はじめに
Databricks Apps の認可まわりは、ドキュメントを一通り読んでも「で、結局何が違うの?」が腹落ちしにくい領域です。特に最近パブリックプレビューになった ユーザー認可 ( User Authorization、いわゆる代理認証 / On-Behalf-Of ) は、用語と概念が密に絡んでいて、設定したつもりでも「実は SP のままだった」「スコープが足りずに 403」といった事故が起きやすいところです。
本記事では、
- アプリ認可 ( Service Principal ) とユーザー認可がそれぞれ「誰として」動くのか
- 何を設定するとどんな効果が得られるのか
- 同じテーブル・同じクエリで結果がどう変わるのか
を、1 つの Streamlit サンプルアプリで並べて体験できる構成にまとめました。サンプルアプリと SQL は実機検証済みで、本記事の手順をそのまま踏めば「左 0 行・右 3 行」というユーザー認可の効果を目で見える形で再現できます。
サンプルコード一式は GitHub で公開しています:
公式ドキュメントは以下です。
ユーザー認可は本記事執筆時点 ( 2026年5月 ) でパブリックプレビューです。利用にはワークスペース管理者が 「ユーザー名メニュー → Previews → On-Behalf-Of User Authorization」 を有効化しておく必要があります。
2 つの認可モデル: SP とユーザー、何が違うのか
Databricks Apps にはID が 2 つあります。アプリそのものの ID と、アプリを操作するユーザーの ID です。どちらの ID でリソースにアクセスするかを切り替えられる、というのが認可モデルの本質です。
アプリ認可 (Service Principal)
アプリを作成した瞬間に Databricks が専用のサービスプリンシパル (SP) を自動で発行します。アプリのコード内から特に何もしなくても、SDK が環境変数 DATABRICKS_CLIENT_ID / DATABRICKS_CLIENT_SECRET を拾って OAuth M2M で認証してくれます。
- 認証主体は アプリ専用 SP
- Unity Catalog の権限評価も SP に対して 行われる
- 誰が画面を開いていても同じ結果が返る
- バックグラウンド処理・共有設定の読み書き・外部 API 呼び出しなど、ユーザーに紐付かない処理に向く
ユーザー認可 (On-Behalf-Of User)
アプリにスコープを設定しておくと、Databricks Apps がログイン中のユーザーの OAuth アクセストークンを HTTP ヘッダー経由でアプリに転送してくれます。アプリはこれを使ってリクエストを送るので、Unity Catalog からは**「そのユーザーが叩いてきた」ように見える**わけです。
- 認証主体は 画面を開いているユーザー
- Unity Catalog の権限評価は ユーザーに対して 行われる
- 行フィルターが自動的に効く
- ユーザーごとのデータを返す、Genie Space を操作する、ユーザーのファイルを読むといった用途に向く
並列で使える
両者は排他ではありません。同じアプリの中で、「アプリのログ書き込みは SP、ユーザー向けデータの取得はユーザー認可」のように使い分けできます。むしろ実運用では混在が普通です。
| 観点 | アプリ認可 (SP) | ユーザー認可 (代理) |
|---|---|---|
| 認証主体 | アプリ専用 SP | アプリを開いているユーザー |
| OAuth フロー | M2M (Client Credentials) | U2M (On-Behalf-Of) |
| 資格情報の取得元 | 環境変数 DATABRICKS_CLIENT_ID / _SECRET
|
HTTPヘッダー x-forwarded-access-token
|
| Unity Catalog 評価 | SP の権限 | ユーザーの権限 |
| 行フィルター | SP に対して評価 | ユーザーに対して評価 |
| 範囲制御 | SP に付与した権限のみ | スコープで API を制限 |
| 主な用途 | 共有処理・バックグラウンド | ユーザー個別データ |
体験用サンプルアプリの設計
「同じ SELECT を投げたのに片方は 0 行、もう片方は自分の region 分が返ってくる」という違いが目で見えれば、ユーザー認可の効果が一発でわかります。そのためにサンプルでは次の仕掛けを使います。
-
sales_dataテーブルに 行フィルター を掛ける - 行フィルターは
current_user()を見て「自分の region だけ」可視にする - 別途
user_region_mapテーブルにユーザーとリージョンの対応を登録しておく - アプリ専用 SP は当然この map に登録されない → SP として実行すると 0 行
- ユーザー本人として実行すると、ヒットしたリージョンの行が返る
アプリは Streamlit 製で、5 つのタブで挙動を見られる構成にします。
- 「認証ID」タブ:
current_user.me()を 2 つの認可で並べる - 「クエリ比較」タブ: 同じ SQL を 2 つの認可で実行して結果を並べる
- 「スコープ動作確認」タブ: スコープ範囲外の API がブロックされる様子を確認
- 「ヘッダー検査」タブ:
x-forwarded-*ヘッダーを覗き見 - 「解説」タブ: 早見表
前提環境
再現に必要なものを最初に揃えておきます。
| 項目 | 要件 |
|---|---|
| Databricks ワークスペース | Unity Catalog が有効化済み |
| Databricks Apps | 利用可能 ( ワークスペース管理者が有効化済み ) |
| ユーザー認可機能 | パブリックプレビュー機能の有効化が必要 ( ワークスペース管理者に依頼 ) |
| SQL Warehouse | Serverless または Pro で稼働中 |
| Unity Catalog 権限 | 任意のカタログへの CREATE SCHEMA、テーブル作成、行フィルター関数作成権限 |
| 開発環境 | Databricks CLI v0.230 以降、databricks auth login 済み |
本記事のサンプルは main カタログを使います。別のカタログを使う場合は、本記事の SQL コード中の main を自分の環境のカタログ名にすべて置換してください。
セットアップ
ステップ 1. Unity Catalog 側のセットアップ
SQL Editor で以下を実行します。'your.email@example.com' を自分のメールアドレスに置き換えてください ( このメールアドレスが行フィルターのキーになります )。
USE CATALOG main;
CREATE SCHEMA IF NOT EXISTS main.app_auth_demo;
USE SCHEMA main.app_auth_demo;
CREATE OR REPLACE TABLE user_region_map (
user_email STRING NOT NULL,
allowed_region STRING NOT NULL
);
INSERT INTO user_region_map VALUES
('your.email@example.com', 'APAC'),
('teammate1@example.com', 'EMEA'),
('teammate2@example.com', 'AMER');
CREATE OR REPLACE TABLE sales_data (
order_id BIGINT, region STRING, customer STRING,
amount DOUBLE, order_date DATE
);
INSERT INTO sales_data VALUES
(1,'APAC','Tokyo Trading Co.',12000.0,DATE'2026-01-15'),
(2,'APAC','Singapore Holdings',8500.0,DATE'2026-01-20'),
(3,'APAC','Sydney Logistics',15200.0,DATE'2026-01-22'),
(4,'EMEA','Berlin GmbH',22000.0,DATE'2026-01-25'),
(5,'EMEA','London Inc',15000.0,DATE'2026-02-01'),
(6,'EMEA','Paris SARL',18500.0,DATE'2026-02-03'),
(7,'AMER','NY Holdings',30000.0,DATE'2026-02-05'),
(8,'AMER','SF Tech',18000.0,DATE'2026-02-10'),
(9,'AMER','Toronto Industries',21000.0,DATE'2026-02-12');
CREATE OR REPLACE FUNCTION region_row_filter(region STRING)
RETURNS BOOLEAN
RETURN region IN (
SELECT allowed_region FROM main.app_auth_demo.user_region_map
WHERE user_email = current_user()
);
ALTER TABLE sales_data SET ROW FILTER region_row_filter ON (region);
ここで重要なのは、フィルター条件が current_user() を使っていることです。これにより「クエリを実行している ID が誰か」によって可視範囲が動的に変わります。
動作確認: 自分の SQL Editor で SELECT * FROM main.app_auth_demo.sales_data を実行すると、APAC ( 上で your.email に紐付けたリージョン ) の 3 行だけが返るはずです。9 行全部が返る場合は行フィルターが効いていません ( ALTER TABLE 文を再実行 )。0 行の場合は user_region_map のメールアドレスが自分と違います。
ステップ 2. アプリを作成する
ワークスペースの「Compute」→「Apps」から新規アプリを作成します。この時点ではコードはまだアップロードしません。空のアプリを作るだけです。
作成すると、アプリ詳細画面の「Authorization」タブにアプリ専用 SP の Application ID ( UUID 形式 ) が払い出されます。後のステップで使うのでコピーしておきます。
動作確認: SP の Application ID が xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx 形式の UUID として表示されていれば OK。
ステップ 3. SQL Warehouse をリソースとして紐付ける
ここが見落としやすいところです。app.yaml には次のように書いてあります。
env:
- name: "DATABRICKS_WAREHOUSE_HTTP_PATH"
valueFrom: "sql_warehouse"
これは「sql_warehouse という名前のリソースから値を取って来る」という参照です。実際にどの Warehouse を指すかは、アプリオブジェクト側で別途バインドする必要があります。
アプリの編集画面で「App resources」セクションを開き、
- 「+ Add resource」
- リソースタイプ: SQL warehouse
- 対象の Warehouse を選択
-
Resource key を
sql_warehouseに設定 (app.yamlのvalueFromと一致させる ) - Permission: CAN_USE
- 保存
実機検証で確認した挙動として、valueFrom が返す値はwarehouse の HTTP path 全体ではなく、warehouse ID のみです。サンプルの app.py には ID を受け取って /sql/1.0/warehouses/{id} 形式のパスに組み立てる resolve_http_path() を入れてあります。
動作確認: 次のステップでデプロイした後、アプリの画面のサイドバーで「Warehouse HTTP Path」に /sql/1.0/warehouses/<長い英数字> が表示されていれば成功です。None が出る場合は Resource key の不一致か、アプリの再起動忘れです。
ステップ 4. コードをデプロイする
まずローカルにリポジトリを clone します。
git clone https://github.com/taka-yayoi/databricks-apps-user-auth-demo.git
cd databricks-apps-user-auth-demo
Workspace フォルダにコードを同期してからデプロイします。
# ローカルから Workspace に同期
databricks sync . /Workspace/Users/<your-email>/apps/auth-demo
# デプロイ
databricks apps deploy auth-demo \
--source-code-path /Workspace/Users/<your-email>/apps/auth-demo
UI からアップロードしてデプロイしても結果は同じです。
動作確認: デプロイが SUCCEEDED で終わり、アプリの URL からアクセスできるようになっていれば OK です。URL は databricks apps get auth-demo または UI で確認できます。
ステップ 5. アプリ専用 SP に Unity Catalog 権限を付与する
ステップ 2 でコピーした Application ID を使って、最低限の SELECT 権限を付与します。
GRANT USE CATALOG ON CATALOG main TO `<APP_SERVICE_PRINCIPAL_APPLICATION_ID>`;
GRANT USE SCHEMA ON SCHEMA main.app_auth_demo TO `<APP_SERVICE_PRINCIPAL_APPLICATION_ID>`;
GRANT SELECT ON TABLE main.app_auth_demo.sales_data TO `<APP_SERVICE_PRINCIPAL_APPLICATION_ID>`;
GRANT SELECT ON TABLE main.app_auth_demo.user_region_map TO `<APP_SERVICE_PRINCIPAL_APPLICATION_ID>`;
これがないと、アプリ認可側のクエリが権限エラーで落ちます。「SP は user_region_map に登録されていないので 0 行が返る」という対照実験を成立させるためには、テーブルへのアクセス自体は許可しておく必要があります。
動作確認: アプリの画面で「認証ID」タブを開くと、左ペイン (アプリ認可) にステップ 2 でコピーしたものと同じ Application ID が表示されているはずです。
ステップ 6. ユーザー認可スコープを追加する
ここが今回の本丸です。アプリの編集画面で「User authorization」セクションの 「+ Add scope」 から sql を追加します。
app.yaml でスコープを宣言する公式構文は現時点で存在しません ( ドキュメントに記載なし )。UI から追加するのが標準ルートです。コード化したい場合は DAB (databricks.yml) の resources.apps で扱います。
スコープを追加・変更したら、必ずアプリを再起動してください。再起動しないと新スコープのトークンが発行されません。同様に、ユーザー認可を無効化したいときも再起動して既存トークンの使用を止める必要があります。
databricks apps stop auth-demo
databricks apps start auth-demo
動作確認: 再起動後にアプリの「認証ID」タブを開くと、右ペイン (ユーザー認可) に自分のメールアドレスが表示されているはずです。「ユーザートークンが届いていません」の警告が出る場合は、スコープ追加または再起動が反映されていません。
ステップ 7. 初回アクセスと同意
ユーザーがアプリを最初に開くと、Databricks が「このアプリが要求するスコープの範囲で、あなたとして動作することを許可しますか?」という同意画面を出します。同意を返すと、以後はそのスコープの範囲でユーザートークンが転送されます。
同意は一度付与するとユーザーは自分で取り消せません。必要に応じてワークスペース管理者に削除を依頼する運用になるので、スコープは最小権限で設計します。
動作確認: 期待される結果
セットアップが完了すると、各タブで以下のような結果が見えるはずです。
「認証ID」タブ
同じ current_user.me() 呼び出しが、左右で異なる ID を返します。
- 左 ( アプリ認可 ): ステップ 2 でコピーした SP の Application ID ( UUID 形式 )
-
右 ( ユーザー認可 ): 自分のメールアドレス ( 例:
your.email@databricks.com)

「クエリ比較」タブ
同じ SELECT * FROM main.app_auth_demo.sales_data ORDER BY order_id を 2 つの認可で実行すると、
-
左 ( SP として実行 ): 取得行数 0 (
user_region_mapに SP が登録されていないため、行フィルターで弾かれる ) - 右 ( ユーザーとして実行 ): 取得行数 3 ( ステップ 1 で自分に紐付けた region の行 )
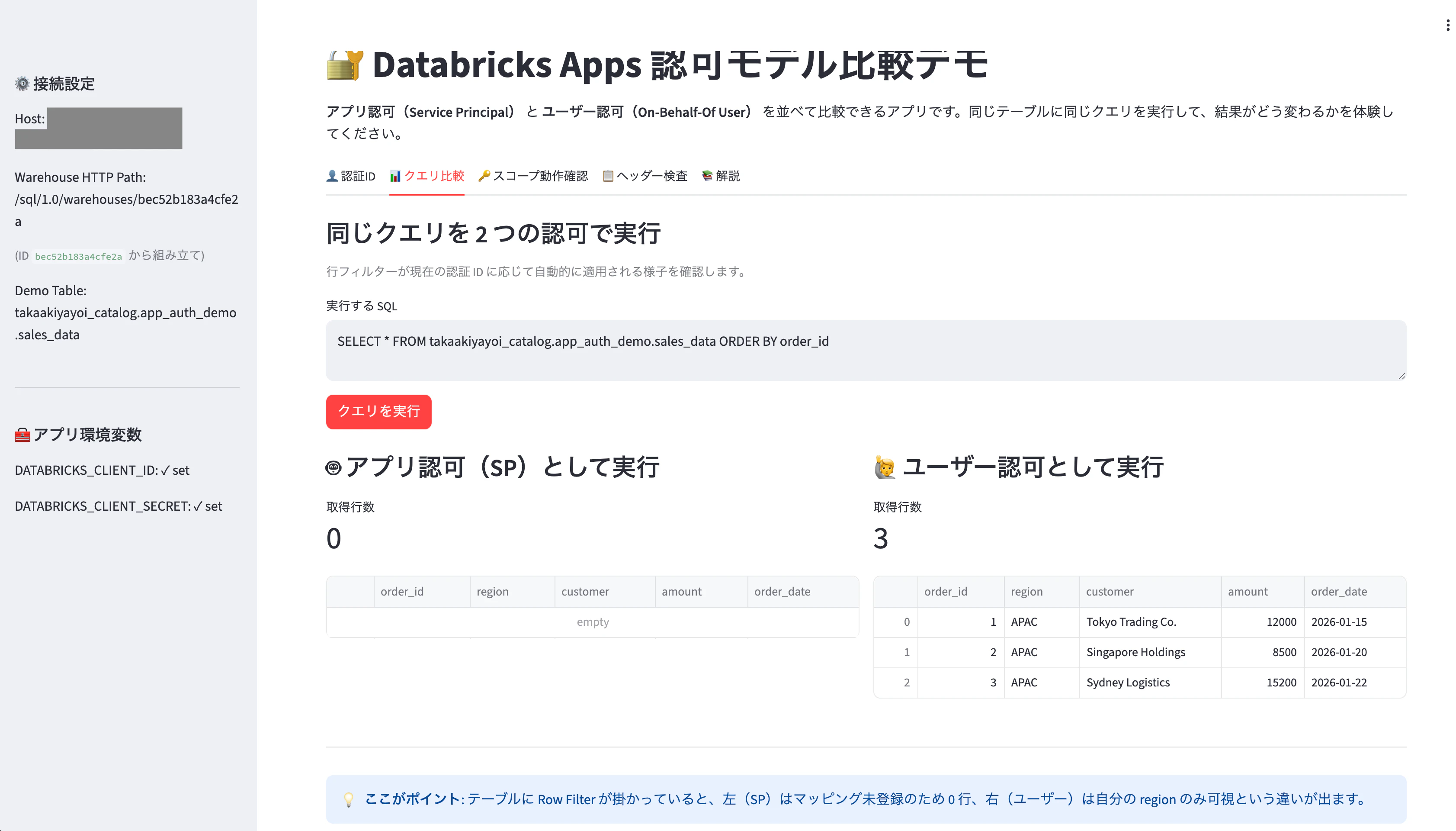
これが本記事のクライマックスです。同じ SDK・同じ SQL・同じテーブルを叩いても、認可方式によって Unity Catalog の評価結果がここまで変わる、という違いがひと目で見える構図になります。
「スコープ動作確認」タブ
sql スコープしか付与していないので、
-
iam.current-user:readボタン ( 既定スコープ ): 成功 -
files.filesボタン ( catalogs.list を呼び出し ): 既定スコープiam.access-control:readで動くため成功するケースあり -
serving.serving-endpointsボタン: 失敗 ( スコープ未付与 )
3 つ目だけ赤いエラーが出れば、「スコープ宣言が API 呼び出しを縛っている」という仕組みが視覚化できます。
「ヘッダー検査」タブ
x-forwarded-access-token ( 伏字 ) / x-forwarded-email ( 自分のアドレス ) / x-forwarded-preferred-username 等が表示されます。トークン自体は冒頭 8 文字 + 長さだけ表示する実装にしてあります。
実装の解説
ユーザー認可で「ユーザーの ID」を取り出す
x-forwarded-access-token を読むだけです。フレームワーク (Streamlit / Gradio / Flask / Shiny / Express) によって取り出し方が変わるので、ドキュメントを参照してください。本サンプルでは Streamlit を使っているので st.context.headers 経由です。
import streamlit as st
headers = st.context.headers
user_access_token = headers.get("x-forwarded-access-token")
user_email = headers.get("x-forwarded-email")
x-forwarded-email や x-forwarded-preferred-username も付いてくるので、画面に「ようこそ ◯◯ さん」を出すだけならトークンを使わずにこちらで足ります。
アプリ認可で WorkspaceClient を使う
SDK は環境変数を勝手に拾ってくれるので、何も指定せず WorkspaceClient() するだけです。これは SP として動きます。
from databricks.sdk import WorkspaceClient
w_sp = WorkspaceClient() # SP として認証
me = w_sp.current_user.me()
print(me.user_name) # → アプリの SP の名前
ユーザー認可で WorkspaceClient を使う
ヘッダーから取り出したトークンを token= で渡しますが、auth_type="pat" を必ず指定します。Databricks Apps の実行環境では SP の OAuth M2M 資格情報が環境変数として常に存在しており、これを指定しないと SDK が「OAuth と PAT の 2 つが設定されている」と判断してエラーになります。
from databricks.sdk import WorkspaceClient
from databricks.sdk.core import Config
cfg = Config()
w_user = WorkspaceClient(
host=cfg.host,
token=user_access_token,
auth_type="pat", # SP の OAuth 資格情報を無視させる
)
me = w_user.current_user.me()
print(me.user_name) # → アプリを開いているユーザーの名前
SQL クエリを 2 つの認可で実行する
公式ドキュメントの書き分けと同じです。SP 側は credentials_provider 経由で SDK の認証フローに任せ、ユーザー側はトークンを直接渡します。
from databricks import sql
from databricks.sdk.core import Config
cfg = Config()
HTTP_PATH = os.getenv("DATABRICKS_WAREHOUSE_HTTP_PATH")
# SP として実行
conn_sp = sql.connect(
server_hostname=cfg.host,
http_path=HTTP_PATH,
credentials_provider=lambda: cfg.authenticate,
)
# ユーザーとして実行
conn_user = sql.connect(
server_hostname=cfg.host,
http_path=HTTP_PATH,
access_token=user_access_token,
)
行フィルターが current_user() を使っているので、同じ SELECT * FROM sales_data でも結果が変わります。これが今回いちばん見せたいポイントです。
スコープ範囲外の呼び出し
スコープ宣言は「ユーザーに同意を求める権限」と「アプリから呼び出せる API」の両方を縛ります。例えば sql だけ宣言したアプリでユーザートークンを使って Serving Endpoint を叩こうとすると、ユーザー自身が権限を持っていてもアプリからの呼び出しは弾かれます。サンプルの「スコープ動作確認」タブで実際に確認できます。
これは仕様ではなく設計です。アプリがバグや侵害で意図しない動きをしても、ユーザーが許諾していない範囲を踏み越えないようにする仕組みです。
よく使うスコープと選び方
| スコープ | 用途 |
|---|---|
iam.current-user:read |
自分の情報を読む (既定) |
iam.access-control:read |
アクセス制御を読む (既定) |
sql |
SQL Warehouse 経由でクエリを実行 |
dashboards.genie |
Genie Space を操作 |
files.files |
Files API でファイル・ボリュームを読み書き |
serving.serving-endpoints |
Serving Endpoint を呼び出す |
選び方の指針は最小権限です。ユーザーから見れば「同意したスコープの範囲でしかアプリは動かない」という保証になり、アプリ開発者から見れば「想定外の API を叩く事故を Databricks 側で止めてもらえる」というセーフネットになります。
ハマりやすいポイント
実機検証で実際に踏んだ落とし穴を、エラーメッセージ込みで記録しておきます ( 後から検索する人のため )。
validate: more than one authorization method configured: oauth and pat
これが本記事を書くうえで最初に踏んだ落とし穴でした。WorkspaceClient(host=..., token=user_token) でユーザートークンを渡しただけだと、Databricks Apps 環境では SDK が環境変数の DATABRICKS_CLIENT_ID / DATABRICKS_CLIENT_SECRET ( SP の OAuth M2M 資格情報 ) も同時に拾ってしまい、「OAuth と PAT の 2 つが設定されている」と判断して起動時に validate でエラーになります。
修正は auth_type="pat" を明示して OAuth を無視させること。Databricks Apps でユーザー認可の WorkspaceClient を作るときの定型句として覚えておくと良いです。
w_user = WorkspaceClient(
host=cfg.host,
token=user_access_token,
auth_type="pat",
)
DATABRICKS_WAREHOUSE_HTTP_PATH が None
app.yaml で valueFrom: "sql_warehouse" を宣言していても、これだけでは値は注入されません。アプリの「App resources」で SQL Warehouse をリソースとして紐付け、Resource key を sql_warehouse ( app.yaml の valueFrom と完全一致 ) にした上で、追加後にアプリを再起動する必要があります。
加えて実機検証で確認した事実として、valueFrom が返してくる値はwarehouse の HTTP path 全体ではなく warehouse ID 単体です。サンプルでは resolve_http_path() で /sql/1.0/warehouses/{id} 形式に組み立てています。
スコープを追加したのに反映されない
スコープを追加・変更したら必ずアプリを再起動してください。databricks apps stop → databricks apps start です。再起動しないと新スコープのトークンが発行されません。
SP として実行したら 403
SP に USE CATALOG / USE SCHEMA / SELECT を別々に付与する必要があります。SELECT だけでは足りません。本記事のステップ 5 にあるとおり 4 つの GRANT 文をすべて流してください。
x-forwarded-access-token が None
ユーザー認可スコープが未設定、または再起動前、もしくはローカル開発実行時です。Databricks Apps としてデプロイされた環境でのみヘッダーが付きます。ローカル PC の streamlit run ではユーザートークンは取得できないことに注意してください。
current_user() が SP を返す
当然 SP 側の SQL は SP を返しますが、ユーザー認可で叩いたつもりが SP の名前 ( UUID ) が返ってきたら、トークンを渡せていないサインです。sql.connect() の access_token= 引数を見直します。
トークンがログに出ている
print(token) や logger.info(headers) をうっかり書きがちです。トークンは必ず伏字化してから扱います。サンプルの「ヘッダー検査」タブが「先頭 8 文字 + 長さ」だけ出す実装の参考になります。
ベストプラクティス
公式ドキュメントが推奨しているポイントを実装に落とすと以下の通りです。
- アプリコードはアプリ所有者と少数の信頼できる開発者だけがアクセスできる Workspace フォルダに置く
-
CAN MANAGEは上級開発者に限定し、CAN USEは実行を許可するユーザー/グループにのみ付与する - アクセストークンを 絶対に print・ログ・例外メッセージ・ファイルに残さない
- 機能に必要な最小限のスコープだけ宣言する
- コードレビュー時にスコープと権限設定をセキュリティ要件と突き合わせる
- 本番デプロイ前にピアレビューを行う
- ユーザー ID・アクション種別・対象リソース・結果を構造化ログとして必ず残す
まとめ
ユーザー認可の理解の鍵は、「アプリの SP」と「ユーザー自身」という 2 つの別 ID をアプリの中で使い分けているという点に尽きます。本サンプルのように同じ SDK 呼び出しと同じ SQL を 2 つの認可で並べて実行すると、
-
current_user.me()の返り値が変わる ( SP の UUID vs ユーザーのメールアドレス ) - 行フィルターの効き方が変わる ( 同じ SELECT が 0 行 vs 3 行 )
- スコープ範囲外の API が弾かれる
といった違いが目で見えて、用語と挙動が一致してきます。実運用では「SP で共有データを取りつつ、ユーザートークンでユーザー固有データを取る」という混在パターンになるので、まずは本サンプルで挙動を掴んでから、実際のユースケースに当てはめてみてください。
本記事で使ったサンプルアプリ一式は GitHub で公開しています。同じ環境でハマったら Issue やコメントで教えてください。
参考リンクをまとめておきます。