sparklyr | Databricks on AWS [2021/9/14時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricksではノートブック、ジョブ、RStudioデスクトップ上でのsparklyrの使用をサポートしています。
要件
Databricksでは、毎回のランタイムリリースに最新の安定バージョンのsparklyrを含めています。インストールされているsparklyrをインポートすることで、Databricks RノートブックやDatabricksでホスティングするRStudioサーバー内でsparklyrを使用することができます。
RStudioデスクトップでは、Databricks Connectを用いることでローカルマシンからsparklyr経由でDatabricksクラスターに接続し、Apache Sparkコードを実行することができます。sparklyrおよびRStudio Desktopをご覧ください。
sparklyrからDatabricksクラスターに接続する
sparklyrの接続を確立するには、spark_connect()における接続方法で"databricks"を使用します。spark_connect()の他のパラメーターを指定する必要はなく、DatabricksクラスターにはSparkがインストール済みなのでspark_install()を呼び出す必要もありません。
# create a sparklyr connection
sc <- spark_connect(method = "databricks")
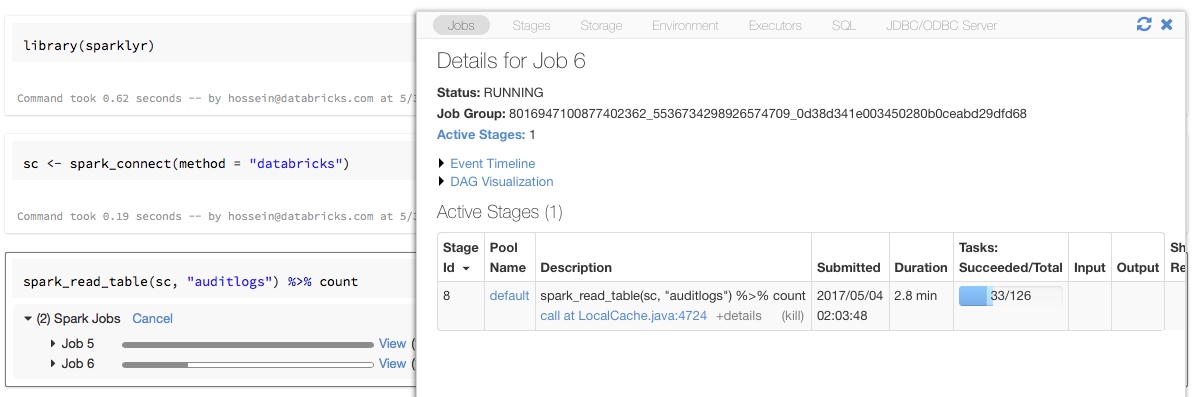
sparklyrにおけるプログレスバーとSpark UI
上の例のように変数scにsparklyrのコネクションオブジェクトを割り当てると、Sparkジョブを起動するそれぞれのコマンドの後にSparkのプログレスバーが表示されます。さらに、特定のSparkジョブに関連づけられるSpark UIを参照するためにプログレスバーの隣のリンクをクリックすることもできます。
sparklyrの使用
sparklyrをインストールして接続を確立した後は、通常と同様に他の全てのsparklyr APIが動作します。サンプルに関しては以下のノートブックを参照ください。
通常sparklyrはdplyrのような他のtidyverseパッケージとともに使用されます。すぐに利用できるようにこれらのパッケージの大部分はDatabricksにインストールされています。シンプルにこれらをインポートし、APIを使い始めることができます。
sparklyrとSparkRを同時に使用する
単一のノートブックやジョブでSparkRとsparklyrを使用することができます。SparkRとsparklyrをインポートし、それらの機能を活用することができます。Databricksノートブックでは、SparkRの接続は事前に設定されています。
SparkRのいくつかの関数は、dplyrの多くの関数をマスクします。
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
dplyrをインポートした後にSparkRをインポートした場合、dplyr::arrange()のように完全修飾名を用いることでdplyrの関数を参照することができます。同様に、SparkRの後にdplyrをインポートした場合には、dplyrによってSparkRの関数がマスクされます。
あるいは、不要な際には2つのパッケージのいずれかを選択的にデタッチすることができます。
detach("package:dplyr")
spark-submitジョブでsparklyrを使う
少々のコード変更で、spark-submitジョブとしてsparklyrを使用するスクリプトをDatabricks上で実行することができます。上述した手順のいくつかはDatabricks上のspark-submitジョブでsparklyrを使用する際には適用されません。特に、spark_connectにはSparkのマスターURLを指定しなくてはなりません。Create and run a spark-submit job for R scriptsをご覧ください。
未サポートの機能
Databricksではローカルのブラウザを必要とするspark_web()やspark_log()のようなsparklyrのメソッドはサポートしていません。しかし、Spark UIはDatabricksにビルトインされているので、簡単にSparkジョブを調査することができます。クラスターのドライバーノード、ワーカーノードのログをご覧ください。
訳者注
2022/7/13時点では、sparklyrで得られるデータフレームに対してdisplay関数が適切に動作しません。
sparklyrノートブック