こちらの記事にも関係するお話です。
とてもざっくりした説明としては、横長のテーブルを縦長に変換するのがmelt(unpivot)、その逆がpivotです。
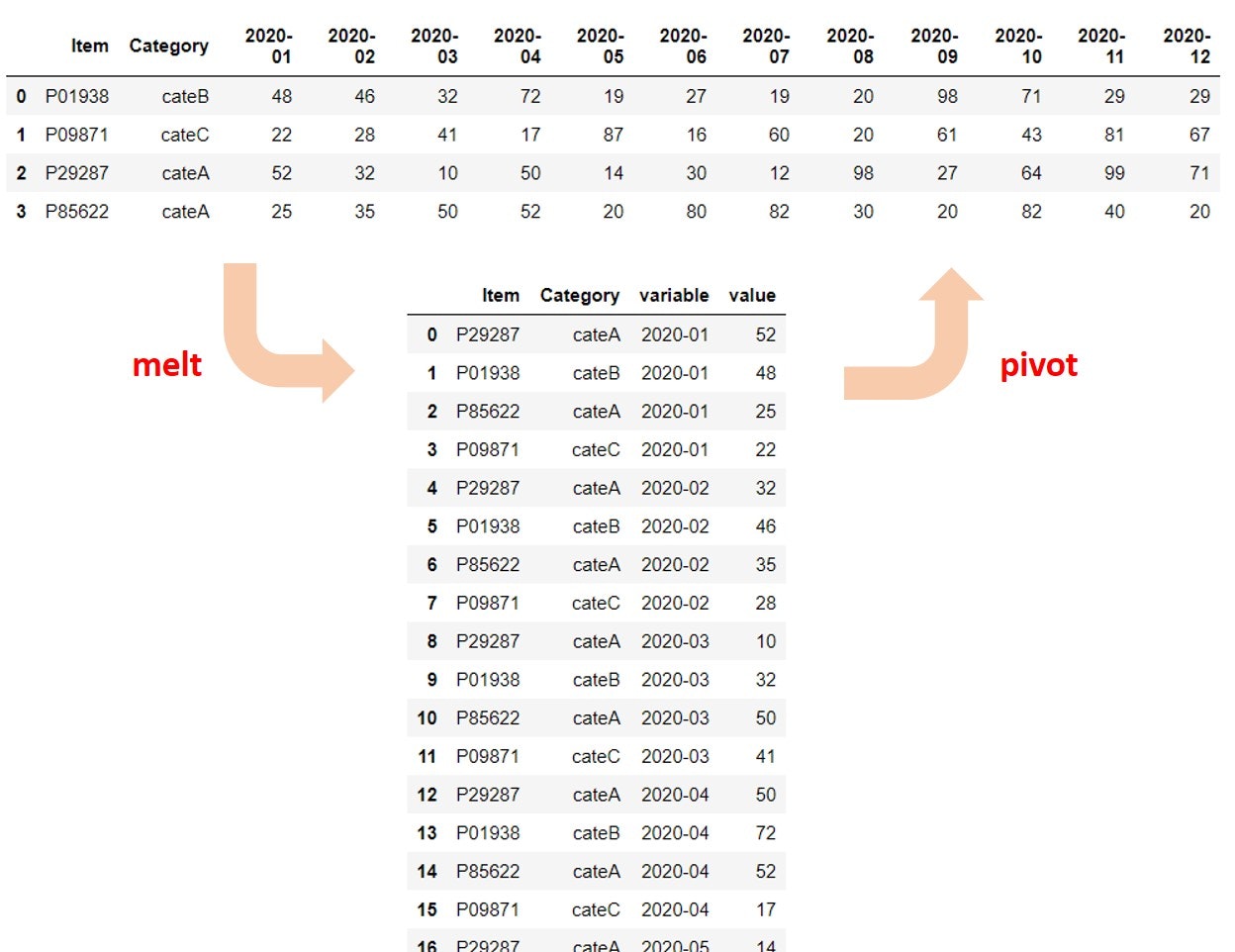
詳しくはこちらの記事をご覧ください。
で、少し昔はSparkではmeltがサポートされていなかったので、pandasに変換して処理していました。ところが、Spark 3.4.0でサポートされていました。
これはこれで嬉しいのですが、pandasとの比較が気になるところです。ということで、pandas、Spark(PySpark/Pandas on Spark)でのmelt/pivotをウォークスルーしました。実際にコーディングする際には、これらを使い分けするケースが出てくると思いますので、ご参考になれば。
概要
横型のテーブルを縦型に変換。
| IDとして用いる列 | melt(unpivot)する列 | variable変数の列 | value変数の列 | |
|---|---|---|---|---|
| pandas (pandas.melt) | id_vars | value_vars | var_name | value_name |
| Pandas on Spark(pyspark.pandas.DataFrame.melt) | d_vars | value_vars | var_name | value_name |
| PySpark(pyspark.sql.DataFrame.melt) | ids | value | variableColumnName | valueColumnName |
pivot
縦型のテーブルを横型に変換。
| ピボットデーブルの列を構成する列 | インデックスの列 | 新規の列に分配される値を持つ列 | |
|---|---|---|---|
| pandas(pandas.pivot) | columns | index | values |
| Pandas on Spark(pyspark.pandas.DataFrame.pivot) | columns | index | values |
| PySpark(pyspark.sql.GroupedData.pivot) | pivot_col | - | values |
こちらで公開されている日本のCOVID-19の感染者数データを使います。
pandas
melt
import pandas as pd
pdf = pd.read_csv("https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv")
display(pdf)
日付と都道府県名の列から構成されている横長のテーブルです。都道府県名の列の値は日付における感染者数となっています。

- id_vars:IDとして利用する変数(カラム)
- value_vars:melt する変数(カラム)、無指定の場合はid_vars以外の変数全部
- var_name:variable変数の変数(カラム)名、無指定の場合はvariableが変数(カラム)名になる
- value_name:value変数の変数(カラム)名、無指定の場合はvalueが変数(カラム)名になる
ID列はDate、variableはPrefecture、valueはCasesとしてmeltします。
# 縦長に変換
pdf = pdf.melt(id_vars=["Date"], var_name="Prefecture", value_name="Cases")
display(pdf)
Date、Prefercture、Casesから構成される縦長のテーブルに変換されました。

pivot
元に戻します。列名などに手を加えています。
pdf = pdf.pivot(index=["Date"], columns="Prefecture", values="Cases")
pdf = pdf.reset_index()
pdf.columns.name = None
display(pdf)
Dateは文字列になっていますが横長の列に戻りました。

Pandas on Spark
基本的にpandasと同じです。そもそもそれを目指して開発されたものですので。ただ、Pandas on Sparkのread_csvでURLの読み込みはできませんでした。
import pandas as pd
import pyspark.pandas as ps
pdf = pd.read_csv("https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv")
psdf = ps.from_pandas(pdf)
display(psdf)

melt
pyspark.pandas.DataFrame.melt — PySpark 3.5.4 documentation
melted_psdf = psdf.melt(id_vars=["Date"], var_name="Prefecture", value_name="Cases")
display(melted_psdf)

pivot
pyspark.pandas.DataFrame.pivot — PySpark 3.5.4 documentation
pivoted_psdf = melted_psdf.pivot(index="Date", columns="Prefecture", values="Cases")
pivoted_psdf = pivoted_psdf.reset_index()
pivoted_psdf.columns.name = None
display(pivoted_psdf)

PySpark
import pandas as pd
pdf = pd.read_csv("https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv")
sdf = spark.createDataFrame(pdf)
display(sdf)
melt
pyspark.sql.DataFrame.melt — PySpark 3.5.4 documentation
New in version 3.4.0.
-
ids str, Column, tuple, list
識別子として使用する列。単一の列または列名、または複数の列の場合はリストまたはタプルで指定できます。 -
values str, Column, tuple, list, optional
アンピボットする列。単一の列または列名、または複数の列の場合はリストまたはタプルで指定できます。指定されている場合、空であってはなりません。指定されていない場合、識別子として設定されていないすべての列を使用します。 -
variableColumnName str
変数列の名前。 -
valueColumnName str
値列の名前。
valuesをNoneにすることでid列以外の全ての列がmeltされます。
melted_sdf = sdf.melt(ids=["Date"], values=None, variableColumnName="Prefecture", valueColumnName="Cases")
display(melted_sdf)

pivot
pyspark.sql.GroupedData.pivot — PySpark 3.5.4 documentation
-
pivot_col str
ピボットする列の名前。 -
values list, optional
出力DataFrameで列に変換される値のリスト。
pandasとの違いですが、こちらのpivotはpyspark.sql.GroupedData.pivotとあるように、groupByしてGroupedDataに適用する必要があるという点です。グルーピング不要のデータフレームでもGroupByが必要となります。こちらでもしょうさいg説明されています。
あと、以下では文字列のDateをDate型に変換してます。
from pyspark.sql.functions import *
from pyspark.sql.types import StringType, BooleanType, DateType
pivoted_sdf = (
melted_sdf.groupBy("Date")
.pivot("Prefecture")
.sum("Cases")
.withColumn("Date", to_date(col("Date"),"yyyy/M/d"))
.orderBy("Date")
)
display(pivoted_sdf)

横長に戻りました