リアルタイムモードとは
Databricksの構造化ストリーミングには、エンドツーエンドの遅延を5ミリ秒以下に抑えるリアルタイムモード (Real-time mode) が用意されています。これはパブリックプレビュー段階の機能で、不正検知やギャンブルサービスのリアルタイムパーソナライゼーションといった、超低レイテンシが求められる運用ワークロードに最適です。
本記事では公式ドキュメント「リアルタイムモードを始める」に沿って、最初のリアルタイムストリーミングクエリを動かすまでの手順を紹介します。
要件
- クラシックコンピュートを作成する権限
- Databricks Runtime 17.1以上 (ノートブックで
display関数のリアルタイムモードを使用するために必要)
クラシックコンピュートの作成権限がない場合は、ワークスペース管理者に依頼して、次のステップの設定でクラスターを作成してもらいます。
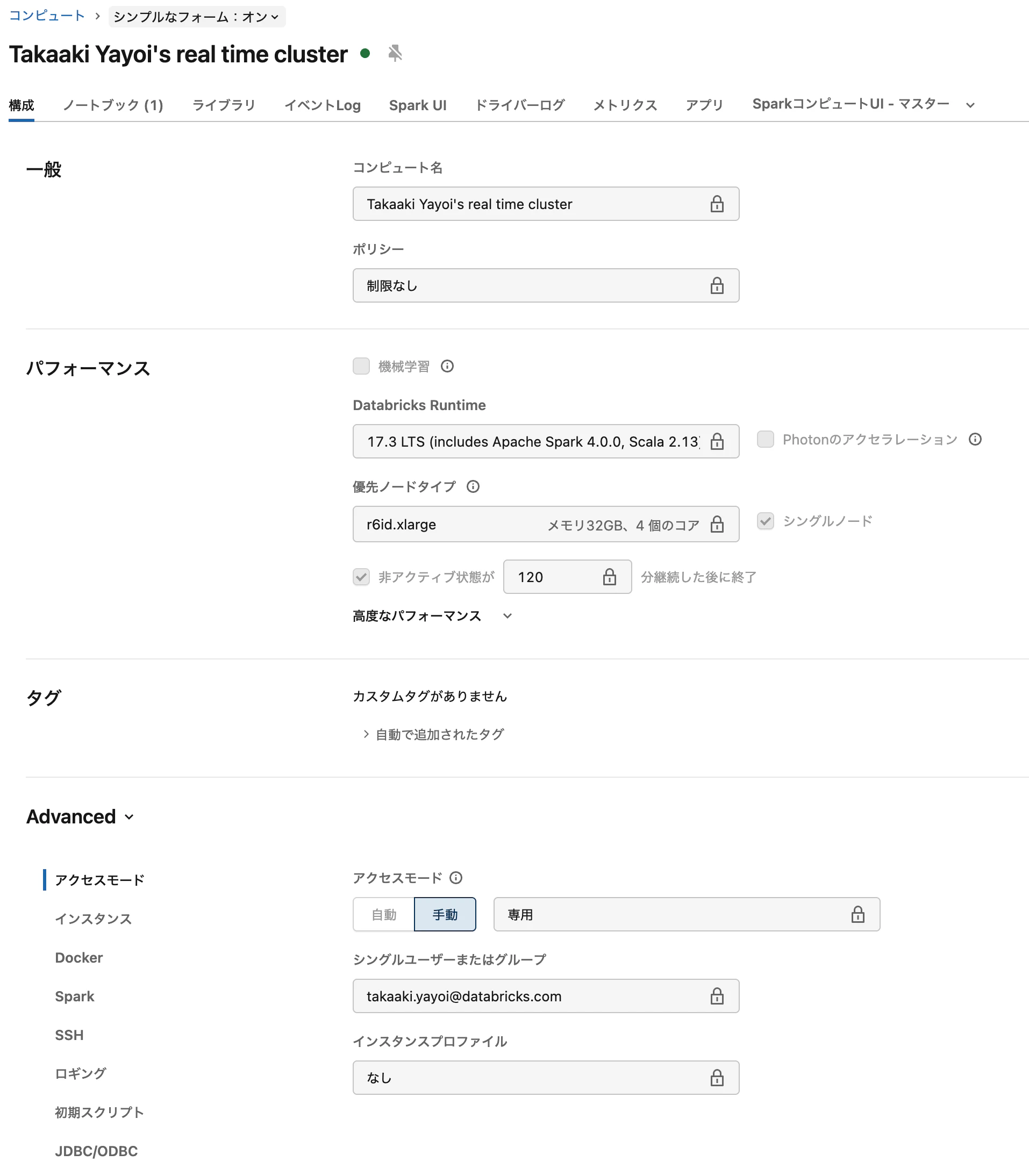
ステップ1: リアルタイムモード用のクラシックコンピュートを作成する
超低レイテンシを実現するには、リアルタイムモード専用のクラシックコンピュート設定が必要です。これらの設定により、タスクが全ステージで同時実行され、データはバッチではなく到着次第継続的に処理されます。
-
Databricksワークスペースのサイドバーで [コンピュート] をクリック
-
[コンピュートを作成] をクリック
-
任意の名前を入力
-
Databricks Runtime 17.1以上を選択
-
[Photonアクセラレーション] をオフ (リアルタイムモードはPhoton非対応)
-
[オートスケールを有効にする] をオフ (固定クラスターサイズが必要)
-
[詳細なパフォーマンス] で [スポットインスタンスを使用する] をオフ (スポットインスタンスは中断を引き起こす可能性があるため)
-
[詳細オプション] を展開
-
[アクセスモード] で [専用 (旧称: シングルユーザー)] を選択
-
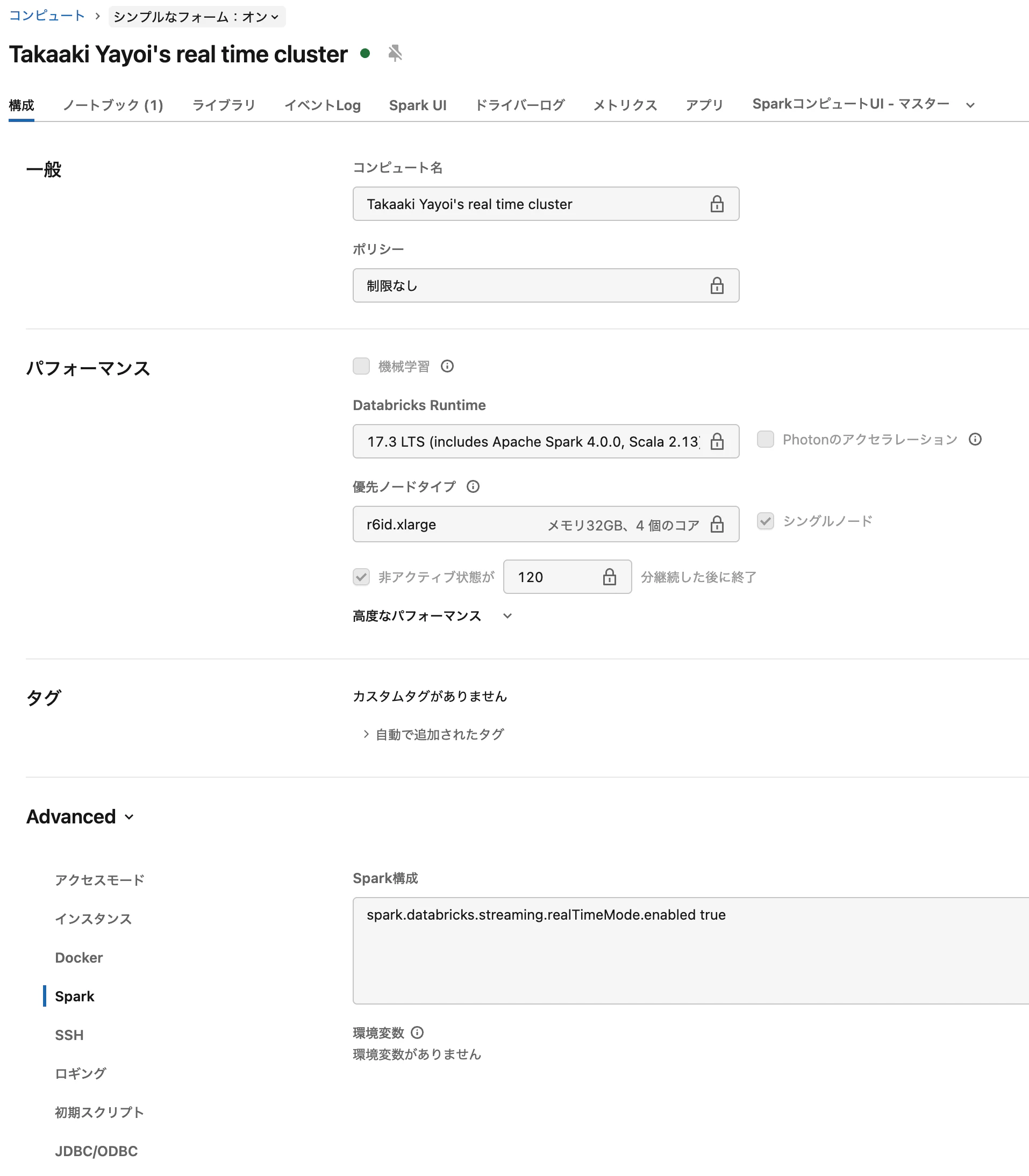
[Spark config] に以下の設定を追加
spark.databricks.streaming.realTimeMode.enabled true -
[コンピュートを作成] をクリック
ステップ2: ノートブックを作成する
ストリーミングクエリを開発・テストするためのノートブックを用意します。
- サイドバーの [新規] → [ノートブック] をクリック
- コンピュートのドロップダウンで、ステップ1で作成したクラスターを選択
- デフォルト言語として Python または Scala を選択
ステップ3: リアルタイムモードのクエリを実行する
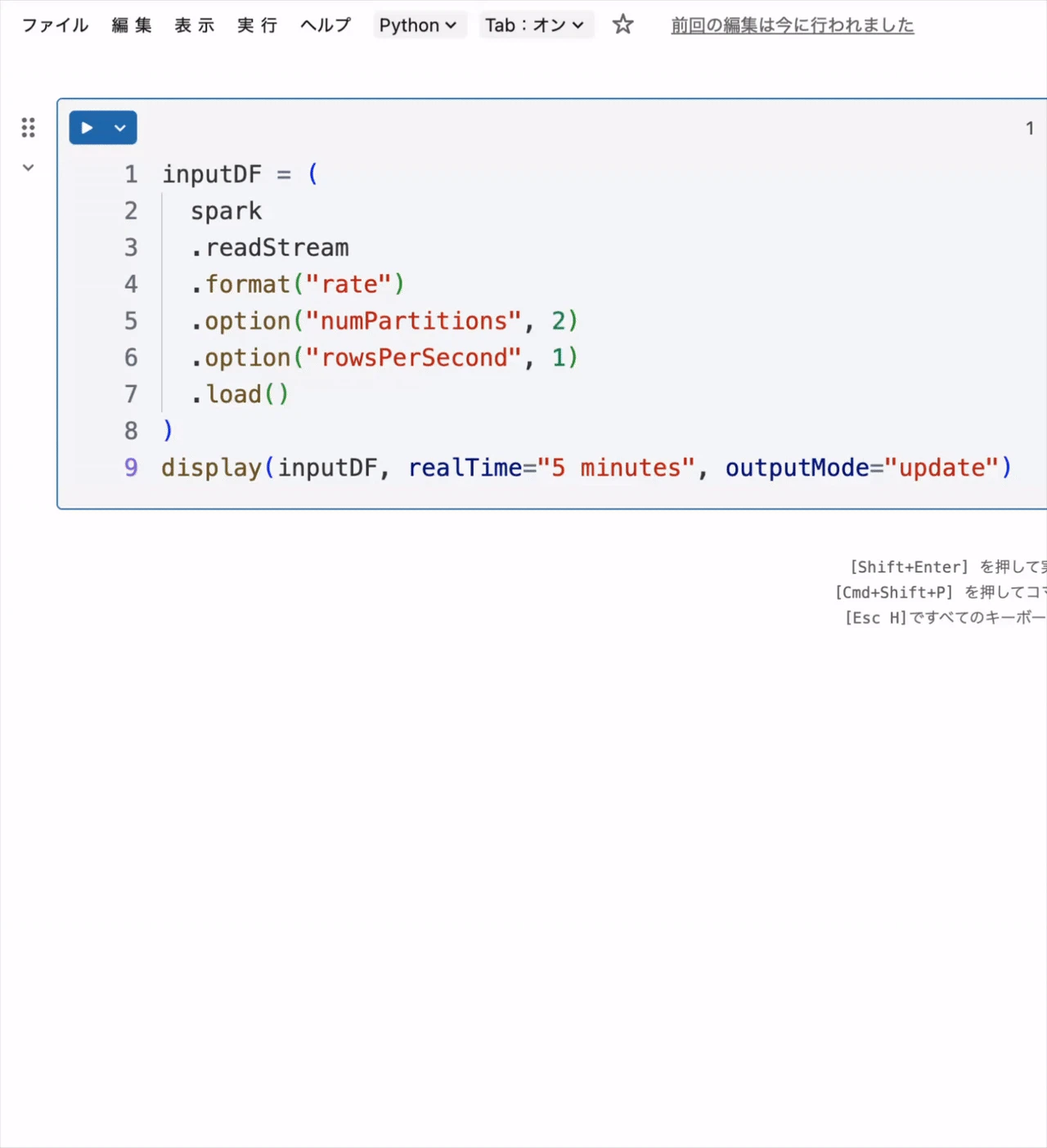
以下のコードをノートブックのセルに貼り付けて実行します。この例では、指定したレートで行を生成するレートソースを使い、結果をリアルタイムで表示します。
realTimeトリガーを使ったdisplay関数はDatabricks Runtime 17.1以降で利用できます。
Python
inputDF = (
spark
.readStream
.format("rate")
.option("numPartitions", 2)
.option("rowsPerSecond", 1)
.load()
)
display(inputDF, realTime="5 minutes", outputMode="update")
Scala
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.streaming.OutputMode
val inputDF = spark
.readStream
.format("rate")
.option("numPartitions", 2)
.option("rowsPerSecond", 1)
.load()
display(inputDF, trigger=Trigger.RealTime(), outputMode=OutputMode.Update())
コードを実行すると、新しい行が生成されるたびにリアルタイムで更新されるテーブルが表示されます。テーブルにはtimestamp列と、行ごとに増加するvalue列が表示されます。
コードの解説
| パラメーター | 説明 |
|---|---|
format("rate") |
外部依存なしで行を一定レートで生成する組み込みソース。テスト用途に便利 |
numPartitions |
生成データのパーティション数 |
rowsPerSecond |
1秒あたりに生成する行数 |
realTime="5 minutes" (Python) |
リアルタイムモードを有効化。間隔はチェックポイントの進行頻度を指定。長い間隔ほどチェックポイント頻度は下がるが、障害後のリカバリ時間が長くなる場合がある |
Trigger.RealTime() (Scala) |
デフォルトのチェックポイント間隔でリアルタイムモードを有効化。Trigger.RealTime("5 minutes")のように間隔指定も可能 |
outputMode="update" |
リアルタイムモードでは更新出力モード (update) が必須 |
実行結果
クエリ実行後、display関数によって継続的に更新されるテーブルが作成されます。各行には以下が含まれます。
- timestamp : レートソースによって行が生成された時刻
- value : 新しい行ごとに単調増加するカウンター
テーブルは最小限の遅延で更新され続け、リアルタイムモードの主な利点であるバッチ処理を待たずにデータをすぐに確認・対応できることを実感できます。
まとめ
この記事では、Databricksの構造化ストリーミングのリアルタイムモードを試すための手順を紹介しました。
- リアルタイムモード用のクラスター設定 (専用モード、Photon無効、オートスケール無効、Spark config追加)
-
realTimeトリガーによるリアルタイム処理の有効化 - ノートブックの
display関数を使ったインタラクティブな動作確認
次のステップとして、KafkaやKinesisなど実際のソースを使った本番パイプラインの構築に挑戦してみてください。