Introducing Spark Connect - The Power of Apache Spark, Everywhere - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
先週のData & AIサミットのオープニングキーノートでSpark Connectという新たなプロジェクトにハイライトしました。この記事では、プロジェクトの動機付け、ハイレベルの提供内容、次のステップについて説明します。
Spark Connectは、プロトコルとしてデータフレームAPIと未解決の論理的プランを用いたSparkクラスターへのリモート接続を可能とする分離されたクライアント・サーバーアーキテクチャを導入します。クライアントとサーバーを分離することで、Sparkとそのオープンなエコシステムをどこからでも利用できるようになります。モダンなデータアプリケーション、IDE、ノートブック、プログラミング言語の中に埋め込むことが可能となります。
動機付け
過去10年間を通じて、開発者、研究者、コミュニティはSparkを用いて数万のデータアプリケーションの開発に成功してきました。これらを通じて、モダンデータアプリケーションのユースケースや要件が進化してきました。今では、アプリケーションサーバーで動作するWebサービス、ノートブックやIDEのようなインタラクティブな環境、スマートホームデバイスのようなエッジデバイスに至るすべてのアプリケーションがデータの力を活用するようになっています。
Sparkのドライバーアーキテクチャはモノリシックであり、スケジューラ、オプティマイザ、アナライザの上でクライアントアプリケーションが動作します。このアーキテクチャでは、これらの新たな要件に対応することが困難です: SQL以外の言語からSparkクラスターにリモートで接続するビルトインの機能がありません。現在のアーキテクチャとAPIはREPL、すなわちドライバーと密接に動作する必要があり、ノートブックで通常行われるようなインタラクティブなデータ探索には適しておらず、モダンなIDEでは一般的なリッチな開発者体験を提供することも困難です。最後になりますが、JVMと相互運用性がないプログラミング言語は現時点ではSparkを活用することができません。
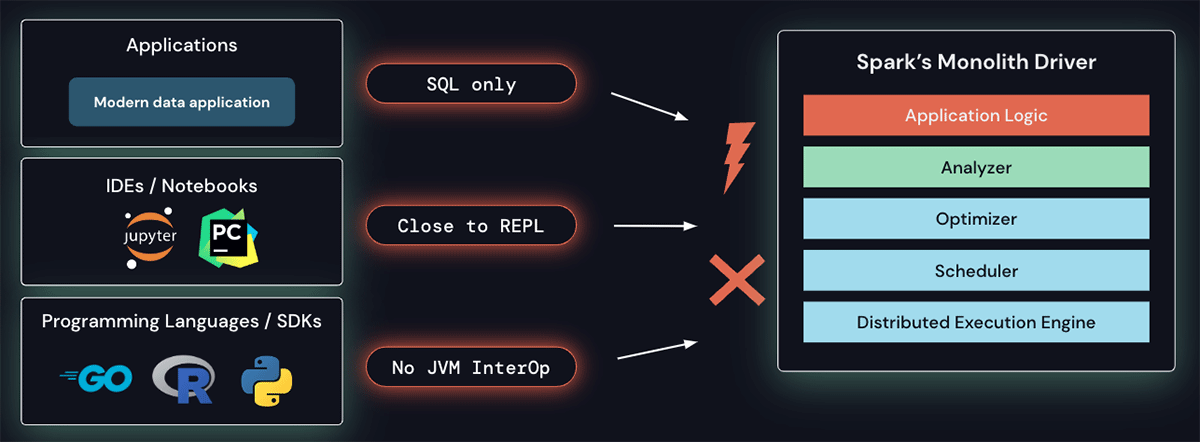
Sparkのモノリシックなドライバーはいくつかの課題を持っています
さらに、Sparkのモノリシックなドライバーアーキテクチャはオペレーション上の課題も引き起こします。
- 安定性: 全てのアプリケーションが直接ドライバーで動作するので、全てのユーザーが利用しているクラスターをダウンさせるような重大な例外(アウトオブメモリーなど)を引き起こす場合があります。
- アップグレード可能性: 現在のプラットフォームとクライアントAPI(classpathにおけるファーストパーティ、サードパーティの依存関係)の密結合は、シームレスなSparkパージョンのアップグレードを不可能とし、新たな機能の導入を妨げます。
- デバッグ可能性および観察可能性: ユーザーは主要なSparkプロセスにアタッチするための適切なセキュリティ権限を持っていないかもしれません。また、JVMプロセス自身のデバッグは、Sparkによって設定された全てのセキュリティ境界を解除してしまいます。さらに、アプリケーションから直接、詳細なログやメトリクスにアクセスすることは容易ではありません。
Spark Connectの動作原理
これら全ての課題を解決するために、Sparkにおける分離されたクライアント・サーバーアーキテクチャであるSpark Connectを導入します。
クライアントAPIはシンになるように設計されており、どこにでも埋め込むことができます: アプリケーションサーバー、IDE、ノートブック、プログラミング言語など。Spark Connect APIは、クライアントとSparkドライバー間の言語非依存のプロトコルとして、よく知られ愛されている未解決の論理的プランを用いたSparkのデータフレームAPI上に構築されています。
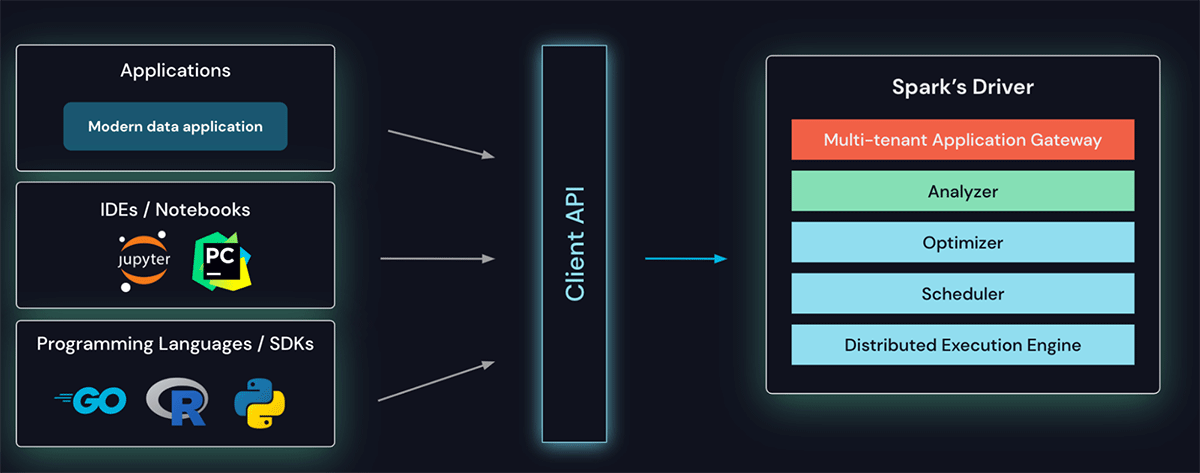
Spark ConnectはSpark用クライアントAPIを提供します
Spark Connectクライアントは、データフレームのオペレーションをプロトコルバッファーを用いてエンコードされる未解決論理的プランに変換します。これらはgRPCフレームワークを用いてサーバーに送信されます。以下の例では、logテーブルに対する一連のデータフレームのオペレーション(project, sort, limit)は論理的プランに変換され、サーバーに送信されます。

SparkにおけるSpark Connectオペレーションの処理
Sparkサーバーに埋め込まれたSpark Connectエンドポイントは、未解決論理的プランを受け取り、Sparkの論理的プランオペレーターに変換します。これは、属性とリレーションがパースされ、初期的なパースプランが構築されるSQLクエリーのパースと同様のものです。ここから、標準的なSparkの実行プロセスが起動され、Spark ConnectがSparkの最適化、エンハンスメントの全てを活用できるようにします。結果は、Apache Arrowでエンコードされた行バッチとしてgRPC経由でクライアントに返却されます。
マルチテナントのオペレーション上の課題を解決する
この新たなアーキテクチャを用いることで、Spark Connectは現在のオペレーション上の問題を軽減します。
- 安定性: メモリーを使いすぎるアプリケーションは、自分のプロセスで実行されるので自分の環境にのみインパクトを限定することができます。ユーザーはクライアントで自分の依存関係を定義することができ、Sparkドライバーとの潜在的な競合を心配する必要はありません。
- アップグレード可能性: 性能改善やセキュリティフィックスを行うために、Sparkドライバーはアプリケーションと独立してシームレスにアップグレードすることができます。これは、サーバーサイドのRPC定義が後方互換性があるように設計されている限り、アプリケーションには前方互換性があることを意味します。
- デバッグ可能性および観察可能性: Spark Connectでは、お好きなIDEを用いて、開発を通じて直接インタラクティブなデバッグが可能となります。同様に、アプリケーションフレームワークのネイティブなメトリクスとロギングライブラリを用いてアプリケーションをモニタリングすることができます。
次のステップ
Spark改善プロセスのプロポーザルは投票され、コミュニティによって受け入れられました。今後のApache Sparkリリースのいずれかで実験的APIとしてSpark Connectを利用できるようにコミュニティと協力しています。
初期のフォーカスは、この新たなAPIにシームレスに移行できるようにPySparkにおけるデータフレームAPIのカバレッジを提供することになります。しかし、Spark Connectは他のプログラミング言語コミュニティへの普及を進める素晴らしい機会であり、Spark Connectクライアントで別の言語に貢献できることを楽しみにしています。
このプロジェクトを開発するためにApache Sparkコミュニティの他の部分と連携することを楽しみにしています。Spark Connectの開発をフォローするには、メーリングリストdev@spark.apache.orgをフォローするか、こちらのフォームをサブミットしてください。