こちらのマニュアルを補完し、サンプルコードを実行した記事です。
はじめに
Databricks Agent Frameworkには「会話型エージェント」と「非会話型エージェント」という2つのタイプがあります。この記事では、両者の違いと、非会話型エージェントが必要になるケースについて解説します。
「会話型」「非会話型」の本当の意味
まず最初に押さえておきたいのは、この名前がユーザー体験(対話的かどうか)を指しているわけではないということです。
ここでいう「会話型」とは、ChatAgentインターフェース(messages形式)に準拠しているかどうかという技術仕様の話です。
# 会話型 = ChatAgent準拠
# 入力がこの形式
{"messages": [{"role": "user", "content": "こんにちは"}]}
# 出力もこの形式
{"messages": [{"role": "assistant", "content": "こんにちは!"}]}
# 非会話型 = 任意のスキーマ
# 入力
{"document": "契約書...", "questions": ["期間は?"]}
# 出力
{"answers": [{"question": "期間は?", "answer": "1年"}]}
より正確に言い換えると:
| Databricksの呼び方 | 実態 |
|---|---|
| 会話型エージェント | ChatAgent準拠エージェント |
| 非会話型エージェント | カスタムスキーマエージェント |
会話型 vs 非会話型:比較表
| 項目 | 会話型エージェント | 非会話型エージェント |
|---|---|---|
| インターフェース |
ChatAgent に準拠 |
カスタム入出力スキーマ |
| 会話履歴 | 維持する | 維持しない |
| デプロイ方法 | agents.deploy() |
カスタム CPU Model Serving |
| 認証パススルー | 自動(Databricksが処理) | 手動(自分で設定) |
| サービスプリンシパル | 自動作成・自動削除(非表示) | 手動でプロビジョニング |
| MLflow Experimentへの権限 | 自動付与 | 手動で CAN_EDIT を付与 |
| 環境変数設定 | 不要 |
DATABRICKS_CLIENT_ID/SECRET または DATABRICKS_HOST/TOKEN を手動設定 |
| トレース記録 | 自動 |
@mlflow.trace で手動実装 |
| ユースケース | チャットボット、対話型アシスタント | 文書分析、構造化入出力タスク |
| 入力形式 | メッセージリスト(messages) |
任意の構造化データ |
| 出力形式 | メッセージ形式 | 任意の構造化データ |
なぜ非会話型が必要なのか?ChatAgentではできないこと
1. 複数項目を構造化して返す
# ChatAgent(会話型)
# 入力
{"messages": [{"role": "user", "content": "この契約書を分析して"}]}
# 出力 → 文字列で返すしかない
{"messages": [{"role": "assistant", "content": "契約種別は業務委託で、金額は100万円で..."}]}
# ↑ 後続処理でパースが必要、フォーマットが不安定
# 非会話型
# 入力
{"document": "契約書テキスト..."}
# 出力 → 構造化データをそのまま返せる
{
"contract_type": "業務委託",
"amount": 1000000,
"parties": ["A社", "B社"],
"is_valid": true
}
# ↑ そのままDBに保存、APIレスポンスとして返却可能
2. 複数ファイル・複数質問の一括処理
# ChatAgent → 1メッセージ1リクエストが基本
{"messages": [{"role": "user", "content": "質問1"}]}
{"messages": [{"role": "user", "content": "質問2"}]} # 別リクエスト
# 非会話型 → まとめて投げてまとめて返せる
# 入力
{
"documents": ["doc1.pdf", "doc2.pdf", "doc3.pdf"],
"questions": ["要約して", "リスクは?", "期限は?"]
}
# 出力
{
"results": [
{"doc": "doc1.pdf", "summary": "...", "risks": [...], "deadline": "2025-03-31"},
{"doc": "doc2.pdf", "summary": "...", "risks": [...], "deadline": "2025-06-30"},
...
]
}
3. 数値・配列を直接やり取り
# ChatAgent → 全部文字列経由
{"messages": [{"role": "assistant", "content": "スコアは0.85です"}]}
# ↑ "0.85"を数値にパースする処理が必要
# 非会話型 → 型を保持
{"score": 0.85, "labels": ["positive", "neutral"], "confidence": [0.85, 0.12]}
# ↑ そのままJSONとして扱える
4. パラメータを明示的に分離
# ChatAgent → 全部contentに詰め込む
{"messages": [{"role": "user", "content": "日本語に翻訳して。フォーマルな口調で。以下のテキスト:Hello world"}]}
# ↑ プロンプトでパラメータを伝える、曖昧さが残る
# 非会話型 → パラメータを明確に分離
{
"text": "Hello world",
"target_language": "ja",
"tone": "formal",
"domain": "business"
}
# ↑ バリデーションも容易、APIドキュメントも明確
要するに、後続システムとの連携や型安全性が求められる場合に非会話型が必要になります。
- 人間が読む → ChatAgent
- システムが読む → 非会話型
という切り分けがわかりやすいでしょう。
トレース認証の違い:自動 vs 手動
会話型エージェントの場合(自動)
agents.deploy() を使うと、Databricksが裏側で以下を自動的に処理してくれます:
- サービスプリンシパルの自動作成
- MLflow Experimentへの書き込み権限の自動付与
- トレースの自動記録
このサービスプリンシパルはUIやAPIには表示されません。また、エージェントのモデルバージョンがエンドポイントから削除されると、自動的に削除されます。
非会話型エージェントの場合(手動)
非会話型エージェントは agents.deploy() が使えないため、以下を手動で行う必要があります:
-
サービスプリンシパル(またはPAT)を自分でプロビジョニングする
- MLflow Experimentへの
CAN_EDIT権限を付与
- MLflow Experimentへの
-
環境変数を手動で設定する
- サービスプリンシパルの場合:
DATABRICKS_CLIENT_IDとDATABRICKS_CLIENT_SECRET - PATの場合:
DATABRICKS_HOSTとDATABRICKS_TOKEN
- サービスプリンシパルの場合:
-
カスタムトレース統合を実装する
-
@mlflow.traceデコレータで手動トレース -
mlflow.tracing.set_destination()でトレース送信先を明示的に指定
-
サンプルコード: MLflowを使った非会話型AIエージェント
こちらのサンプルを実行します。
非会話型エージェントは、構造化された入力を受け取り、会話の状態を保持せずに特定の出力を返します。各リクエストは独立しており、ドキュメント分類、データ抽出、バッチ分析、構造化質問応答など、タスク特化型の処理に最適です。
会話型エージェントが複数ターンの対話を管理するのに対し、非会話型エージェントは明確なタスクを効率的に実行します。このシンプルな構成により、独立したリクエストの高いスループットが可能です。
このノートブックで学べること:
- 非会話型エージェントの作成方法
- MLflowによる包括的なトレーシングと可観測性の実装
- モデルサービングへのデプロイと自動トレース収集
- MLflow 3スコアラーによる本番監視の設定
必要条件
依存関係:
- MLflow 3.2.0以上
- databricks-agents 1.2.0以上
- databricks-sdk[openai](LLM連携用)
- Python 3.10以上
ワークスペースアクセス:
- ファウンデーションモデルAPIへのアクセス(デフォルト:Claude 3.7 Sonnet、変更可能)
- AIモデル登録用のカタログとスキーマへのアクセス
要件のインストール
%pip install --upgrade mlflow[databricks]==3.6.0 pydantic databricks-sdk[openai] databricks-agents databricks-sdk
%restart_python
例:シナリオ
この例のエージェントは、財務ドキュメントの内容に関する構造化質問を処理し、理由付きのYes/No回答を返します。ユーザーはドキュメント本文と質問を直接入力するため、ベクトル検索などのインフラは不要です。非会話型エージェントが明確なタスクを会話文脈なしで処理できることを示します。
本番用途では、ベクトル検索によるドキュメント取得、MCP(Model Context Protocol)ツールによる外部連携、GenieなどのDatabricksエージェントとの統合など、機能拡張が可能です。
サービスプリンシパルの設定
非会話型エージェントは、Model Servingからのトレース書き込み時に自動認証パススルーをサポートしません。MLflow 3のトレーシング統合をカスタム実装し、サービスプリンシパルによる認証を手動で行う必要があります。
-
サービスプリンシパルを作成します(AWS|Azure|GCP)。OAuth認証情報も取得します(AWS|Azure|GCP)。

サービスプリンシパル作成後にシークレットを生成します -
認証情報をシークレットスコープに保存します:
from databricks.sdk import WorkspaceClient SECRET_SCOPE = "demo-token-takaaki.yayoi" # ご自身のシークレットスコープ名に変更してください w = WorkspaceClient() w.secrets.put_secret(SECRET_SCOPE, "client_id", string_value ="<クライアントID>") w.secrets.put_secret(SECRET_SCOPE, "client_secret", string_value ="<シークレット>")
ユーザー設定
# TODO: 設定定数 - ご自身の環境に合わせて更新してください
CATALOG = "takaakiyayoi_catalog"
SCHEMA = "non_conversational_agent" # ご自身のスキーマ名に変更してください
SECRET_SCOPE = "demo-token-takaaki.yayoi" # ご自身のシークレットスコープ名に変更してください
DATABRICKS_HOST = (
"https://<ワークスペースURL>" # ご自身のワークスペースURLに変更してください
)
MLflowエクスペリメントの設定(AWS|Azure|GCP):
- 実験が存在しない場合は作成してください。
- サービスプリンシパルに
CAN_EDIT権限を付与してください。
その他の設定
# トレースを記録するMLflow実験名
EXPERIMENT_NAME = "/Workspace/Users/takaaki.yayoi@databricks.com/20251201_mlflow_non_conversational_agent/non-conversational"
# LLMの設定
LLM_MODEL = "databricks-claude-sonnet-4-5" # 他のモデルを使う場合は変更してください
# モデル名とエンドポイント名(変更不要)
MODEL_NAME = "document_analyser"
ENDPOINT_NAME = "document_analyser_agent"
REGISTERED_MODEL_NAME = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.ml import ExperimentAccessControlRequest
from databricks.sdk.service.iam import PermissionLevel
import mlflow
# 実験をセットし、実験オブジェクトを取得
experiment = mlflow.set_experiment(EXPERIMENT_NAME)
experiment_id = experiment.experiment_id
# シークレットスコープからサービスプリンシパルのclient_idを取得
client_id = dbutils.secrets.get(scope=SECRET_SCOPE, key="client_id")
# サービスプリンシパルにトレース書き込み権限を付与
w = WorkspaceClient()
# サービスプリンシパルにCAN_EDIT権限を付与
w.experiments.set_permissions(
experiment_id=experiment_id,
access_control_list=[
ExperimentAccessControlRequest(
service_principal_name=client_id,
permission_level=PermissionLevel.CAN_EDIT
)
]
)
print(f"✓ サービスプリンシパル {client_id[:8]}... にCAN_EDIT権限を付与しました(実験ID: {experiment_id})")
2025/12/03 04:57:10 INFO mlflow.tracking.fluent: Experiment with name '/Workspace/Users/takaaki.yayoi@databricks.com/20251201_mlflow_non_conversational_agent/non-conversational' does not exist. Creating a new experiment.
✓ サービスプリンシパル 4533bc8d... にCAN_EDIT権限を付与しました(実験ID: 922449267358331)
入力・出力フォーマット
会話型エージェントが柔軟なチャットメッセージ形式を使うのに対し、非会話型エージェントはPydanticモデルによる構造化入力・出力を使用します:
- タスク実行に必要な項目をすべて含む入力スキーマを作成
- 出力スキーマにトレースメタデータ(
trace_id,span_id)を含め、フィードバック記録を可能に - 必要に応じて詳細な理由や思考過程(chain-of-thought)を出力に含める
- 開発時にスキーマバリデーションを行い、デプロイ前にエラーを検出
入力フォーマット(AgentInput)
{
"document_text": "Document content to analyze...",
"questions": [
{"text": "Do the documents contain a balance sheet?"},
{"text": "Do the documents contain an income statement?"},
{"text": "Do the documents contain a cash flow statement?"}
]
}
非会話型エージェントの構築
MLflowトレーシング付きの非会話型エージェントを作成します。エージェントは@mlflow.traceデコレーターを使い、LLM呼び出しやリクエスト全体の流れを自動的に記録し、可観測性を高めます。
ユーザーはドキュメント本文と質問を直接入力します。
非対話型エージェントモデルの定義
%%writefile model.py
import json
import logging
from typing import Optional
import uuid
import os
import sys
from databricks.sdk import WorkspaceClient
import mlflow
from mlflow.pyfunc import PythonModel
from mlflow.tracing import set_destination
from mlflow.tracing.destination import Databricks
from mlflow.entities import SpanType
from pydantic import BaseModel, Field
class Question(BaseModel):
"""入力の質問を表します。"""
text: str = Field(..., description="ドキュメント内容に関するYes/No質問")
class AgentInput(BaseModel):
"""ドキュメント分析エージェントの入力モデル"""
document_text: str = Field(..., description="分析対象のドキュメント本文")
questions: list[Question] = Field(..., description="Yes/No質問のリスト")
class Answer(BaseModel):
"""LLMからの構造化応答を表します。"""
answer: str = Field(..., description="YesまたはNoの回答")
chain_of_thought: str = Field(..., description="回答の理由や思考過程")
class AnalysisResult(BaseModel):
"""出力の分析結果を表します。"""
question_text: str = Field(..., description="元の質問文")
answer: str = Field(..., description="YesまたはNoの回答")
chain_of_thought: str = Field(..., description="回答の理由や思考過程")
span_id: str | None = Field(None, description="この回答に対応するMLflowのspan ID(オフライン評価時はNone)")
class AgentOutput(BaseModel):
"""ドキュメント分析エージェントの出力モデル"""
results: list[AnalysisResult] = Field(..., description="分析結果のリスト")
trace_id: str | None = Field(None, description="ユーザーフィードバック収集用のMLflow trace ID(オフライン評価時はNone)")
class DocumentAnalyser(PythonModel):
"""MLflowモデルサービング用の非会話型ドキュメント分析エージェント"""
def __init__(self) -> None:
"""ドキュメント分析エージェントの初期化
ロギング設定、モデルプロパティの初期化、サービング準備を行います。
"""
self._setup_logging()
self.model_name = "document_analyser_v1"
self.logger.debug(f"{self.model_name} を初期化しました")
def _setup_logging(self) -> None:
"""Model Serving用のロギング設定
stderrを使ったロガーを設定します。ログレベルは環境変数MODEL_LOG_LEVELで制御可能(デフォルトはINFO)。
"""
self.logger = logging.getLogger("ModelLogger")
# 環境変数またはデフォルトでログレベルを設定
log_level = os.getenv("MODEL_LOG_LEVEL", "INFO").upper()
self.logger.setLevel(getattr(logging, log_level, logging.INFO))
if not self.logger.handlers:
handler = logging.StreamHandler()
handler.setLevel(getattr(logging, log_level, logging.INFO))
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
self.logger.addHandler(handler)
def load_context(self, context) -> None:
"""モデルコンテキストのロードとクライアント初期化
モデルがサービング環境でロードされる際に呼ばれます。MLflowトレーシング先の設定、Databricksワークスペースクライアントの初期化、LLM推論用OpenAI互換クライアントの設定を行います。
Args:
context: アーティファクトや設定を含むMLflowモデルコンテキスト
"""
self.logger.debug("モデルコンテキストをロード中")
set_destination(Databricks(experiment_id=os.getenv("MONITORING_EXPERIMENT_ID")))
self.logger.debug("ワークスペースクライアントを初期化")
self.w = WorkspaceClient()
# 必要に応じてアーティファクトをロード可能
# self.artifacts = context.artifacts
self.logger.debug("OpenAIクライアントを初期化")
# Databricksサービングエンドポイント用のOpenAI互換クライアントを取得
self.openai_client = self.w.serving_endpoints.get_open_ai_client()
@mlflow.trace(name="answer_question", span_type=SpanType.LLM)
def answer_question(self, question_text: str, document_text: str) -> tuple[object, str | None]:
"""LLMを使って構造化応答形式で質問に回答
OpenAI互換クライアントを使い、構造化JSON応答形式で言語モデルを呼び出します。ドキュメント本文を分析し、Yes/No回答と理由を返します。
Args:
question_text (str): ドキュメントに関するYes/No質問
document_text (str): 分析対象のドキュメント本文
Returns:
tuple: (openai.ChatCompletion, str|None) - LLM応答とspan_id
"""
# 質問用のチャットプロンプトを作成
question_prompt = f"""
あなたはドキュメント分析の専門家です。以下のYes/No質問に、与えられたドキュメントをもとに日本語で回答してください。
質問: "{question_text}"
ドキュメント:
{document_text}
ドキュメントを分析し、構造化応答(answer: YesまたはNo, chain_of_thought: 理由や根拠)を日本語で返してください。
"""
# OpenAI API呼び出し用のサブスパンを作成
llm_response = self._call_openai_completion(question_prompt)
# この回答に対応する現在のspan IDを取得
current_span = mlflow.get_current_active_span()
span_id = current_span.span_id if current_span is not None else None
return llm_response, span_id
@mlflow.trace(name="openai_completion", span_type=SpanType.LLM)
def _call_openai_completion(self, prompt: str):
"""OpenAI API呼び出し(サブスパン付き)
Args:
prompt (str): LLMに送るプロンプト
Returns:
OpenAI ChatCompletion応答
"""
return self.openai_client.chat.completions.create(
model=os.getenv("LLM_MODEL", "databricks-claude-3-7-sonnet"), # LLMモデルは環境変数で設定可能
messages=[
{
"role": "user",
"content": prompt
}
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "question_response",
"schema": Answer.model_json_schema()
}
}
)
@mlflow.trace(name="document_analysis")
def predict(self, context, model_input: list[AgentInput]) -> list[AgentOutput]:
"""ドキュメント分析質問をYes/Noで処理
Args:
context: MLflowモデルコンテキスト
model_input: ドキュメント本文と質問を含む構造化入力のリスト
Returns:
Yes/No回答と理由を含むAgentOutputのリスト
"""
self.logger.debug(f"{len(model_input)}件の分類リクエストを処理中")
# ユーザーフィードバック収集用の現在のtrace IDを取得
# オフライン評価時はNone
current_span = mlflow.get_current_active_span()
trace_id = current_span.trace_id if current_span is not None else None
results = []
for input_data in model_input:
self.logger.debug(f"質問数: {len(input_data.questions)}")
self.logger.debug(f"ドキュメント長: {len(input_data.document_text)}文字")
analysis_results = []
for question in input_data.questions:
self.logger.debug(f"質問処理中: {question.text}")
# LLMで質問に回答(構造化応答)
llm_response, answer_span_id = self.answer_question(question.text, input_data.document_text)
# 構造化JSON応答をパース
try:
response_data = json.loads(llm_response.choices[0].message.content)
answer_obj = Answer(**response_data)
except Exception as e:
self.logger.debug(f"構造化応答のパースに失敗: {e}")
# パース失敗時はデフォルト応答
answer_obj = Answer(
answer="いいえ",
chain_of_thought="パースエラーのため質問を処理できませんでした。"
)
analysis_results.append(AnalysisResult(
question_text=question.text,
answer=answer_obj.answer,
chain_of_thought=answer_obj.chain_of_thought,
span_id=answer_span_id
))
self.logger.debug(f"{len(analysis_results)}件の分析結果を生成")
results.append(AgentOutput(
results=analysis_results,
trace_id=trace_id
))
return results
mlflow.models.set_model(DocumentAnalyser())
Overwriting model.py
エージェントのログ・登録
エージェントをサービングエンドポイントにデプロイする前に、MLflow実験にログし、Unity Catalogに登録する必要があります。
import os
import mlflow
import json
from mlflow.pyfunc import PythonModel
from pydantic import BaseModel, Field
from model import DocumentAnalyser, AgentInput, Question
# シグネチャ推論用の入力例を作成
def create_example_input() -> AgentInput:
"""非会話型エージェント用の入力例を作成"""
return AgentInput(
document_text="総資産: $2,300,000. 総負債: $1,200,000. 株主資本: $1,100,000. 当期純利益: $450,000. 売上高: $1,700,000. 費用: $1,250,000. 営業活動によるキャッシュフロー: $80,000. 投資活動によるキャッシュフロー: -$20,000",
questions=[
Question(text="文書にはバランスシートが含まれていますか?"),
Question(text="文書には損益計算書が含まれていますか?"),
Question(text="文書にはキャッシュフロー計算書が含まれていますか?"),
],
)
input_example = create_example_input()
with mlflow.start_run(run_name="非会話型エージェントのデプロイ"):
active_run = mlflow.active_run()
current_experiment_id = active_run.info.experiment_id
# モデル用の環境変数を現在のノートブック実験IDで設定
os.environ["MONITORING_EXPERIMENT_ID"] = current_experiment_id
print(
f"✓ トレーシングに現在のノートブック実験IDを使用: {current_experiment_id}"
)
# 非会話型エージェントを自動依存関係推論付きでログ
model_info = mlflow.pyfunc.log_model(
name=MODEL_NAME,
python_model="model.py", # モデルコードファイルのパス
input_example=[create_example_input().model_dump()],
registered_model_name=REGISTERED_MODEL_NAME,
)
# ログしたモデルを評価結果に紐付けるため、アクティブモデルに設定
mlflow.set_active_model(model_id=mlflow.last_logged_model().model_id)
print(f"✓ モデルをログ・登録しました: {REGISTERED_MODEL_NAME}")
print(f"✓ モデルバージョン: {model_info.registered_model_version}")
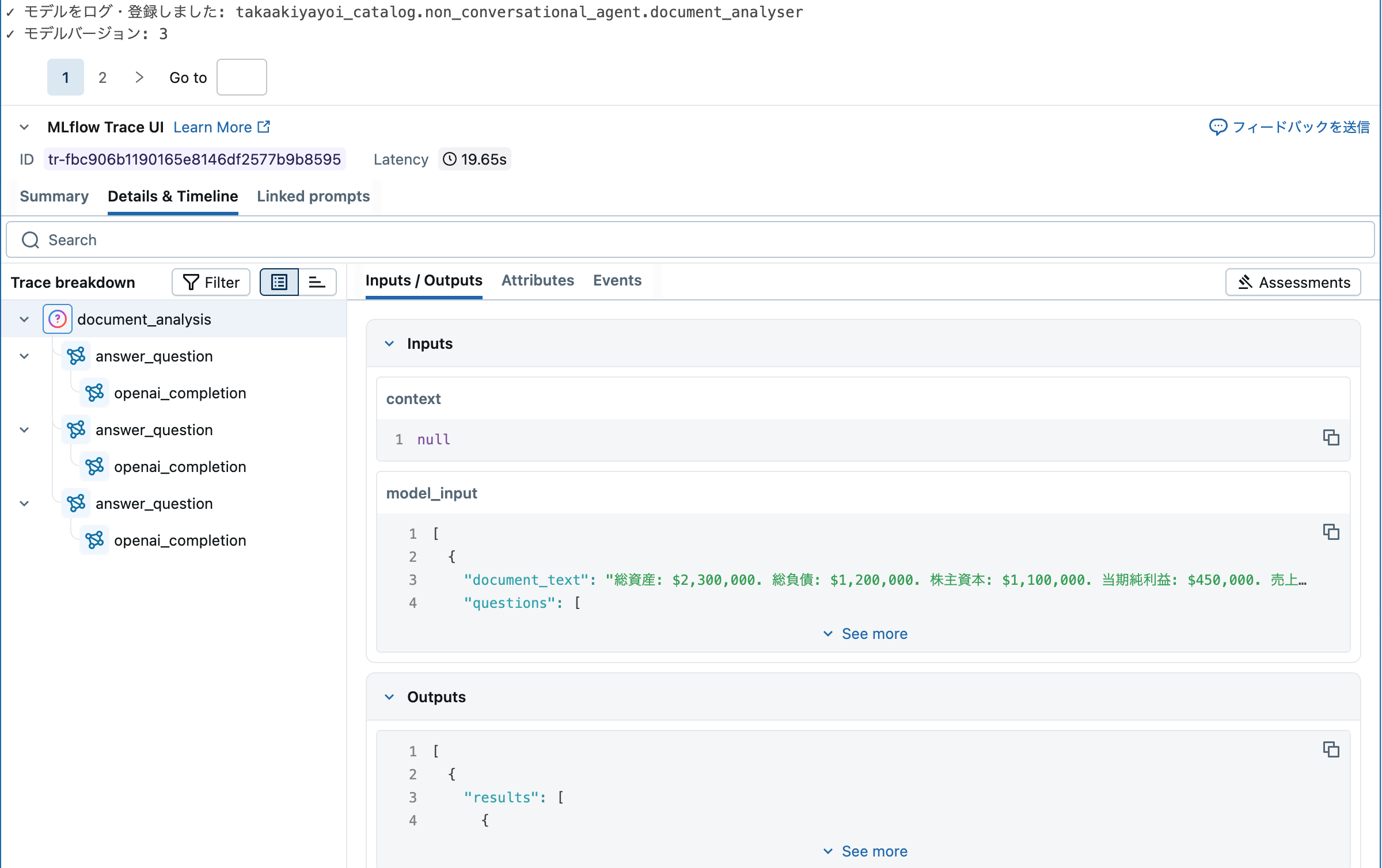
エージェントの評価
本番デプロイ前に、MLflowの生成AI評価フレームワークと組み込みスコアラーを使ってエージェントの性能を評価します。一部のスコアラーは正解データセットが必要です。
MLflowマネージド評価データセットの作成
import mlflow
import mlflow.genai.datasets
from requests import HTTPError
# Unity Catalogに評価用データセットを作成
uc_schema = f"{CATALOG}.{SCHEMA}"
evaluation_dataset_table_name = "document_analyser_eval"
try:
# 新しい評価データセットを作成
eval_dataset = mlflow.genai.datasets.create_dataset(
uc_table_name=f"{uc_schema}.{evaluation_dataset_table_name}",
)
print(f"✓ 評価データセットを作成: {uc_schema}.{evaluation_dataset_table_name}")
except HTTPError as e:
# TABLE_ALREADY_EXISTSエラーかどうか確認
if e.response.status_code == 400 and "TABLE_ALREADY_EXISTS" in str(e):
print(
f"データセット {uc_schema}.{evaluation_dataset_table_name} は既に存在します。既存データセットをロードします..."
)
eval_dataset = mlflow.genai.datasets.get_dataset(
uc_table_name=f"{uc_schema}.{evaluation_dataset_table_name}"
)
print(
f"✓ 既存の評価データセットをロード: {uc_schema}.{evaluation_dataset_table_name}"
)
else:
# その他のHTTPエラーは再送出
raise
# 正解比較用の包括的なテストケースを定義
sample_document = "総資産: $2,300,000. 総負債: $1,200,000. 株主資本: $1,100,000. 当期純利益: $450,000. 売上高: $1,700,000. 費用: $1,250,000. 営業活動によるキャッシュフロー: $80,000. 投資活動によるキャッシュフロー: -$20,000"
evaluation_examples = [
{
"inputs": {
"document_text": sample_document,
"questions": [{"text": "文書にバランスシートが含まれていますか?"}],
},
"expectations": {
"expected_facts": [
"答えははい",
"バランスシート情報",
"総資産が言及されている",
"総負債が言及されている",
"株主資本が言及されている",
]
},
},
{
"inputs": {
"document_text": sample_document,
"questions": [{"text": "文書に損益計算書が含まれていますか?"}],
},
"expectations": {
"expected_facts": [
"答えははい",
"損益計算書情報",
"純利益が言及されている",
"売上高が言及されている",
"費用が言及されている",
]
},
},
{
"inputs": {
"document_text": sample_document,
"questions": [{"text": "文書にキャッシュフロー計算書が含まれていますか?"}],
},
"expectations": {
"expected_facts": [
"答えははい",
"キャッシュフロー情報",
"営業活動が言及されている",
"投資活動が言及されている",
"キャッシュフローが言及されている",
]
},
},
{
"inputs": {
"document_text": sample_document,
"questions": [
{
"text": "文書に従業員福利厚生に関する情報が含まれていますか?"
}
],
},
"expectations": {
"expected_facts": [
"答えはいいえ",
"従業員福利厚生情報はない",
"財務諸表に焦点を当てている",
"人事関連の内容はない",
]
},
},
]
# 評価例をデータセットに追加
eval_dataset.merge_records(evaluation_examples)
print(f"✓ {len(evaluation_examples)}件のレコードを評価データセットに追加")
# データセットをプレビュー
df = eval_dataset.to_df()
print(f"✓ データセットプレビュー - 総レコード数: {len(df)}")
df.display()

MLflowデータセットによるオフライン評価の実行
import warnings
import mlflow
from mlflow.genai.scorers import (
RelevanceToQuery,
Correctness,
Guidelines,
)
# Databricks環境で表示される無害なthreadpoolctl警告を抑制
warnings.filterwarnings("ignore", message=".*threadpoolctl.*")
warnings.filterwarnings("ignore", category=UserWarning, module="threadpoolctl")
# 評価用にログしたモデルをロード
model_uri = f"models:/{REGISTERED_MODEL_NAME}/{model_info.registered_model_version}"
print(f"評価用モデルをロード: {model_uri}")
# モデルをpredict関数としてロード
loaded_model = mlflow.pyfunc.load_model(model_uri)
def my_app(document_text, questions):
"""モデル予測用のラッパー関数"""
# 評価データセットのinputsフィールドは{"document_text": "...", "questions": [...]}形式
# predict_fnのパラメータ名はinputsのキーと一致させる必要あり
input_data = {"document_text": document_text, "questions": questions}
return loaded_model.predict([input_data])
# 正解比較を含む評価用スコアラーを定義
correctness_scorer = Correctness() # expected_factsと比較
relevance_scorer = RelevanceToQuery() # 回答の質問への関連性を評価
response_schema_scorer = Guidelines(
name="response_schema",
guidelines="レスポンスは'answer'(Yes/No)と'chain_of_thought'(理由)を含む構造化JSONであること。'question_text'も必須。これらは'results'配列内に含まれること。",
) # 構造化出力形式のバリデーション
# MLflow管理データセットを使って評価ランを作成
results = mlflow.genai.evaluate(
data=eval_dataset, # MLflow管理データセットを使用
predict_fn=my_app,
scorers=[
correctness_scorer,
relevance_scorer,
response_schema_scorer,
],
)
# ランIDにアクセス
print(f"✓ 評価が完了しました")
print(f"評価ランID: {results.run_id}")
# 評価結果サマリーを表示
if hasattr(results, "metrics") and results.metrics:
print("\n📊 評価結果サマリー:")
for metric_name, metric_value in results.metrics.items():
if isinstance(metric_value, (int, float)):
print(f" • {metric_name}: {metric_value:.3f}")
else:
print(f" • {metric_name}: {metric_value}")
else:
print("✓ 評価が完了しました - 詳細結果は評価実験で確認してください")
# 評価データセットへのリンクを表示
print(f"\n📊 評価データセット: {uc_schema}.{evaluation_dataset_table_name}")
print(f"🔗 Unity Catalog Data Explorerでデータセットを表示")
✓ 評価が完了しました
評価ランID: b23ef747bc4944f69072e2d61d5c6960
📊 評価結果サマリー:
• relevance_to_query/mean: 1.000
• response_schema/mean: 1.000
• correctness/mean: 1.000
📊 評価データセット: takaakiyayoi_catalog.non_conversational_agent.document_analyser_eval
🔗 Unity Catalog Data Explorerでデータセットを表示
エクスペリメントに評価結果が表示されます。

モデルサービングへのデプロイ
評価済みエージェントをMLflow 3トレーシング用の環境変数付きでModel Servingエンドポイントにデプロイします。これにより、本番リクエストがすべて指定したMLflow実験に自動的にトレース・記録されます。
モデルサービングへのデプロイ
import mlflow
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import (
ServedEntityInput,
ServingModelWorkloadType,
EndpointCoreConfigInput,
)
from model import DocumentAnalyser, AgentInput, Question
workspace = WorkspaceClient()
# ログしたモデルのバージョンを使用
model_version = model_info.registered_model_version
print(f"使用するモデルバージョン: {model_version}")
new_entity = ServedEntityInput(
entity_name=REGISTERED_MODEL_NAME,
entity_version=model_version,
name=f"{MODEL_NAME}-{model_version}",
workload_size="Small",
workload_type=ServingModelWorkloadType.CPU,
scale_to_zero_enabled=True,
environment_vars={
"DATABRICKS_CLIENT_ID": f"{{{{secrets/{SECRET_SCOPE}/client_id}}}}",
"DATABRICKS_CLIENT_SECRET": f"{{{{secrets/{SECRET_SCOPE}/client_secret}}}}",
"DATABRICKS_HOST": DATABRICKS_HOST,
"MLFLOW_TRACKING_URI": "databricks",
"MONITORING_EXPERIMENT_ID": current_experiment_id,
"MODEL_LOG_LEVEL": "INFO",
"LLM_MODEL": LLM_MODEL,
},
)
# エンドポイントが存在するか確認し、作成または更新
try:
# 既存エンドポイントを取得
existing_endpoint = workspace.serving_endpoints.get(ENDPOINT_NAME)
print(
f"エンドポイント {ENDPOINT_NAME} は存在します。モデルバージョン {model_version} で更新します"
)
# 既存エンドポイントを新しいモデルバージョンで更新
workspace.serving_endpoints.update_config(
name=ENDPOINT_NAME, served_entities=[new_entity]
)
print("エンドポイントの更新を開始、完了まで待機...")
# 更新完了まで待機
workspace.serving_endpoints.wait_get_serving_endpoint_not_updating(ENDPOINT_NAME)
print("エンドポイントが正常に更新され、準備完了")
except Exception as e:
# エンドポイントが存在しない場合は新規作成
print(f"エンドポイント {ENDPOINT_NAME} が存在しません。新規作成します...")
workspace.serving_endpoints.create(
name=ENDPOINT_NAME,
config=EndpointCoreConfigInput(name=ENDPOINT_NAME, served_entities=[new_entity]),
)
print("エンドポイントの作成を開始、完了まで待機...")
# 作成完了まで待機
workspace.serving_endpoints.wait_get_serving_endpoint_not_updating(ENDPOINT_NAME)
print("エンドポイントが正常に作成され、準備完了")
# 最終ステータス確認
endpoint_status = workspace.serving_endpoints.get(ENDPOINT_NAME)
print(f"最終エンドポイントステータス: {endpoint_status.state}")
print(
f"エンドポイントURL: https://{DATABRICKS_HOST.replace('https://', '')}/serving-endpoints/{ENDPOINT_NAME}/invocations"
)
使用するモデルバージョン: 3
エンドポイント document_analyser_agent が存在しません。新規作成します...
エンドポイントの作成を開始、完了まで待機...
エンドポイントが正常に作成され、準備完了
最終エンドポイントステータス: EndpointState(config_update=<EndpointStateConfigUpdate.NOT_UPDATING: 'NOT_UPDATING'>, ready=<EndpointStateReady.READY: 'READY'>)
エンドポイントURL: https://xxxx.cloud.databricks.com/serving-endpoints/document_analyser_agent/invocations

本番監視用スコアラーの設定
本番トラフィックの自動品質評価をMLflow 3スコアラーで構成します。スコアラーは本番リクエストから記録されたトレースを自動分析し、継続的な品質監視を実現します。ここでは、わかりやすさのためにサンプリング率を100%にしています。
本番運用スコアラーの設定
from mlflow.genai.scorers import (
RelevanceToQuery,
Guidelines,
ScorerSamplingConfig,
list_scorers,
get_scorer,
)
# スコアリング用の実験を設定(現在のノートブック実験IDを使用)
print(f"実験を設定しています: {current_experiment_id}")
mlflow.set_experiment(experiment_id=current_experiment_id)
# 実験が正しく設定されたか確認
current_experiment = mlflow.get_experiment(current_experiment_id)
print(
f"現在の実験: {current_experiment.name} (ID: {current_experiment.experiment_id})"
)
# 本番監視用スコアラーをセットアップ
print("本番監視スコアラーをセットアップしています...")
# 関連性スコアラー(常に新規作成、競合回避のため)
relevance_scorer = RelevanceToQuery().register(name="financial_relevance_check")
relevance_scorer = relevance_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0)
)
print("✅ 関連性スコアラーを作成しました(サンプリング率100%)")
# レスポンススキーマバリデーション用ガイドラインスコアラー
response_schema_scorer = Guidelines(
name="response_schema",
guidelines="レスポンスは'answer'(Yes/No)と'chain_of_thought'(理由)を含む構造化JSONであること。",
).register(name="response_schema_check")
response_schema_scorer = response_schema_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0)
)
print("✅ レスポンススキーマスコアラーを作成しました(サンプリング率100%)")
# 実験内の全アクティブスコアラーを表示
print(f"\n実験 {current_experiment_id} のアクティブスコアラー:")
scorers = list_scorers()
for scorer in scorers:
print(f"• {scorer.name}: {scorer.sample_rate*100}% サンプリング")
実験を設定しています: 922449267358331
現在の実験: /Users/takaaki.yayoi@databricks.com/20251201_mlflow_non_conversational_agent/non-conversational (ID: 922449267358331)
本番監視スコアラーをセットアップしています...
✅ 関連性スコアラーを作成しました(サンプリング率100%)
✅ レスポンススキーマスコアラーを作成しました(サンプリング率100%)
実験 922449267358331 のアクティブスコアラー:
• financial_relevance_check: 100.0% サンプリング
• response_schema_check: 100.0% サンプリング
エクスペメリメントでもスコアラーを確認できます。
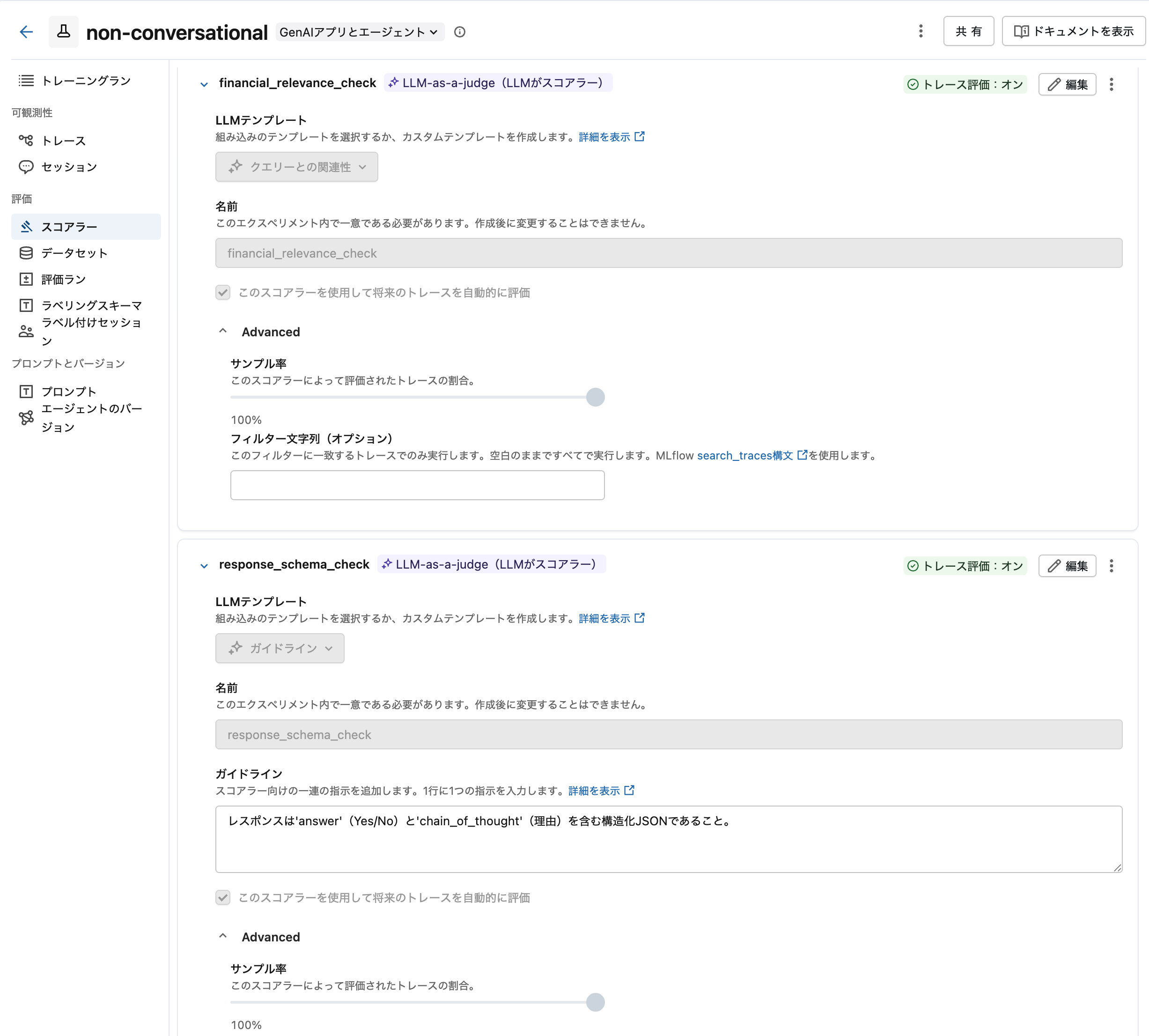
スコアラーを実行するジョブも作成されます。
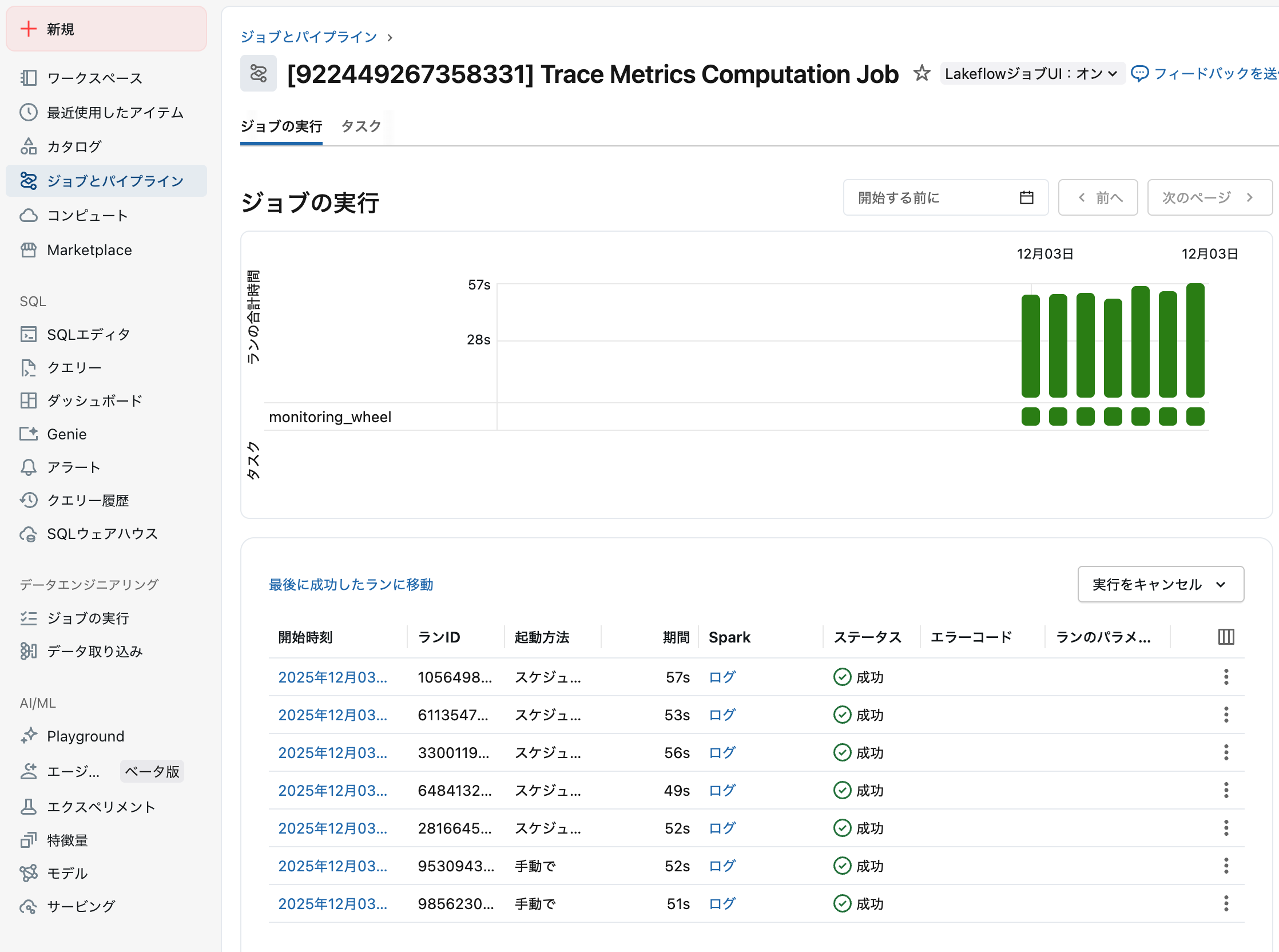
デプロイ済みエージェントのテスト
サンプル入力でデプロイ済みエージェントをテストします。各リクエストはMLflow 3のトレースを自動生成し、リクエスト全体のフローを記録します。本番監視用スコアラーがこれらのトレースを評価し、品質監視を行います。
デプロイされた非会話型エージェントのテスト
from databricks.sdk import WorkspaceClient
# Databricks SDKを使って非会話型エージェントエンドポイントをテスト
workspace = WorkspaceClient()
# 非会話型エージェント用の構造化入力例
test_input = {
"inputs": [
{
"document_text": "総資産: $2,300,000. 総負債: $1,200,000. 株主資本: $1,100,000. 当期純利益: $450,000. 売上高: $1,700,000. 費用: $1,250,000. 営業活動によるキャッシュフロー: $80,000. 投資活動によるキャッシュフロー: -$20,000",
"questions": [
{"text": "文書には貸借対照表が含まれていますか?"},
{"text": "文書には損益計算書が含まれていますか?"},
{"text": "文書にはキャッシュフロー計算書が含まれていますか?"},
],
}
]
}
# ワークスペースクライアントでサービングエンドポイントに問い合わせ
response = workspace.serving_endpoints.query(
name=ENDPOINT_NAME, inputs=test_input["inputs"]
)
print("エンドポイントの応答:")
print(response.as_dict())
# MLflow実験URLを生成
experiment_url = f"{DATABRICKS_HOST}/ml/experiments/{current_experiment_id}"
print(f"\nMLflow実験のURL: {experiment_url}")
エンドポイントの応答:
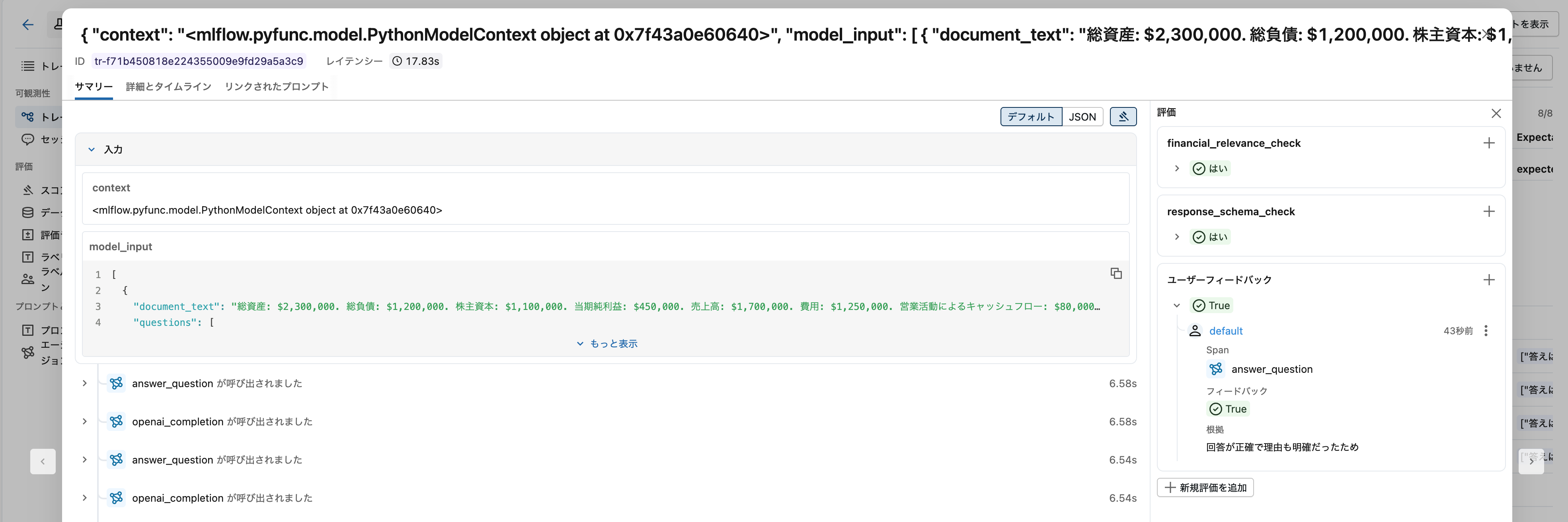
{'predictions': [{'results': [{'question_text': '文書には貸借対照表が含まれていますか?', 'answer': 'Yes', 'chain_of_thought': '文書には貸借対照表の主要な構成要素が含まれています。具体的には、「総資産: $2,300,000」「総負債: $1,200,000」「株主資本: $1,100,000」という貸借対照表の3つの基本項目が記載されています。貸借対照表は資産、負債、株主資本(純資産)で構成され、資産=負債+株主資本という等式が成り立ちます。この文書では$2,300,000 = $1,200,000 + $1,100,000という関係が確認でき、貸借対照表の情報が含まれていると判断できます。なお、文書には損益計算書(当期純利益、売上高、費用)やキャッシュフロー計算書の情報も含まれていますが、貸借対照表の要素も明確に存在しています。', 'span_id': '0c6b9e8fd5bf838a'}, {'question_text': '文書には損益計算書が含まれていますか?', 'answer': 'Yes', 'chain_of_thought': '文書には損益計算書の主要な構成要素が含まれています。具体的には、「売上高: $1,700,000」「費用: $1,250,000」「当期純利益: $450,000」という損益計算書に必要な項目が記載されています。損益計算書は企業の一定期間における収益と費用を示し、最終的な利益を算出する財務諸表であり、これらの情報はまさに損益計算書の内容を表しています。また、売上高から費用を差し引いた金額($1,700,000 - $1,250,000 = $450,000)が当期純利益と一致しており、損益計算書の構造として整合性が取れています。したがって、この文書には損益計算書が含まれていると判断できます。', 'span_id': 'd9ca5a2849a35e3e'}, {'question_text': '文書にはキャッシュフロー計算書が含まれていますか?', 'answer': 'Yes', 'chain_of_thought': 'ドキュメントには「営業活動によるキャッシュフロー: $80,000」と「投資活動によるキャッシュフロー: -$20,000」という記載があります。これらはキャッシュフロー計算書の主要な構成要素です。キャッシュフロー計算書は通常、営業活動、投資活動、財務活動の3つのセクションから構成されますが、このドキュメントには少なくとも営業活動と投資活動に関するキャッシュフローの情報が含まれているため、キャッシュフロー計算書の要素が含まれていると判断できます。', 'span_id': 'dc2d0a0376884148'}], 'trace_id': 'tr-f71b450818e224355009e9fd29a5a3c9'}], 'served-model-name': 'document_analyser-3'}
MLflow実験のURL: https://xxxx.cloud.databricks.com/ml/experiments/922449267358331
少し待つと、モデルサービングエンドポイント経由で記録されたトレースが評価されます。一部の列しか表示されていない場合には、列 > すべてのAssessmentsをチェックしてください。
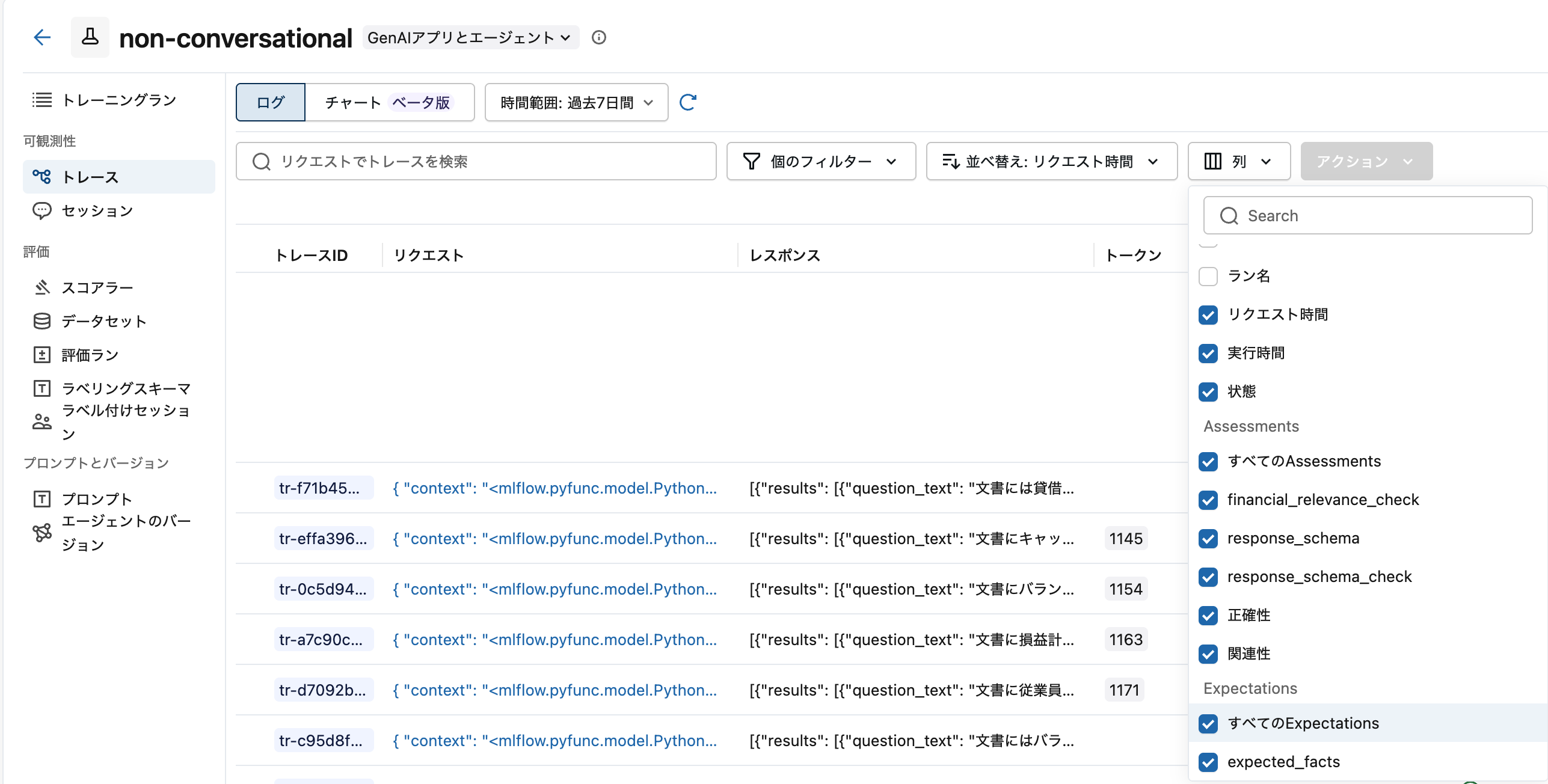

ユーザーフィードバックの記録
非会話型エージェントでも継続的な改善のためにユーザーフィードバックの収集は重要です。フロントエンドアプリケーションで、エージェントの各回答に対して「正しい」「誤り」などのフィードバックを受け付け、レスポンスに含まれるtrace_idとspan_idを使ってMLflowに記録できます。
非会話型エージェントの主なフィードバック例:
- 正確性フィードバック:「このYes/No回答は正しかったですか?」
- 関連性フィードバック:「理由付けは質問に適切でしたか?」
- 品質フィードバック:「根拠となる説明は十分でしたか?」
- エラー報告:「エージェントがドキュメント内容を誤解していませんか?」
以下のセルは、レスポンスで返されたspan_idを使って個別回答にフィードバックを記録する例です。
個別の回答に対するユーザーフィードバック記録のデモンストレーション
import mlflow
from mlflow.entities import AssessmentSource
# 前のテスト応答からspan_idを抽出(1件目の結果)
# 実際のアプリケーションではAPIレスポンスから取得
response_dict = response.as_dict()
first_prediction = response_dict["predictions"][0]
first_result = first_prediction["results"][0]
# フィードバック記録に必要なIDがあるか確認
assert (
first_result.get("span_id") is not None
), "フィードバック記録にはspan_idが必要です"
assert (
first_prediction.get("trace_id") is not None
), "フィードバック記録にはtrace_idが必要です"
span_id = first_result["span_id"]
trace_id = first_prediction["trace_id"]
question_text = first_result["question_text"]
answer = first_result["answer"]
print(f"質問に対するフィードバックを記録: '{question_text}'")
print(f"エージェントの回答: {answer}")
print(f"スパンID: {span_id}")
print(f"トレースID: {trace_id}")
try:
# 例:ユーザーがこの回答に肯定的なフィードバックを提供
mlflow.log_feedback(
trace_id=trace_id,
span_id=span_id,
name="ユーザーフィードバック",
value=True, # Trueは肯定、Falseは否定
source=AssessmentSource(source_type="HUMAN"),
rationale="回答が正確で理由も明確だったため",
)
print("✅ フィードバックを正常に記録しました!")
except Exception as e:
print(f"注意: この環境ではフィードバックを記録できません: {e}")
質問に対するフィードバックを記録: '文書には貸借対照表が含まれていますか?'
エージェントの回答: Yes
スパンID: 0c6b9e8fd5bf838a
トレースID: tr-f71b450818e224355009e9fd29a5a3c9
✅ フィードバックを正常に記録しました!
最新のトレースを確認すると、ユーザーフィードバックが記録されていることを確認できます。
次のステップ
- エージェントにツールを追加する方法を学ぶ(AWS|Azure|GCP)
- MLflow 3トレーシングのドキュメント(AWS|Azure|GCP)で高度な可観測性機能を確認
- 本番監視のドキュメント(AWS|Azure|GCP)
まとめ
| 観点 | 会話型 | 非会話型 |
|---|---|---|
| 本質 | ChatAgent準拠 | カスタムスキーマ |
| 利点 | 設定が楽、自動化されている | 柔軟、型安全、システム連携向き |
| 欠点 | 出力が文字列のみ | 認証・トレースを自分で実装 |
| 選ぶ基準 | 人間向けUI | システム間連携 |
「非会話型」という名前は正直イマイチですが、実態は「ChatAgentじゃないエージェント」という意味です。後続システムとの連携や構造化データの受け渡しが必要な場合は、非会話型エージェントを検討してみてください。