はじめに
Databricksのパブリックプレビュー機能として提供されている LakeFlow Designer を触ってみたので、機能概要とシンプルなチュートリアルをまとめます。
LakeFlow Designerは、Databricksに直接組み込まれた コード不要かつAIネイティブなビジュアルデータ準備・分析エクスペリエンス です。ドラッグ&ドロップ式のキャンバスと自然言語インタフェース (Genie Code) でデータ変換パイプラインを構築でき、生成されたワークフローはそのまま本番運用向けのコードに裏付けられ、Unity Catalogで完全に管理されます。
これまで「Databricksは使いたいがコードは書けない/書きたくない」というアナリスト層が、プロトタイプから本番運用までシームレスに移行できるようになる、というのが大きな狙いです。
注意 本記事執筆時点 (2026年4月) でLakeFlow Designerは パブリックプレビュー 段階です。
公式ドキュメント: LakeFlowデザイナー | Databricks on AWS
LakeFlow Designerの主要概念
ビジュアルデータ準備
LakeFlow Designerの基本単位は ビジュアルデータ準備 (visual data preparation) です。これは、結果を生成するためにDAG (有向非巡回グラフ) として配置された一連の オペレーター (フィルタ、結合、変換など) で構成されます。
キャンバス
オペレーターを追加・構成・接続するメインワークスペースです。
- パン: スペースキー+ドラッグ、またはトラックパッド2本指スライド
- ズーム: ピンチ/ストレッチ、またはCtrl+スクロール
- 左下ツールバー: ズームイン/アウト、フィットビュー、自動レイアウト、ドラッグモード切替
- 右クリックでコンテキストメニュー (演算子追加、元に戻す、自動レイアウト等)
- Excel/CSVファイルを直接ドラッグ&ドロップ するだけでSourceオペレーターが作成される
オペレーター
ビジュアルデータ準備の構成要素です。結合、変換、フィルタリングといった操作の単位で、キャンバス上で連結してワークフローを構築します。ダブルクリックまたは鉛筆アイコンで設定ペインを開きます。
接続
出力ハンドル (オペレーター右端の円) から入力ハンドル (次のオペレーター左端の円) にドラッグして接続します。データは 左から右へ 流れます。JoinやCombineなど一部のオペレーターは複数の入力接続を受け付けます。
出力ペイン
任意のオペレーターを選択すると画面下部に表示されます。入力データが左側、出力データが右側。
- デフォルトは最大1,000行の サンプル実行
- 完全なデータセットで実行するには「サンプルデータセット」→「完全なデータセット」に切替
- データプロファイリング: サイドバーを開くと、選択データの分布や統計情報が表示される
警告 完全なデータセットで実行すると、すべての上流オペレーターが再実行されるため時間がかかります。
Genie Code
自然言語で変換を記述できるエージェント機能です。Databricksプラットフォームのコンテキストを活用してオペレーターの生成や変更を行います。

- 画像アップロード (プロンプトに画像を含める)
- オブジェクト指定 (@メンションでテーブル/ファイルを参照)
- 新規チャットスレッド開始
- サイドパネルで会話履歴とエージェントの動作詳細を確認
組み込みオペレーター一覧
カテゴリ別に整理します。詳細は組み込みオペレーターを参照してください。
ソースと出力
| オペレーター | 説明 |
|---|---|
| Source | Unity Catalogテーブル、ローカルCSV/Excel、Googleドライブ、SharePointから取り込み |
| Output | Unity Catalogテーブルへ書き出し |
AI機能
1つのオペレーター内で複数のAI関数を連続実行できます。
| 関数 | 説明 |
|---|---|
ai_analyze_sentiment |
感情分析 (positive/negative/neutral/mixed) |
ai_classify |
ユーザー指定ラベルでテキスト分類 |
ai_extract |
定義フィールドで構造化データ抽出 |
ai_fix_grammar |
文法誤り修正 |
ai_gen |
プロンプト応答生成 |
ai_mask |
エンティティマスキング (匿名化) |
ai_similarity |
2文字列の意味的類似度スコア |
ai_summarize |
要約生成 |
ai_translate |
指定言語への翻訳 |
変換系
| オペレーター | 説明 |
|---|---|
| 集計 (Aggregate) | AVG, COUNT, MAX, MEAN, MEDIAN, MIN, PERCENTILE, STDDEV, SUM, VARIANCE |
| 組み合わせる (Combine) | Union/Intersect/Except、Distinct/All戦略 |
| フィルター (Filter) | 条件ビルダー (等しい/含む/より大きい/null等) |
| 参加する (Join) | 内部/完全/左/右結合、複数条件、カスタム式列追加可 |
| 制限 (Limit) | 最大行数制限 |
| ピボット (Pivot) | 行→列 (ピボット) / 列→行 (アンピボット) 双方向 |
| 選別 (Sort) | 複数列ASC/DESC |
| SQL | カスタムSELECT文。他オペレーター名をテーブル名として参照可 |
| 変身 (Transform) | 列の選択/名前変更/順序変更、カスタム列追加 (自然言語↔式双方向) |
| Python | PySparkコード実行。inputs["data"]リスト→result変数に代入 |
整理用 (組織)
| オペレーター | 説明 |
|---|---|
| 注記 (Note) | Markdown対応のドキュメンテーション。データフロー不変 |
| グループ (Group) | 視覚的グルーピング。最小化/展開可能 |
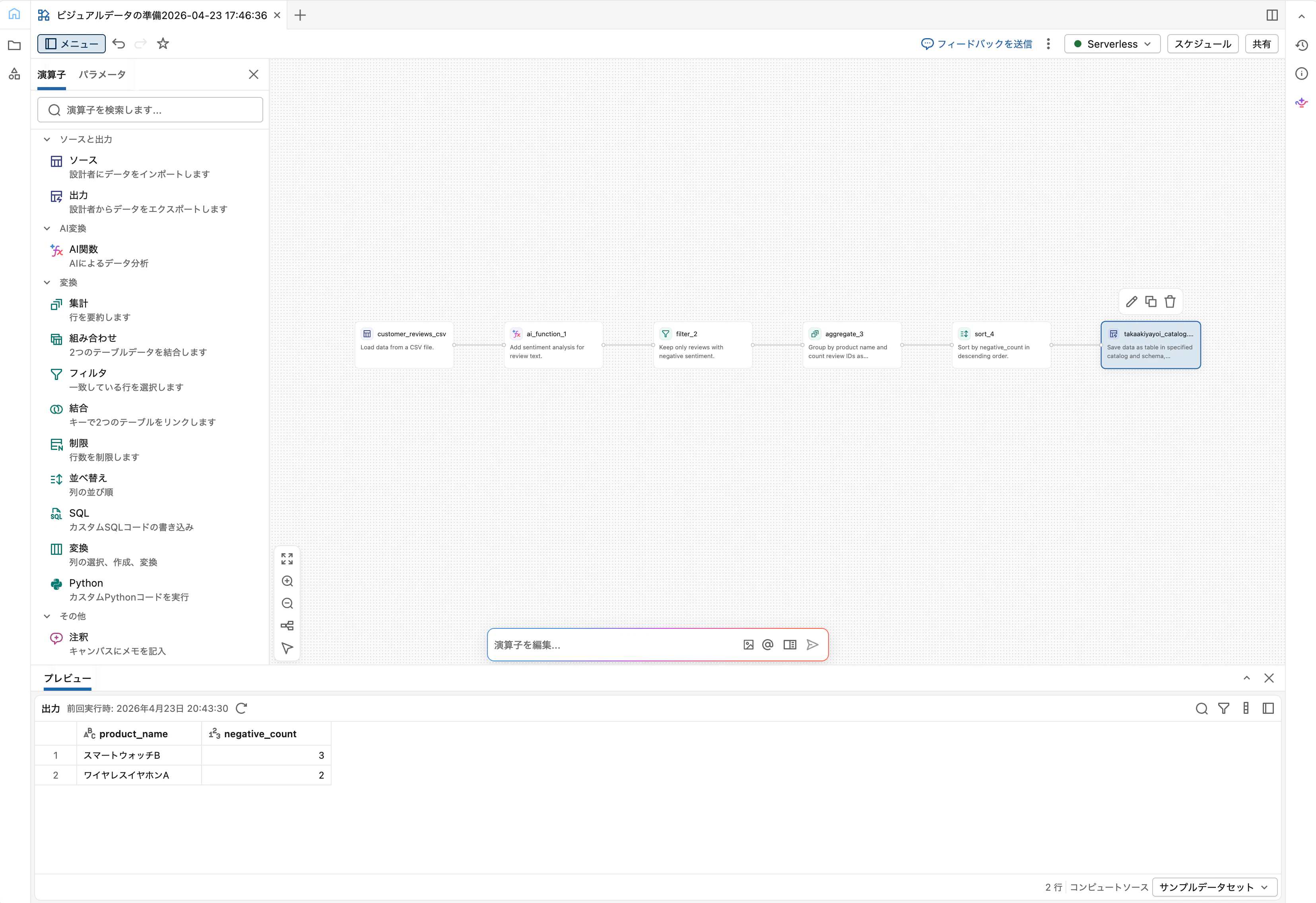
チュートリアル: 顧客レビュー感情分析パイプライン
ここからは実践編です。顧客レビューを感情分析し、ネガティブレビューの多い製品ランキングを作るパイプラインを構築します。所要時間は15〜20分程度。
作るものの全体像
以下の7ステップのパイプラインを組み立てます。
Source (CSV)
↓
AI機能 (ai_analyze_sentiment)
↓
Filter (sentiment = negative)
↓
Aggregate (製品別件数)
↓
Sort (件数降順)
↓
Output (Unity Catalogテーブル)
最終成果物は「改善優先度の高い製品ランキング」テーブルで、営業・CS・プロダクトチームがすぐに使える形に仕上げます。
前提条件
- Unity Catalogが有効なDatabricksワークスペース
- サーバレスまたは汎用コンピュートに対する
CAN USE権限 (最低1つ) -
Databricks AI支援機能が有効 (
ai_analyze_sentimentを使うため) - 書き込み先のカタログ/スキーマ (例:
main.sandbox) に対する権限 -
プレビューでDesignerを有効化していること。

LakeFlow Designerがサイドバー「新規」メニューに見当たらない場合はワークスペース管理者に有効化を依頼してください。
サンプルデータ
以下を customer_reviews.csv として保存してください。3製品×15レビューのシンプルなデータです。
review_id,product_name,review_text,rating,purchase_date
R001,ワイヤレスイヤホンA,音質は良いがバッテリーの持ちが悪い。充電してもすぐ切れて困ります。,2,2026-03-15
R002,ワイヤレスイヤホンA,コスパ最高!音も十分で大満足です。,5,2026-03-17
R003,ワイヤレスイヤホンA,接続が不安定で途切れる。返品したい。,1,2026-03-18
R004,ワイヤレスイヤホンA,この価格帯では文句なし。普通に良い製品。,4,2026-03-20
R005,ワイヤレスイヤホンA,ケースがすぐ傷つく。品質に不満。,2,2026-03-22
R006,スマートウォッチB,画面が小さくて見づらい。期待外れでした。,2,2026-03-18
R007,スマートウォッチB,バッテリーが1週間持つのは素晴らしい。おすすめです。,5,2026-03-20
R008,スマートウォッチB,アプリとの連携がうまくいかない。使い物にならない。,1,2026-03-21
R009,スマートウォッチB,デザインは気に入っているが機能が少ない。,3,2026-03-23
R010,スマートウォッチB,ベルトが硬くて着け心地が悪い。,2,2026-03-25
R011,スマートスピーカーC,音声認識の精度が高く、毎日使っています。最高。,5,2026-03-16
R012,スマートスピーカーC,音質がクリアで音楽鑑賞にも十分使えます。,5,2026-03-19
R013,スマートスピーカーC,設定が簡単で親にもすぐ使えました。,4,2026-03-21
R014,スマートスピーカーC,時々反応しないときがあるが、概ね満足。,4,2026-03-23
R015,スマートスピーカーC,デザインもよく、インテリアに馴染む。,5,2026-03-24
Step 1: ビジュアルデータ準備を新規作成
サイドバー「新規」→「ビジュアルデータ準備」をクリックします。ウェルカム画面が開きます。
Step 2: Sourceオペレーターでデータを取り込む
customer_reviews.csv をキャンバスに直接ドラッグ&ドロップします。自動的にSourceオペレーターが作成され、CSVがワークスペースファイルにアップロードされます。
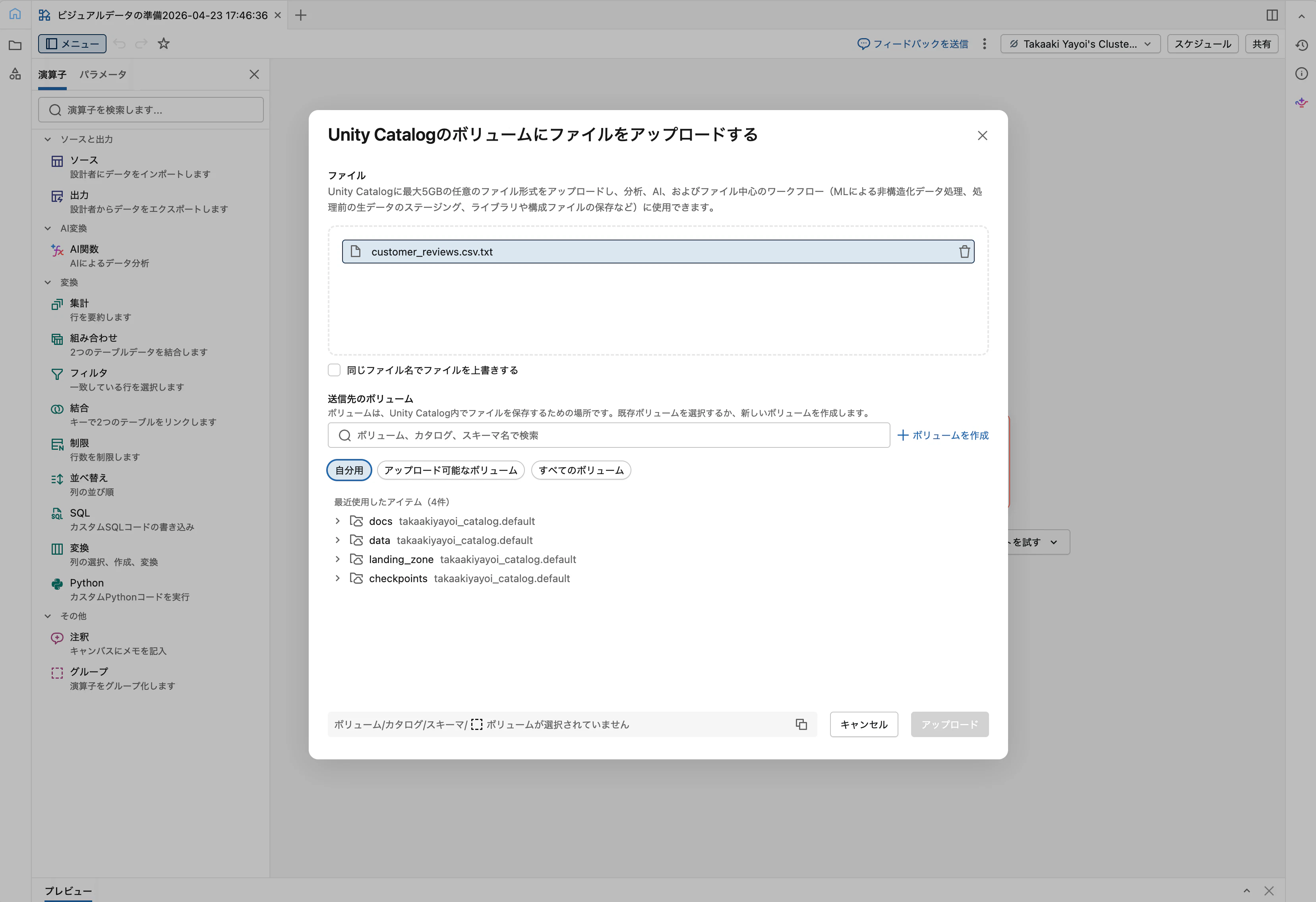
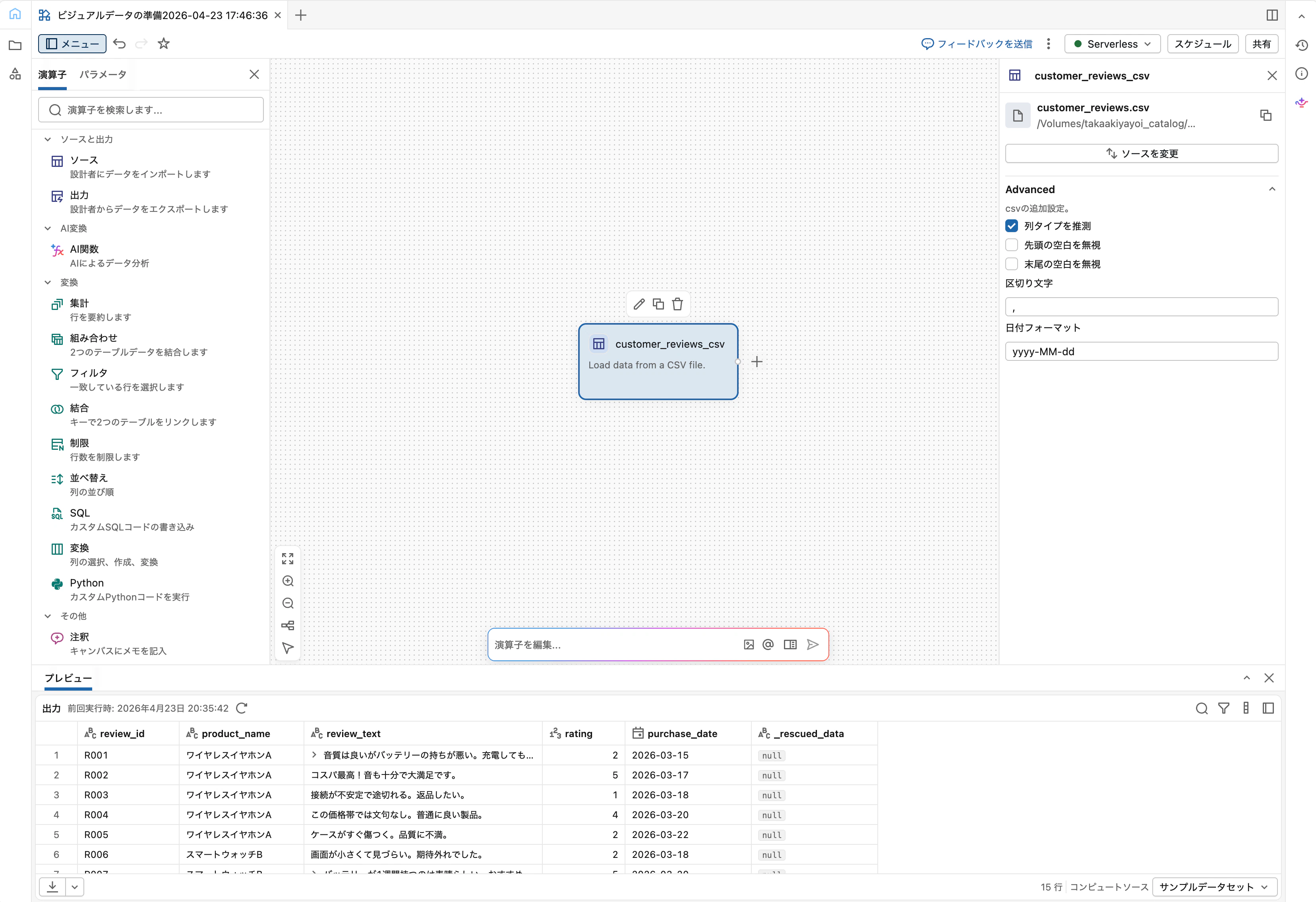
オペレーターを選択して画面下部の出力ペインで中身を確認します。15行のサンプルが見えるはずです。
大量データや本番運用では、演算子メニューから Source を追加→「ファイルからテーブルを作成」でUnity Catalogマネージドテーブルとして取り込む方が高パフォーマンスです。詳細はデータを取り込むを参照してください。
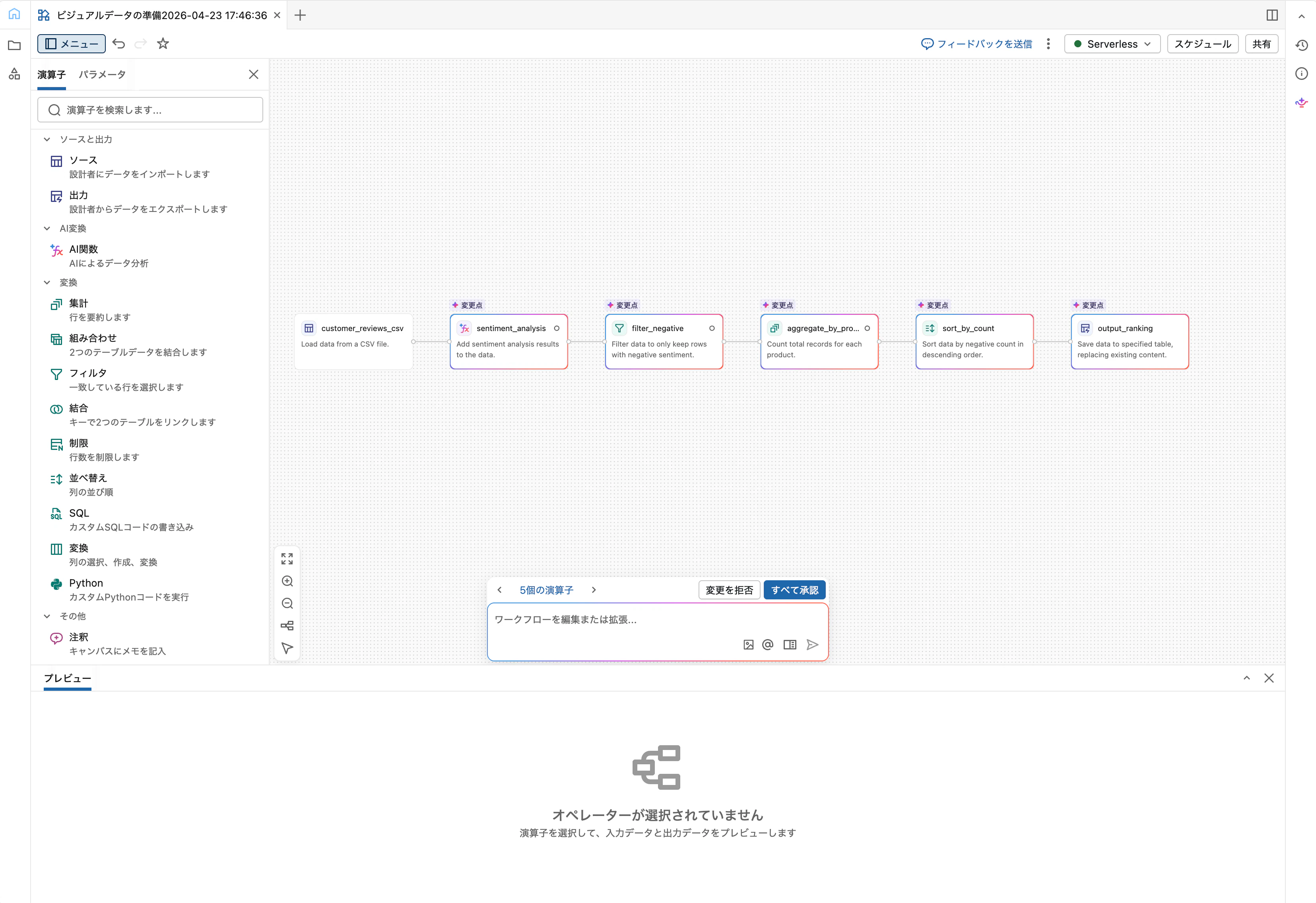
Step 3: AI関数で感情分析
Sourceの右側にある「+」をクリック、または演算子メニューから AI関数 を選択します。
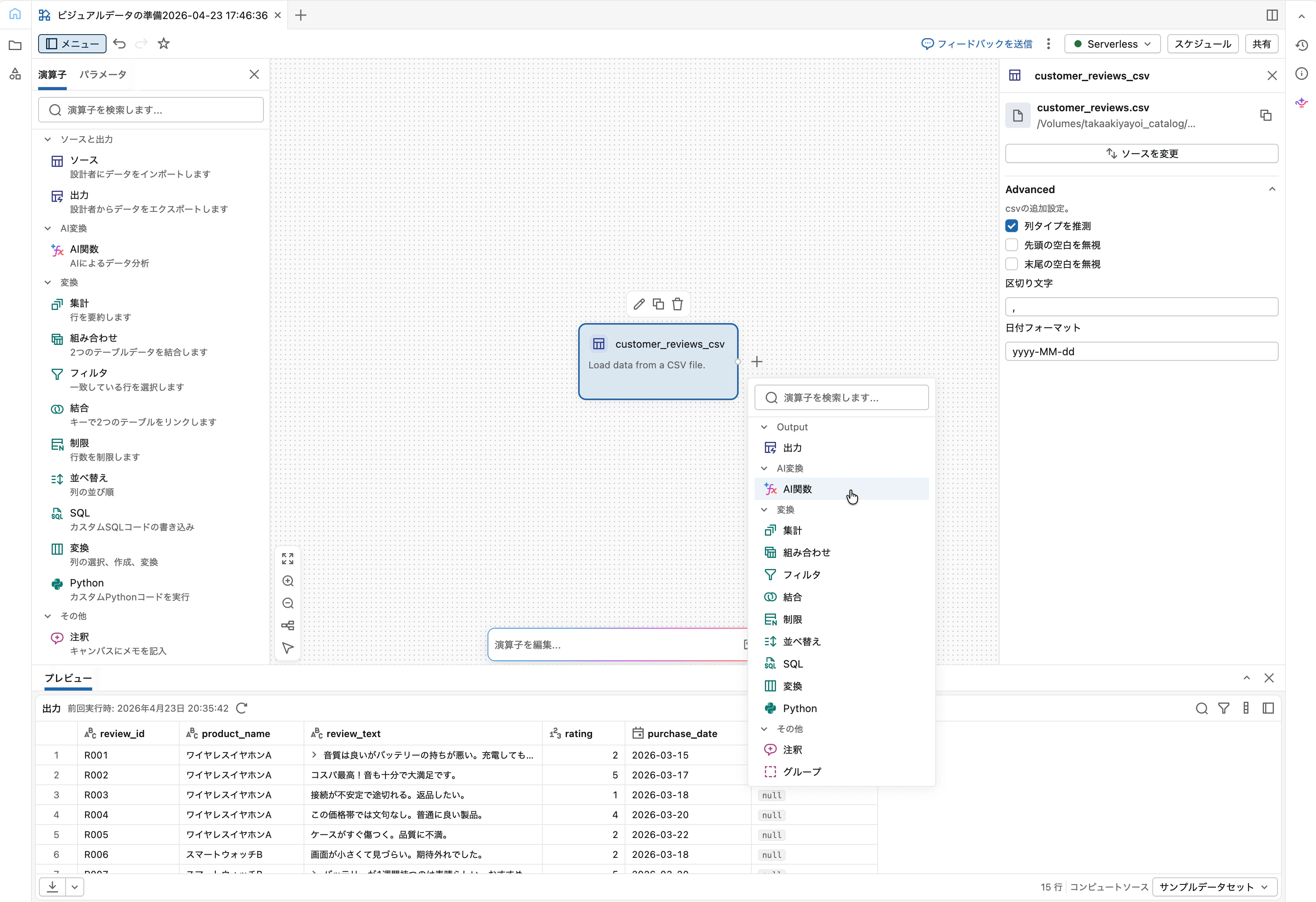
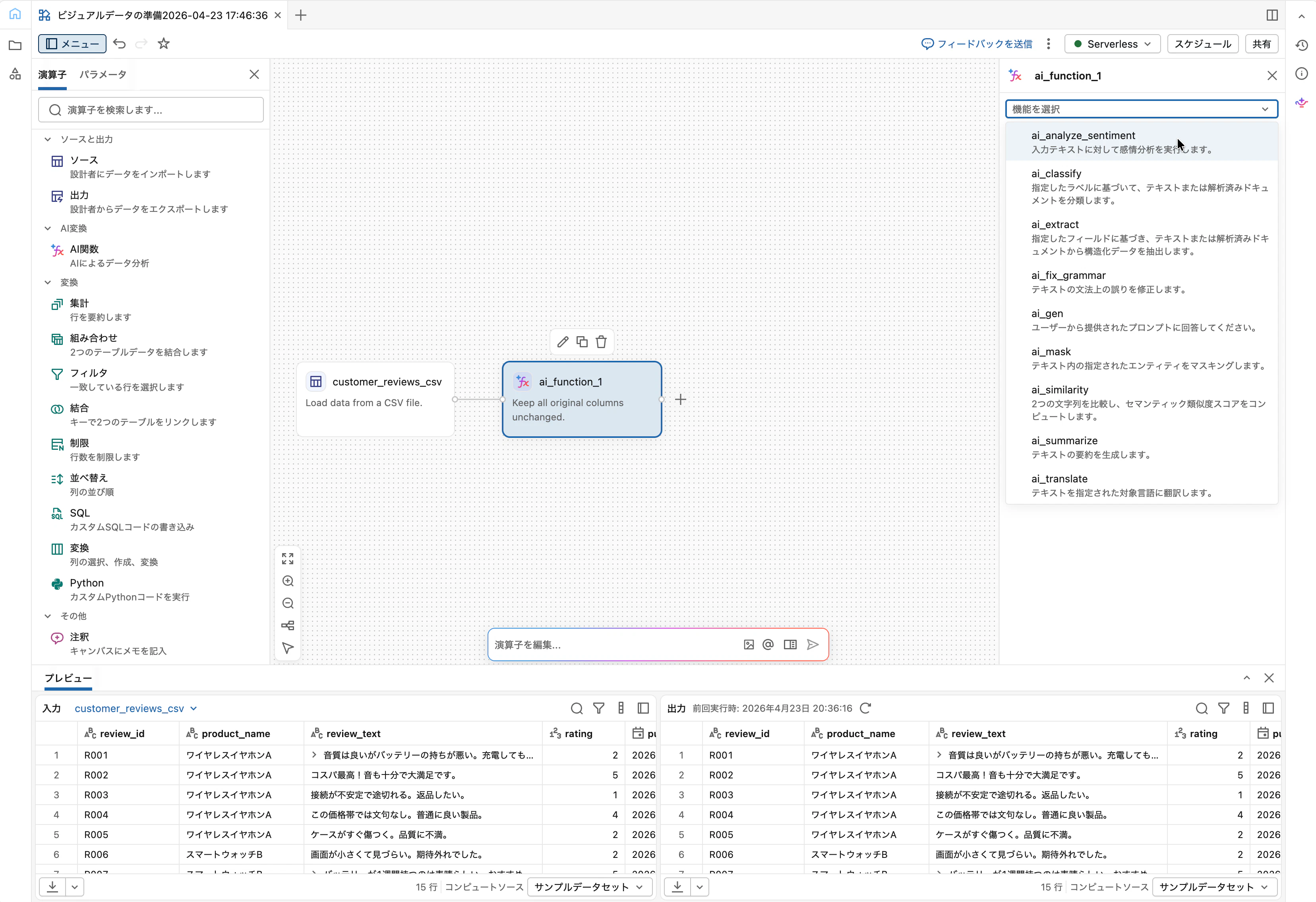
設定ペインは以下のようになります。
-
関数セレクタ (下段ドロップダウン):
ai_analyze_sentimentを選択 -
出力列名 (上段テキストボックス): デフォルトで関数名と同じ文字列が入っているので、
sentimentに書き換え -
分析する列:
review_textを指定
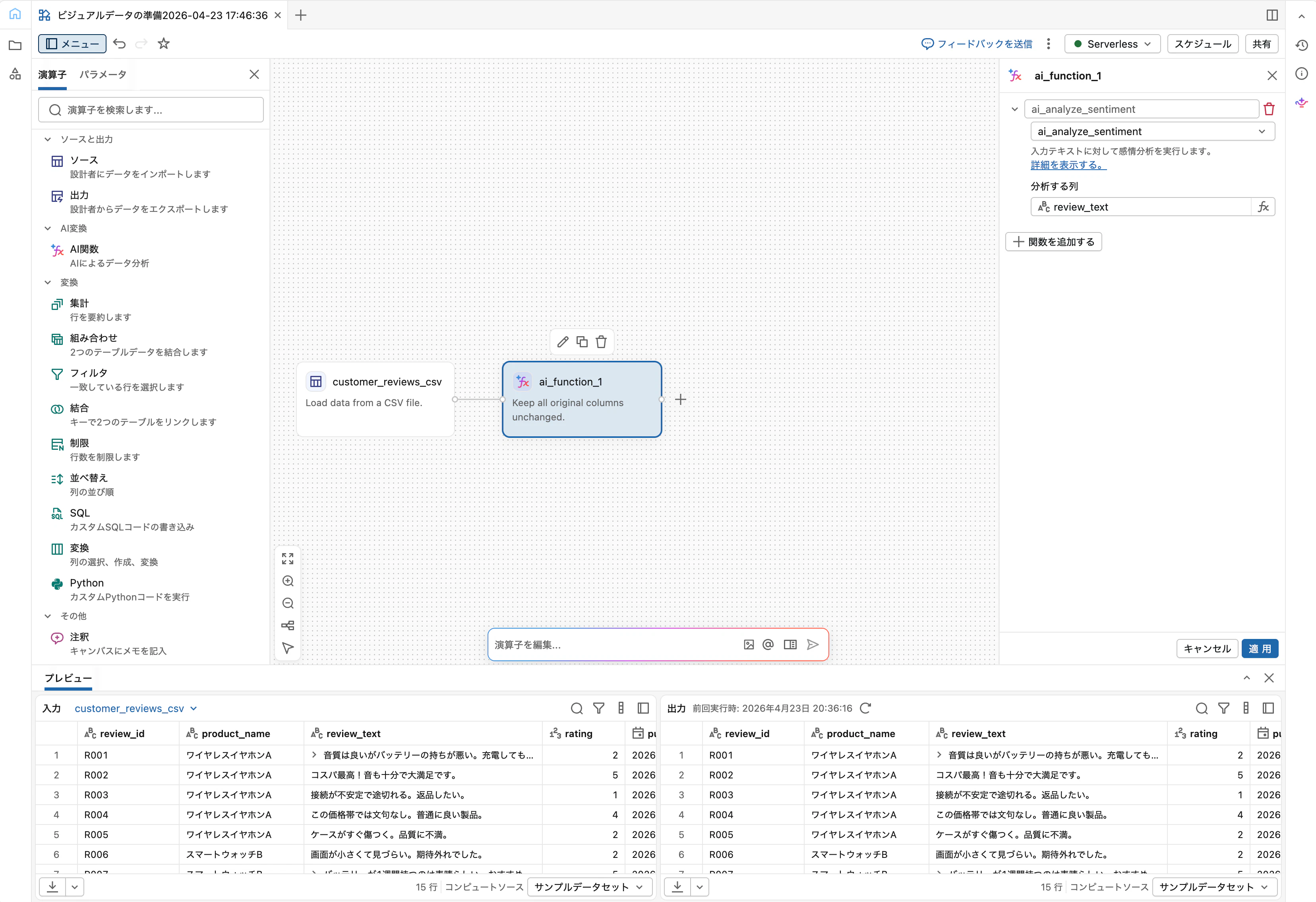
上段のテキストボックスは「関数名ラベル」ではなく 出力列名そのもの です。デフォルトで ai_analyze_sentiment と入っているので紛らわしいですが、ここを書き換えると出力列名が変わります。
「適用」をクリックすると、出力ペイン右側に sentiment 列が追加され、positive/negative/neutral/mixed のいずれかが入っているはずです。
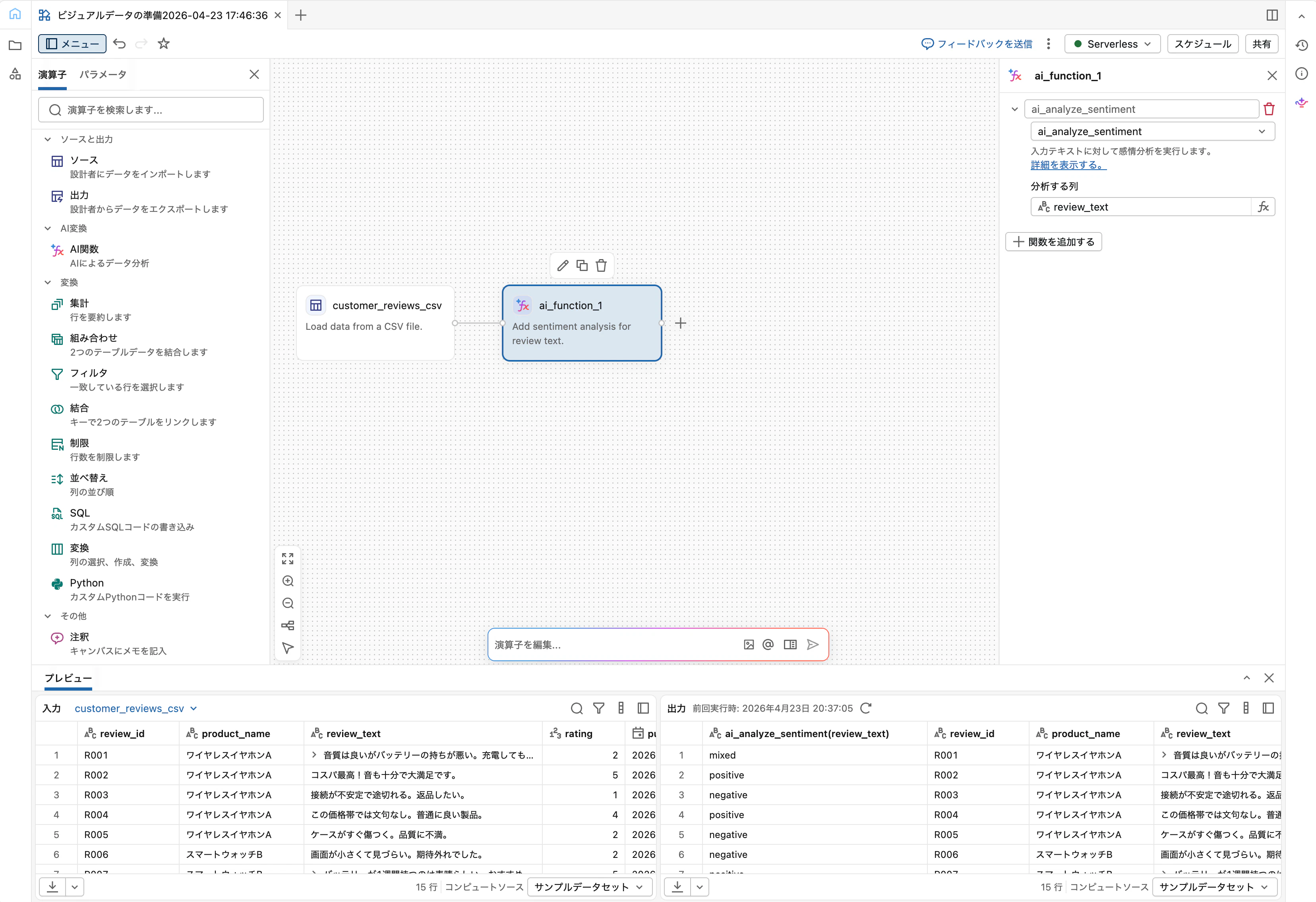
1つのAI機能オペレーター内で「+ 関数を追加する」から複数の関数を連続適用できます。例えば ai_analyze_sentiment と ai_translate を同時に適用すれば、sentiment 列と review_en 列を一度に生成できます。
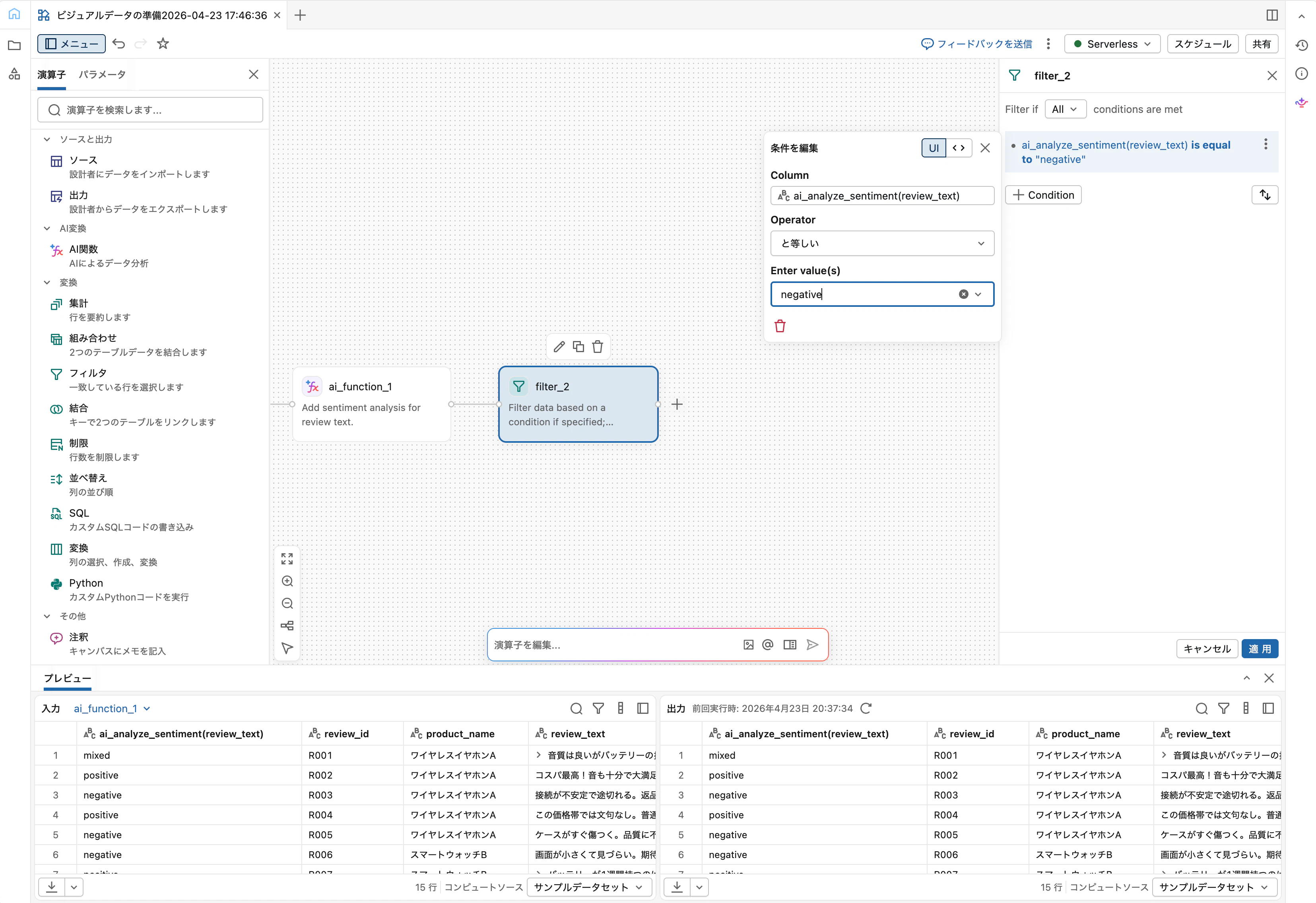
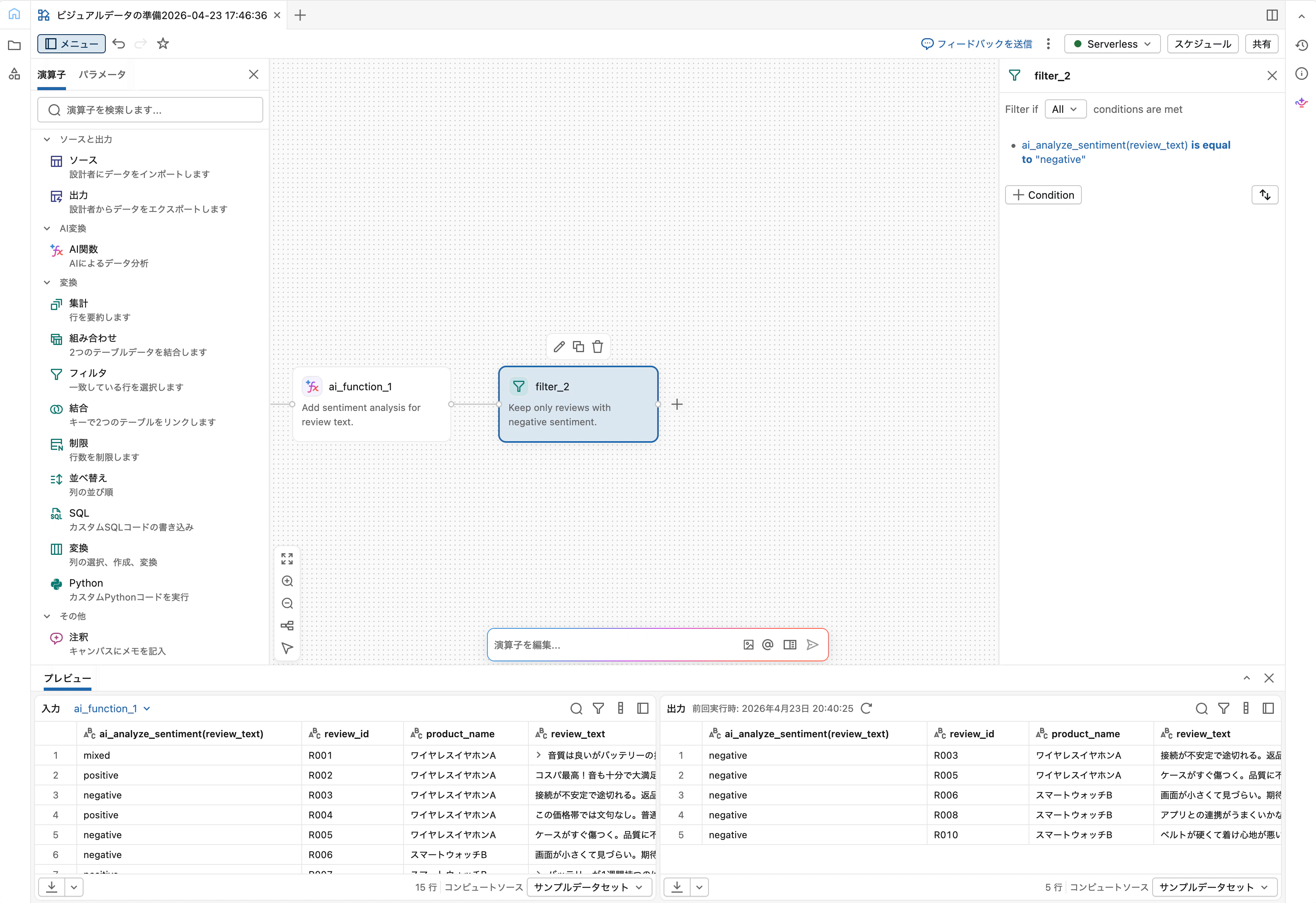
Step 4: Filterでネガティブレビューのみ抽出
AI関数オペレーターに続けて Filter を追加します。条件ビルダーで以下を設定:
- 列:
sentiment - 条件タイプ: 等しい
- 値:
negative
「適用」をクリック。出力ペインで、ネガティブ判定されたレビューのみが残っていることを確認します。
Step 5: Aggregateで製品別に集計
Filterに続けて Aggregate を追加し、以下を設定します。
-
グループ化:
product_name -
集計方法:
- 列:
review_id - 関数:
COUNT - 出力列名:
negative_count
- 列:
「適用」をクリック。結果は製品ごとの行に negative_count が並ぶ形式になります。
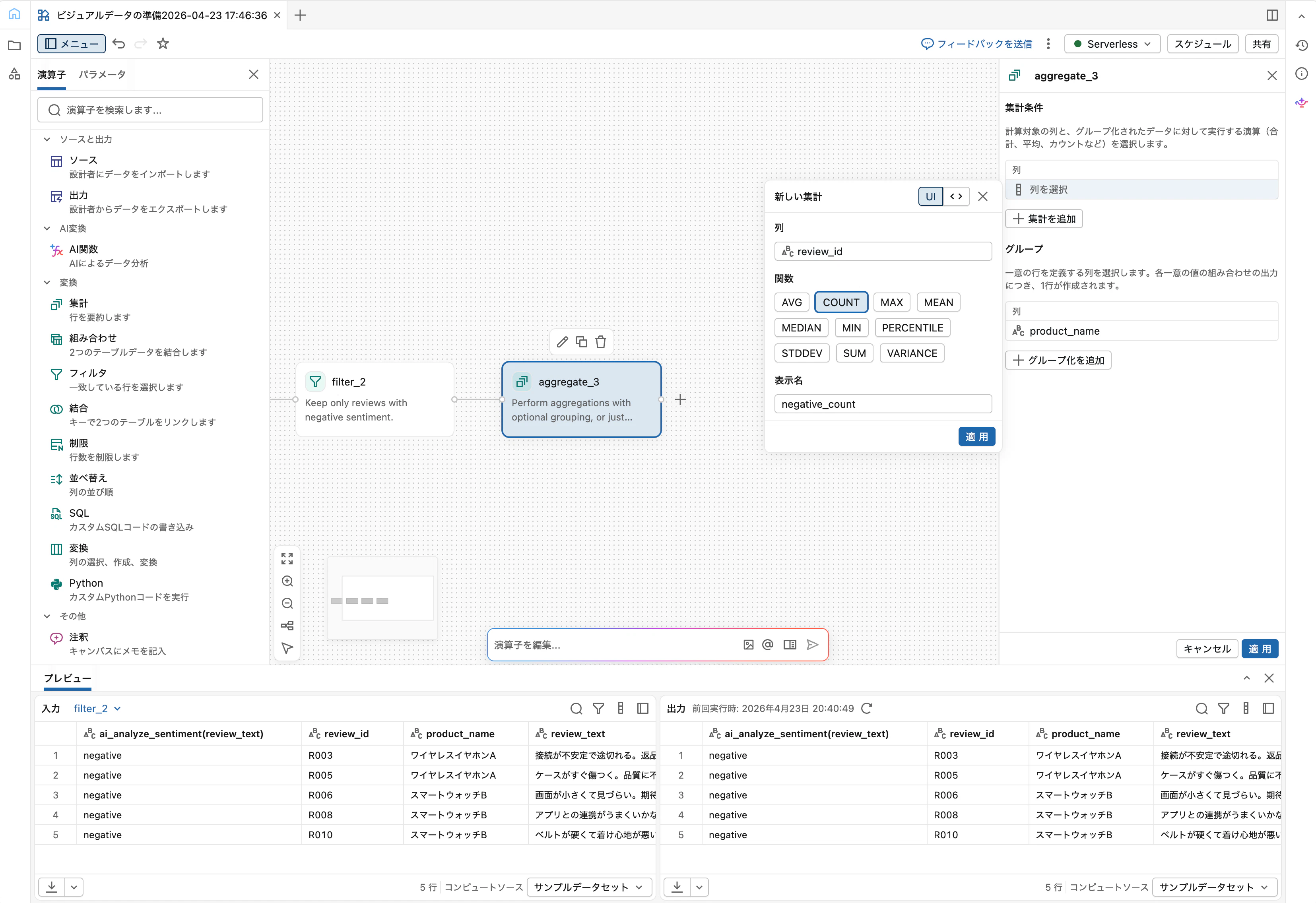
Group byで使用される列は出力に自動的に含まれます。
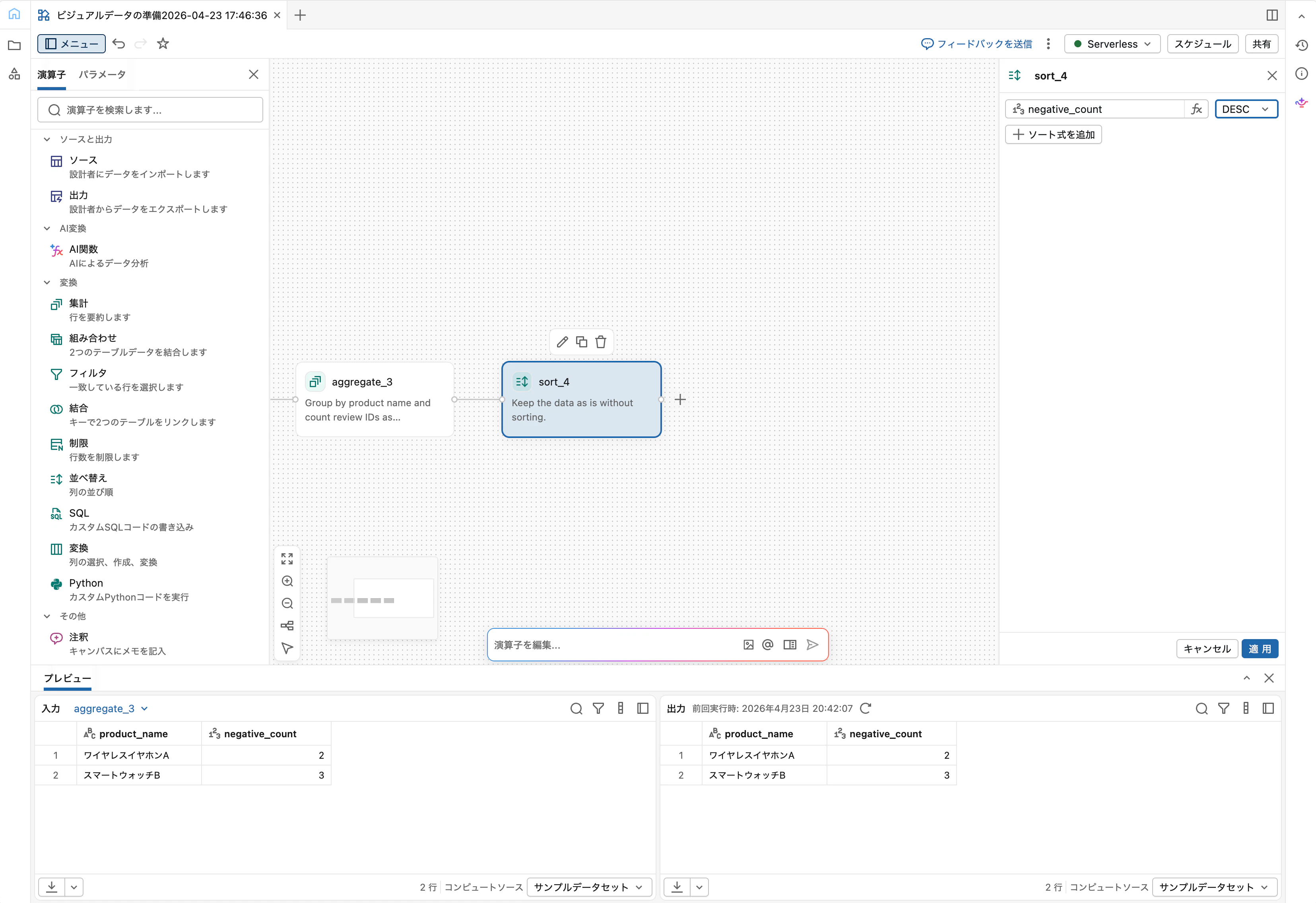
Step 6: Sortで件数降順に並べる
Sort オペレーターを追加し、以下を設定します。
- 列:
negative_count - 順序:
DESC(降順)
ネガティブが多い順、つまり改善優先度が高い順に並びます。
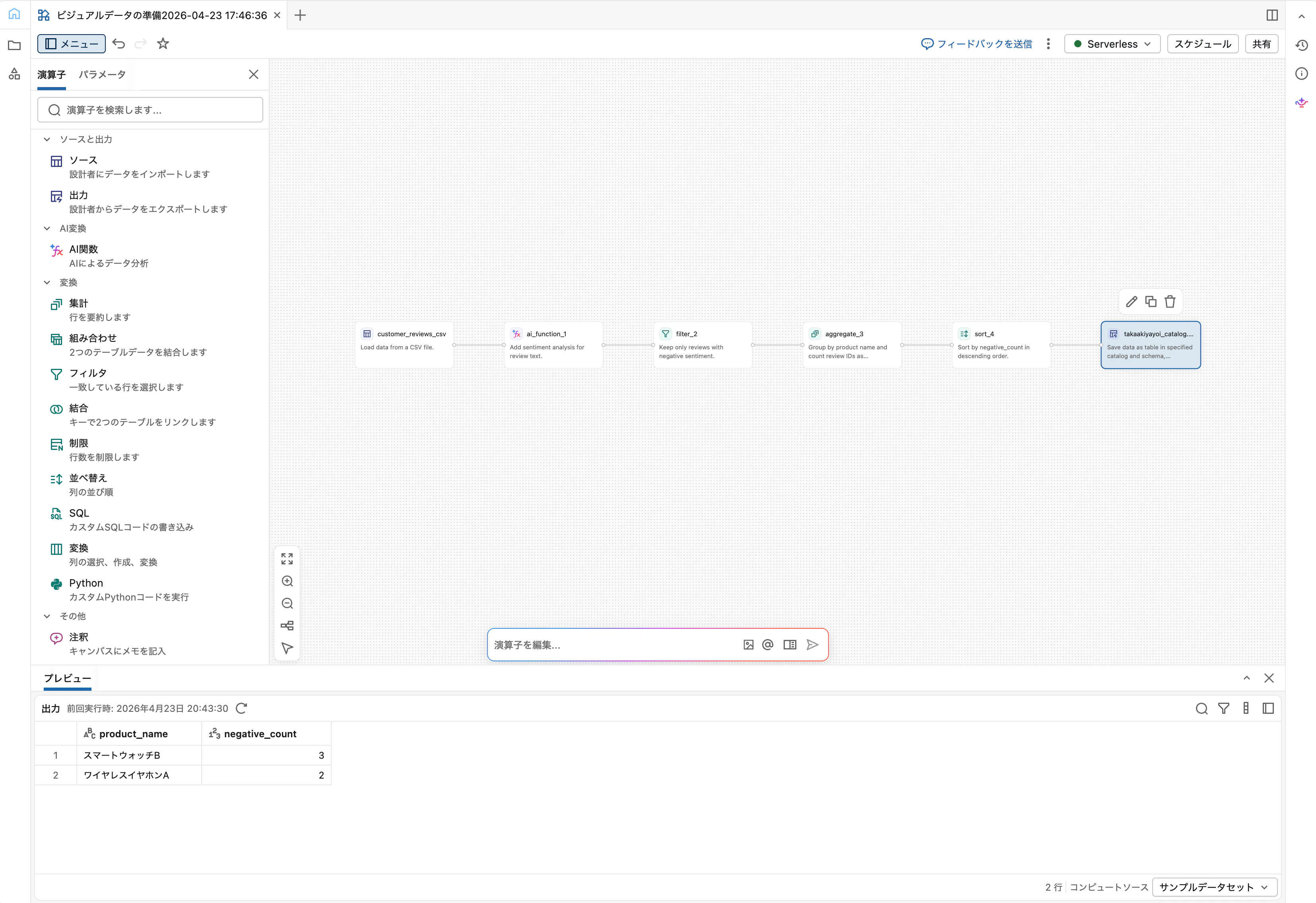
Step 7: OutputでUnity Catalogに書き出す
Sortに続けて Output オペレーターを追加します。
-
テーブル名:
negative_review_ranking -
出力場所: カタログとスキーマを選択 (例:
main.sandbox)
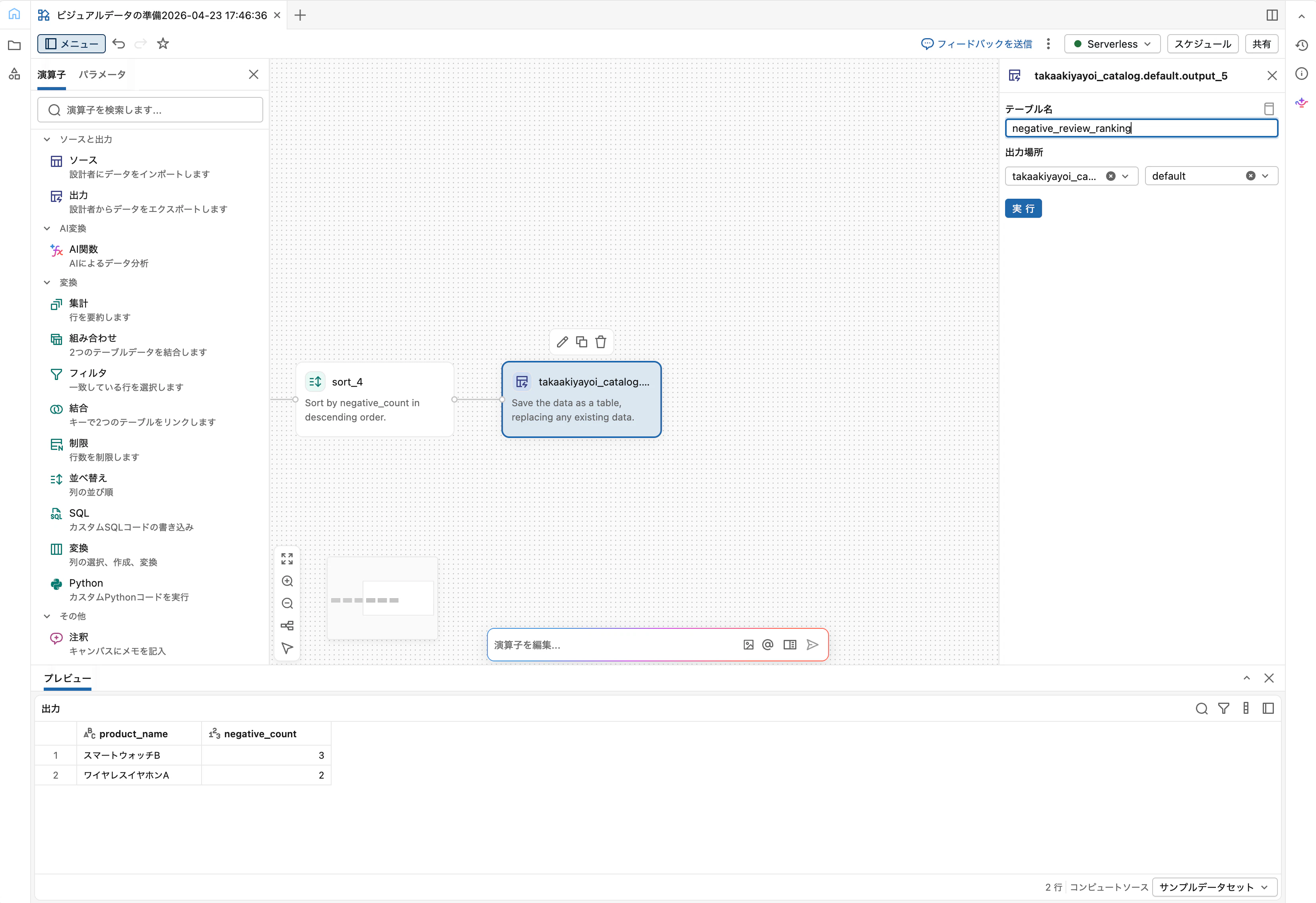
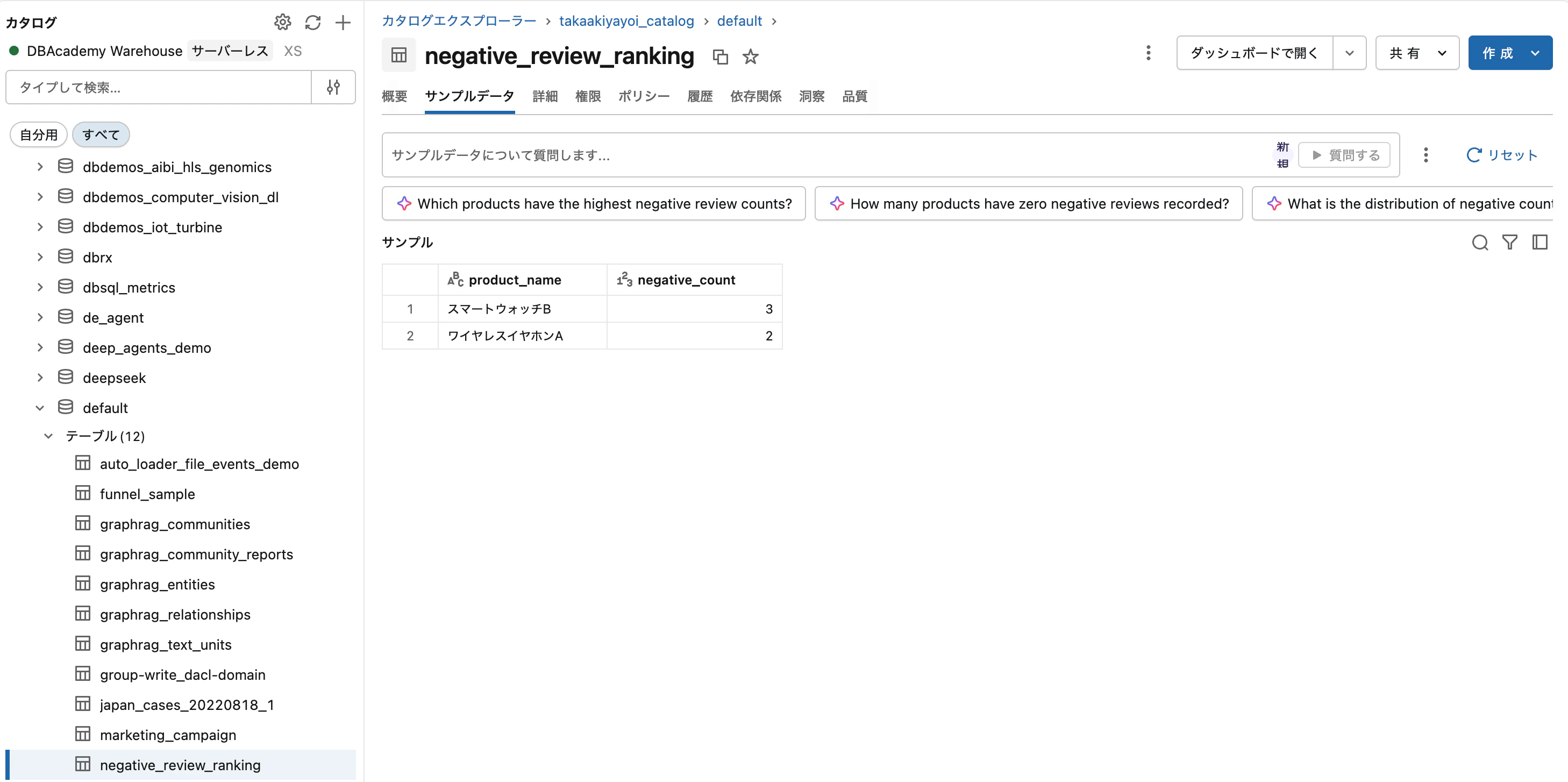
「実行」をクリックすると、完全なデータセットに対してパイプライン全体が実行されます。完了後、カタログエクスプローラーで main.sandbox.negative_review_ranking が作成されていることを確認できます。
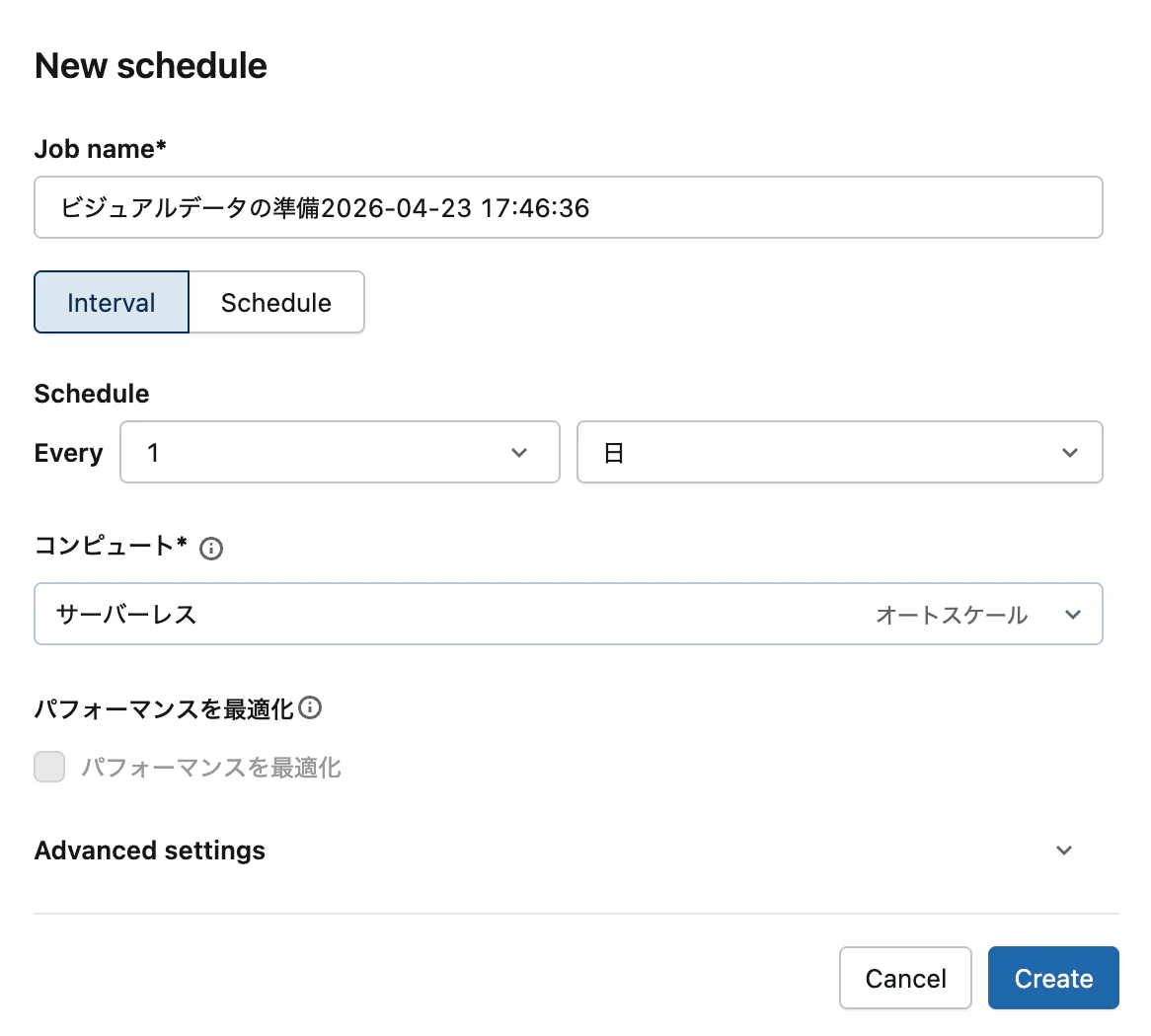
Step 8: スケジュール化して本番運用に乗せる
レビューデータが日次で更新される前提で、自動実行を設定しましょう。
- 直接スケジュール: 上部メニューの「スケジュール」ボタンからジョブ化
- ジョブに追加: Databricksジョブを新規作成して、このビジュアルデータ準備をタスクの1つとして追加。他のタスクと組み合わせて大規模パイプラインを組める
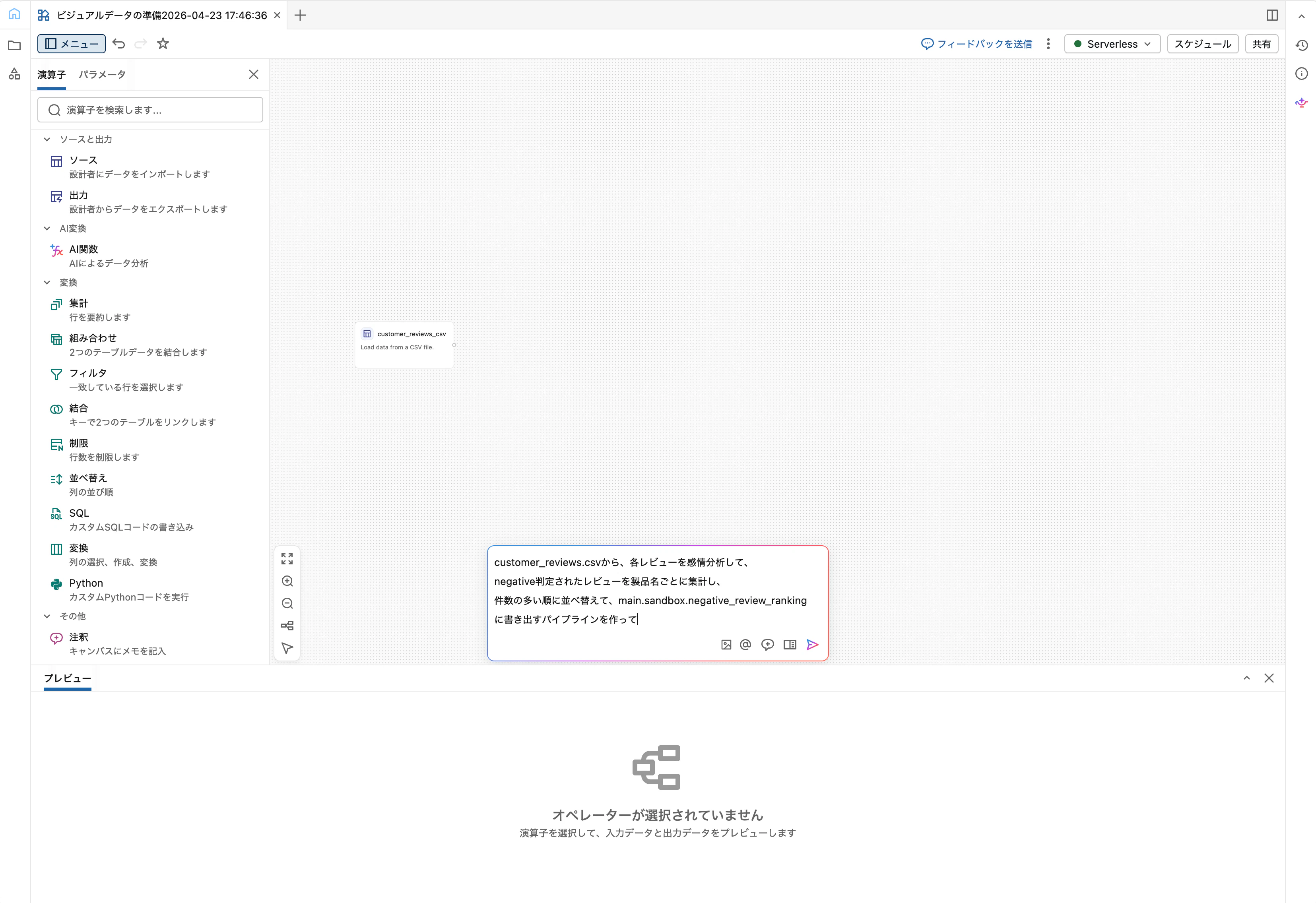
おまけ: Genie Codeで一気に生成してみる
ここまでの手作業をGenie Codeに丸ごと任せることもできます。キャンバスのGenie Codeプロンプトに以下を入力してみてください。
customer_reviews.csvから、各レビューを感情分析して、
negative判定されたレビューを製品名ごとに集計し、
件数の多い順に並べ替えて、main.sandbox.negative_review_ranking
に書き出すパイプラインを作って
Genie CodeがSource/AI機能/Filter/Aggregate/Sort/Outputの演算子を自動配置してくれます。細部は手動で調整できるため、「たたき台をAIに作らせて、人が仕上げる」 というワークフローが現実的です。
まとめ
本記事でカバーした要素は以下の通りです。
- LakeFlow Designerのコンセプト (キャンバス、オペレーター、接続、出力ペイン、Genie Code)
- 組み込みオペレーターの全体像 (Source/Output、AI機能、変換系、組織系)
- 実践チュートリアル: 顧客レビューの感情分析→ネガティブ集計→ランキングテーブル作成
LakeFlow Designerの特筆すべきポイントをまとめると:
- ビジネスアナリスト層の新しい入り口: コードを書かずにDatabricks上でデータ変換が完結する
- 本番運用への橋渡し: ビジュアルで作ったものがそのまま本番用コードとしてバックアップされる (Alteryx、Dataiku、Informatica IDMC等との大きな差別化)
- Genie Code統合: 自然言語でオペレーターを生成・変更できるAIネイティブな世代感
-
AI関数の一級市民化:
ai_classify、ai_extract、ai_gen等がオペレーターとして直接組み込める (LLMOps文脈でETL段階にAIを埋め込める) - Python/SQLエスケープハッチ: ノーコードツールでありながら、カスタムSQLとPySparkで逃げ道が用意されている
- Unity Catalog前提: ガバナンス・リネージ・権限管理が最初から組み込まれる
ぜひ試してみてください。