How to Deploy ML Production Pipelines Even Easier With Python Wheel Tasks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
豊富なオープンソースエコシステムと、とっつき易い文法によってPythonは、データエンジニアリングと機械学習における主要なプログラミング言語となりました。データエンジニア、MLエンジニアはすでにPythonノートブック、Pythonスクリプトを用いてパイプラインをおーけストレートするためにDatabricksを活用しています。本日、より複雑なPythonのデータパイプライン、MLパイプラインのコードをより簡単に開発、パッケージ、デプロイできるようにDatabricksでPythonのWheelを実行できるようになったことを発表できることを嬉しく思います。
Python wheelタスクはインタラクティブクラスターあるいはマルチタスクのジョブの一部としてジョブクラスター上で実行することができます。
Wheelパッケージフォーマットを用いることで、Python開発者は別のシステムに簡単かつ信頼性を持ってコンポーネントをインストールできるように、プロジェクトのコンポーネントをパッケージングすることができます。JVMの世界におけるJARフォーマットのように、Wheelは通常CI/CDシステムのアウトプットとなっており、圧縮された単一のビルドアーティファクトです。JARと同様に、Wheelにはソースコードだけではなく、全ての依存関係への参照も含まれています。
Wheelを用いたジョブを実行するためには、ローカルあるいはCI/CDパイプラインでPython Wheelを構築します。タスクでWheelのパスを指定し、エントリーポイントとして実行されるべきメソッドを指定します。タスクのパラメーターは、*argsあるいは**kwargsを通じてお使いのメインメソッドに引き渡されます。
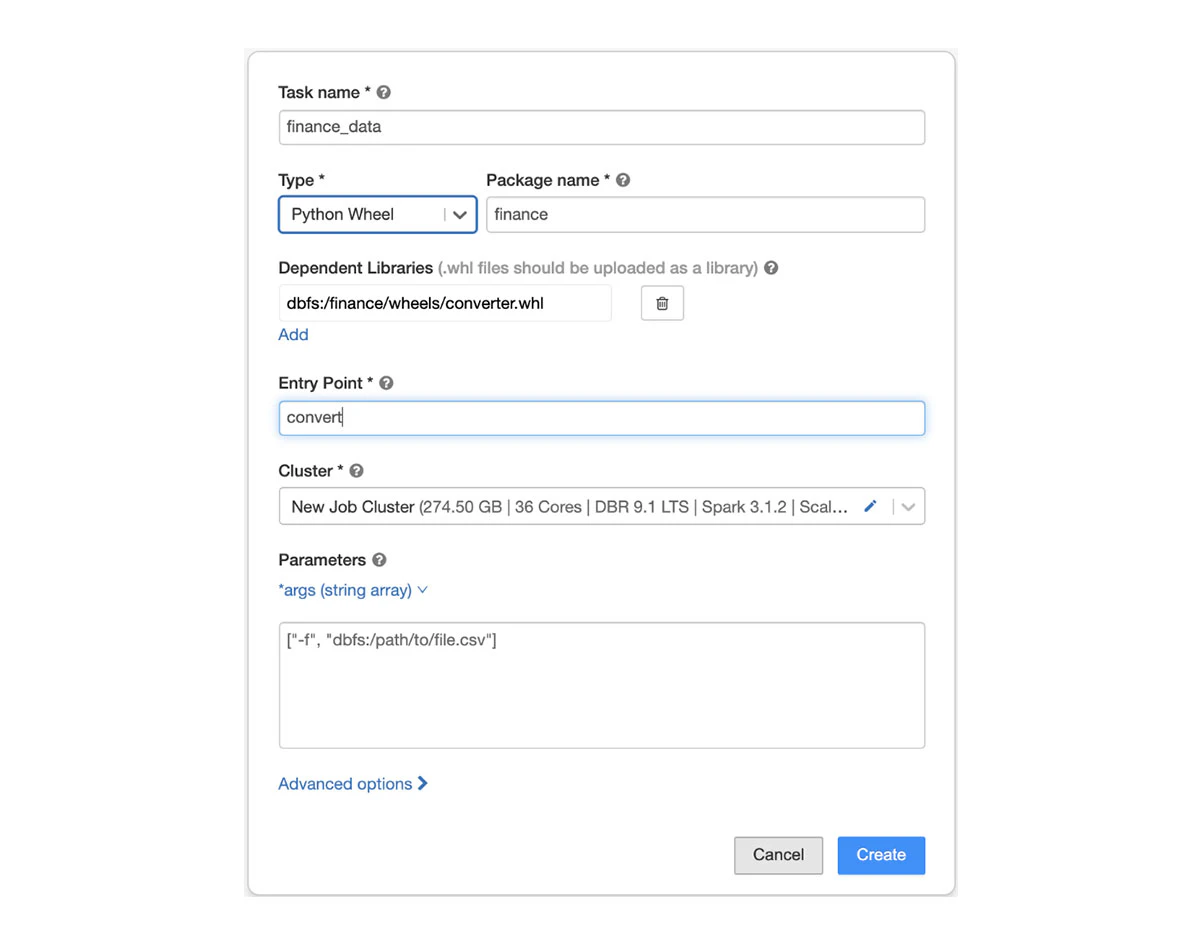
DatabricksジョブにおけるPython WheelタスクはGA(Generally Available)です。是非本機能を試していただき、我々がどのようにPythonデータエンジニアをサポートできるのかについてフィードバックいただければと思います。