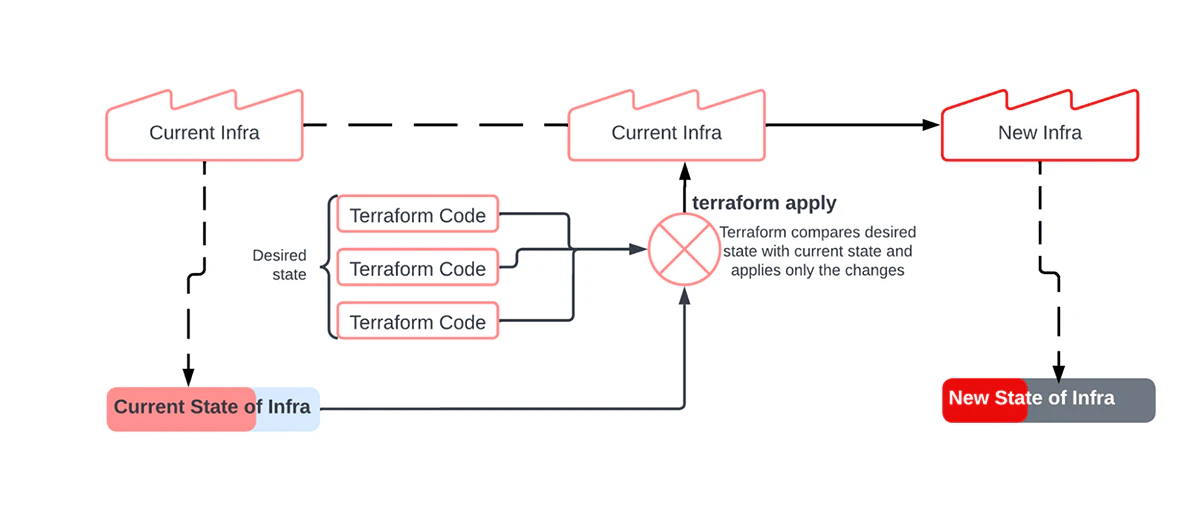
図3. Terraformの状態フローチャート
Databricksにおけるインフラ - 鳥か飛行機か?
クラスター、ノートブック、ワークスペースといったDatabricksの文脈においては、実際インフラストラクチャはどのような意味を持つのでしょうか?ある意味、それが全てであり、それ以上のものでもあります。ユーザー、ノートブック、ジョブ、クラスター、ワークスペース、リポジトリ、シークレットなどのDatabricksオブジェクトは、Terraformの用語においてはすべてインフラストラクチャとして参照されます。これらに対するより良い用語はリソースです。Terraform Databricksプロバイダーは、Databricksにこれらのリソースをプロビジョンするためのテンプレートを提供するプラグインです。Databricks自身のデプロイからスタートし、このプラグインを通じて事実上全てのDatabricksのリソースをプロビジョン、管理することが可能です。以下のshared_autoscalingというリソースは、HashiCorp Language (HCL) (またはTerraform language)と呼ばれる言語で指定されたDatabricksクラスターリソースのサンプルです。この記事では、AWSにインフラストラクチャをプロビジョンするためのコードスニペットを示しています。
data "databricks_node_type" "smallest" {
local_disk = true
}
data "databricks_spark_version" "latest_lts" {
long_term_support = true
}
resource "databricks_cluster" "shared_autoscaling" {
cluster_name = "Shared Autoscaling"
spark_version = data.databricks_spark_version.latest_lts.id
node_type_id = data.databricks_node_type.smallest.id
autotermination_minutes = 20
autoscale {
min_workers = 1
max_workers = 50
}
}
これら全てのリソースに対する完全なリストやドキュメントに関しては、入力引数や出力を含めTerraform Provider registryから取得することができます。以下の図では、AWS、Azure、GCPにおけるDatabricksのTerraformリソースの現状をマッピングしています。
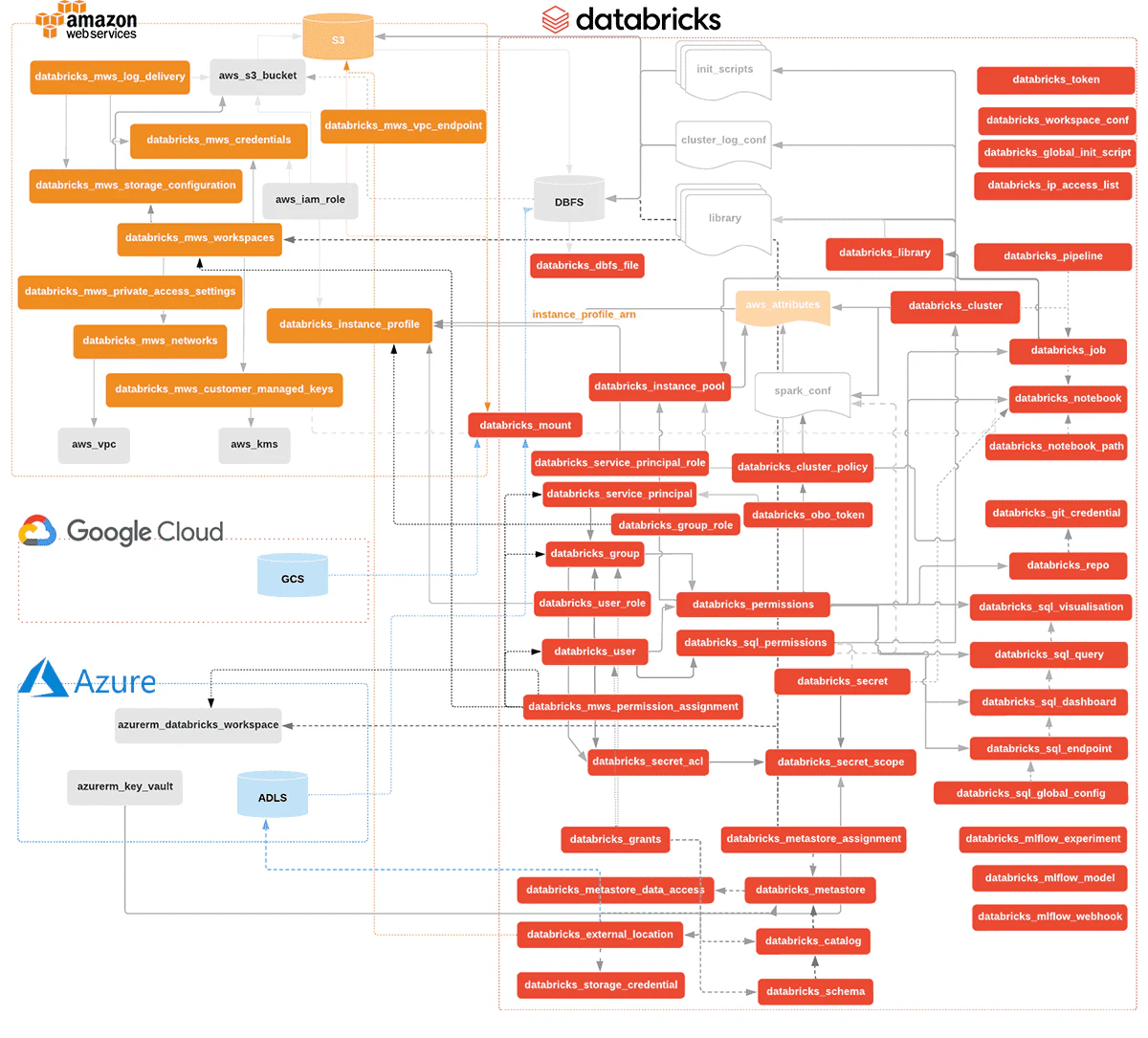
図4. Terraform向けDatabricksプロバイダー
Terraformを通じたマルチタスクジョブリソースのデプロイ
マルチタスクジョブ(MTJ)作成に関するドキュメントはTerraformのdatabricks_job resourceページで参照することができます。実際、プロダクションのジョブにおける可動パーツは多数存在しており、これらは必要なものです。それでは、マルチタスクジョブの作成プロセスにディープダイブしてみましょう。以下の図では、このようなジョブのキーコンポーネントのいくつかを列挙しています:
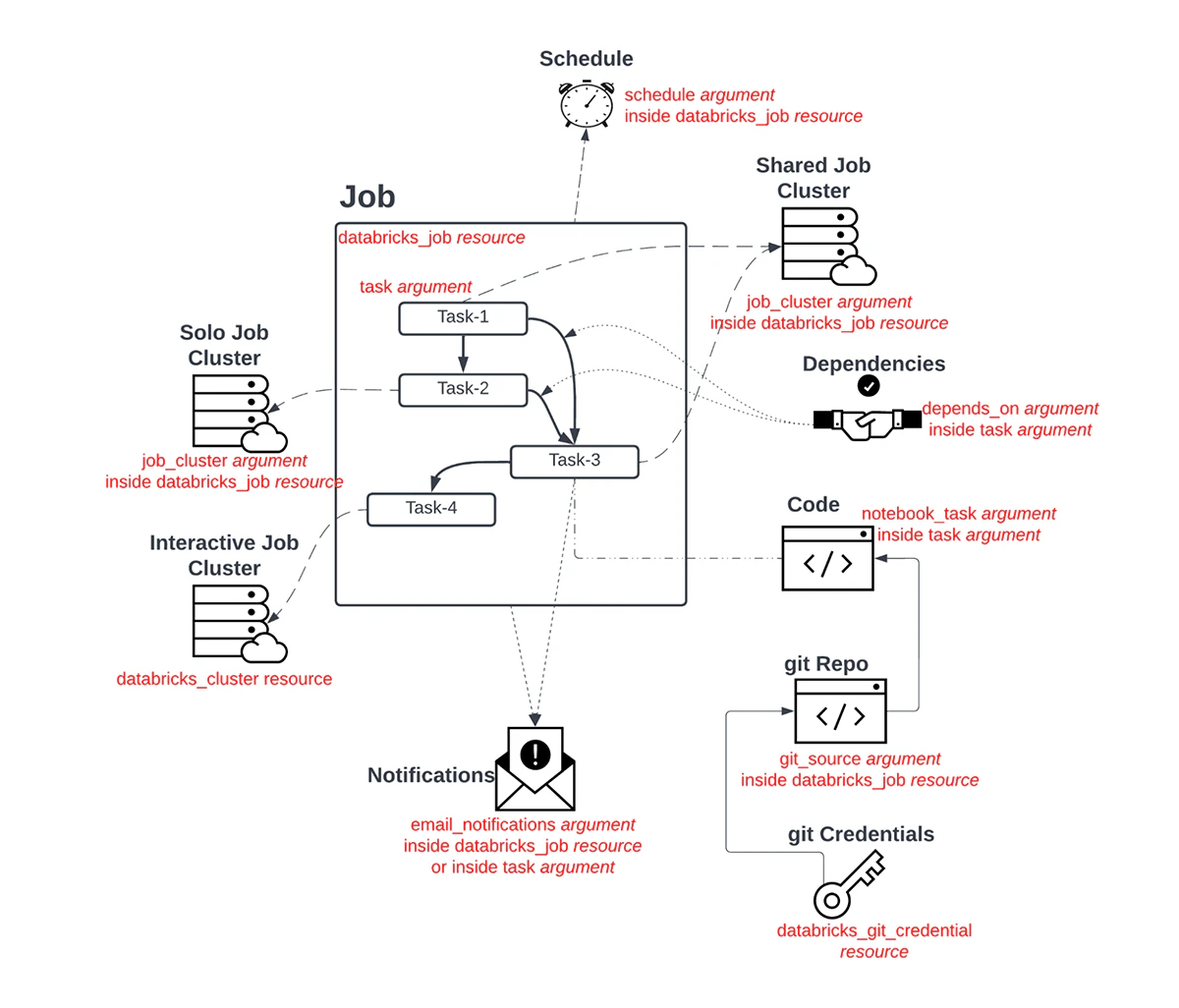
図5. マルチタスクジョブ / ワークフローのTerraform解剖学
これらのコンポーネントは3つのステップに展開され、デプロイされます:
- プロバイダーのセットアップとDatabricksの認証。
- ノートブック、リポジトリ、インタラクティブクラスター、Git資格情報、initスクリプトのような全ての上流のリソース依存関係の解決。
- 一時的なジョブクラスター、タスク、依存タスク、通知の詳細、スケジュール、リトライポリシーなどのジョブのコンポーネントの作成。
Databricksによるセットアップと認証
Terraform Databricksプロバイダーを使う最初のステップは、プロジェクトのための作業ディレクトリにプロバイダーのバイナリーを追加することです。このためには、以下の内容(release historyからお好きなプロバイダーバージョンを選択してください)を含む<my_provider>.tfファイルを作業ディレクトリに作成し、コマンドterraform initを実行します:
terraform {
required_providers {
databricks = {
source = "databricks/databricks"
version = "1.6.1" # provider version
}
}
}
TerraformがDatabricksワークスペースの認証を受けてインフラをプロビジョンできるように、作業用フォルダに作成される必要があるトークンの詳細をファイル<my-databricks-token>.tfに記述します。
provider "databricks" {
host = "https://my-databricks-workspace.cloud.databricks.com"
token = "my-databricks-api-token"
}
DatabricksのAPIトークンの作成方法に関しては、こちらのドキュメントを参照ください。他の認証の設定方法に関しては、こちらを参照ください。平文で資格情報をハードコードすることは推奨されないことに注意してください。これはデモ目的であるため、こうしているに過ぎません。暗号化をサポートするTerraformバックエンドを使用することを強くお勧めします。環境変数、~/.databrickscfgファイル、暗号化された.tfvarsファイル、お好きなシークレットストア(Hashicorp Vault、AWS Secrets Manager、AWS Param Store、Azure Key Vault)を使用することができます。
上流のリソース依存関係のデプロイ
Databricksプロバイダーのバイナリをダウンロードし、トークンファイルを設定することで、Terraformはトークンファイルに記述されているワークスペースにリソースをデプロイできるようになります。以下のように、ジョブが依存する全てのリソースをプロビジョンすることが重要となります:
- ジョブに含まれるタスクがインタラクティブクラスターを使用している場合、最初にクラスターをデプロイする必要があります。これによって、ジョブのTerraformコードはインタラクティブクラスターのidを取得し、引数
existing_cluster_idに引き渡せるようになります。
data "databricks_current_user" "me" {}
data "databricks_spark_version" "latest" {}
data "databricks_spark_version" "latest_lts" {
long_term_support = true
}
data "databricks_node_type" "smallest" {
local_disk = true
}
# create interactive cluster
resource "databricks_cluster" "my_interactive_cluster" {
cluster_name = "my_favorite_interactive_cluster"
spark_version = data.databricks_spark_version.latest_lts.id
node_type_id = data.databricks_node_type.smallest.id
autotermination_minutes = 20
autoscale {
min_workers = 1
max_workers = 2
}
}
# create a multi-task job
resource "databricks_job" "my_mtj" {
name = "Job with multiple tasks"
task {
# arguments to create a task
# reference the pre-created cluster here
existing_cluster_id = "${databricks_cluster.my_interactive_cluster.id}"
}
}
- ジョブのタスクがワークスペースやDatabricks Repoのコードを使用している場合、最初にノートブックやRepoをデプロイする必要があります。Repoやノートブックは、IAM(Identity and Access Management)やGit資格情報などの上流の依存関係を持っている場合があることに注意してください。事前にこれらをプロビジョンしてください。
data "databricks_current_user" "me" { }
# notebook will be copied from local path
# and provisioned in the path provided
# inside Databricks Workspace
resource "databricks_notebook" "my_notebook" {
source = "${path.module}/my_notebook.py"
path = "${data.databricks_current_user.me.home}/AA/BB/CC"
}
- クラスターポリシー 、インスタンスプール、Delta Live Tablesパイプラインは上流のリソース依存関係です。これらを使用している場合には、事前に解決しておく必要があります。
ジョブコンポーネントのデプロイ
全ての上流の依存関係を設定したら、ジョブのリソースをデプロイする準備ができたことになります。databricks_job resourceの設定は、Terraformレジストリで指示されている方法で行うことができます。マルチタスクジョブが設定されたサンプルのいくつかは、こちらのgithub repoでアクセスすることができます。先に進めて、ジョブのTerraformテンプレートを作成してみましょう。完了すると、ワークフローは以下のような図を構成するはずです。
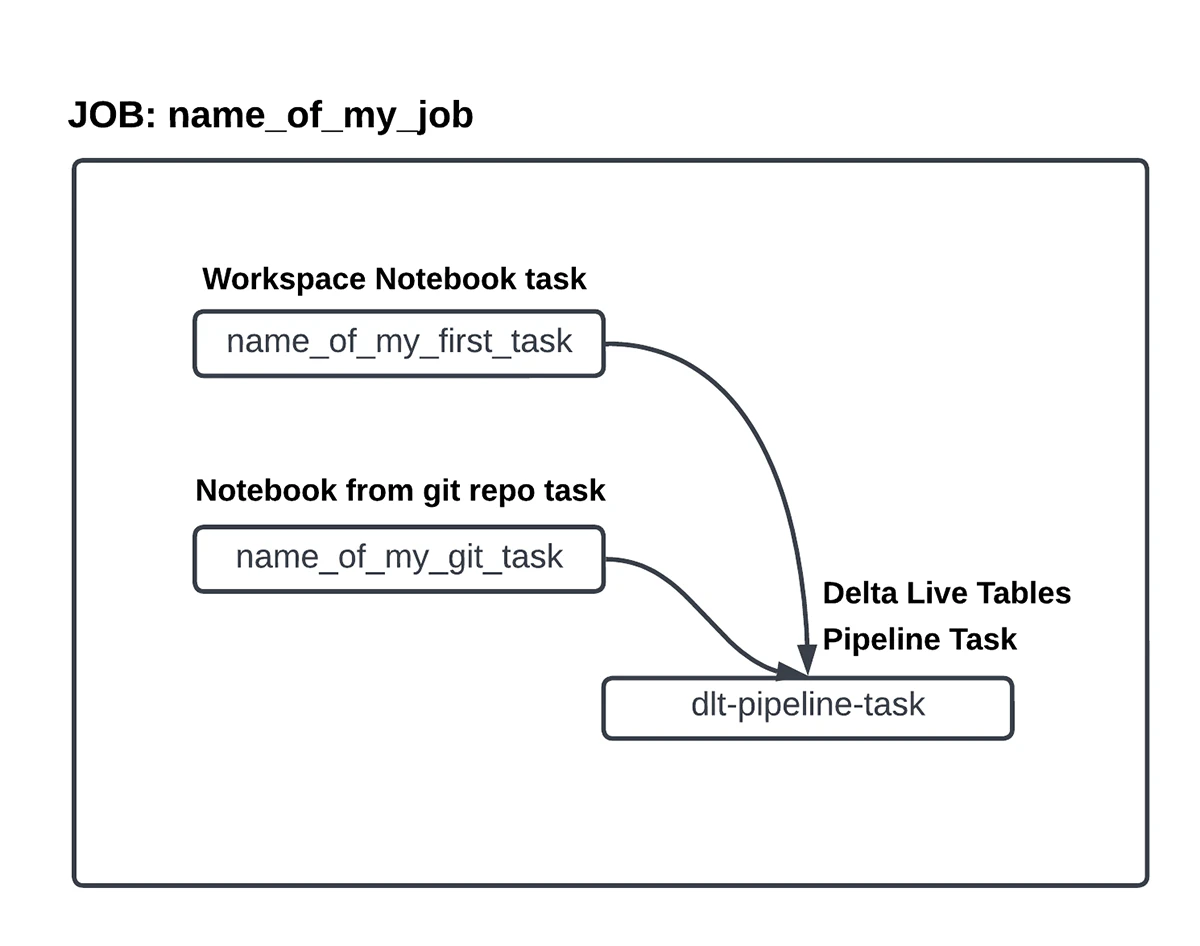
図6. ターゲットのワークフローの状態
databricks_jobリソースのコンテナを作成するところからスタートします。スケジュール、最大同時実行数のようなジョブレベルのパラメーターがどのように設定されているのかに注意してください。
resource "databricks_job" "name_of_my_job" {
name = "my_multi_task_job"
max_concurrent_runs = 1
# job schedule
schedule {
quartz_cron_expression = "0 0 0 ? 1/1 * *" # cron schedule of job
timezone_id = "UTC"
}
# notifications at job level
email_notifications {
on_success = ["111@abc.com", "222@abc.com"]
on_start = ["222@abc.com"]
on_failure = ["my_distribution_list@abc.com"]
}
# reference to git repo. Add the git credential separately
# through a databricks_git_credential resource
git_source {
url = "https://github.com/udaysat-db/test-repo.git"
provider = "gitHub"
branch = "main"
}
# Create blocks for Jobs Clusters here #
# Create blocks for Tasks here #
}
次のステップでは、このジョブの寿命に紐づけられた一時的なクラスターであるジョブクラスターを作成します。一方、インタラクティブクラスターは事前に作成され、ジョブの範囲の外でリソースが共有されます。
# this ephemeral cluster can be shared among tasks
# stack as many job_cluster blocks as you need
job_cluster {
new_cluster {
spark_version = "10.4.x-scala2.12"
spark_env_vars = {
PYSPARK_PYTHON = "/databricks/python3/bin/python3"
}
num_workers = 8
data_security_mode = "NONE"
aws_attributes {
zone_id = "us-west-2a"
spot_bid_price_percent = 100
first_on_demand = 1
availability = "SPOT_WITH_FALLBACK"
}
}
job_cluster_key = "Shared_job_cluster"
}
それでは、タスクブロックを作成しましょう。こちらは、ワークスペースのノートブックと上で定義した共有ジョブクラスターを使用するタスクです。タスクへの入力引数を提供するbase_parametersの使い方に注意してください。
task {
task_key = "name_of_my_first_task" # this task depends on nothing
notebook_task {
notebook_path = "path/to/notebook/in/Databricks/Workspace" # workspace notebook
}
job_cluster_key = "Shared_job_cluster" # use ephemeral cluster created above
# input parameters passed into the task
base_parameters = {
my_bool = "True"
my_number = "1"
my_text = "hello"
}
# notifications at task level
email_notifications {
on_success = ["111@abc.com", "222@abc.com"]
on_start = ["222@abc.com"]
on_failure = ["my_distribution_list@abc.com"]
}
}
こちらは(Jobコンテナで定義されている)リモートgitリポジトリをポイントするタスクです。計算資源に関しては、このタスクはインタラクティブクラスターを使用します。pipライブラリとタイムアウト、リトライの設定の使用法に注意してください。
task {
task_key = "name_of_my_git_task" # reference git repo code
notebook_task {
notebook_path = "nb-1.py" # relative to git root
}
existing_cluster_id = "id_of_my_interactive_cluster" # use a pre existing cluster
# you can stack multiple depends_on blocks
depends_on {
task_key = "name_of_my_first_task"
}
# libraries needed
library {
pypi {
package = "faker"
}
}
# timeout and retries
timeout_seconds = 1000
min_retry_interval_millis = 900000
max_retries = 1
}
最後に、こちらがDelta Live Tablesパイプラインを使用するタスクブロックとなります。このパイプラインは別に作成する必要があります。
task {
task_key = "dlt-pipeline-task"
pipeline_task {
pipeline_id = "id_of_my_dlt_pipeline"
}
# depends on multiple tasks
depends_on {
task_key = "name_of_my_first_task"
}
depends_on {
task_key = "name_of_my_git_task"
}
}
タスクタイプ、クラスタータイプ、その他の属性の順序や組み合わせは無数です。しかし、上述のパターンがこれらのビルディングブロックを用いて複雑なマルチタスクジョブ/ワークフローをどのように合理的に構成するのかの助けとなれば幸いです。Terraformのコードを記述したら、以下のコマンドを用いてリソースを操作することができます。
| コマンド | 説明 |
|---|---|
| terraform init | 他のコマンドを使用するために作業ディレクトリを準備します。 |
| terraform validate | 設定が妥当かどうかをチェックします。 |
| terraform plan | 現在の設定に必要な変更点を表示します。 |
| terraform apply | インフラストラクチャを作成、更新します。 |
| terraform destroy | 以前作成したインフラストラクチャを破壊します。 |
まとめ
TerraformはDatabricksにリソースをデプロイするパワフルなIaCツールです。マルチタスクワークフローを組み立てるためにこれらの数多くのリソースをつなぎ合わせることで、ジョブ、タスク、クラスターのモジュール化されたテンプレートを作成する際に非常に大きな柔軟性をチームに提供します。これらは、バージョン管理、共有、再利用が可能で、企業内でこれらのテンプレートをクイックにデプロイすることができます。この記事で説明したように、スクラッチからワークフローを作成することはTerraformに慣れた開発者にとっては分かりやすいものですが、データエンジニアやデータサイエンティストは依然としてUIでワークフローを作成することを好むかもしれません。このようなシナリオにおいては、Terraform開発者はすでに作成ずみのワークフローを継承することができます。継承されたワークフローとはどのようなものでしょうか?これをさらに再利用、進化させることが可能なのでしょうか?このシリーズの次の記事でこれらのシナリオを議論しましょう。
使い始める
Learn Terraform
Databricks Terraformプロバイダー