こちらで説明されているプロセスをウォークスルーします。
リポジトリはこちら。
このバンドルは、Free Editionではメトリクスビューで参照するシステムテーブルsystem.access.workspaces_latestにアクセスできないため動作しません。
Databricksアセットバンドルとは
Databricksアセットバンドル(DAB)は、Databricksのリソース(ジョブ、パイプライン、ダッシュボードなど)をコードで管理し、複数の環境に一貫してデプロイするためのツールです。
従来の課題
- UIで手動作成したジョブの設定を別環境に再現するのが大変
- 開発→ステージング→本番への移行が手作業でミスが発生しやすい
- チームメンバー間で設定の共有が困難
DABで解決できること
┌─────────────────────────────────────────────────────────────┐
│ コードで定義 │
│ databricks.yml + resources/*.yml │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌─────────┐ ┌──────────┐ ┌─────────┐
│ Dev │ │ Staging │ │ Prod │
│ 環境 │ │ 環境 │ │ 環境 │
└─────────┘ └──────────┘ └─────────┘
同じ定義から複数環境に一貫したデプロイが可能
基本的なプロジェクト構成
my_project/
├── databricks.yml # メイン設定ファイル
├── resources/
│ ├── my_job.yml # ジョブ定義
│ └── my_pipeline.yml # パイプライン定義
└── src/
└── notebook.py # ソースコード
databricks.ymlの例
bundle:
name: my_project
targets:
dev:
mode: development
workspace:
host: https://adb-xxxxx.azuredatabricks.net
prod:
mode: production
workspace:
host: https://adb-yyyyy.azuredatabricks.net
resources:
jobs:
my_etl_job:
name: "Daily ETL Job"
schedule:
quartz_cron_expression: "0 0 9 * * ?"
tasks:
- task_key: extract
notebook_task:
notebook_path: ./src/notebook.py
基本コマンド
| コマンド | 説明 |
|---|---|
databricks bundle init |
プロジェクトの初期化 |
databricks bundle validate --target dev |
設定の検証 |
databricks bundle deploy --target dev |
デプロイ |
databricks bundle run --target dev my_job |
ジョブの実行 |
databricks bundle destroy --target dev |
リソースの削除 |
重要な概念
Target(ターゲット)
デプロイ先の環境を定義します。各targetは独立した状態管理を持ちます。
targets:
dev: # 開発環境
staging: # ステージング環境
prod: # 本番環境
ポイント: ワークスペースごとにtargetを分けることを推奨します。
Profile(プロファイル)
認証情報を管理します。~/.databrickscfg に設定を記述します。
[my-workspace]
host = https://adb-xxxxx.azuredatabricks.net
token = dapi_xxxxx
使用例:
databricks bundle deploy --target dev --profile my-workspace
ポイント: Profileは「誰として接続するか」、Targetは「どこにデプロイするか」を管理します。
Mode(モード)
| モード | 用途 | 特徴 |
|---|---|---|
development |
個人開発 | リソース名にプレフィックス付与、スケジュール一時停止 |
production |
本番運用 | 権限チェックが厳格、run_as必須 |
ProfileとTargetの関係
┌─────────────────┐ ┌─────────────────┐
│ Profile │ │ Target │
│ (認証) │ │ (環境) │
├─────────────────┤ ├─────────────────┤
│ 誰として接続 │ │ どこにデプロイ │
│ するか │ │ するか │
├─────────────────┤ ├─────────────────┤
│ ~/.databrickscfg│ │ databricks.yml │
│ (Gitに含めない) │ │ (Gitで管理) │
└─────────────────┘ └─────────────────┘
推奨構成
# databricks.yml
targets:
dev:
workspace:
host: https://adb-dev.azuredatabricks.net
prod:
workspace:
host: https://adb-prod.azuredatabricks.net
# targetでワークスペースが決まる
databricks bundle deploy --target dev
databricks bundle deploy --target prod
避けるべき構成
# 同じtargetで異なるprofile(ワークスペース)を使うと状態が壊れる
databricks bundle deploy --target dev --profile workspace-a
databricks bundle deploy --target dev --profile workspace-b # ❌ 問題発生
始め方
1. Databricks CLIのインストール
# macOS
brew install databricks
# Windows / Linux
pip install databricks-cli
2. 認証設定
databricks configure --profile my-workspace
3. テンプレートからプロジェクト作成
databricks bundle init
4. デプロイ
cd my_project
databricks bundle deploy --target dev
公式ドキュメント
DABを使うことで以下のメリットが得られます。
- Infrastructure as Code: リソース定義をGitで管理
- 環境の一貫性: 開発・ステージング・本番で同じ定義を使用
- CI/CD統合: パイプラインからの自動デプロイが容易
- チーム協業: 設定のレビューと共有が可能
メトリックビューとは
メトリックビューを一言で
「指標(KPI)の計算方法を一度定義すれば、どこでも同じ計算で使えるセマンティックレイヤー」
「売上」や「顧客数」などの計算ロジックをYAMLで定義してUnity Catalogに登録しておけば、ダッシュボード、Genie、ノートブックなど、どのツールからクエリしても同じ結果が返ってきます。
なぜ必要なのか:よくある問題
営業チーム: 「今月の売上は1億円です」
経理チーム: 「今月の売上は9500万円です」
経営層: 「どっちが正しいの?」
原因: チームごとに「売上」の計算方法が微妙に違う(返品を含むか、税込か、など)
メトリックビューで解決
1. 指標を一度だけ定義する
CREATE VIEW sales_metrics WITH METRICS LANGUAGE YAML AS $$
version: 1.1
source: sales_data
measures:
- name: 売上
expr: SUM(amount) - SUM(refund) -- 返品を除いた正式な定義
comment: "返品控除後の純売上"
$$;
2. 誰がどこから見ても同じ結果
-- 営業チームがダッシュボードで見る
SELECT month, MEASURE(売上) FROM sales_metrics GROUP BY month;
-- 経理チームがノートブックで見る
SELECT month, MEASURE(売上) FROM sales_metrics GROUP BY month;
-- 経営層がGenieで「今月の売上は?」と聞く
→ 同じ計算ロジックで回答
指標とビューの対応関係
1つのメトリックビュー = 複数の指標(メジャー) + 複数の切り口(ディメンション)のセット
┌─────────────────────────────────────────────────────────────┐
│ sales_metrics(メトリックビュー) │
├─────────────────────────────────────────────────────────────┤
│ │
│ ディメンション(切り口) │
│ ├── month(月) │
│ ├── region(地域) │
│ └── product_category(商品カテゴリ) │
│ │
│ メジャー(指標) │
│ ├── 売上 = SUM(amount) - SUM(refund) │
│ ├── 注文件数 = COUNT(*) │
│ ├── 顧客数 = COUNT(DISTINCT customer_id) │
│ └── 平均単価 = 売上 / 注文件数 │
│ │
└─────────────────────────────────────────────────────────────┘
この1つのメトリックビューから、さまざまな組み合わせでクエリできます:
-- 月別の売上
SELECT month, MEASURE(売上) FROM sales_metrics GROUP BY month;
-- 地域別の顧客数
SELECT region, MEASURE(顧客数) FROM sales_metrics GROUP BY region;
-- 月×地域の売上と注文件数
SELECT month, region, MEASURE(売上), MEASURE(注文件数)
FROM sales_metrics
GROUP BY month, region;
ポイント: メトリックビューは「指標の計算方法」を定義する場所であり、「どの軸で集計するか」は使う人が決める
標準ビューとの違い
標準ビュー: 1つのビュー = 1つの集計結果(固定)
-- 月別売上ビュー
CREATE VIEW monthly_sales AS
SELECT month, SUM(amount) - SUM(refund) AS 売上
FROM sales_data GROUP BY month;
-- 地域別売上ビュー(別途作成が必要)
CREATE VIEW regional_sales AS
SELECT region, SUM(amount) - SUM(refund) AS 売上
FROM sales_data GROUP BY region;
-- 切り口が増えるたびにビューが増える...
メトリックビュー: 1つのビュー = 指標の定義だけ(集計の軸は実行時に決める)
-- これ1つで、どの切り口でも集計できる
CREATE VIEW sales_metrics WITH METRICS ...
measures:
- name: 売上
expr: SUM(amount) - SUM(refund)
比較表
| 項目 | 標準ビュー | メトリックビュー |
|---|---|---|
| 集計の定義 | 作成時に固定 | 実行時に柔軟に選択 |
| 切り口の変更 | 新しいビューが必要 | 同じ定義で GROUP BY を変えるだけ |
| 複雑な指標(比率など) | 再集計で誤った結果になる可能性 | 正しく計算される |
| ガバナンス | 個別管理 | Unity Catalogで一元管理 |
基本概念
構成要素の整理
| 要素 | 説明 | 例 |
|---|---|---|
| Source | データソース | テーブル、ビュー、SQLクエリ |
| Dimensions | 切り口(集計の軸) | 月、地域、顧客タイプ |
| Measures | 指標(集計値) | 売上、顧客数、平均単価 |
| Joins | 結合定義(オプション) | ディメンションテーブルとの結合 |
| Filter | グローバルフィルター(オプション) | 全クエリに適用される条件 |
メトリックビューの作成
方法1: SQLで作成
CREATE OR REPLACE VIEW my_catalog.my_schema.sales_metrics
WITH METRICS LANGUAGE YAML AS $$
version: 1.1
source: my_catalog.my_schema.orders
comment: "売上分析用メトリックビュー"
dimensions:
- name: order_date
expr: o_orderdate
comment: "注文日"
- name: order_month
expr: DATE_TRUNC('MONTH', o_orderdate)
comment: "注文月"
- name: order_status
expr: >
CASE
WHEN o_orderstatus = 'O' THEN 'Open'
WHEN o_orderstatus = 'P' THEN 'Processing'
WHEN o_orderstatus = 'F' THEN 'Fulfilled'
END
comment: "注文ステータス"
measures:
- name: total_revenue
expr: SUM(o_totalprice)
comment: "売上合計"
- name: order_count
expr: COUNT(*)
comment: "注文件数"
- name: avg_order_value
expr: SUM(o_totalprice) / COUNT(*)
comment: "平均注文額"
- name: unique_customers
expr: COUNT(DISTINCT o_custkey)
comment: "ユニーク顧客数"
$$;
方法2: Catalog Explorer UIで作成
- カタログ をサイドバーでクリック
- 対象のスキーマに移動
- 作成 → メトリックビュー を選択
- YAMLエディタでメトリックビューを定義
- Save をクリック
方法3: Databricks Assistantを活用
- Assistantアイコンをクリック
- 「売上分析用のメトリックビューを作成して」などと入力
- 生成されたSQLを確認・編集
- 実行して作成
メトリックビューのクエリ
MEASURE関数の使用
メトリックビューのメジャーをクエリする際は、必ず MEASURE() 関数を使用します。
-- 月別の売上合計と注文件数
SELECT
order_month,
MEASURE(total_revenue) AS revenue,
MEASURE(order_count) AS orders
FROM my_catalog.my_schema.sales_metrics
GROUP BY order_month
ORDER BY order_month;
-- ステータス別の集計
SELECT
order_status,
MEASURE(total_revenue) AS revenue,
MEASURE(unique_customers) AS customers
FROM my_catalog.my_schema.sales_metrics
GROUP BY order_status;
-- フィルター付きクエリ
SELECT
order_month,
MEASURE(total_revenue) AS revenue
FROM my_catalog.my_schema.sales_metrics
WHERE order_status = 'Fulfilled'
GROUP BY order_month;
クエリの制約
-
SELECT *は使用できない(メジャーとディメンションを明示的に指定) - クエリ時のJOINはサポートされない(YAML定義内でJOINを定義するか、CTEを使用)
YAML定義リファレンス
基本構造
version: 1.1 # YAMLスペックのバージョン
source: catalog.schema.table # データソース
comment: "説明" # メトリックビューの説明
filter: "条件式" # グローバルフィルター(オプション)
dimensions: # ディメンション定義
- name: dimension_name
expr: SQL式
comment: "説明"
measures: # メジャー定義
- name: measure_name
expr: 集計関数(カラム)
comment: "説明"
joins: # 結合定義(オプション)
- name: join_name
source: catalog.schema.dim_table
on: 結合条件
ディメンションの例
dimensions:
# シンプルなカラム参照
- name: order_date
expr: o_orderdate
# SQL式
- name: order_year
expr: YEAR(o_orderdate)
# CASE式
- name: order_priority_label
expr: >
CASE
WHEN o_orderpriority = '1-URGENT' THEN '緊急'
WHEN o_orderpriority = '2-HIGH' THEN '高'
ELSE '通常'
END
# 他のディメンションを参照
- name: order_quarter
expr: DATE_TRUNC('QUARTER', order_date)
メジャーの例
measures:
# 基本的な集計
- name: total_revenue
expr: SUM(o_totalprice)
# 比率計算
- name: revenue_per_customer
expr: SUM(o_totalprice) / COUNT(DISTINCT o_custkey)
# 条件付き集計(FILTER句)
- name: fulfilled_revenue
expr: SUM(o_totalprice) FILTER (WHERE o_orderstatus = 'F')
# 他のメジャーを参照
- name: avg_revenue_per_order
expr: MEASURE(total_revenue) / MEASURE(order_count)
JOINの例(スタースキーマ)
source: catalog.schema.fact_orders
joins:
- name: customer
source: catalog.schema.dim_customer
on: customer.c_custkey = source.o_custkey
- name: region
source: catalog.schema.dim_region
on: region.r_regionkey = customer.c_regionkey
dimensions:
- name: customer_name
expr: customer.c_name
- name: region_name
expr: region.r_name
measures:
- name: total_revenue
expr: SUM(o_totalprice)
ウィンドウメジャー(高度な機能)
ローリング集計
measures:
# 過去7日間のユニーク顧客数
- name: rolling_7d_customers
expr: COUNT(DISTINCT o_custkey)
window:
- order: date
range: trailing 7 day
semiadditive: last
前日比較
measures:
- name: previous_day_sales
expr: SUM(o_totalprice)
window:
- order: date
range: trailing 1 day
semiadditive: last
- name: current_day_sales
expr: SUM(o_totalprice)
window:
- order: date
range: current
semiadditive: last
- name: day_over_day_growth
expr: >
(MEASURE(current_day_sales) - MEASURE(previous_day_sales))
/ MEASURE(previous_day_sales) * 100
累計(YTD)
measures:
- name: ytd_revenue
expr: SUM(o_totalprice)
window:
- order: date
range: cumulative
semiadditive: last
セマンティックメタデータ
バージョン1.1以降では、表示名、フォーマット、シノニム(同義語)を定義できます。これにより、AI/BIダッシュボードやGenieスペースでの利用が向上します。
dimensions:
- name: order_date
expr: o_orderdate
comment: "注文日"
display_name: "Order Date"
synonyms:
- "購入日"
- "発注日"
measures:
- name: total_revenue
expr: SUM(o_totalprice)
comment: "売上合計"
display_name: "Total Revenue"
format: "$#,##0.00"
synonyms:
- "売上"
- "Revenue"
ガバナンスと権限
権限モデル
メトリックビューはUnity Catalogのセキュアブルオブジェクトとして管理されます。
| 操作 | 必要な権限 |
|---|---|
| 作成 | スキーマに対する CREATE TABLE
|
| クエリ | メトリックビューに対する SELECT
|
| 編集 | オーナーまたはオーナーグループのメンバー |
共同編集の設定
複数人でメトリックビューを編集する場合は、オーナーシップをグループに移譲します。
-- グループにオーナーシップを移譲
ALTER VIEW my_catalog.my_schema.sales_metrics
SET OWNER TO `data-analytics-team`;
リネージと洞察
カタログエクスプローラで以下を確認できます:
- リネージ: 関連するテーブル、ノートブック、ダッシュボード
- 洞察: 過去30日間のクエリ履歴とアクセスユーザー
ユースケース
1. AI/BIダッシュボード
メトリックビューをダッシュボードのデータソースとして使用すると、一貫した指標定義で可視化できます。
2. Genieスペース
自然言語でメトリックビューに対してクエリできます。セマンティックメタデータを定義すると、より正確な回答が得られます。
3. アラート
メトリックの閾値を監視し、条件を満たした際に通知を受け取れます。
4. ノートブック分析
データサイエンティストが一貫した指標定義を使って分析できます。
Databricksアセットバンドルでのデプロイ
メトリックビューはDABのリソースとして直接サポートされていないため、SQLステートメントでデプロイします。
-- パラメータマーカーを使用した動的SQL
DECLARE OR REPLACE VARIABLE sql_stmt STRING;
SET VAR sql_stmt = "
CREATE OR REPLACE VIEW " || :catalog || "." || :schema || ".sales_metrics
WITH METRICS LANGUAGE YAML AS $$
version: 1.1
source: " || :catalog || "." || :schema || ".orders
dimensions:
- name: order_date
expr: o_orderdate
measures:
- name: total_revenue
expr: SUM(o_totalprice)
$$";
EXECUTE IMMEDIATE sql_stmt;
公式ドキュメント
メトリックビューを使うことで以下のメリットが得られます:
- Single Source of Truth: KPIを一度定義すれば、全ツールで一貫して利用
- 柔軟な分析: 同じ指標を任意のディメンションで集計可能
- ガバナンス: Unity Catalogで権限・リネージ・監査を一元管理
- AI対応: Genieスペースやセマンティックメタデータとの統合
- 保守性向上: 計算ロジックの変更が全ツールに自動反映
環境準備
最新版のDatabricks CLIをインストールします。私はインストール済みだったのでアップデートします。
brew upgrade databricks
リポジトリをクローンします。
git clone https://github.com/databricks-solutions/databricks-dab-examples/
cd databricks-dab-examples/knowledge-base/metric-views
必要に応じてデプロイするワークスペースにログインします。
databricks auth login --host https://your-workspace.cloud.databricks.com --profile tokyo
仮想環境を作成します。
python3 -m venv venv
source venv/bin/activate
databricks.ymlの設定
デプロイメントターゲットを指定します。ワークスペースのホスト、SQLウェアハウスのID、カタログ、スキーマを指定します。カタログやスキーマは作成済みのものを指定します。
今回は以下のようにdevターゲットを設定しました。
targets:
dev:
# The default target uses 'mode: development' to create a development copy.
# - Deployed resources get prefixed with '[dev my_user_name]'
# - Any job schedules and triggers are paused by default.
# See also https://docs.databricks.com/dev-tools/bundles/deployment-modes.html.
mode: development
default: true
workspace:
host: https://<Databricksワークスペースホスト>/
variables:
warehouse_id: <SQLウェアハウスID>
catalog: takaakiyayoi_catalog
schema: dbsql_metrics
ダッシュボード設定の更新
ターゲット環境向けにダッシュボードのクエリパラメータを更新するには、バンドルをデプロイする前に、baseフォルダでPythonスクリプトを実行してください。ターゲット名とCLIプロファイルは必須の引数です。
python3 src/replace_dashboard_vars.py --target dev --profile tokyo
Using target environment: dev
Using catalog: takaakiyayoi_catalog
Using schema: dbsql_metrics
Updated catalog parameter in dataset query_duration_pct to: takaakiyayoi_catalog
Updated schema parameter in dataset query_duration_pct to: dbsql_metrics
Updated catalog parameter in dataset param_warehouses to: takaakiyayoi_catalog
Updated schema parameter in dataset param_warehouses to: dbsql_metrics
Updated catalog parameter in dataset dbsql_usage to: takaakiyayoi_catalog
Updated schema parameter in dataset dbsql_usage to: dbsql_metrics
Successfully updated src/dbsql_metrics.lvdash.json with catalog 'takaakiyayoi_catalog' and schema 'dbsql_metrics'
デプロイメント
databricks bundle deploy --target dev --profile tokyo
ジョブが作成されます。
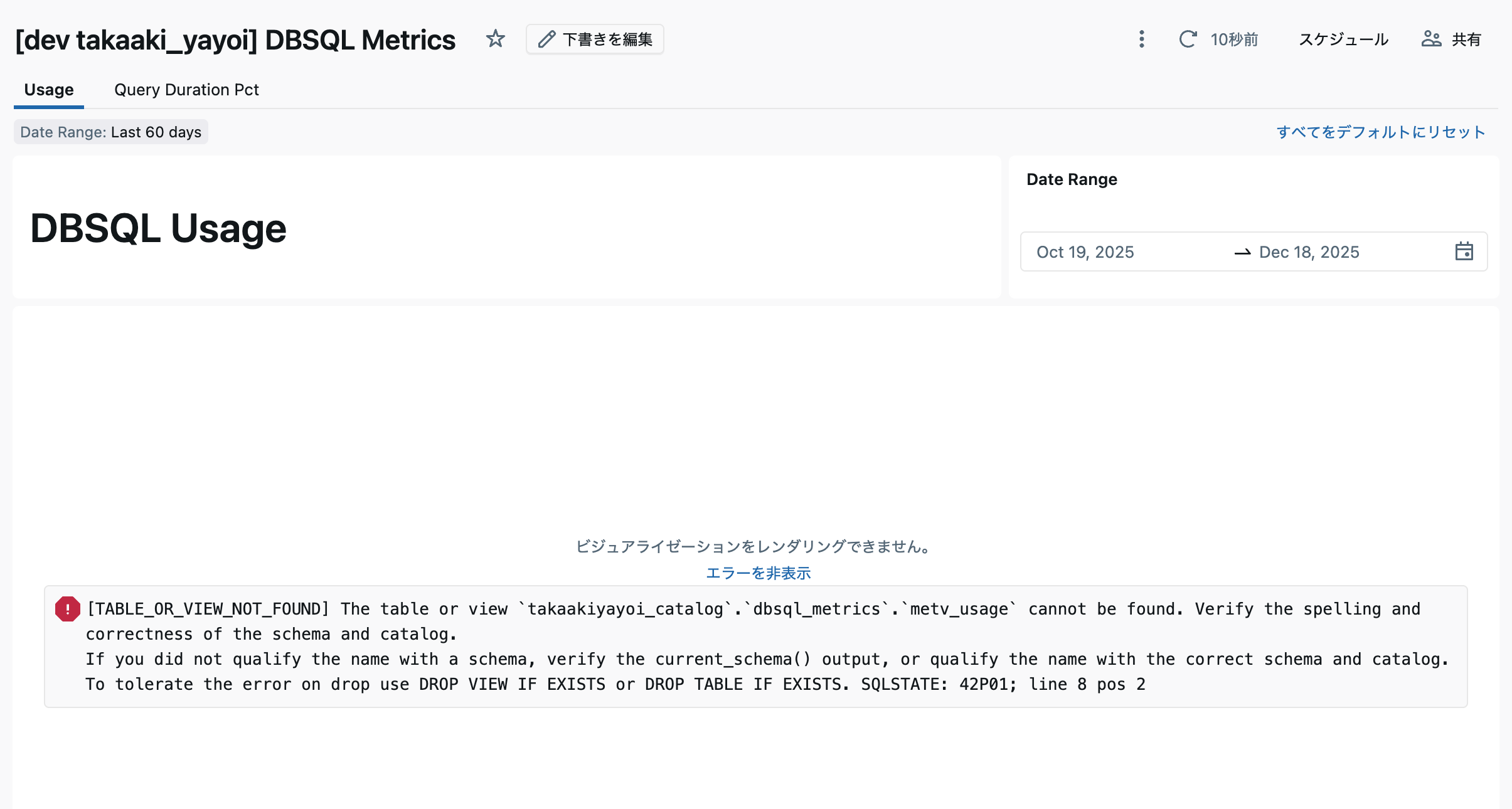
ダッシュボードが作成されますが、現時点ではテーブルが作成されていないのでエラーが表示されています。
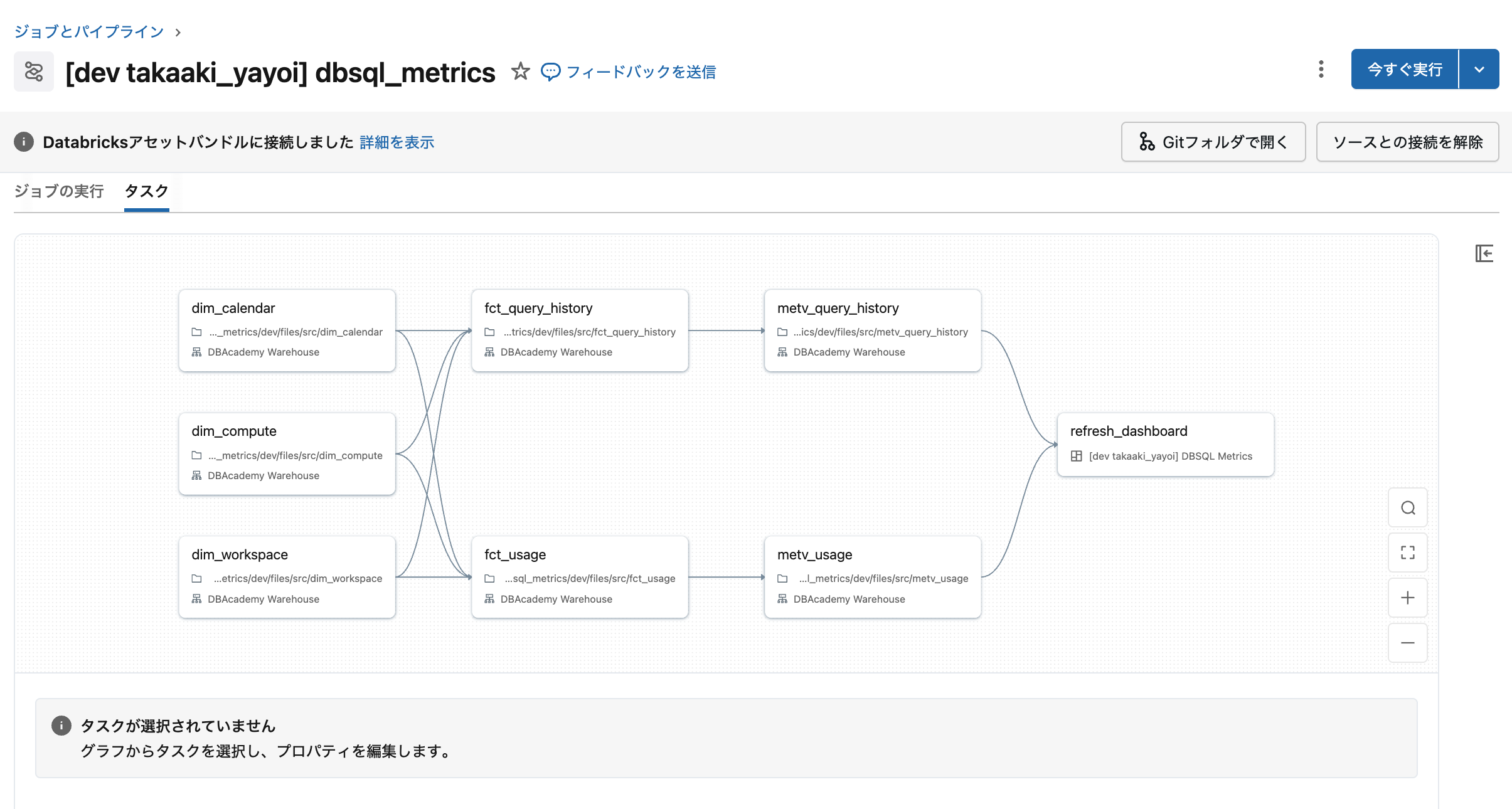
ジョブの実行
databricks bundle run --target dev --profile tokyo
確認されますのでENTERを押します。

少し待つとジョブが完了します。
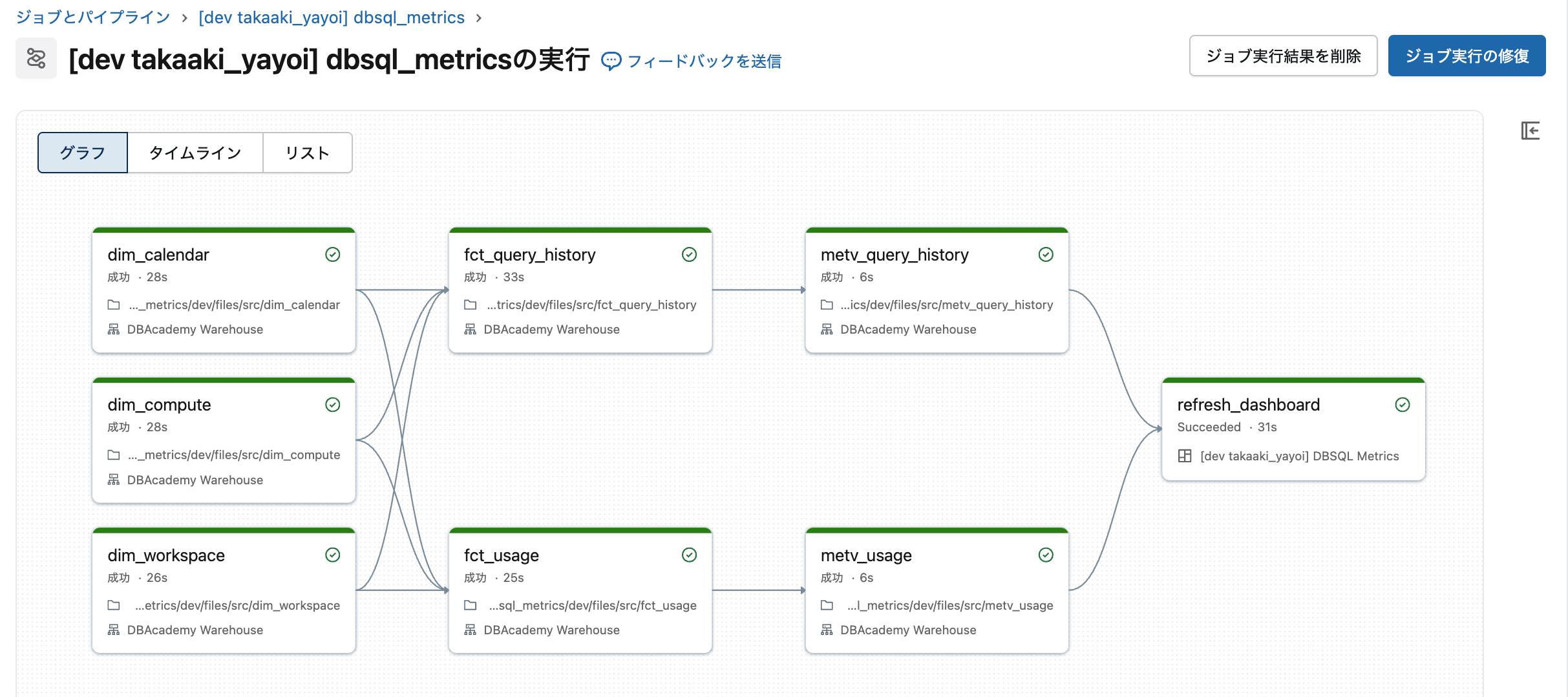
2025-12-18 11:48:17 "[dev takaaki_yayoi] dbsql_metrics" TERMINATED SUCCESS
Output:
=======
Task dim_workspace:
=======
Task dim_compute:
=======
Task dim_calendar:
=======
Task fct_usage:
=======
Task metv_usage:
=======
Task fct_query_history:
=======
Task metv_query_history:
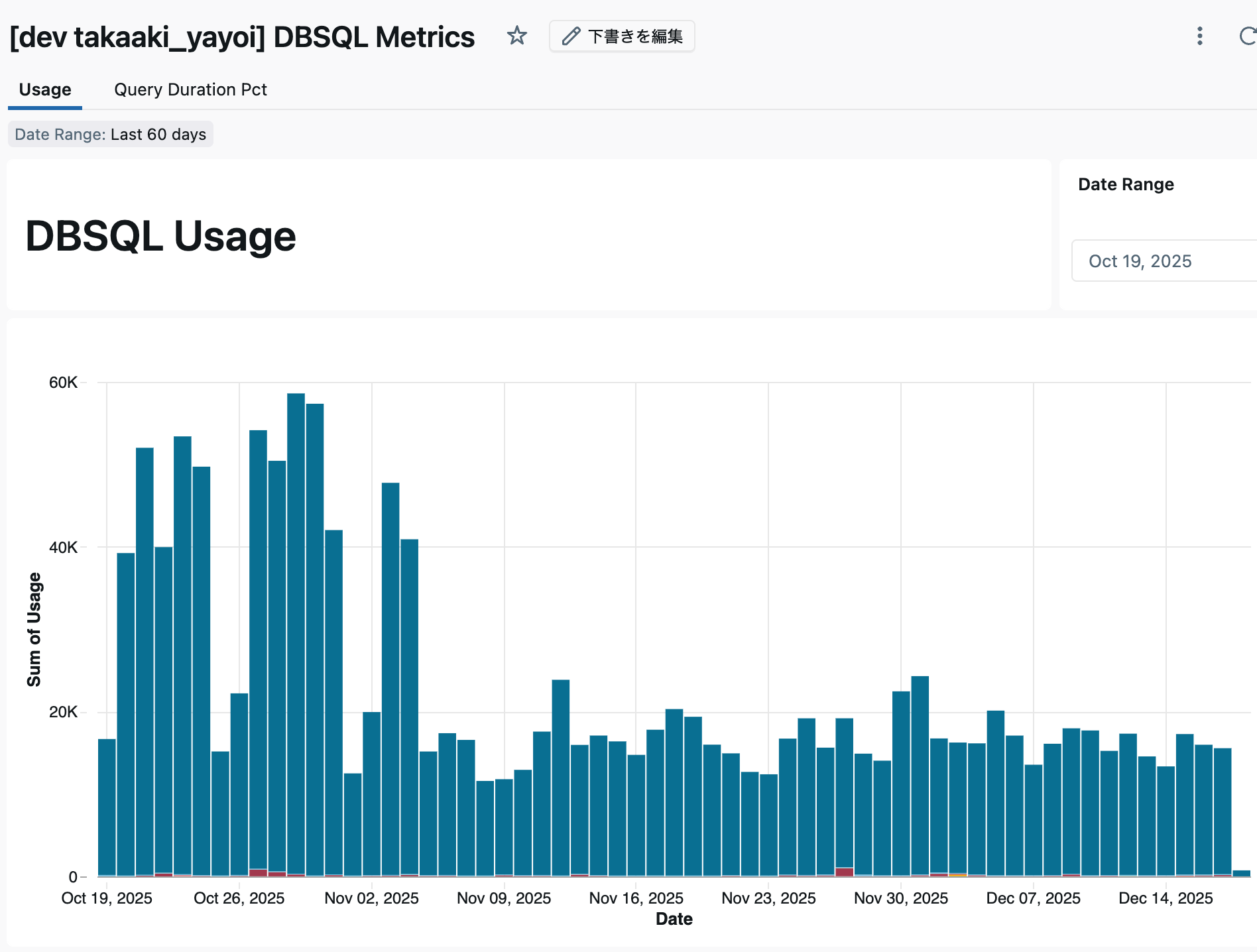
テーブルとメトリックビューが作成されました。
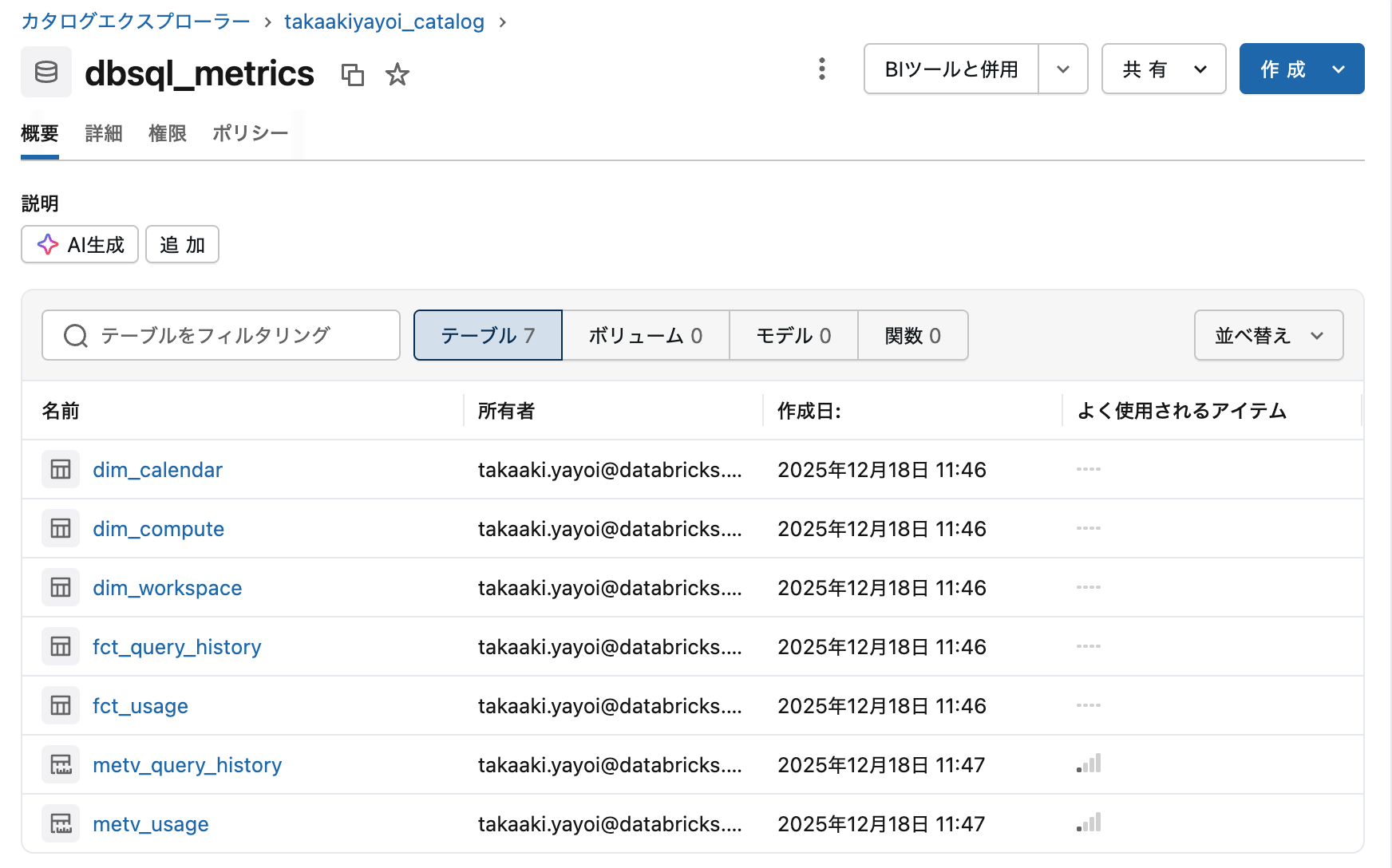
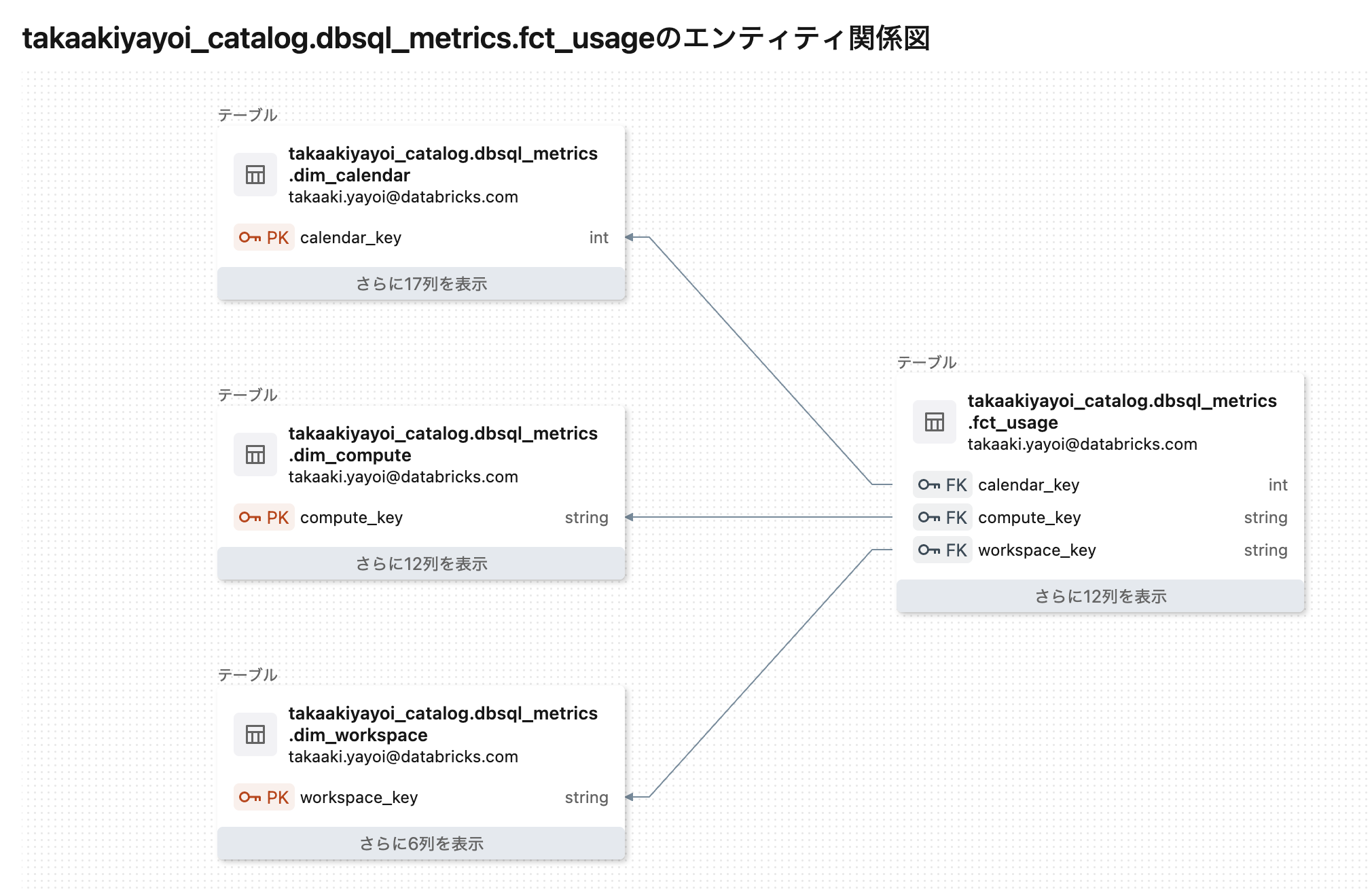
主キー、外部キー制約とリレーションシップも確認できます。
ダッシュボードにもアクセスできます。