Introducing Apache Spark™ 3.2 - The Databricks Blogの翻訳です。
Databricksランタイム 10.0でご利用いただけます。
Databricksランタイム 10.0の一部としてDatabricks上でApache Spark™ 3.2が利用可能になることを発表できることを嬉しく思います。Spark 3.2のリリースに多大なる貢献をしたApache Sparkコミュニティに感謝の意を評します。
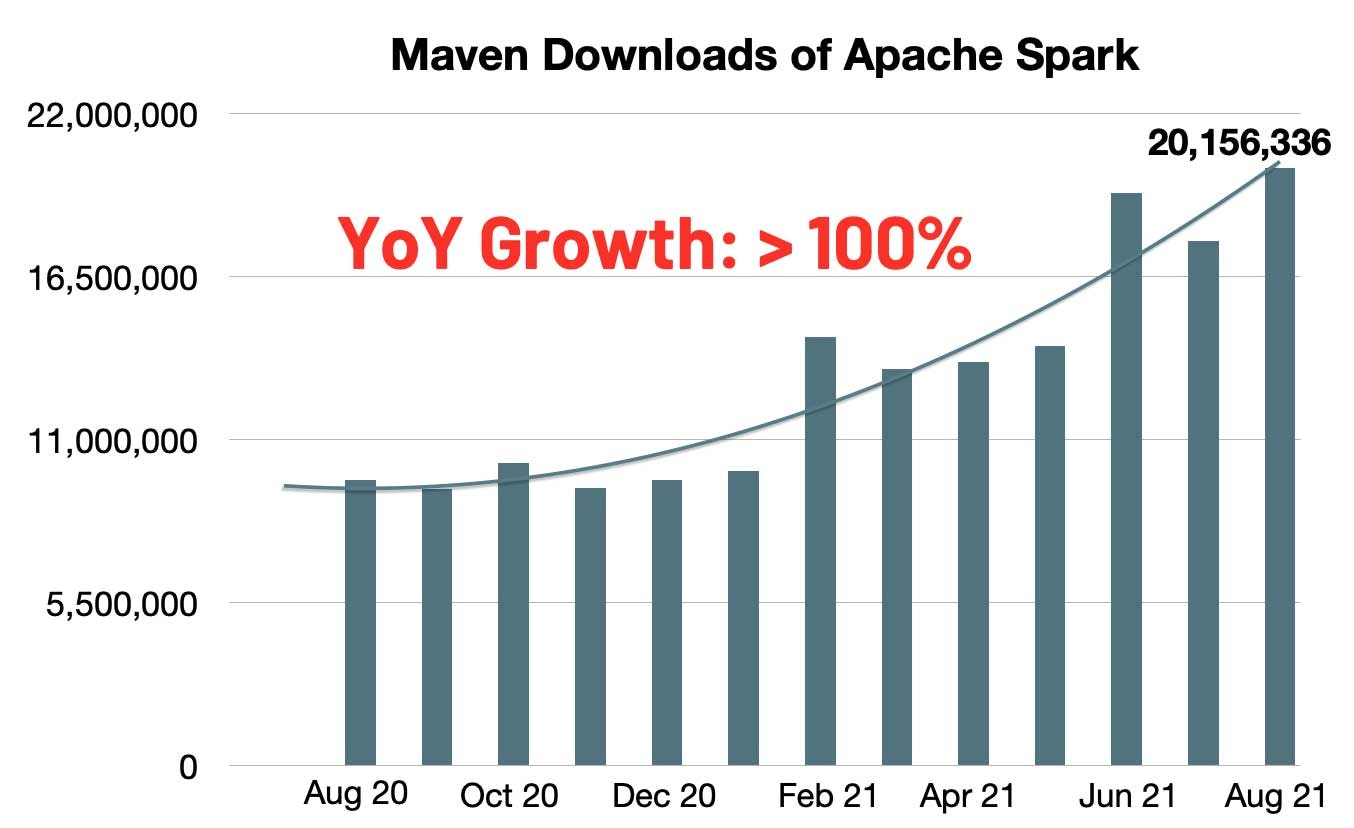
Sparkに対するMavenの月間ダウンロード数は急激に増加し、2000万ダウンロードに達しています。年ごとの成長率は、昨年と比較して2倍の月間ダウンロード数を示しています。Sparkは、シングルノードマシン、あるいはクラスター上でのデータエンジニアリング、データサイエンス、機械学習を実行する際に最も幅広く活用されているエンジンとなりました。
Sparkをさらに統合し、シンプルかつ高速、スケーラブルなものにするというゴールに向けて、Spark 3.2では以下の機能でそのスコープを拡張しました。
- Apache Sparkへのpandas APIの導入: 小規模データAPIとビッグデータAPIを統合します。(詳細はこちらを参照ください)
- ANSI SQL互換モードの完成: SQLワークロードの移行をシンプルにします。
- アダプティブクエリーエンジンをプロダクションに: Spark SQLの実行性能を改善します。
- RockDBステートストアの導入: 状態処理をよりスケーラブルにします。
この記事では、ハイレベルでの機能と改善を要約します。今後投稿される記事では、これらの機能にディープダイブする予定ですので楽しみにしていてください。Sparkコンポーネントにおける主要機能の包括的なリストと、解決されたJIRAチケットに関しては、Apache Spark 3.2.0のリリースノートをご覧ください。
小規模データAPIとビッグデータAPIの統合
PythonはSparkで最も使用されている言語です。SparkをよりPythonicにするために、Project Zen(Project Zen: Making Data Science Easier in PySparkもご覧ください)の一環で、pandas APIがSparkに導入されました。今では、pandasの既存ユーザーは1行の変更のみでpandasアプリ絵ケーションをスケールさせることができます。以下に示すように、Sparkエンジンにおける洗練された最適化により、シングルノードマシン[左]、マルチノードのSparkクラスター「右」の両方で性能が劇的に改善されます。
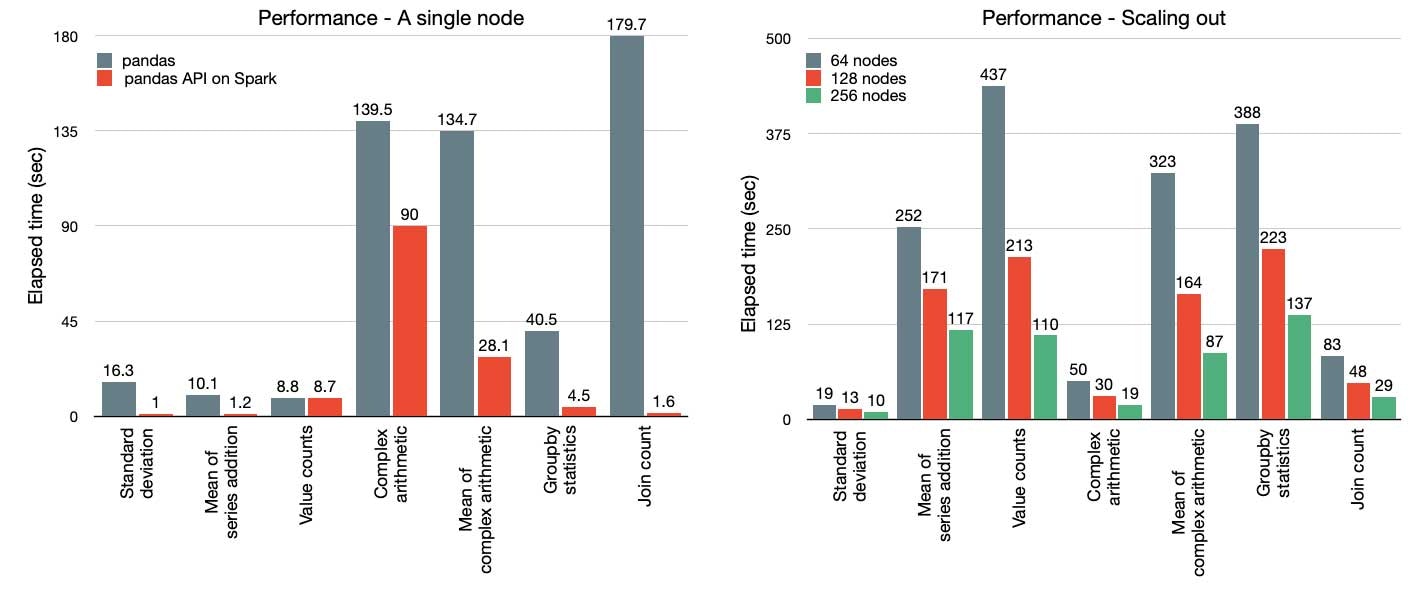
図: pandas対Sparkのpandas API
加えて、Pythonユーザーは、SQLに対するクエリー、ストリーミング処理、スケーラブルな機械学習(ML)などSparkによって提供される統合分析機能をシームレスに活用することができます。また、新たなpandas APIは、plotlyバックエンドによって提供されるインタラクティブなデータの可視化機能も提供します。
詳細に関しては、ブログ記事「Apache Spark™ 3.2におけるPandas APIのサポート」をご覧ください。
SQLマイグレーションをシンプルに
さらなるANSI SQL機能(ラテラルジョインのサポートなど)が追加されました。1年以上の開発を経て、このリリースでANSI SQLモードがGAとなります。挙動を損なうような大規模な変化を避けるために、spark.sql.ansi.enabledモードはデフォルトでは無効化されたままとなります。ANSIモードには、以下に示すような主要な挙動の変更が含まれます。
- SQLオペレーター/関数への入力が不正な際、nullの結果でサイレントに無視するのではなくランタイムエラーをスローします(SPARK-33275)。例えば、計算オペレーションにおけるinteger値のオーバーフローエラー、文字列から数値/タイムスタンプ型にキャストする際のパーシングエラーです。
- 型強制の文法ルールを標準化(SPARK-34246)。新たなルールは特定のデータ型の値がデータ型の優先度リストに基づいて暗黙的に別のデータ型にプロモートできるかどうかを定義しており、デフォルトの非ANSIモードよりも直感的なものとなっています。
- 新たな明示的なキャスト文法ルール(SPARK-33354)。Sparkクエリーに不正な型キャスト(例: date/timestamp型をnumeric型へのキャスト)が含まれる場合、コンパイル時エラーがスローされ、ユーザーに不正な変換をしていることを知らせます。
このリリースには、まだ完了していませんが新たなイニシアチブが含まれています。例えば、Sparkにおける例外メッセージの標準化(SPARK-33539)、ANSIのインターバル型の導入(SPARK-27790)、相関サブクエリの改善(SPARK-35553)などが挙げられます。
Spark SQLの実行速度の向上
このリリースでAdaptive Query Execution (AQE)はデフォルトで有効化されます(SPARK-33679)。パフォーマンスを改善するために、AQEは実行時に収集される正確な統計情報に基づき、クエリー実行計画を再度最適化することができます。ビッグデータにおいては、統計情報の維持、事前収集のコストは大きいものになります。オプティマイザがどれだけ先進的なものであったとしても、正確な統計情報の欠如は非効率的な計画を作り出すことになります。このリリースでは、joinの戦略、skew joinとシャッフルパーティションの結合を再度最適化するために、AQEは全ての既存のクエリー最適化技術(例: Dynamic Partition Pruning)との互換性を担保します。
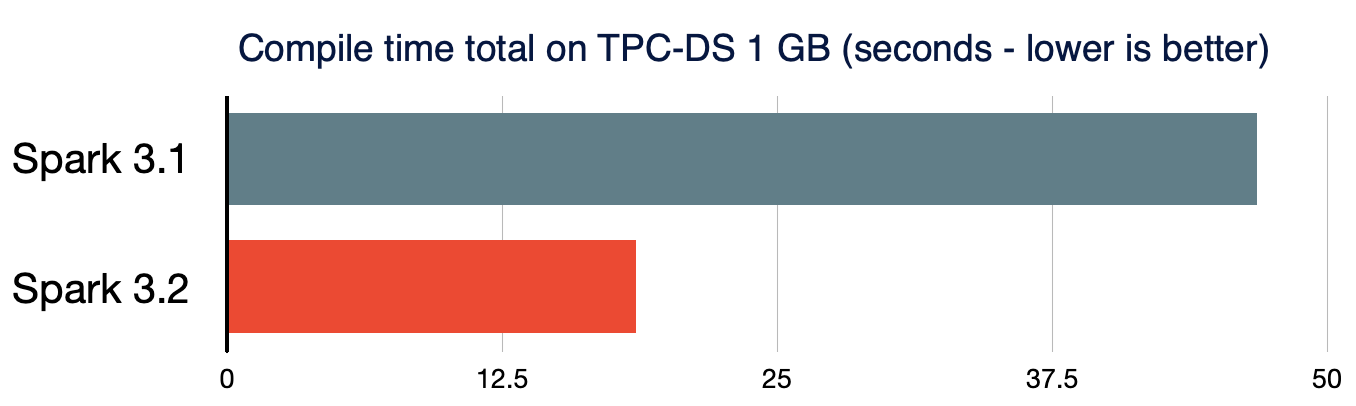
小規模データとビッグデータの両方は、統合されたデータ分析システムにおいて、高度に効率化された方法で処理されるべきです。短時間のクエリーのパフォーマンスも重要なものとなります。処理データのサイズが非常に小さい場合、複雑なクエリーにおけるSparkクエリーのコンパイルによるオーバーヘッドは重要となります。クエリーのコンパイルのレーテンシーをさらに削減するために、Spark 3.2.0では、アナライザー/オプティマイザールールにおいて、不要なクエリープランのトラバーサルを削除し(SPARK-35042、SPARK-35103)、新たなクエリープランの構築を高速化します(SPARK-34989)。結果として、TPC-DSクエリーのコンパイル時間は、Spark3.1.2と比較して**61%**削減されます。
よりスケーラブルな状態処理ストリーミング
構造化ストリーミングにおける状態ストアのデフォルト実装においては、保持される状態の数がエグゼキューターのヒープサイズによって制限されるためスケールしません。このリリースでは、DatabricksはSparkコミュニティに対して、4年以上に渡ってDatabricksの製品で使用されているRockDBベースの状態ストアの実装に貢献しました。この状態ストアは、キーでソートすることでフルスキャンを回避し、エグゼキューターのヒープサイズに依存せずに、ディスクからデータをサーブします。
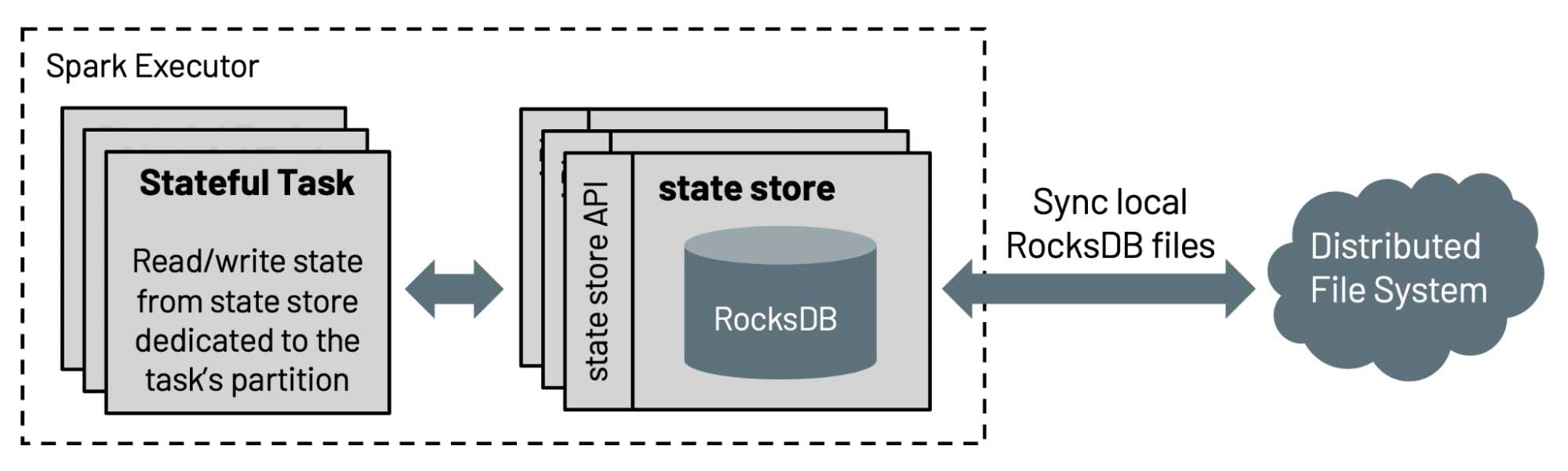
さらに、イベント時間に基づくセッション化(SPARK-10816)を効率的にサポートするために、状態ストアAPIはプレフィクスマッチスキャン(SPARK-35861)に対するAPIで拡張されており、ユーザーはon session windows over eventTimeを用いた集計を行えるようになります。詳細に関しては、ブログ記事「Spark構造化ストリーミングにおけるセッションウィンドウのネイティブサポート」をご覧ください。
Spark 3.2におけるその他のアップデート
これらの新機能のリリースに加え、このリリースでは1700ものJIRAチケットを解決することで、使いやすさ、安定性、洗練度にフォーカスしています。これは、個人、そして、Databricks、Apple、Linkedin、Facebook、Microsoft、Intel、Alibaba、Nvidia、Netflix、Adobeなどの企業を含む200以上のコントリビュータによる貢献によるものです。この記事では、SparkにおけるSQL、Python、ストリーミングデータのキーとなる改善をハイライトしましたが、codegenのカバレッジの改善、コネクターのエンハンスメントなど3.2のマイルストーンでは多くの機能が追加されています。詳細はリリースノートで確認できます。

すぐにSpark 3.2を使ってみる
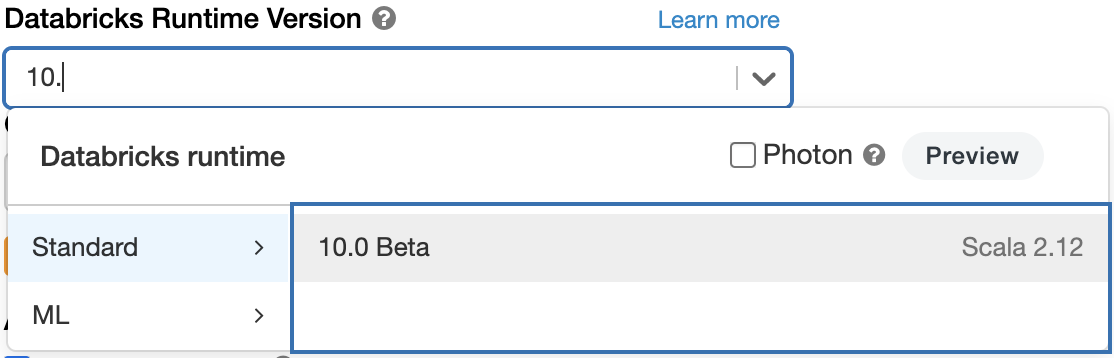
Databricksランタイム10.0でApache Spark 3.2を試して見たいのであれば、Databricks 無料トライアルにサインアップしてください。無料ですぐに利用を開始できます。クラスターを作成する際に、Databricks Runtime Versionに、手打ちで"10.0"と入力することでSpark 3.2を利用することができます。