Databricks Apps for Admins: Architecture and Access Controlの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
これは、プラットフォーム管理者としてのDatabricks Appsの管理に関する複数記事ブログシリーズの最初の導入です。このシリーズでは、アーキテクチャやアクセス制御からコスト管理、ネットワーク管理、モニタリング、運用のベストプラクティうに至る全てをカバーします。この最初のパートでは、あなたが組織にアプリをロールアウトする前に理解すべき実行モデルと権限、認証フレームワークにフォーカスします。 リソース設定、コストのガバナンス、セキュリティなどの詳細に踏み込む今後のパートにも期待してください。
- Peyman Nasirifard, Senior Solutions Architect, Databricks
イントロダクション
Databricks Appsによって、チームはDatabricksワークスペース内に直接フルスタックのWebアプリケーション(ダッシュボード、内部ツール、AIを活用したインタフェース)を構築、デプロイすることができます。開発者にとってはエキサイティングなことです。プラットフォーム管理者は即座に疑問を持ちます: 誰がこれらをデプロイするのか?アプリは何にアクセスできるのか?どれだけコストがかかるのか?セキュアに保つにはどうすれば?
この記事と以降のシリーズでは、これらの質問に回答します。あなたが初めてアプリをロールアウトしようとしていても、既存のデプロイメントのガバナンスを強化しようとしているにしても、我々はあなたが必要とするアーキテクチャ、アクセス制御、コスト管理、ネットワーク管理、運用のプラクティスをウォークスルーします。
Databricks Appsの動作原理(管理者視点)
ガバナンスに踏み込む前に、実行モデルの理解が役立ちます。
アプリはDatabricksサーバレスコンピュートで実行されるので、設定、管理するクラスターは不要です。ソースコードをデプロイすると、Databricksは依存関係を構築し、アプリはdatabricksapps.comドメインのユニークなURLを取得します。サポートされるフレームワークには、Streamlit、Dash、Gradio、Flask、Reactが含まれます。
ソースコードはワークスペースフォルダや(GitHub、GitLab、Bitbucketなどの)Gitリポジトリに格納されます。現時点では、それぞれのデプロイメントはスナップショットを取得します。自動同期は今後サポートされる予定です。
課金の観点では、以下の4つの状態を持ちます:
| 状態 | アクセス可能? | 課金対象? |
|---|---|---|
| Running | Yes | Yes |
| Stopped | No | No |
| Deploying | No | No |
| Crashed | No | No |
重要なポイント: アプリがRunningの状態の時のみ課金されます。アイドル状態のアプリを停止することが、重要なコスト制御のレバーとなります。
アクセス制御: 誰が何をできるのか
Databricks Appsは、ワークスペースレベルに置いて直感的な2レベルの権限モデルを採用しています:
| 権限 | 許可する操作 |
|---|---|
| CAN MANAGE | 編集、削除、設定、権限の付与/剥奪 |
| CAN USE | アプリケーションの実行、操作のみ |
権限は、ユーザー、グループ、サービスプリンシパルに割り当て可能です。広範な内部アクセスのためにすべてのアカウントユーザーにCAN USEを許可することも可能です。外部、匿名アクセスは存在しません。すべてのユーザーは自身のワークスペースのSSOを通じた認証が必要です。
2つの認証モデル
これは、管理者が理解すべきもっと重要なアーキテクチャ上のコンセプトです。Appsでは、独立あるいは組み合わせて(推奨)利用できる2つの認証モードをサポートしています:
アプリの認証(Machine-to-Machine)
すべてのアプリは作成時に専用のサービスプリンシパルを自動で取得します。Databricksは、アプリの実行環境にDATABRICKS_CLIENT_IDとDATABRICKS_CLIENT_SECRETを注入します。サービスプリンシパルの権限は、アプリが自身で何をできるのかを決定します: バックグラインドジョブ、ログの書き込み、共有リソースへのアクセス。すべてのユーザーは、同じサービスプリンシパルの権限を共有します。このモードではユーザーごとの違いはありません。
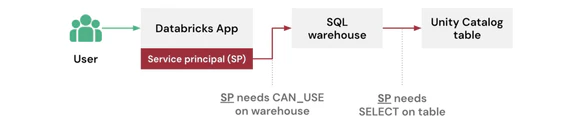
ユーザー認証(User-to-Machine)
アプリは呼び出しを行なったユーザーのIDを用いて動作します。行レベルフィルター、列マスク、テーブルのアクセスコントロールリスト(ACL)を含むUnity Catalogのポリシーが自動で強制されます。ユーザートークンはx-forwarded-access-token HTTPヘッダーを通じて到着します。
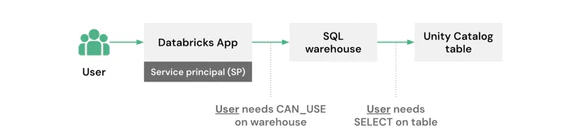
アプリは、以下のようにAPIアクセスを制限するために認証スコープを宣言する必要があります:
-
sql: SQLウェアハウスのクエリー -
dashboards.genie: Genieスペースの管理 -
files.files: ファイル/ディレクトリ管理
スコープを選択しない場合、Databricksはアプリが基本的なユーザーID情報を取得できるようにするデフォルトセットを割り当てます:
iam.access-control:readiam.current-user:read
これらのデフォルトは、ユーザー認証機能をサポートするために必要ですが、これらはデータやコンピュート資源へのアクセスを許可しません。アプリを作成、編集する際にスコープを追加してください。
Databricksは許可されたスコープ外のアクセスをブロックし、権限のエスカレーションをガードします。これは、重要なセキュリティ境界となります。
組み合わせモード
プロダクションのアプリでの推奨パターンとなります: (ロギングや設定など)共有のオペレーションではアプリの認証を使用し、ユーザーごとのデータアクセスではユーザー認証を使いましょう。これによって、共有オペレーションがスムーズに動作しつつも、ユーザーレベルの監査可能性を得ることができます。こちらが処理詳細なガイドラインです:
以下のような共有オペレーションではアプリ認証を使いましょう:
- 共有テーブル、ボリュームへのログやメトリクスの書き込み。
- 共有設定、機能フラグの管理。
- アプリレベルの認証情報を用いた外部サービスの呼び出し。
- 単一ユーザーに紐づかないバックグラウンドジョブやメンテナンスタスク。
メリット:
- 安定性と信頼性: 特定のユーザーがアクセス権を失ったり退職した場合にもバックグラウンドタスクが破損しません。
- シンプルな権限: サービスプリンシパルに共有リソースに対する最低限の権限を与えるのみです。
- ユーザーごとの割り当てを必要としないノイズの多いオペレーションの監査ログのトラフィックを削減します。
以下のようなユーザーごとのデータアクセスではユーザー認証を使いましょう:
- ユーザーごとにアクセス権が異なるUnity Catalogのテーブル/ボリュームへのクエリー。
- ユーザーの資格情報に依存した結果となるSQLウェアハウス、クラスター、モデルエンドポイント、Genieスペースの使用。
- ガバナンスにおいて「誰がどのデータに何をしたのか」が問題となるすべてのUIアクション。
メリット:
- 真のユーザーごとのガバナンス: (行フィルター、列マスク、ACLなどの)UCポリシーが自動で適用されます。
- 最小権限: スコープとUCの権限によって、設定が間違った場合でもアプリが過度の操作をすることを防ぎます。
- ユーザーレベルの監査可能性: 監査ログと下流のテレメトリをアプリのSPではなくエンドユーザーのアクションに紐づけることができます。
管理者へのおすすめ
アプリ権限に関するいくつかの推奨事項です:
- CAN MANAGEはシニアな開発者、アプリオーナーのみに許可しましょう。
- CAN USEはエンドユーザーと利用者に付与しましょう。
- データアクセスに関しては、Unity Catalogのガバナンスが適用されるユーザー認証が常に好ましいものとなります。
- 最低限の必要な認証スコープをリクエストしましょう。例えば、アプリがファイル読み込みのみなら、
sqlは付与しないでください。
カバーした内容
最初の導入では、Databricks Appsの背後の実行モデルと、権限、それらを管理する認証フレームワークを探索しました。重要なポイントは:
- アプリはサーバレスコンピュートで動作するので、アプリがRunningの状態の時のみに課金が発生します。
- 2レベルの権限モデル(CAN MANAGEとCAN USE)が、誰がデプロイでき、誰が利用できるのかを制御します。
- 2つの認証モードは、セキュアで監査可能なアプリのガバナンスの基礎となります。共有オペレーションではアプリ認証、ユーザーごとのデータアクセスではユーザー認証を使用しましょう。両方のモードを組み合わせることで、ユーザーレベルではUnity Catalogのポリシーを強制しつつも、背後のオペレーションを安定したものにします。
この基礎を身につけることで、大規模にアプリを実行する実践的な側面に進む準備ができたことになります。
次は
次の記事(Part 2)では、アーキテクチャからオペレーションにシフトします。アプリがワークスペースのリソース(SQLウェアハウス、モデルサービングエンドポイント、シークレットなど)を宣言し、接続する方法、セキュアな設定のためのapp.yamlの構成方法、billingシステムテーブルとSQLアラートを用いて、コストを追跡、コントロール、統治する方法をカバーします。お楽しみに。
そして、Part 3ではネットワークとセキュリティ(イングレス制御、イグレスポリシー、プライベートリンク)、モニタリングと可観測性、日々の管理のためのコマンド、注意すべきプラットフォームの制限、すべてをまとめるための管理者の完全なロールアウトチェックリストに取り組みます。