Jobs quickstart | Databricks on AWS [2022/3/1時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksクイックスタートガイドのコンテンツです。
本書ではサンプルデータセットを読み込み、処理を行うタスクをオーケストレートするDatabricksジョブをデモンストレーションします。このクイックスタートでは以下のことを行います。
- 年ごとに人気のある赤ちゃんの名前を含むサンプルデータセットを取得する新規ノートブックを作成し、コードを追加します。
- DBFSにサンプルデータセットをを保存します。
- DBFSからデータセットを読み込み、年でフィルタリングを行い結果を表示するための新規ノートブックを作成し、コードを追加します。
- 新規にジョブを作成し、ノートブックを用いる2つのタスクを設定します。
- ジョブを実行して結果を参照します。
要件
ジョブクラスターを作成するためのクラスター作成権限、あるいはall-purposeクラスターに対する権限が必要です。
ノートブックの作成
データの収集及び保存
サンプルデータセットを収集し、DBFSに保存するノートブックを作成します。
-
Databricksのランディングページに移動し、Create Blank Notebookを選択するか、サイドバーの
 Createをクリックし、メニューからNotebookを選択します。Create Notebookダイアログが表示されます。
Createをクリックし、メニューからNotebookを選択します。Create Notebookダイアログが表示されます。 -
Create Notebookダイアログでは、ノートブックの名前、例えばRetrieve baby namesを指定します。Default LanguageドロップダウンメニューからPythonを選択します。Clusterはデフォルトのままで構いません。このノートブックを使用するタスクを作成する際にクラスターを設定します。
-
Createをクリックします。
-
以下のPythonコードをノートブックの最初のセルに貼り付けます。
Pythonimport requests response = requests.get('http://health.data.ny.gov/api/views/myeu- hzra/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("dbfs:/FileStore/babynames.csv", csvfile, True)
データの読み込み及びフィルタリングしたデータの表示
データを読み取りフィルタリングしたデータを表示するノートブックを作成します。
-
Databricksのランディングページに移動し、Create Blank Notebookを選択するか、サイドバーの
Createをクリックし、メニューからNotebookを選択します。Create Notebookダイアログが表示されます。 -
Create Notebookダイアログでは、ノートブックの名前、例えばFilter baby namesを指定します。Default LanguageドロップダウンメニューからPythonを選択します。Clusterはデフォルトのままで構いません。このノートブックを使用するタスクを作成する際にクラスターを設定します。
-
Createをクリックします。
-
以下のPythonコードをノートブックの最初のセルに貼り付けます。
Pythonbabynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("dbfs:/FileStore/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").rdd.map(lambda row : row[0]).collect() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
ジョブの作成
-
サイドバーの
 Jobsをクリックします。
Jobsをクリックします。 -
 をクリックします。
をクリックします。タスク作成ダイアログとTasksタブが表示されます。
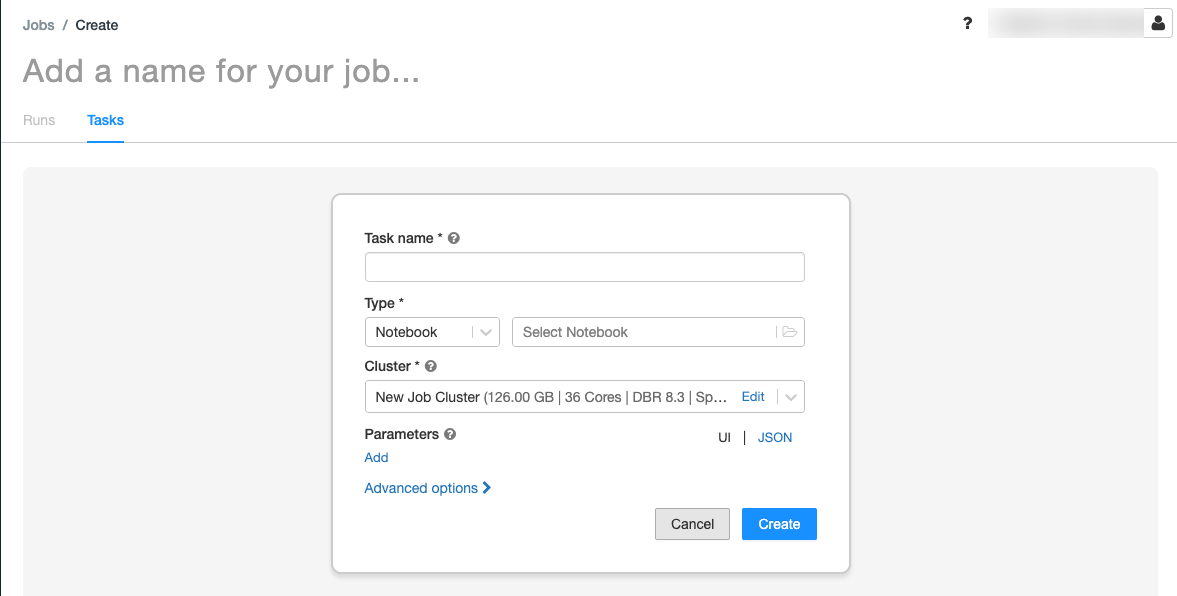
-
Add a name for your job… にジョブの名前を入力します。
-
Task nameフィールドにタスクの名前、例えばretrieve-baby-namesを入力します。
-
TypeドロップダウンでNotebookを選択します。
-
最初に作成したノートブックを選択するためにファイルブラウザを使用します。ノートブック名を選択し、Confirmをクリックします。
-
Create taskをクリックします。
-
別のタスクを追加するために、作成したタスクの下にある
 をクリックします。
をクリックします。 -
Task nameフィールドにタスクの名前、例えばfilter-baby-namesを入力します。
-
TypeドロップダウンでNotebookを選択します。
-
二番目に作成したノートブックを選択するためにファイルブラウザを使用します。ノートブック名を選択し、Confirmをクリックします。
-
Parametersの下のAddをクリックします。Keyフィールドには
year、Valueフィールドには2014を入力します。 -
Create taskをクリックします。
ジョブの実行
ジョブを即時実行するには、右上の をクリックします。Runsタブをクリックし、Active RunsテーブルのRun Nowをクリックすることでも実行することができます。
をクリックします。Runsタブをクリックし、Active RunsテーブルのRun Nowをクリックすることでも実行することができます。
ジョブ実行詳細の参照
- Runsタブをクリックし、Active RunsテーブルかCompleted Runs (past 60 days) テーブルのジョブ実行のリンクをクリックします。
- 出力と詳細を見るためにいずれかのタスクをクリックします。例えば、フィルタリングタスクのステータスとアウトプットを参照するために、filter-baby-namesタスクをクリックします。

別のパラメーターを指定して実行
別の年の赤ちゃんの名前をフィルタリングしてジョブを再実行します。
-
Run Nowの隣の
 をクリックし、Run Now with Different Parametersを選択するか、Active RunsテーブルのRun Now with Different Parametersをクリックします。
をクリックし、Run Now with Different Parametersを選択するか、Active RunsテーブルのRun Now with Different Parametersをクリックします。 -
Valueフィールドに
2015と入力します。 - Runをクリックします。