Databricksの利用者が、容易に依存関係のある複数のデータパイプライン、機械学習パイプラインを構築できる様にする新機能である、ジョブオーケストレーションのGA(General Availability)を発表できることを嬉しく思います。
今では、データパイプラインは、自信の複雑性を緩和するために、一連の依存関係のあるタスクとして定義されるのが一般的です。しかし、この作業はいまだに、データチームにとって負荷の高い作業を必要とし、これらのパイプラインを開発、管理、監視し、信頼性高く実行するための特別なツールが必要となります。通常これらのツールは、実際のデータや機械学習タスクとは分離しています。インテグレーションの欠如は、企業における作業リソースを分断し、ユーザーは数多くのコンテキストスイッチを行う必要が出てきます。
本日のローンチによって、パイプラインのオーケストレーションは劇的にシンプルなものになります。複数ステップから構成されるジョブは、ノートブック、Pythonスクリプト、JARから構成される、モジュール化され依存関係のあるタスクを用いることで、データ・MLパイプラインの定義をシンプルなものにします。データエンジニアは、馴染みのあるDatabricksワークスペースの中で、データを変換・洗練し、機械学習アルゴリズムをトレーニングするマルチステップのジョブを容易に定義できるようになり、膨大な時間と労力を削減することができます。
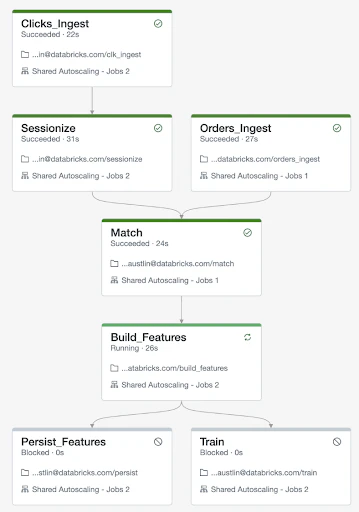
上の例では、ジョブはデータを取り込む2つのタスク:Clicks_IngestとOrders_Ingestから構成されています。この取り込まれたデータは、"Match"タスクで共に集計、フィルタリングされ、そこから機械学習用の特徴量を生成(Build_Features)し、永続化(Persist_Features)、新規モデルのトレーニングに使用(Train)されます。
複数タスクを伴うジョブオーケストレーションのパブリックプレビュー中にいただいた、数多くのお客様からのフィードバックに大変感謝しております。これらのインプットに基づき、我々はさらなる改善を加えました。デバッグワークフローの改善、常にジョブの概観を知らせる情報パネル、そして新たなオーケストレーション機能をサポートする、Jobs API(AWS|Azure|GCP)のバージョン2.1の提供です。
「ジョブオーケストレーションは素晴らしいものであり、ノートブックのオーケストレーションよりもはるかに優れています。今や我々のジョブは複数のタスクを持っており、思ったよりもこれらの実装が簡単であることがわかりました。Databricksなしにこのようなデータパイプラインを実装することは想像もできません。」 - Omar Doma、BatchServiceのデータエンジニアリングマネージャー
**ご自身のワークスペースでジョブオーケストレーションを有効化(AWS|Azure|GCP)して使い始めてみてください。**そうしない場合でも、向こう数ヶ月で自動的に有効化されます。
向こう数ヶ月間で、ジョブの複数のタスクで同じクラスターを再利用できる機能、全体の再実行を行わずに失敗したジョブを復旧する機能をサポートする予定です。また、既存のオーケストレーションツールとのインテグレーションを容易にする機能をローンチする予定です。
ワークスペースでの有効化手順