最近、GEPAというキーワードを見かけるなと思っていたら、Databricksドキュメントにもチュートリアルが追加されていました。
勉強を兼ねてチュートリアルを動かしてみます。
GEPAとは
GEPA(Genetic-Pareto)は、AIプロンプトやコードなどのテキストコンポーネントを自動最適化するフレームワークです。MLflow 3.5以降で mlflow.genai.optimize_prompts() APIを通じて利用できます。
主な特徴
リフレクティブ(内省的)な進化
GEPAは単なるスコアだけでなく、テキストフィードバックも活用します。「なぜそのスコアになったのか」を分析し、改善方法を内省的に特定することで、少ない試行回数で高性能なプロンプトを提案できます。
Paretoフロンティアの活用
最良の単一候補だけを進化させる(局所最適に陥りやすい)のではなく、複数の優秀な候補を維持します。各評価インスタンスで最高スコアを達成した候補の集合(Paretoフロンティア)から次の候補を選択することで、探索と活用のバランスを取ります。
フレームワーク非依存
MLflowプロンプトレジストリでプロンプトを管理していれば、LangChain、OpenAI Agents SDK、CrewAI、独自実装など、どのエージェントフレームワークでも利用可能です。
最適化の流れ
- 現在のプロンプトをトレーニングデータで評価
- 失敗パターンと共通の問題を分析
- 改善されたプロンプトバリエーションを生成
- バリエーションをテストして最良のものを発見
- 収束または最大呼び出し回数まで反復
基本的な使い方
import mlflow
from mlflow.genai.optimize import GepaPromptOptimizer
from mlflow.genai.scorers import Correctness
# 初期プロンプトを登録
prompt = mlflow.genai.register_prompt(
name="my_prompt",
template="classify this: {{query}}",
)
# 予測関数を定義
def predict_fn(query: str) -> str:
prompt = mlflow.genai.load_prompt("prompts:/my_prompt/1")
# LLM呼び出し処理
return response
# トレーニングデータ(入力と期待される出力)
dataset = [
{
"inputs": {"query": "..."},
"outputs": {"response": "BACKGROUND"},
"expectations": {"expected_facts": ["..."]}
},
# ...
]
# 最適化実行
result = mlflow.genai.optimize_prompts(
predict_fn=predict_fn,
train_data=dataset,
prompt_uris=[prompt.uri],
optimizer=GepaPromptOptimizer(
reflection_model="databricks:/databricks-claude-sonnet-4-5"
),
scorers=[Correctness(model="databricks:/databricks-gpt-5")],
)
# 最適化されたプロンプトを取得
optimized_prompt = result.optimized_prompts[0]
print(f"Optimized template: {optimized_prompt.template}")
性能
論文「GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning」(arxiv:2507.19457)によると:
| 比較対象 | 結果 |
|---|---|
| GRPO(強化学習手法) | 最大20%上回り、試行回数は35分の1 |
| MIPROv2(従来のプロンプト最適化) | 10%以上の改善 |
MLflowブログのHotpotQA実験では、100サンプル・500回の最大メトリック呼び出しで約30分の実行時間で、精度が46%から60%へ14ポイント向上しました。
GEPAが改善する観点の例
HotpotQAの実験では、以下のような改善が自動的に行われました:
- 出力フォーマットの明確化: 有効な回答の定義を明示
- Yes/No質問の検出強化: Is/Are/Was/Wereなどの指示語を例示
- マルチドキュメント推論の許可: 複数文書からの情報統合を指示
- エッジケースへの対応: 最適化中に発見された失敗パターンへの直接対処
- フォーマット保持の厳格化: スペル、大文字小文字、フォーマットの一致を要求
参考リンク
- MLflow Prompt Optimization ドキュメント
- Databricks プロンプト最適化チュートリアル(日本語)
- GEPA GitHub リポジトリ
- 論文: GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
- MLflow Blog: Systematic Prompt Optimization for OpenAI Agents with GEPA
チュートリアルのウォークスルー
以下は、シンプルなプロンプトこのクエリを分類してくださいを最適化するクイックスタート例です。この例ではGPT-OSS 20Bを使用します。
依存関係のインストール
%pip install --upgrade mlflow databricks-sdk dspy openai
# Python環境を再起動します
dbutils.library.restartPython()
このノートブックを正常に実行するには、Databricks Foundation Model APIへのアクセス権が必要です。
import mlflow
import openai
from mlflow.genai.optimize import GepaPromptOptimizer
from mlflow.genai.scorers import Correctness
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# カタログとスキーマを自分のものに変更してください
catalog = "takaakiyayoi_catalog"
schema = "agents"
prompt_registry_name = "qa"
prompt_location = f"{catalog}.{schema}.{prompt_registry_name}"
openai_client = w.serving_endpoints.get_open_ai_client()
# 初期プロンプトを登録
prompt = mlflow.genai.register_prompt(
name=prompt_location,
template="このクエリを分類してください: {{query}}",
)
# 予測関数を定義
def predict_fn(query: str) -> str:
prompt = mlflow.genai.load_prompt(f"prompts:/{prompt_location}/1")
completion = openai_client.chat.completions.create(
model="databricks-gpt-oss-20b",
# PromptVersion.format()でプロンプトテンプレートをロード
messages=[{"role": "user", "content": prompt.format(query=query)}],
)
return completion.choices[0].message.content
関数をテストする
ベースとなるプロンプトでモデルがどれだけ正確に分類できるかを確認します。正確ですが、特定のタスクやユースケースにはまだ最適化されていません。
from IPython.display import Markdown
output = predict_fn("HIVが慢性疾患として現れることで、HIV陽性者は自身の状態を自己管理する責任をより多く担う必要があり、身体的・感情的・社会的な調整を行うことが求められます。")
Markdown(output[1]['text'])
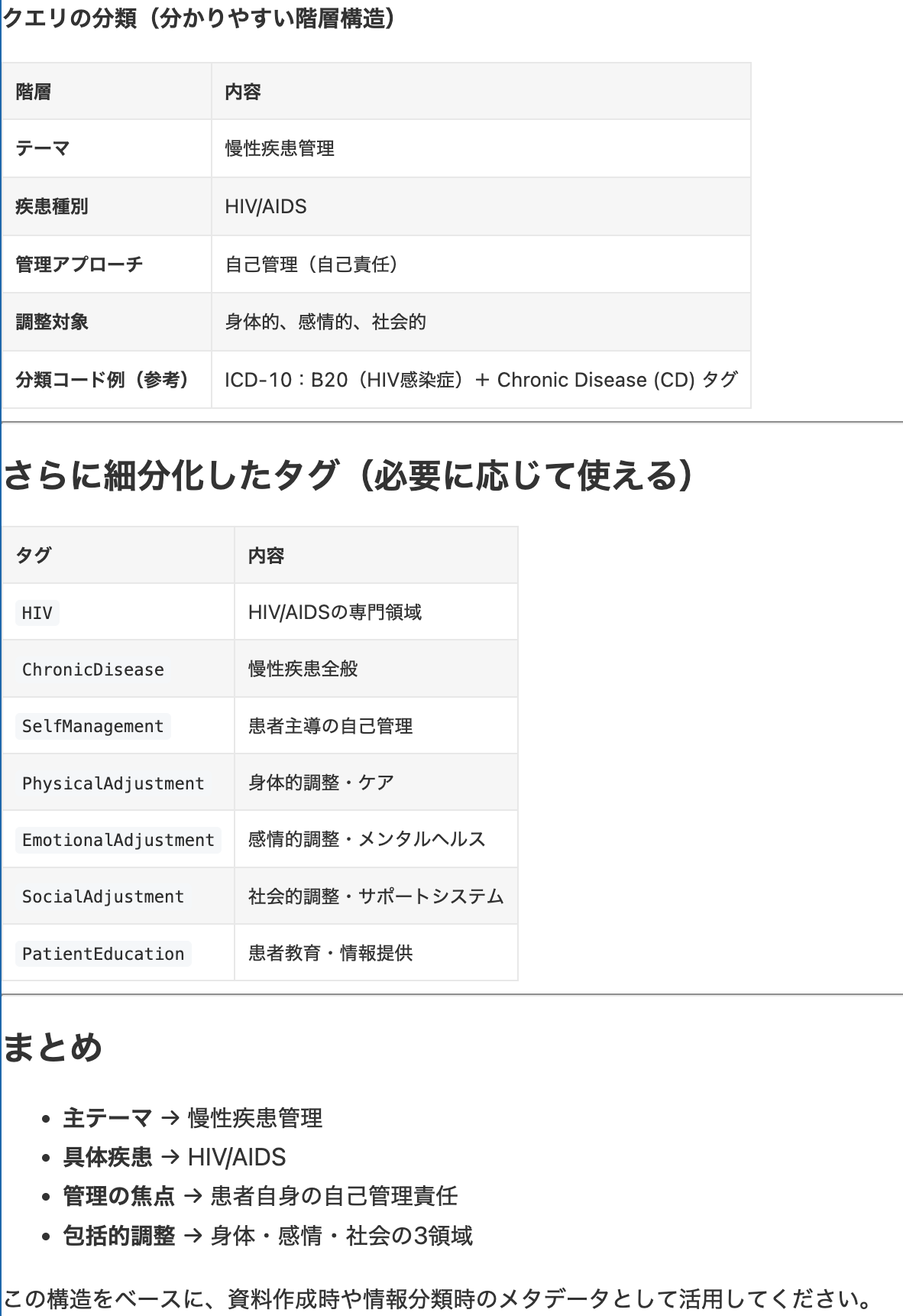
データを使って最適化
期待される応答や事実とともにデータを提供することで、モデルの動作や出力をユースケースに合わせて最適化できます。
この例では、モデルに5つの単語のうち1つだけを出力させます。説明は不要で、その単語のみを返すようにします。
# 入力と期待される出力を含む学習データ
dataset = [
{
"inputs": {"query": "HIVが慢性疾患として現れることで、HIV陽性者は自身の状態を自己管理する責任をより多く担う必要があり、身体的・感情的・社会的な調整を行うことが求められます。"},
"outputs": {"response": "背景"},
"expectations": {"expected_facts": ["分類ラベルは『結論』『結果』『方法』『目的』『背景』のいずれかでなければなりません"]}
},
{
"inputs": {"query": "この論文では、HIV陽性のゲイ男性の自己管理スキルを高めるためのオンラインプログラム『Positive Outlook』の設計と評価について説明します。"},
"outputs": {"response": "背景"},
"expectations": {"expected_facts": ["分類ラベルは『結論』『結果』『方法』『目的』『背景』のいずれかでなければなりません"]}
},
{
"inputs": {"query": "本研究は、オーストラリア在住のHIV陽性男性を介入群または通常ケアの対照群に割り当てるランダム化比較試験として設計されています。"},
"outputs": {"response": "方法"},
"expectations": {"expected_facts": ["分類ラベルは『結論』『結果』『方法』『目的』『背景』のいずれかでなければなりません"]}
},
{
"inputs": {"query": "介入群はオンライングループプログラム『Positive Outlook』に参加します。"},
"outputs": {"response": "方法"},
"expectations": {"expected_facts": ["分類ラベルは『結論』『結果』『方法』『目的』『背景』のいずれかでなければなりません"]}
},
{
"inputs": {"query": "このプログラムは自己効力感理論に基づき、HIVに関連する心理社会的課題を日常生活で管理するためのスキル・自信・能力を高める自己管理アプローチを採用しています。"},
"outputs": {"response": "方法"},
"expectations": {"expected_facts": ["分類ラベルは『結論』『結果』『方法』『目的』『背景』のいずれかでなければなりません"]}
},
{
"inputs": {"query": "参加者は7週間にわたり、週最低90分間プログラムにアクセスします。"},
"outputs": {"response": "方法"},
"expectations": {"expected_facts": ["分類ラベルは『結論』『結果』『方法』『目的』『背景』のいずれかでなければなりません"]}
}
]
# プロンプトを最適化
result = mlflow.genai.optimize_prompts(
predict_fn=predict_fn,
train_data=dataset,
prompt_uris=[prompt.uri],
optimizer=GepaPromptOptimizer(reflection_model="databricks:/databricks-claude-sonnet-4-5"),
scorers=[Correctness(model="databricks:/databricks-gpt-5")],
)
# 最適化されたプロンプトを使用
optimized_prompt = result.optimized_prompts[0]
print(f"最適化されたテンプレート: {optimized_prompt.template}")
最適化に関する情報がMLflowエクスペリメントに記録されています。
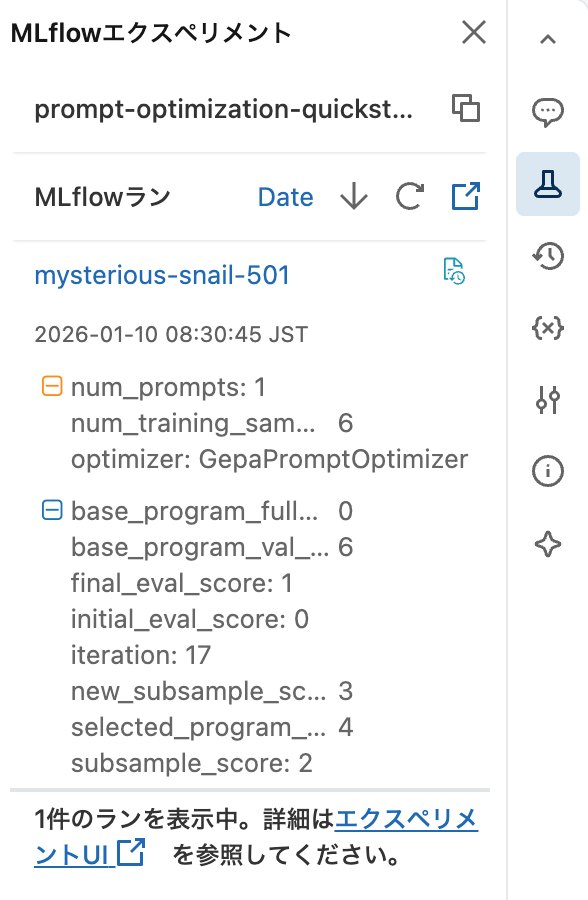
評価ランとして実行されたということですね。
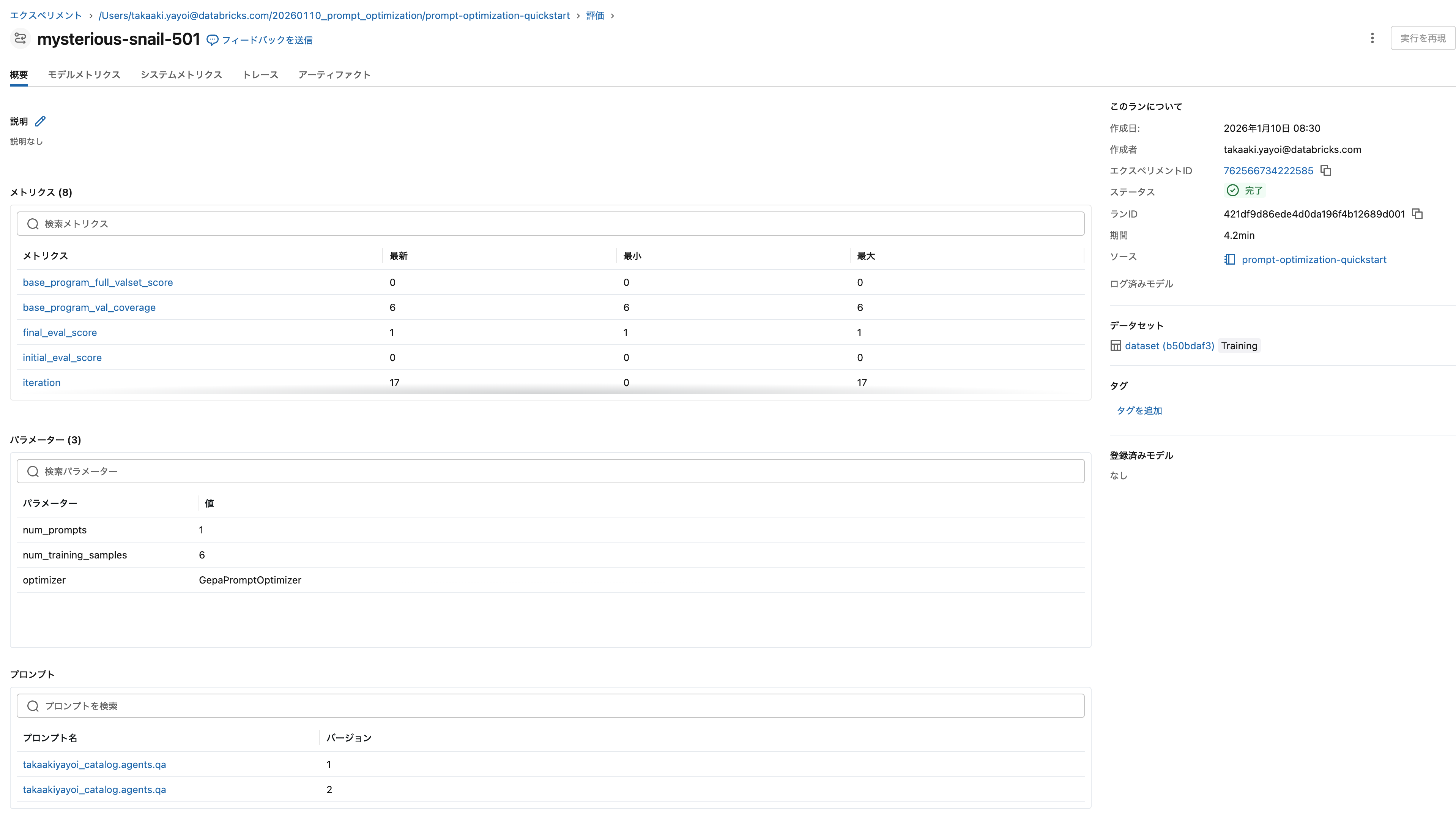
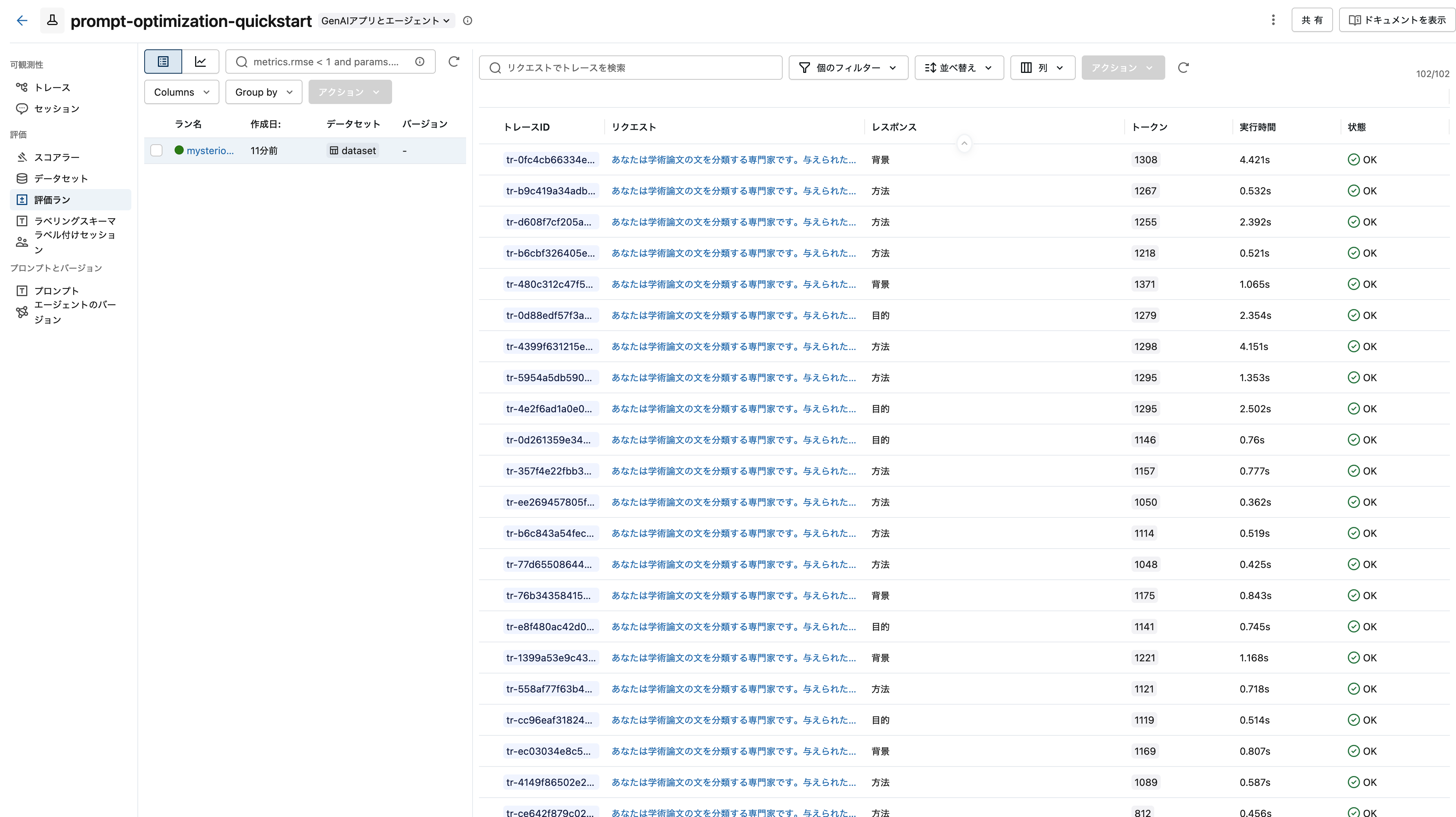
プロンプトを確認する
MLflowエクスペリメントのリンクを開き、以下の手順でプロンプトを確認してください:
- 実験タイプがGenAIアプリ・エージェントになっていることを確認
- プロンプトタブに移動
- 右上の「スキーマを選択」をクリックし、上記で設定したスキーマを入力してプロンプトを表示
バージョン1は素朴でした。
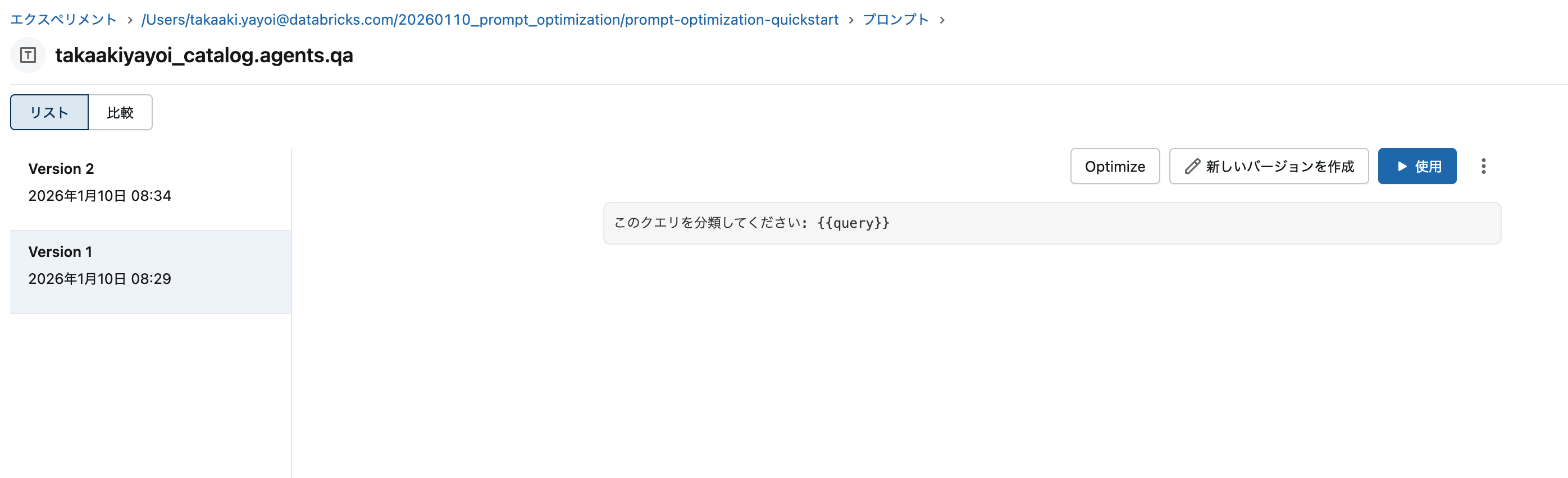
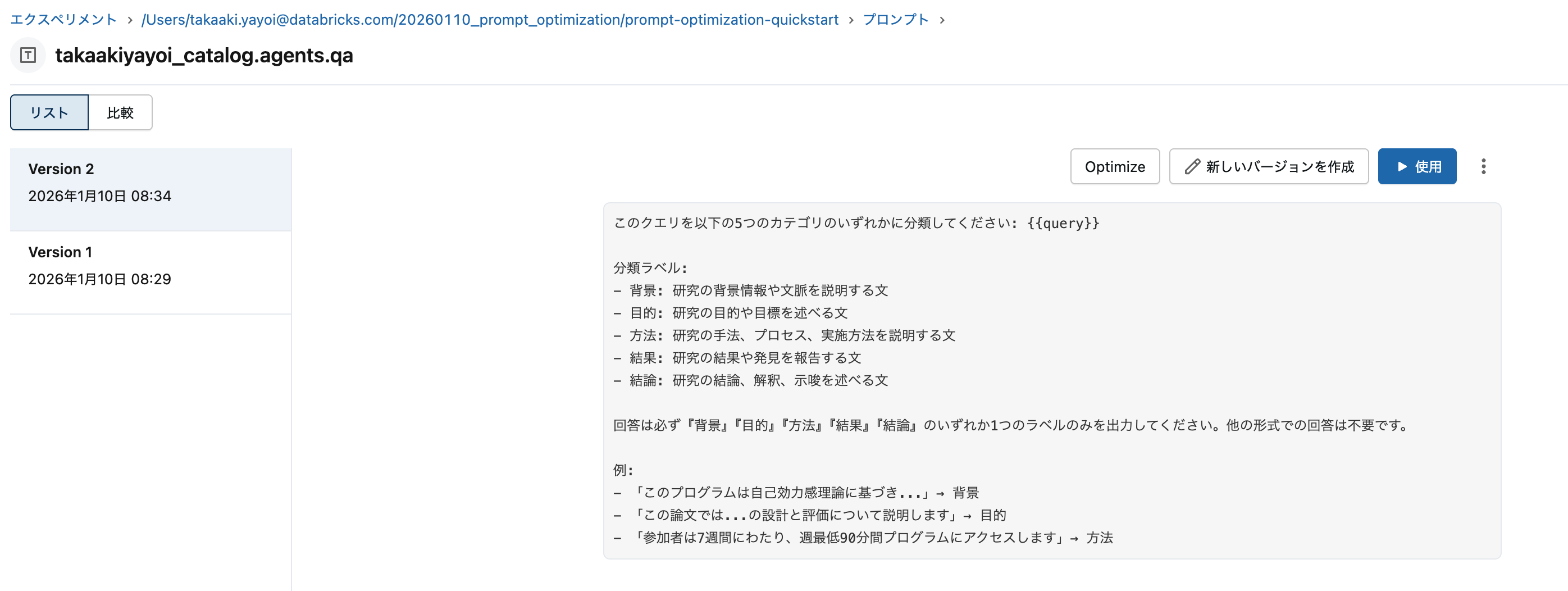
与えたデータセットによって、バージョン2に最適化されました。
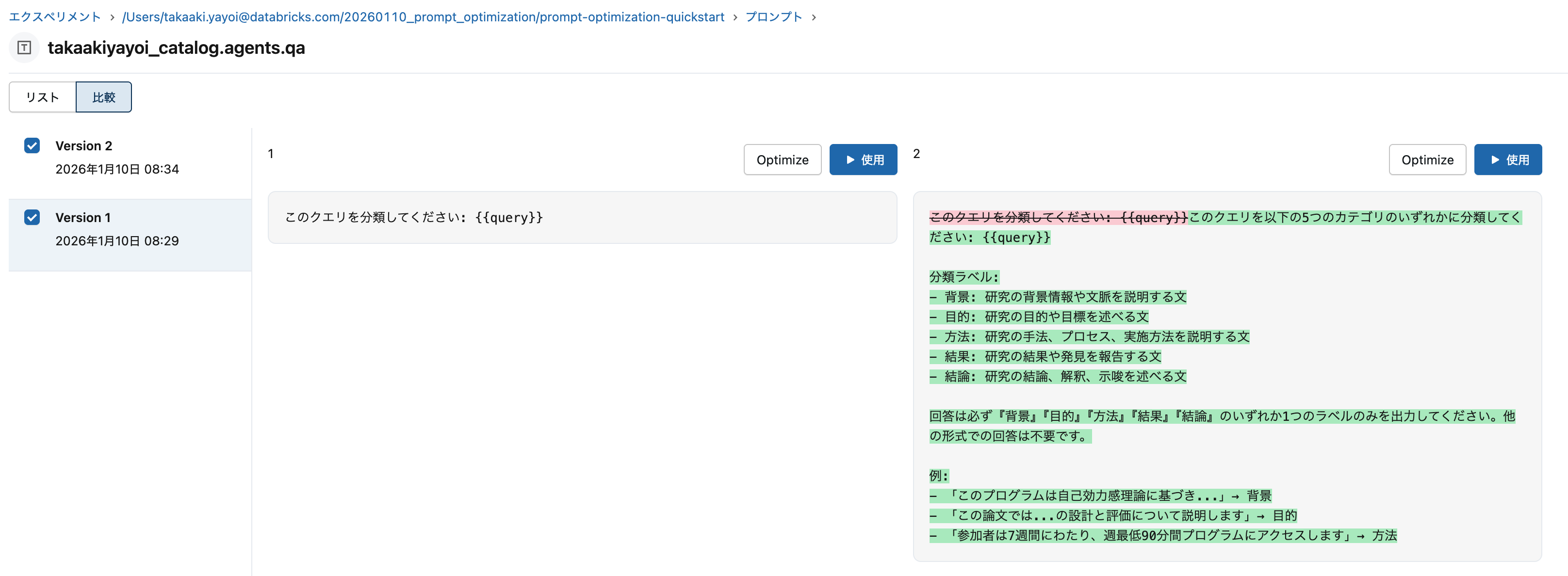
比較もできます。
新しいプロンプトをロードして再度テスト
最適化されたプロンプトの内容を確認し、予測関数にロードしてモデルのパフォーマンスの違いを見てみましょう。
from IPython.display import Markdown
prompt = mlflow.genai.load_prompt(f"prompts:/{prompt_location}/2")
# プロンプトのテンプレートを表示します
Markdown(prompt.template)
このクエリを以下の5つのカテゴリのいずれかに分類してください: {{query}}
分類ラベル:
背景: 研究の背景情報や文脈を説明する文
目的: 研究の目的や目標を述べる文
方法: 研究の手法、プロセス、実施方法を説明する文
結果: 研究の結果や発見を報告する文
結論: 研究の結論、解釈、示唆を述べる文
回答は必ず『背景』『目的』『方法』『結果』『結論』のいずれか1つのラベルのみを出力してください。他の形式での回答は不要です。
例:
「このプログラムは自己効力感理論に基づき...」→ 背景
「この論文では...の設計と評価について説明します」→ 目的
「参加者は7週間にわたり、週最低90分間プログラムにアクセスします」→ 方法
from IPython.display import Markdown
def predict_fn(query: str) -> str:
prompt = mlflow.genai.load_prompt(f"prompts:/{prompt_location}/2")
completion = openai_client.chat.completions.create(
model="databricks-gpt-oss-20b",
# プロンプトテンプレートをPromptVersion.format()でロード
messages=[{"role": "user", "content": prompt.format(query=query)}],
)
return completion.choices[0].message.content
output = predict_fn("HIVが慢性疾患として現れることで、HIV陽性者は自身の状態を自己管理する責任をより多く担う必要があり、身体的・感情的・社会的な調整を行うことが求められます。")
Markdown(output[1]['text'])
背景
まとめ
GEPAは、手動でのプロンプトエンジニアリングにおける「試行錯誤の繰り返し」という課題を、データ駆動で体系的なアプローチに変革するツールです。
従来、プロンプトの改善は経験と勘に頼る部分が大きく、改善の保証もありませんでした。GEPAはLLMによるリフレクション(内省)とParetoフロンティアを活用した探索により、少ない試行回数で効果的なプロンプトを自動生成します。
MLflow 3.5以降で mlflow.genai.optimize_prompts() として統合されたことで、特定のフレームワークに縛られることなく、既存の生成AIアプリケーションに容易に導入できるようになりました。プロンプトをMLflowプロンプトレジストリで管理していれば、数行のコード追加で自動最適化の恩恵を受けられます。
実際にチュートリアルを実行してみると、シンプルなこのクエリを分類してください: {{query}}というプロンプトが、タスクに特化した詳細な指示を含むプロンプトへと自動的に進化する様子を確認できました。この過程がすべてMLflow上で追跡・記録されるため、どのような改善が行われたかを後から検証することも容易です。
プロンプトエンジニアリングの自動化は、LLMOpsにおける重要なトレンドの一つです。GEPAとMLflowの組み合わせは、生成AIアプリケーションの品質向上を効率化する強力な選択肢となるでしょう。