Introducing Native Support for Session Windows in Spark Structured Streaming - The Databricks Blogの翻訳です。
Apache Spark™の構造化ストリーミングを用いることで、ユーザーはイベント時間に対するウィンドウで集計を行うことができます。Apache Spark 3.2™の前までは、Sparkはタンブリングウィンドウとスライディングウィンドウをサポートしていました。来たるApache Spark 3.2で、我々は新たなウィンドウタイプとして、ストリーミングとバッチクエリーの両方をサポートする「セッションウィンドウ」のサポートを追加します。
「セッションウィンドウ」とは?
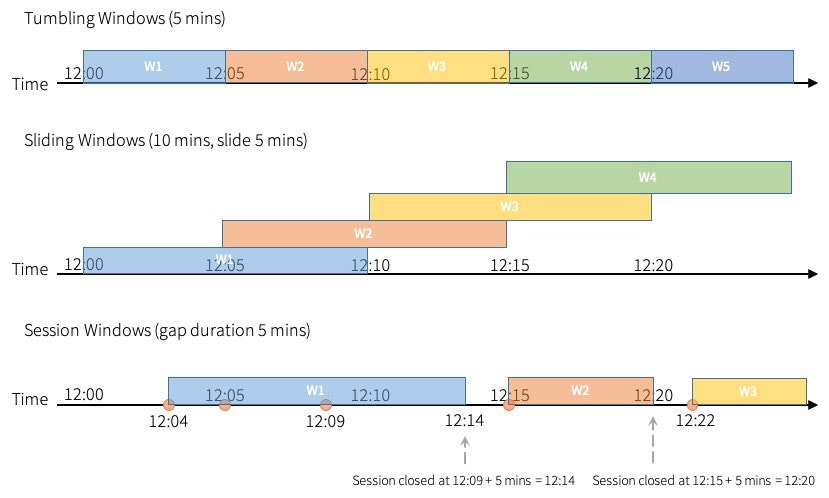
タンブリングウィンドウは固定サイズ、オーバーラップのない連続するタイムインターバルとなります。入力は単一のウィンドウにのみ紐付けられます。
スライディングウィンドウは「固定サイズ」という点ではタンブリングウィンドウと同じですが、ウィンドウの期間がスライドの期間が小さい場合、ウィンドウはオーバーラップし、この場合、入力は複数のウィンドウに紐づけられます。
セッションウィンドウは、上記二つのタイプと異なる特性を持っています。入力に応じて、セッションウィンドウは動的なウィンドウサイズを持ちます。入力によってセッションウィンドウがスタートし、ギャップ期間内で入力が継続している間、ウィンドウは拡張されます。最後のインプット以降のギャップ期間に入力がない場合にはウィンドウはクローズします。これによって、新規イベントが無い特定の期間(不活性期間)ごとにイベントをグルーピングすることができます。
これは、セッションタイムアウトがあるウェブサイトのセッションと同じように動作します。ウェブサイトにログインし、一定期間活動が認められない場合には、ウェブサイトはタイムアウト経過後、不活性状態が続いている際には、ログインステータスを保持し、ログアウトを強制することをユーザーに提示します。何かしらの活動が認められた際には、セッションタイムアウトは延長されます。
これをセッションウィンドウに当てはめてみましょう。ストリーミングジョブのような新規イベントが起きた際に、新たなセッションウィンドウが起動され、タイムアウト時間内の以降のイベントは同じセッションウィンドウに含まれます。個々のイベントはセッションタイムアウトを延長するので、他のタイムウィンドウと異なる特性を持つことになります。タンブリングウィンドウ、スライディングウィンドウと異なり、セッションウィンドウの期間は静的ではありません。
セッションウィンドウを用いてどのようにクエリーを実装するのか?
これまでは、Sparkではセッションウィンドウを取り扱うためには、flatMapGroupsWithStateを活用する必要がありました。ご自身でセッションウィンドウを定義し、同じセッション内で入力を集計するためのロジックを作成しなくてはなりませんでした。これはいくつかの問題を引き起こします。
- count、sumのようなビルトインの集計関数を活用できず、自身で実装しなくてはなりません。
- 様々な出力モード、入力の遅延を考慮したロジックを作り出すことは容易なことではありません。
- PySparkではflatMapGroupsWithStateは利用できません。このため、クエリーはJava/Scalaで開発する必要があります。
今となっては、Sparkはタイムウィンドウを使用するのと同じエクスペリエンスを提供します。「構造化ストリーミングにおいては、イベント時間に対するそのようなウィンドウの表現は、シンプルに特別なグルーピング処理を行います」という言葉は真実であり続けます。タンブリングウィンドウ、スライディングウィンドウにおいてwindow関数が提供されており、新たにsession_windowが導入されます。
例えば、イベントのeventTimeカラムに対する5分のタンブリングウィンドウ(重複なし)におけるカウントは、以下のように表現できます。
# tumbling window
windowedCountsDF = \
eventsDF \
.withWatermark("eventTime", "10 minutes") \
.groupBy("deviceId", window("eventTime", "10 minutes") \
.count()
# sliding window
windowedCountsDF = \
eventsDF \
.withWatermark("eventTime", "10 minutes") \
.groupBy("deviceId", window("eventTime", "10 minutes", "5 minutes")) \
.count()
イベントのeventTimeカラムにおいて、5分のギャップを持つセッションウィンドウに対するカウントを行うには、シンプルにwindow関数をsession_windowで置き換えます。
# session window
windowedCountsDF = \
eventsDF \
.withWatermark("eventTime", "10 minutes") \
.groupBy(session_window("eventTime", "5 minutes") \
.count()
動的ギャップ期間によるセッションウィンドウ
セッションの間に同じギャップ期間を持つセッションウィンドウに加え、セッションごとに異なるギャップ期間を持つ別のタイプのセッションウィンドウがあります。我々はこれを「動的ギャップ期間(dynamic gap duration)」と呼びます。
以下のボックスでは、Timeのラインはギャップ機関を伴うそれぞれのイベントを示しています。4つのイベントとそれぞれの(イベント時間, ギャップ期間)のペアは、青が(12:04, 4 mins)、オレンジが(12:06, 9 mins)、黄色が(12:09, 5 mins)、緑が(12:15, 5 mins)となっています。
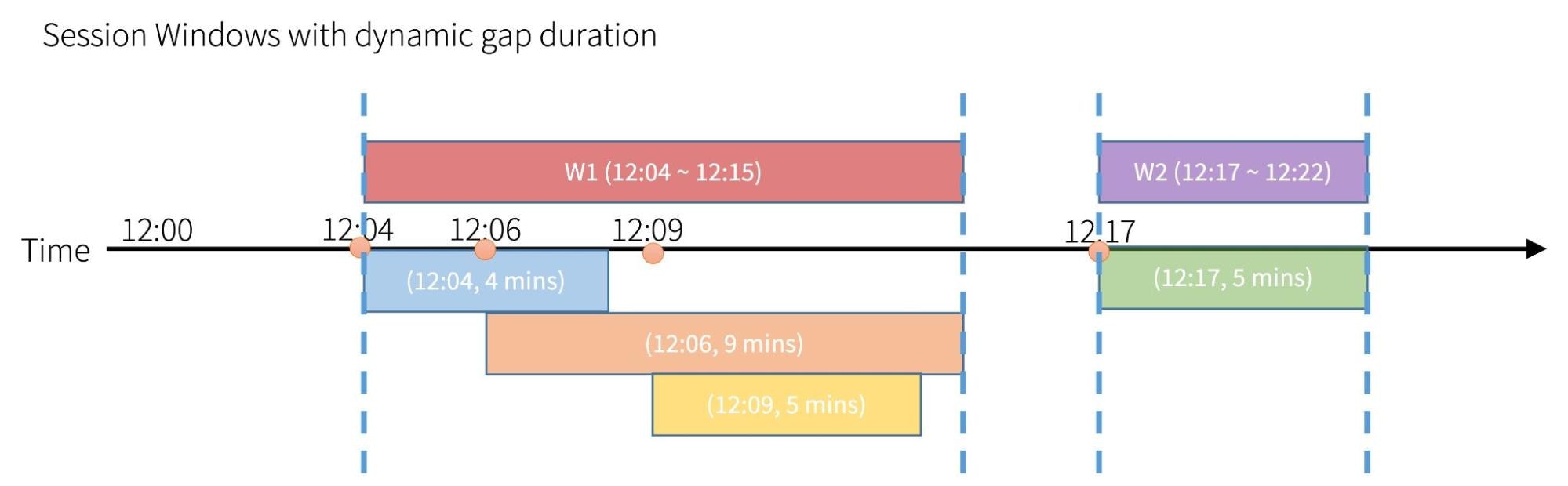
上の箱の栓はこれらのイベントから生成された実際のセッションを示しています。それぞれのイベントを個々のセッションと考えることができ、重なりを持つセッションを一つにまとめることができます。気づいたかもしれませんが、セッションの時間レンジはセッションに含まれる時間レンジの「union」になります。セッションの終了時刻はセッションの最後のイベントの時間+ギャップ期間であることに注意してください。
新たなsession_window関数は、イベント時間カラムとギャップ期間の2つのパラメーターを受け取ります。エクスプレッションは"5分"のようなインターバルに変換される必要があります。「ギャップ期間」パラメーターはエクスプレッションを受け取るので、UDF(ユーザー定義関数)を活用することもできます。
動的セッションウィンドウにおいては、session_window関数の「ギャップ期間」に「エクスプレッション」を指定することができます。
例えば、eventTypeカラムに基づく動的なギャップ期間によるセッションウィンドウに対するカウントは以下のようになります。
# Define the session window having dynamic gap duration based on eventType
session_window = session_window(events.timestamp, \
when(events.eventType == "type1", "5 seconds") \
.when(events.eventType == "type2", "20 seconds") \
.otherwise("5 minutes"))
# Group the data by session window and userId, and compute the count of each group
windowedCountsDF = events \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
session_window, \
events.userId) \
.count()
セッションウィンドウのネイティブサポート vs FlatMapGroupsWithState
flatMapGroupsWithStateはセッションウィンドウの実装においてさらなる柔軟性を提供しますが、ユーザーは大量のコードを書く必要があります。例えば、flatMapGroupsWithStateを用いてセッションウィンドウを実装したApache Sparkのセッション化サンプルをご覧ください。Apache Sparkのセッション化サンプルは極度にシンプルなものであり、処理時間と追加モードのペアでのみ動作することに注意してください。セッションウィンドウのネイティブサポートによって、イベント時間と様々な出力モードへの対応に関わる様々な複雑性を抽象化することができます。
Sparkは、セッションウィンドウが一般的なユースケースをカバーするようネイティブサポートのゴールを定めています。これによって、Sparkは性能と状態ストアの活用を最適化します。また、あなたのビジネスユースケースが複雑なセッションウィンドウ、例えば、特定のタイプのイベントの場合には不活性か否かに関係なくセッションをクローズする必要がある場合には、flatMapGroupsWithStateを活用したいと考えるかもしれません。
まとめ
ストリーミング、バッチクエリー両方で動作するセッションウィンドウについて説明しました。新たなsession_window関数の使い方を学ぶことで、タイムウィンドウによるストリーミングデータ集計の知識を活かし、セッションウィンドウを使いこなせるようになります。セッションウィンドウ集計クエリーにビルトインの集計関数やご自身のUDFを活用することもできます。flatMapGroupsWithStateはPySparkでは利用できず、SQL文でも利用できませんでしたが、これによって、SQL/PySparkのユーザーはセッションウィンドウを活用できるようになります。
オンタイムのウィンドウ操作にはまだ改善の余地があり、flatMapGroupsWithState APIを使う必要が出てくる場合があります。近い将来、カスタムのウィンドウ操作について検討していきます。
Databricksランタイム 10.0でApache Spark 3.2を試してみたいのであれば、Databricksコミュニティエディション、あるいは、Databricks 無料トライアルを試してみてください。クラスターを起動する際にバージョン"10.0"を選択するだけです。