ハンズオンの目的
生成AI(Databricksアシスタント)を活用したバイブデータサイエンス(Vibe Data Science)を体験いただく。
バイブデータサイエンスとは?
「ビジネスゴール」や「欲しい洞察」を伝えるだけで分析を実行するデータサイエンス。データサイエンティストが統計手法や機械学習アルゴリズムを選択するのではなく、「この課題を解決したい」「こんなインサイトが欲しい」という要望を伝え、AIが適切な分析を実行する手法。
| 側面 | 従来のコーディング | Vibe Coding | 従来のデータサイエンス | Vibe Data Science |
|---|---|---|---|---|
| 入力 | 詳細な仕様書・設計書 | 自然言語での意図・イメージ | 分析計画・統計手法の選択 | ビジネス課題・欲しい答え |
| プロセス | 手動でコード記述 | AI対話でコード生成 | 手動で分析実行 | AI対話で分析自動実行 |
| 必要スキル | プログラミング言語習得 | コミュニケーション能力 | 統計・ML知識 | ビジネス理解力 |
| アウトプット | 実装コード | 動作するアプリケーション | 分析結果・モデル | ビジネスインサイト |
| 反復速度 | 時間/日単位 | 分/時間単位 | 日/週単位 | 時間/日単位 |
ハンズオン
Databricksアシスタントを用いたバイブデータサイエンスの実践。Pythonコードを直接記述するのではなく、AIアシスタントとの対話を通じてデータサイエンスを実施します。
ハンズオンの準備
こちらの手順に従って、無料版Databricks(Databricks Free Edition)にサインアップしてください。
-
ワークスペースにログイン

-
「新規」→「ノートブック」を選択

-
言語がPythonになっていることを確認

-
画面右上の紫十字アイコンをクリックしてアシスタントを呼び出します。
-
これで準備が整いました。

アシスタントのインタフェースに慣れましょう
まず、マニュアルをご一読ください。

アシスタントには2つのモードがあります。
- Chatモード: 日本語での質疑応答に対応してくれます。コードを提示してくれることもありますが、ノートブックを編集はしません。
- Editモード: 日本語での問い合わせや指示に応じて、ノートブックを直接編集します。
単に質問に答えて欲しい場合にはChatモード、この後実施するバイブデータサイエンスでのデータ分析ではEditモードを使うことをお勧めします。
データの読み込み
アシスタントがEditモードになっていることを確認の上、以下のプロンプトを入力してみましょう。
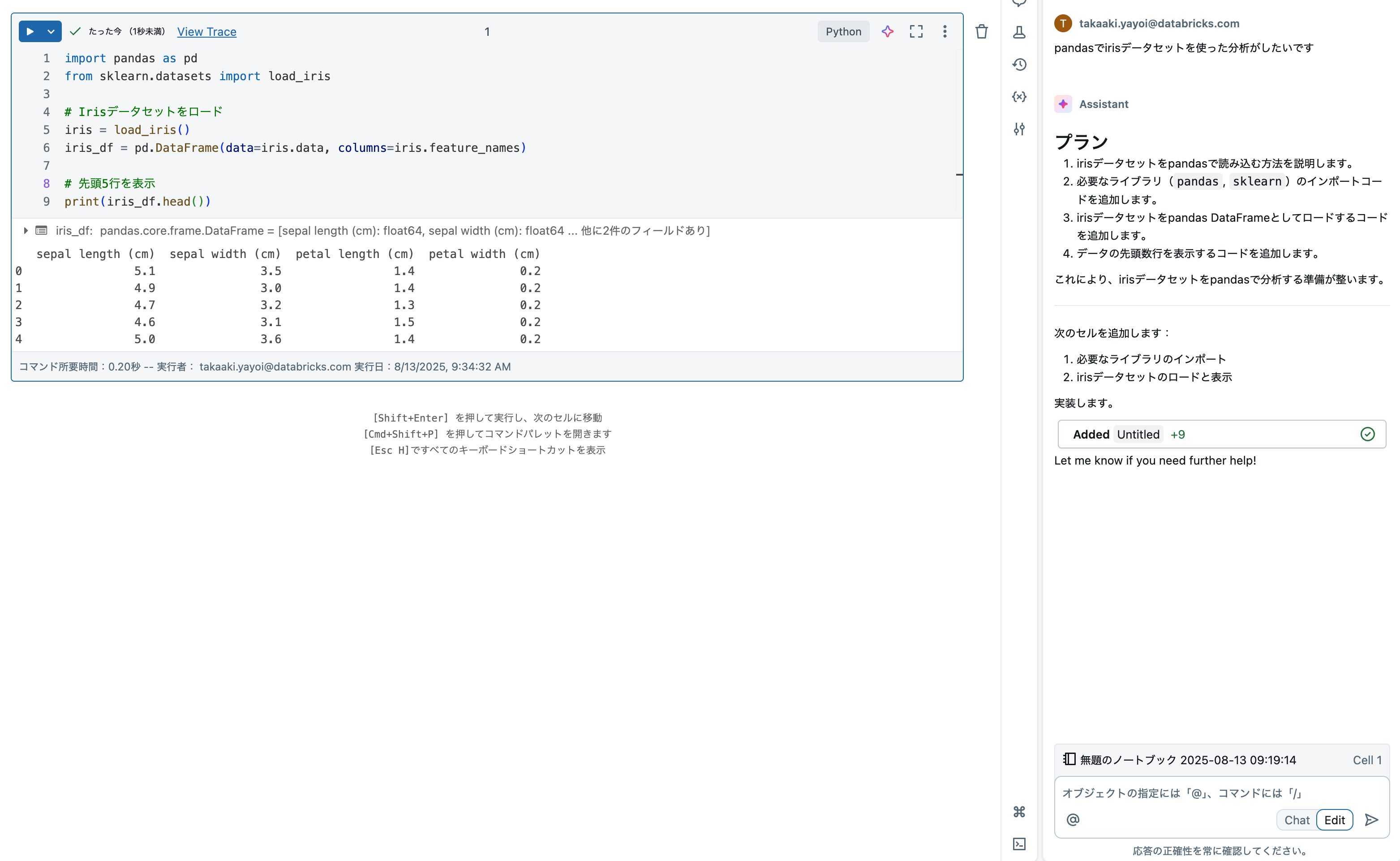
pandasでirisデータセットを使った分析がしたいです
すると以下のようなコードが生成されるはずです。生成AIなので常に同じ回答になるとは限らないことに注意してください。
import pandas as pd
from sklearn.datasets import load_iris
# Irisデータセットをロード
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 先頭5行を表示
print(iris_df.head())
アシスタントの提案を全て受け入れるには右下のAccept Allをクリックします。

コードを確定したら、ノートブックセル左上の▶️ボタンをクリックして、Pythonコードを実行します。

無事データを読み込むことができました。
探索的データ分析
注意
- AIも完璧ではないので、エラーが発生することがあります。その場合には、エラーメッセージの下に表示される診断エラーをクリックしてみましょう。

- グラフが文字化けした際には「plotlyを使ってください」と指示してみましょう。
データを入手した後は、通常データの傾向を把握するために探索的データ分析(Exploratory Data Analysis:EDA)を行います。以下のようなプロンプトを入力しましょう。
このデータの分析の切り口をいくつか挙げて実際に可視化してください
指示に従ってコードを編集してくれるはずです。以下は一例です。
# Plotlyのインストール
%pip install plotly
import pandas as pd
from sklearn.datasets import load_iris
import plotly.express as px
import plotly.graph_objects as go
# Irisデータセットをロード
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# target(品種)列を追加
iris_df['target'] = iris.target
iris_df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
# 先頭5行を表示
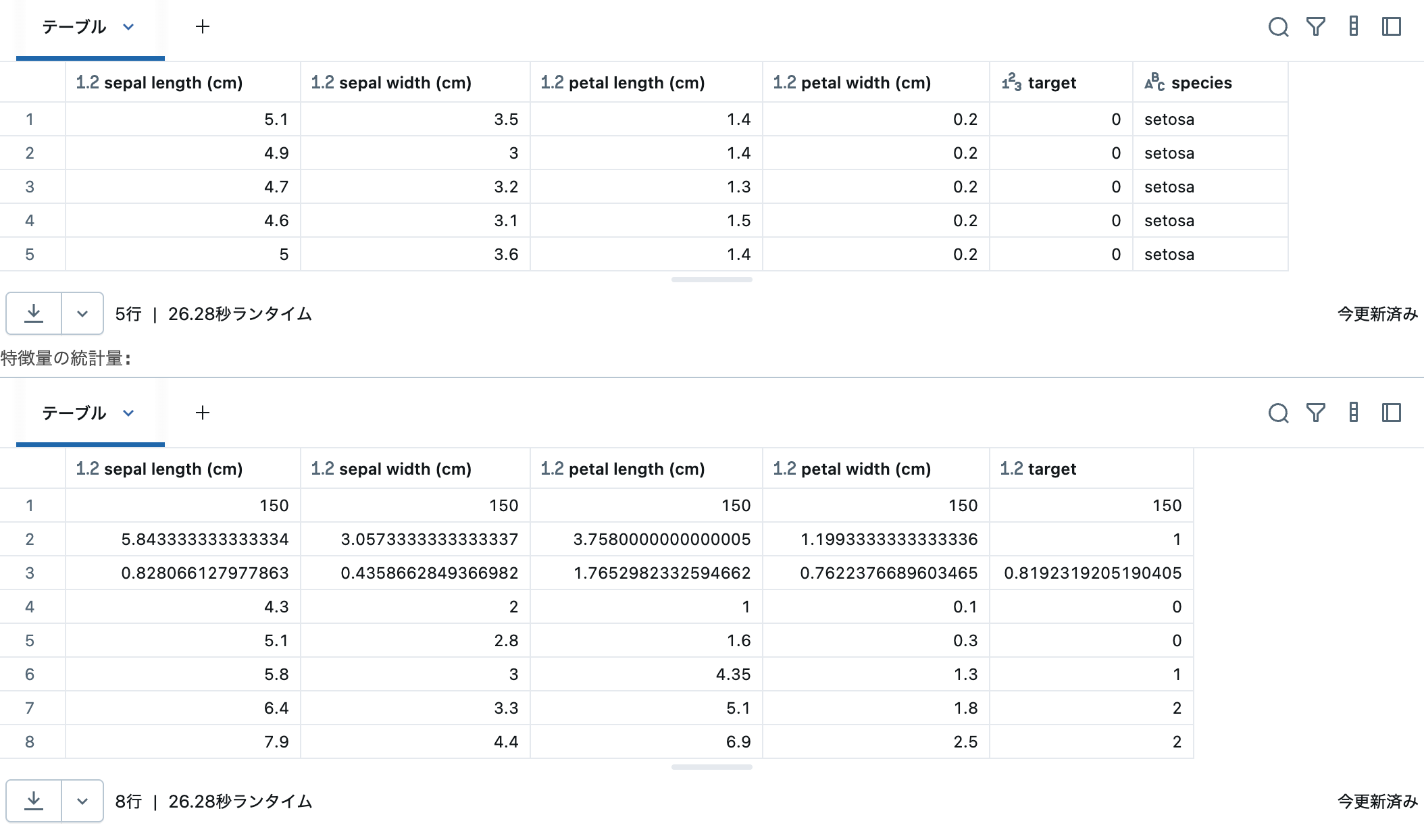
display(iris_df.head())
# 1. 各特徴量の統計量
print('特徴量の統計量:')
display(iris_df.describe())
# 2. 品種ごとの特徴量分布(箱ひげ図)
fig_box = px.box(
iris_df,
x='species',
y='sepal length (cm)',
title='品種ごとのがく片長の分布',
points='all',
color='species'
)
displayHTML(fig_box.to_html())
# 3. 特徴量同士の関係(散布図行列)
fig_scatter = px.scatter_matrix(
iris_df,
dimensions=iris.feature_names,
color='species',
title='特徴量同士の関係(散布図行列)'
)
displayHTML(fig_scatter.to_html())
# 4. 相関係数のヒートマップ
corr = iris_df[iris.feature_names].corr()
fig_heatmap = go.Figure(
data=go.Heatmap(
z=corr.values,
x=corr.columns,
y=corr.index,
colorscale='Blues',
colorbar=dict(title='相関係数')
)
)
fig_heatmap.update_layout(title='特徴量間の相関係数')
displayHTML(fig_heatmap.to_html())
データの統計情報などが表示されます。
ボックスプロットが表示されます。

散布図やヒートマップによって特徴量間の関係を把握することができます。

洞察の抽出
通常のデータサイエンスであれば、データサイエンティストの目で可視化の結果から洞察を得ることになります。しかし、今では生成AIに洞察を導き出してもらうことができます。
以下のプロンプトを入力しましょう。
ここまでの可視化の結果から導き出される洞察がありますか

まとめ
このハンズオンでは1行のPythonを書くことなしに、日本語だけでデータサイエンスのプロセスの一部を実行できることを体験いただきました。実際には、モデルのトレーニングやMLflowによるモデル管理なども可能ですので是非トライしてみてください。