はじめに
こちらのアップデートです。
ワークスペースでのPythonユニットテスト
Databricksのワークスペースに、Pythonユニットテストツールが統合されました。テストサイドバー、インライン実行グリフ、テスト結果の下部パネルタブを使用して、pytestベースのテストの検出、実行、デバッグが可能です。詳細はワークスペースでのPythonユニットテストを参照してください。
Databricksのワークスペースに、Pythonのユニットテストを直接実行・管理できる機能があるのをご存知でしょうか?
テストサイドバー、インライン実行ボタン、結果パネルが統合されており、ワークスペースを離れることなくテストの検出・実行・結果確認がすべて完結します。VSCodeのテストエクスプローラーに近い体験がDatabricks上で得られるイメージです。
本記事では、この機能の使い方をサンプルコード付きで紹介します。
公式ドキュメントはこちらです。
前提条件
- Databricksワークスペースにアクセスできること
-
ワークスペースファイルとして
.pyファイルを作成できること(ノートブックではありません)
テスト対象の本体コードもテストファイルも、どちらもワークスペースファイル(.py)である必要があります。Databricksノートブック形式ではpytestが動作しません。ノートブックは通常のPython importで参照できないためです。
テストファイルの命名規則
Databricksはpytestの命名規約に従ってテストファイルを自動検出します。
ファイル名は以下のいずれかのパターンに合致する必要があります。
test_*.py*_test.py
テストケースは以下の命名規則で検出されます。
- クラス外の
testプレフィックス付き関数 -
Testプレフィックス付きクラス(__init__メソッドなし)内のtestプレフィックス付きメソッド -
@staticmethodや@classmethodデコレータ付きメソッドも対象
ファイル構成
今回は以下の構成で試します。同一ディレクトリに本体コードとテストファイルを配置します。
workspace/
├── my_functions.py # テスト対象の本体コード
└── test_my_functions.py # テストファイル
テスト対象の本体コード
まず、テスト対象となるユーティリティ関数を my_functions.py に用意します。
def clean_column_name(name: str) -> str:
"""カラム名をクリーンアップする(小文字化、スペースをアンダースコアに)"""
return name.strip().lower().replace(" ", "_")
def categorize_age(age: int) -> str:
"""年齢をカテゴリに分類する"""
if age < 0:
raise ValueError("年齢は0以上である必要があります")
elif age < 13:
return "child"
elif age < 20:
return "teenager"
elif age < 65:
return "adult"
else:
return "senior"
def calculate_tax(price: float, tax_rate: float = 0.10) -> float:
"""税込価格を計算する"""
if price < 0:
raise ValueError("価格は0以上である必要があります")
return round(price * (1 + tax_rate), 2)
def parse_full_name(full_name: str) -> dict:
"""フルネームを姓と名に分割する"""
parts = full_name.strip().split()
if len(parts) == 0:
raise ValueError("名前が空です")
elif len(parts) == 1:
return {"first_name": parts[0], "last_name": ""}
else:
return {"first_name": parts[0], "last_name": " ".join(parts[1:])}
def flatten_dict(d: dict, parent_key: str = "", sep: str = ".") -> dict:
"""ネストされた辞書をフラットにする"""
items = []
for k, v in d.items():
new_key = f"{parent_key}{sep}{k}" if parent_key else k
if isinstance(v, dict):
items.extend(flatten_dict(v, new_key, sep=sep).items())
else:
items.append((new_key, v))
return dict(items)
テストファイル
次に test_my_functions.py を作成します。意図的に失敗するテストケースも含めています。失敗時のUIの挙動を確認するためです。
import pytest
from my_functions import (
clean_column_name,
categorize_age,
calculate_tax,
parse_full_name,
flatten_dict,
)
# ---------------------------------------------------------------------------
# clean_column_name のテスト
# ---------------------------------------------------------------------------
class TestCleanColumnName:
def test_basic(self):
assert clean_column_name("First Name") == "first_name"
def test_with_leading_trailing_spaces(self):
assert clean_column_name(" Sales Amount ") == "sales_amount"
def test_already_clean(self):
assert clean_column_name("user_id") == "user_id"
def test_multiple_spaces(self):
assert clean_column_name("Total Sales Amount") == "total_sales_amount"
def test_fail_special_chars(self):
"""意図的に失敗: 特殊文字の処理は未実装"""
# clean_column_nameは特殊文字を除去しないため失敗する
assert clean_column_name("Price ($)") == "price"
# ---------------------------------------------------------------------------
# categorize_age のテスト (@pytest.mark.parametrize の例)
# ---------------------------------------------------------------------------
class TestCategorizeAge:
@pytest.mark.parametrize(
"age, expected",
[
(0, "child"),
(12, "child"),
(13, "teenager"),
(19, "teenager"),
(20, "adult"),
(64, "adult"),
(65, "senior"),
(100, "senior"),
],
)
def test_valid_ages(self, age, expected):
assert categorize_age(age) == expected
def test_negative_age_raises(self):
with pytest.raises(ValueError, match="年齢は0以上"):
categorize_age(-1)
def test_fail_boundary(self):
"""意図的に失敗: 境界値の期待値が間違っている"""
# 13歳は "teenager" だが、"child" を期待しているので失敗する
assert categorize_age(13) == "child"
# ---------------------------------------------------------------------------
# calculate_tax のテスト
# ---------------------------------------------------------------------------
class TestCalculateTax:
def test_default_tax_rate(self):
assert calculate_tax(1000) == 1100.0
def test_custom_tax_rate(self):
assert calculate_tax(1000, tax_rate=0.08) == 1080.0
def test_zero_price(self):
assert calculate_tax(0) == 0.0
def test_rounding(self):
assert calculate_tax(33.33) == 36.66
def test_negative_price_raises(self):
with pytest.raises(ValueError, match="価格は0以上"):
calculate_tax(-100)
# ---------------------------------------------------------------------------
# parse_full_name のテスト
# ---------------------------------------------------------------------------
class TestParseFullName:
def test_first_and_last(self):
result = parse_full_name("Taro Yamada")
assert result == {"first_name": "Taro", "last_name": "Yamada"}
def test_single_name(self):
result = parse_full_name("Madonna")
assert result == {"first_name": "Madonna", "last_name": ""}
def test_three_parts(self):
result = parse_full_name("Mary Jane Watson")
assert result == {"first_name": "Mary", "last_name": "Jane Watson"}
def test_empty_raises(self):
with pytest.raises(ValueError, match="名前が空"):
parse_full_name(" ")
def test_fail_wrong_expectation(self):
"""意図的に失敗: last_nameの大文字小文字が一致しない"""
result = parse_full_name("Taro Yamada")
assert result == {"first_name": "Taro", "last_name": "yamada"}
# ---------------------------------------------------------------------------
# flatten_dict のテスト
# ---------------------------------------------------------------------------
class TestFlattenDict:
def test_flat_dict(self):
assert flatten_dict({"a": 1, "b": 2}) == {"a": 1, "b": 2}
def test_nested_dict(self):
data = {"user": {"name": "Taro", "age": 30}}
expected = {"user.name": "Taro", "user.age": 30}
assert flatten_dict(data) == expected
def test_deeply_nested(self):
data = {"a": {"b": {"c": 1}}}
assert flatten_dict(data) == {"a.b.c": 1}
def test_custom_separator(self):
data = {"a": {"b": 1}}
assert flatten_dict(data, sep="/") == {"a/b": 1}
def test_empty_dict(self):
assert flatten_dict({}) == {}
意図的に失敗させているテストケースは以下の3つです。
| テスト | 失敗理由 |
|---|---|
test_fail_special_chars |
clean_column_nameは特殊文字の除去が未実装 |
test_fail_boundary |
13歳は teenager だが child を期待値にしている |
test_fail_wrong_expectation |
Yamada と yamada の大文字小文字が一致しない |
テストの実行方法
ワークスペースに両ファイルをアップロードし、test_my_functions.py を開くと、テストが自動検出されます。
テストサイドバーパネル
テストファイルを開くと、左側に テスト パネルが自動表示されます。
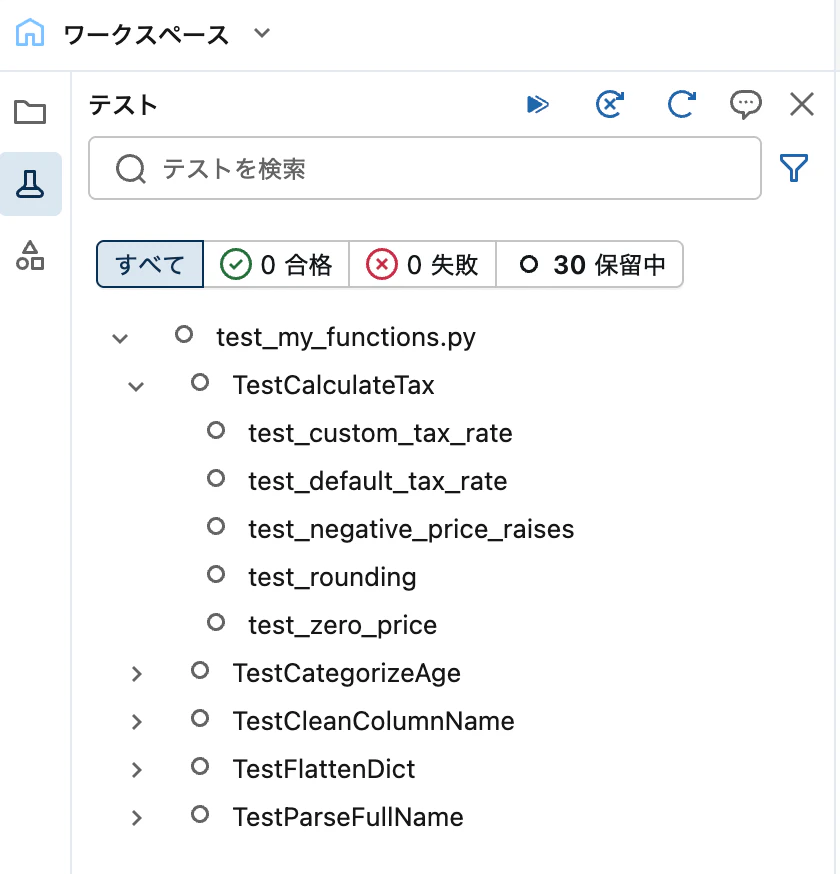
パネル上部のボタンから以下の操作ができます。
| ボタン | 機能 |
|---|---|
| すべてのテストを実行 | 全テスト実行 |
| 失敗したすべてのテストを実行 | 失敗テストのみ再実行 |
| テストの更新 | テスト一覧を再検出 |
個別のテストにホバーすると再生ボタンが表示され、テスト単体で実行することも可能です。
インラインの実行グリフ
エディタ上で各 def test_... の横に再生ボタンが表示されます。クリックするだけでそのテストを個別に実行できます。

実行後、アイコンがpass(緑)またはfail(赤)に更新されます。
テスト結果パネル
画面下部の Testing タブに、直近のテスト実行結果のサマリーが表示されます。

テストケースにホバーすると、該当コードへのジャンプや再実行が可能です。
失敗時の表示
テストが失敗すると、失敗した行にインラインでインジケータが表示されます。クリックするとエラーメッセージの全文を確認できます。

例えば test_fail_boundary を実行すると、assert categorize_age(13) == "child" の行に赤いインジケータが表示され、AssertionError: assert 'teenager' == 'child' のようなメッセージが確認できます。
Sparkを使ったテスト
Databricksワークスペース上で実行するので、テスト内で spark を直接利用できます。ETL処理のテストに便利です。
def test_spark_dataframe_filter():
"""SparkのDataFrameをフィルタするテスト"""
df = spark.createDataFrame(
[(1, "Alice", 30), (2, "Bob", 17), (3, "Charlie", 65)],
["id", "name", "age"],
)
adults = df.filter(df.age >= 18)
assert adults.count() == 2
def test_spark_column_rename():
"""カラム名クリーンアップをSparkに適用するテスト"""
from my_functions import clean_column_name
df = spark.createDataFrame([(1, "hello")], ["User ID", "Message Text"])
new_columns = [clean_column_name(c) for c in df.columns]
df_renamed = df.toDF(*new_columns)
assert df_renamed.columns == ["user_id", "message_text"]
注意点
ワークスペースファイルであること
テスト対象もテストファイルも、ワークスペースファイル(.py)として作成する必要があります。Databricksノートブック形式ではpytestが動作しません。
ノートブック形式かワークスペースファイル形式かは、ファイル先頭に # Databricks notebook source というマーカーがあるかどうかで判別できます。このマーカーがあるとノートブックとして扱われます。
既存のロジックがノートブックに書かれている場合は、関数部分をワークスペースファイルに切り出して、ノートブックからはそれをimportする形にリファクタリングするのがベストプラクティスです。
# ノートブックからワークスペースファイルの関数をimportして使う
from my_functions import clean_column_name, categorize_age
テスト結果がクリアできない
現時点(2025年2月)では、テスト結果をクリアする方法が提供されていません。
ファイルを閉じて開き直しても、ファイルを削除して再アップロードしても、前回のテスト結果が残り続けます。サイドバーの「Refresh tests」ボタンはテスト一覧の再検出であり、結果のリセットではありません。
テスト結果をリセットしたい場合は、ブラウザのキャッシュクリアやシークレットウィンドウでのアクセスを試す価値はありますが、根本的な解決策は今後のアップデートを待つ必要がありそうです。
importパスについて
テストファイルと本体コードが同一ディレクトリにある場合は、そのまま from my_functions import ... でimportできます。サブディレクトリに分ける場合は、__init__.py の配置やsys.pathの設定が必要になる場合があります。
まとめ
Databricksワークスペースのpythonユニットテスト機能を使うことで、以下のメリットが得られます。
- ワークスペースを離れずにテストの実行・結果確認ができる
- pytestの標準的な書き方がそのまま使える(
parametrize,fixture,raisesなど) - Sparkを使ったデータ処理のテストも直接実行できる
- サイドバー、インライングリフ、結果パネルの3つのUIでテストを効率的に管理できる
一方で、テスト結果のクリアができないなど、まだ荒削りな部分もあります。今後のアップデートに期待しつつ、データエンジニアリングのコード品質向上にぜひ活用してみてください。