試したことがなかったので接続してみます。
Databricksのレイクハウスフェデレーションを使用すると、Google BigQueryに格納されたデータを移動させることなく、Databricks環境から直接クエリすることができます。Unity Catalogの統一されたガバナンス機能により、BigQueryデータへのアクセス管理も簡単に行えます。本記事では、BigQueryとの接続設定からフォーリンカタログの作成まで、具体的な手順を解説します。Databricks Runtime 16.1以降では、ジョイン処理のプッシュダウンもサポートされ、より効率的なクエリ実行が可能になりました。
機能概要
レイクハウスフェデレーションは、Databricks外部のデータソースに対して、データを移動させることなく直接クエリを実行できる機能です。BigQueryとの連携では、以下の仕組みで動作します。
┌─────────────────────────┐ ┌─────────────────────────┐
│ Databricks │ │ Google BigQuery │
├─────────────────────────┤ ├─────────────────────────┤
│ Unity Catalog │ │ BigQuery Project │
│ ┌─────────────────┐ │ │ ┌─────────────────┐ │
│ │ Foreign Catalog │◄──┼──────────┼──►│ Datasets │ │
│ └─────────────────┘ │ │ └─────────────────┘ │
│ ┌─────────────────┐ │ │ ┌─────────────────┐ │
│ │ Connection │◄──┼──────────┼──►│ Service Account │ │
│ └─────────────────┘ │ │ └─────────────────┘ │
└─────────────────────────┘ └─────────────────────────┘
│ ▲
│ SQLクエリ │
└────────────────────────────────────────┘
クエリ結果
主な特徴として以下があります。
- データの移動不要: BigQueryのデータをDatabricksにコピーすることなく、直接クエリを実行
- 統一されたガバナンス: Unity Catalogを通じて、BigQueryデータへのアクセス権限を一元管理
- クエリプッシュダウン: フィルタ、集計、ジョインなどの処理をBigQuery側で実行し、パフォーマンスを最適化
メリット、嬉しさ
1. データサイロの解消
異なるクラウドプラットフォームに分散したデータを、Databricks環境から統一的にアクセスできます。データ移行の手間とコストを削減し、リアルタイムで最新のデータを分析できます。
2. 運用コストの削減
- データ複製が不要なため、ストレージコストを削減
- ETLパイプラインの構築・メンテナンスが不要
- データ同期の遅延や不整合の心配がない
3. セキュリティとガバナンスの強化
Unity Catalogの機能により:
- 行レベル、列レベルのアクセス制御が可能
- データリネージの追跡
- 監査ログの一元管理
4. パフォーマンスの最適化
| 処理タイプ | サポート状況 | 詳細・備考 |
|---|---|---|
| フィルタ (WHERE句) | ✓ サポート | 条件フィルタをBigQuery側で実行し、転送データ量を削減 |
| プロジェクション (SELECT句) | ✓ サポート | 必要な列のみを取得し、ネットワーク転送を最適化 |
| 集計 (GROUP BY) | ✓ サポート | SUM、COUNT、AVGなどの集計をBigQuery側で実行 |
| 上限 (LIMIT) | ✓ サポート | 結果セットのサイズを制限 |
| ソート (ORDER BY) | △ 制限付き | LIMITと組み合わせた場合のみサポート |
| 結合 (JOIN) | ✓ サポート | Databricks Runtime 16.1以降で利用可能 |
| 関数 | △ 部分的 | フィルタ式内の文字列、数学、日付関数などをサポート |
| ウィンドウ関数 | ✗ 未サポート | ROW_NUMBER()、RANK()などはDatabricks側で処理 |
使い方の流れ
前提条件の確認
まず、以下の要件を満たしていることを確認します。
ワークスペース要件:
- Unity Catalogが有効化されたワークスペース
コンピュート要件:
- Databricks Runtime 16.1以降
- 標準または専用アクセスモード
- SQLウェアハウスはProまたはServerless
権限要件:
- 接続作成:
CREATE CONNECTION権限 - カタログ作成:
CREATE CATALOG権限
ステップ0: BigQueryの設定
以下のようなBigQueryのテーブルにアクセスします。まず、サービスアカウント(AWSにおけるIAMロール)を作成します。
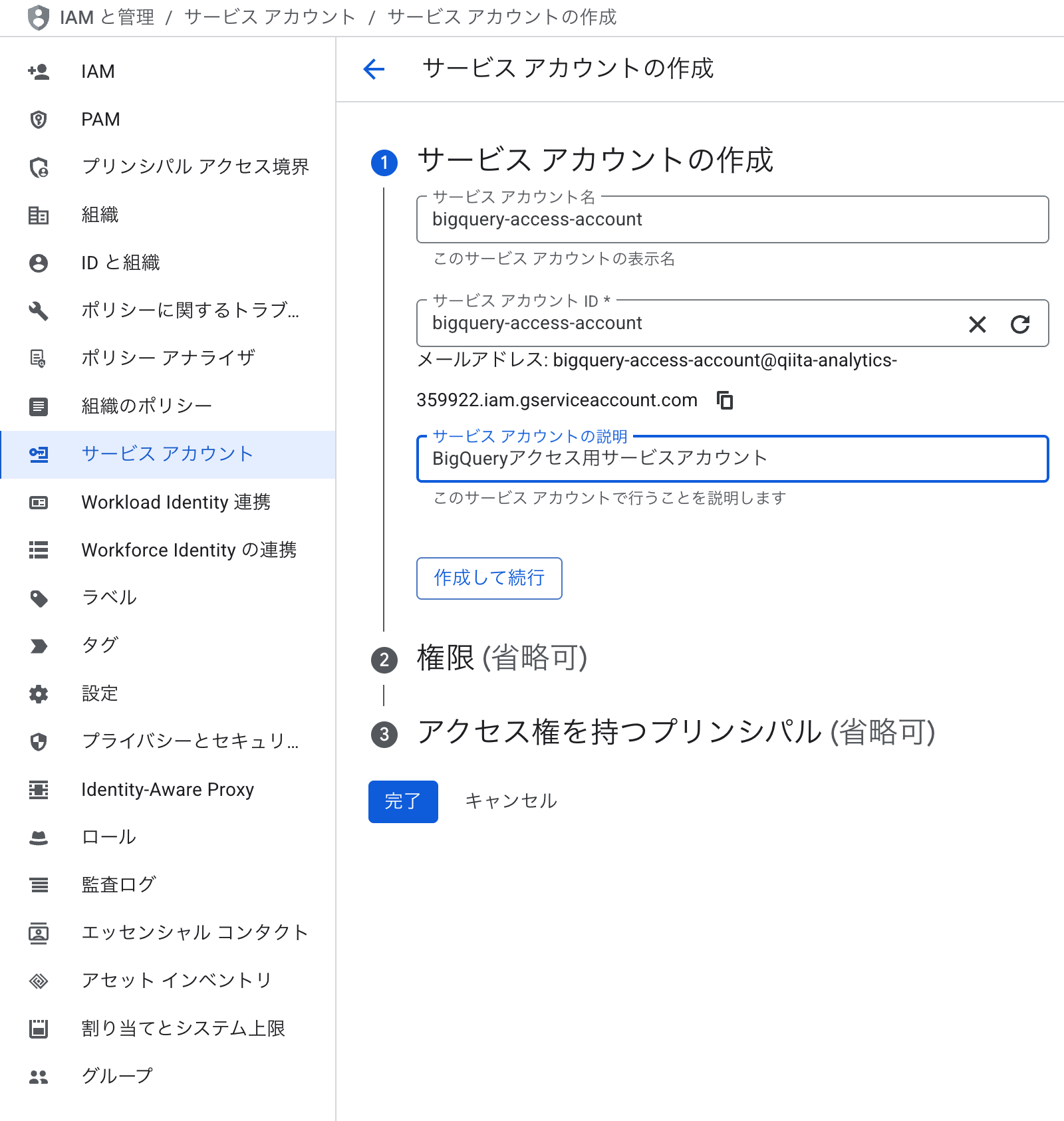
JSON鍵を作成します。
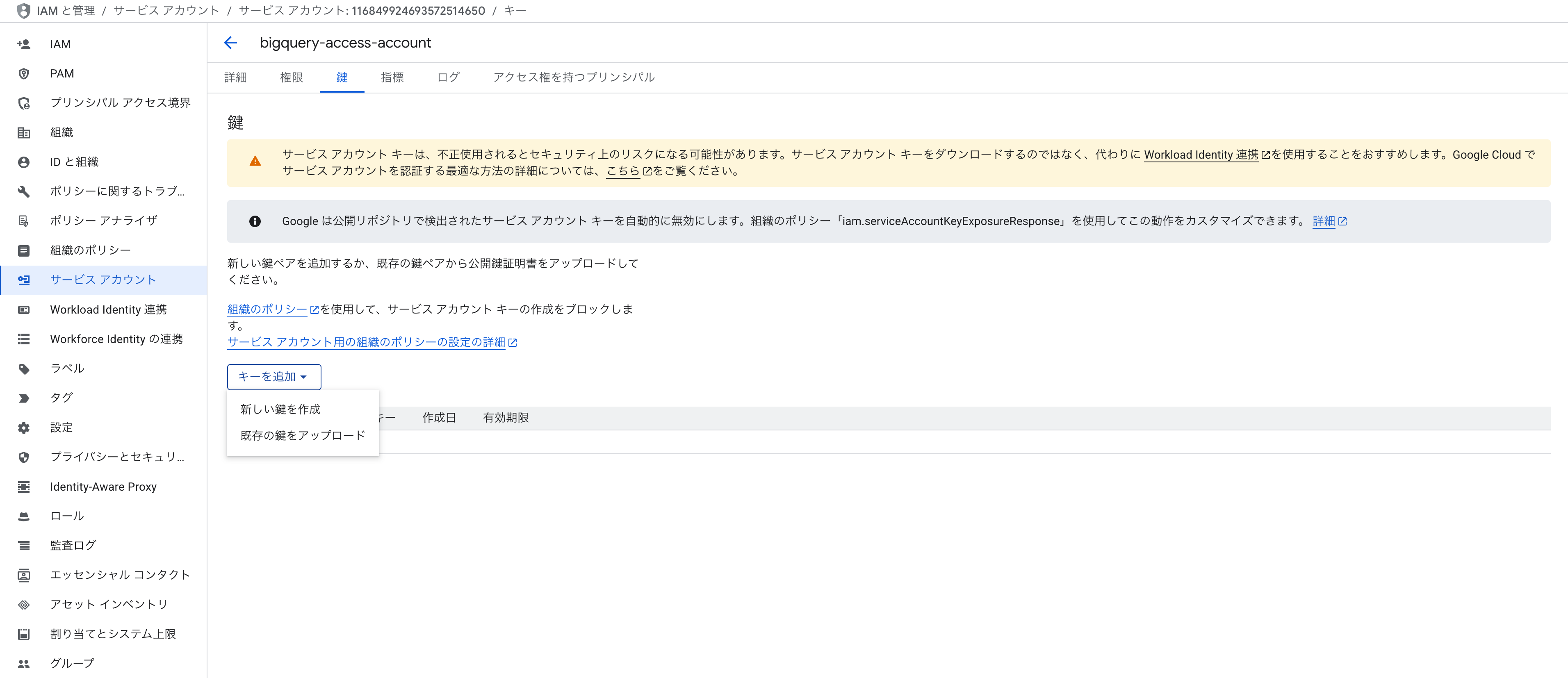

ローカルに以下のようなJSONがダウンロードされます。
{
"type": "service_account",
"project_id": "xxxxx",
"private_key_id": "793ac5e62d6b228b849ab2406d4d6f11b0730ec6",
"private_key": "-----BEGIN PRIVATE KEY-----
:
:
\n-----END PRIVATE KEY-----\n",
"client_email": "bigquery-access-account@qxxxx.iam.gserviceaccount.com",
"client_id": "116849924693572514650",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/bigquery-access-account%40qiita-analytics-359922.iam.gserviceaccount.com",
"universe_domain": "googleapis.com"
}
データセットにサービスアカウントの閲覧権限を追加しておきます。

ステップ1: 接続の作成
- Databricksワークスペースで「カタログ」をクリック
- 「追加」アイコンから「接続の追加」を選択

- 接続名を入力し、接続タイプで「Google BigQuery」を選択

- Google サービスアカウントキーのJSONを入力: ここでダウンロードしたJSONの中身を貼り付けます。
- (オプション) 請求用プロジェクトIDを指定
- 「接続の作成」をクリック
ステップ2: フォーリンカタログの作成
UIで接続を作成した場合は自動的に作成されます。
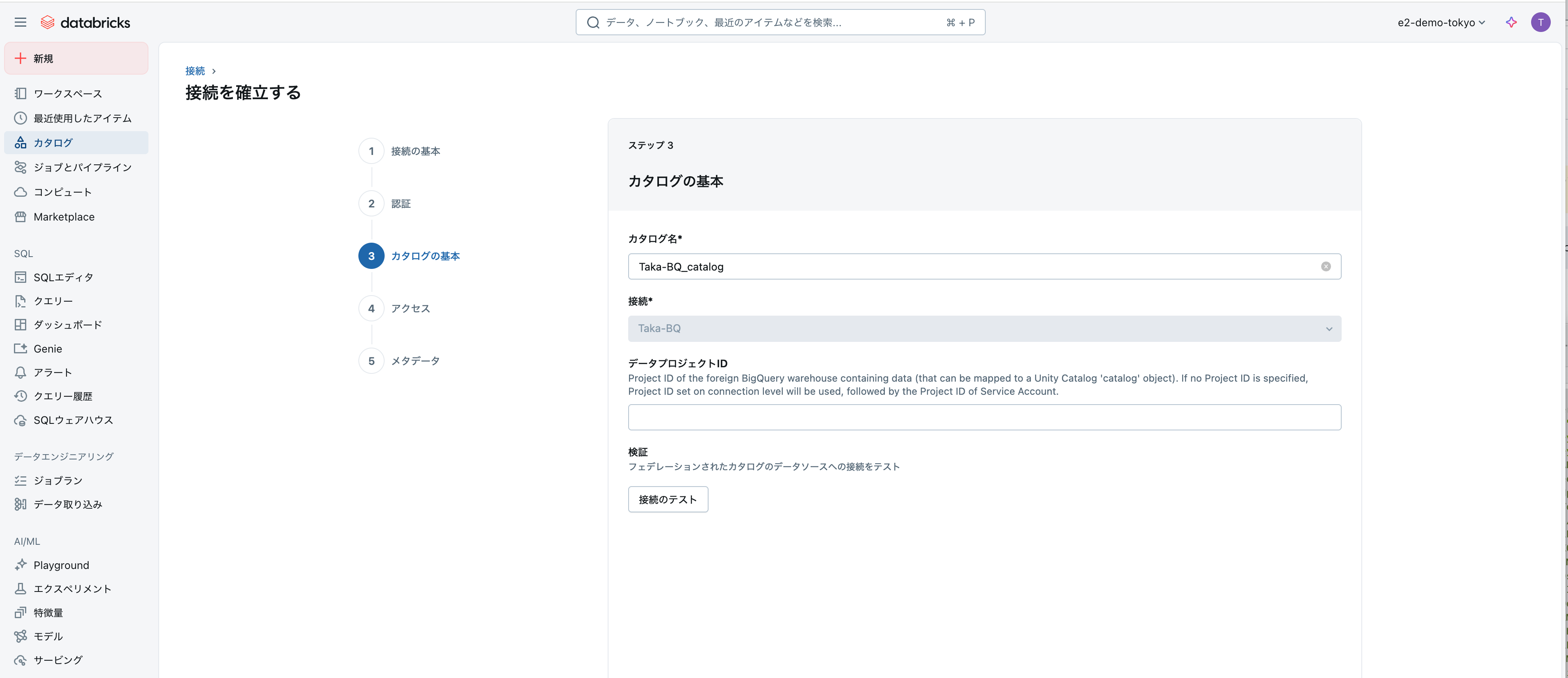
ここで接続テストもできます。


必要に応じてフォーリンカタログの権限、タグを設定します。

ステップ3: データへのアクセス
作成したカタログを通じて、BigQueryのデータにアクセスできます。
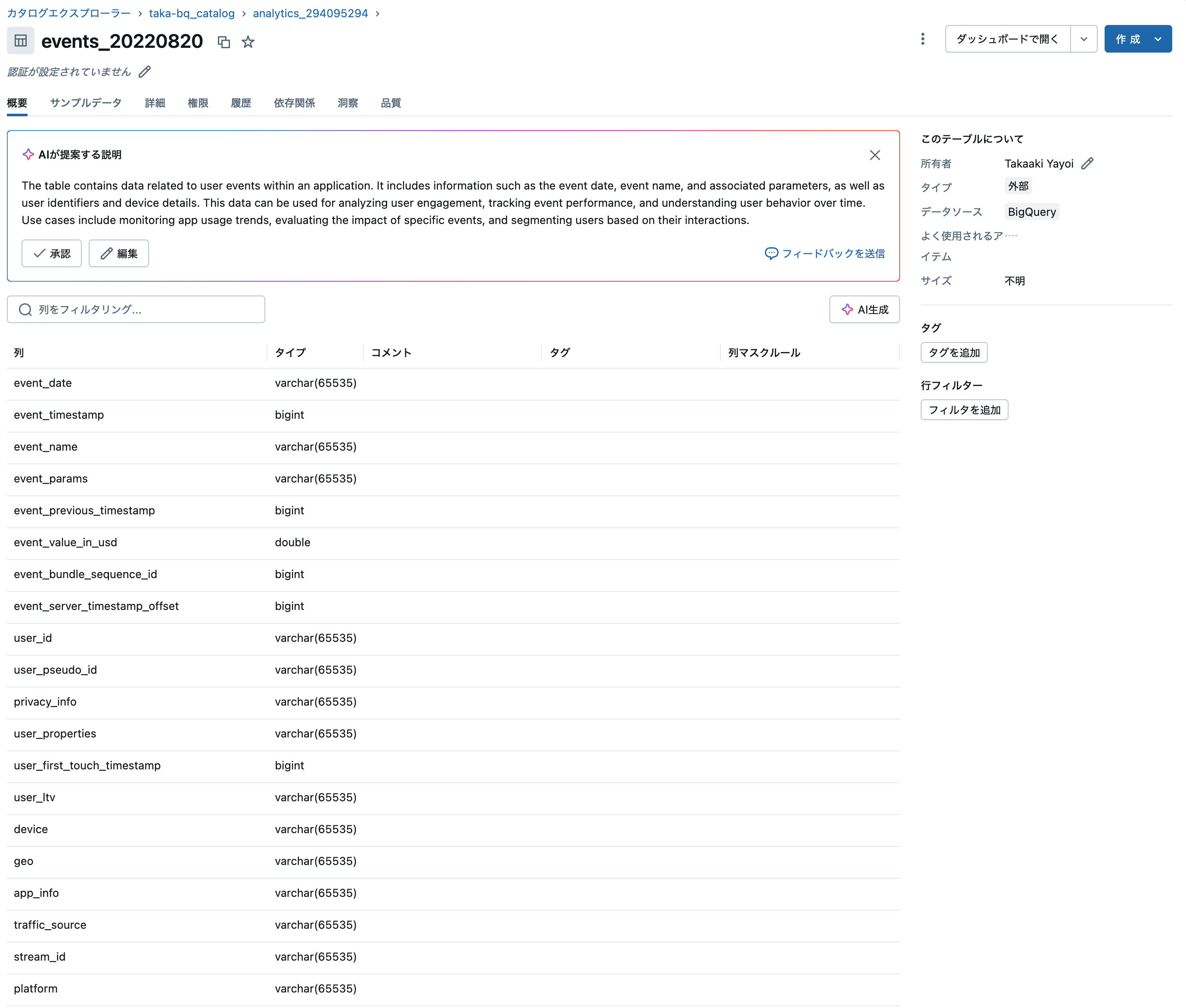

注意点
1. ネットワーク接続
- DatabricksクラスターからBigQueryへのネットワーク接続が必要
- ファイアウォールやVPCの設定を確認
2. 認証とセキュリティ
- サービスアカウントに適切な権限(BigQuery ユーザー、BigQuery データビューア)を付与
- シークレット管理を使用して認証情報を安全に保管
3. データ型の互換性
| BigQuery型 | Spark型 |
|---|---|
| BIGNUMERIC, NUMERIC | DecimalType |
| INT64 | LongType |
| FLOAT64 | DoubleType |
| ARRAY, GEOGRAPHY, INTERVAL, JSON, STRING, STRUCT | VarcharType |
| BYTES | BinaryType |
| BOOL | BooleanType |
| DATE | DateType |
| DATETIME, TIME, TIMESTAMP | TimestampType / TimestampNTZType* |
データ型変換に関する注意事項
- 複雑な型(ARRAY、STRUCT、JSON等)はVarcharTypeに変換されるため、構造が失われます
- TIMESTAMP型は、preferTimestampNTZ設定により動作が変わります(デフォルト: false)
- 精度の高い数値型を扱う場合は、DecimalTypeの精度設定に注意が必要です
4. パフォーマンスとコスト
- 大量のデータ転送はネットワークコストに影響
- BigQuery側の課金(クエリ実行量)に注意
- プッシュダウンを活用してデータ転送量を最小化
5. 制限事項
- ウィンドウ関数はプッシュダウンされない
- 一部の複雑なデータ型は文字列型に変換される
- リアルタイムストリーミングデータへのアクセスは非対応
まとめ
Databricksのレイクハウスフェデレーション機能を使用することで、BigQueryのデータを簡単かつ効率的に活用できます。データの移動が不要で、Unity Catalogによる統一的なガバナンスを実現できるため、マルチクラウド環境でのデータ分析基盤の構築に適しています。
設定は接続とフォーリンカタログの作成という2ステップで完了し、その後は通常のテーブルと同じようにクエリを実行できます。プッシュダウン機能により、パフォーマンスも最適化されています。
ただし、ネットワーク設定やデータ型の互換性、コスト面での考慮事項もあるため、本番環境での利用前には十分な検証を行うことをお勧めします。