How to Manage End-to-end Deep Learning Pipelines w/ Databricks - The Databricks Blogの翻訳です。
ディープラーニング(DL)モデルは全ての業界のユースケースで適用されています。金融サービスにおける不正検知、メディアにおけるパーソナライゼーション、ヘルスケアにおける画像認識など。適用の拡大によって、今ではDLテクノロジーの活用は数年前と比べて非常に簡単になっています。TensorflowやPytorchのような人気のあるDLフレームワークは、優れた性能、精度を実現できるまで成熟しました。マネージドMLflowを提供するDatabricksレイクハウスプラットフォームのような機械学習(ML)環境でHorovod、Pandas UDF(ユーザー定義関数)を活用することで、容易にDLを分散実行することができます。
課題
現在直面している主要な課題の一つは、どのようにDL機械学習パイプラインをコントロール、再現可能な状態にして、自動化、本格運用に持っていくかというものです。Kubeflowのようなテクノロジーがソリューションを提供していますが、これらは多く場合、ある一定量の専門知識を必要とし、利用できるマネージドサービスが少ないため、取り扱いが煩雑です。このことは、エンジニアは自身でこれらの複雑な環境を管理しなくてはならないことを意味します。データと分析プラットフォームに統合されたDLパイプラインの管理機構を持つ方が遥かにシンプルでしょう。
この記事では、現在パブリックプレビューのDatabricksジョブオーケストレーションを活用した、Databricks環境におけるDLパイプラインの管理がいかに簡単であるかを説明します。ジョブオーケストレーションによって、ディープラーニングのパイプラインを含む多段ステップのMLパイプラインの管理、構築、テスト、スケジュール実行が容易になります。ここで説明するコードの全てはGitHubのリポジトリから利用できます。どのようにアクセスするかについては、この記事の最後のセクションを参照ください。
リアルワールドのビジネスユースケースを見ていきましょう。CoolFundCoは、画像が何であるのかを識別し、コンテンツを分類するために毎日数万の画像を分析している(架空の)投資会社です。CoolFundCoはこの技術を様々な方法で活用しています。例えば、短期の経済トレンドを決定するために国中のショッピングモールの写真を分析するなどです。この会社は結果を投資を行うためのデータポイントの一つとして活用します。CoolFundCoのデータサイエンティストとMLエンジニアは、このプロセスを管理するために多大な時間と労力を費やしています。CoolFundCoは、大量の既存画像を保有しており、日々新たな画像が彼らのクラウドオブジェクトストレージに送られてきます。このケースでは、Microsoft Azure Data Lake Storage (ADLS)を想定していますが、AWS S3やGoogle Cloud Storage (GCS)のケースも想定できます。
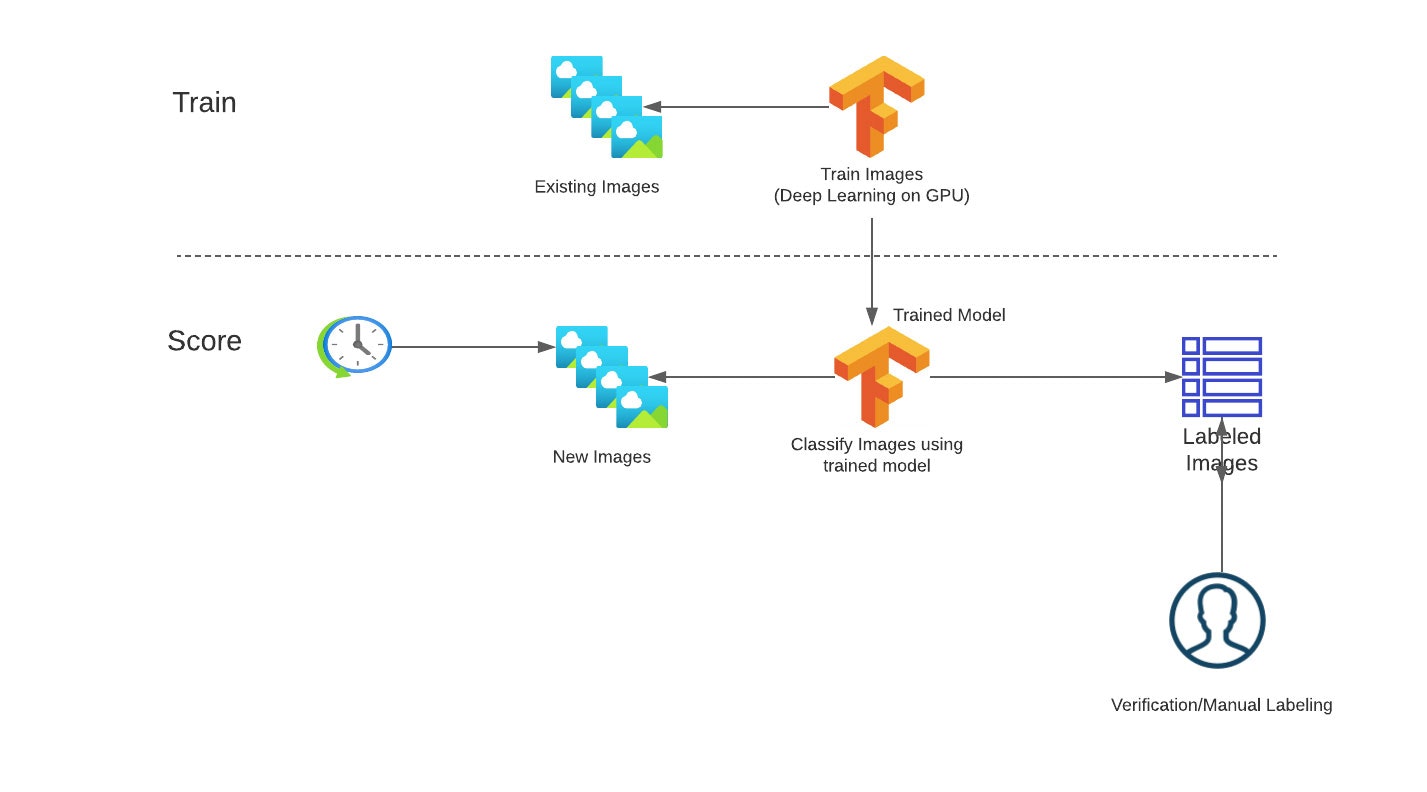
図1: 典型的な画像分類ワークフロー
現状、このプロセスの管理は悪夢です。毎日、エンジニアが画像をコピーし、画像カテゴリーを予測するためにディープラーニングモデルを実行し、そして、モデルのアウトプットをCSVファイルで保存して結果を共有します。画像認識の品質が維持されるように、DLモデルは定期的に検証され、再トレーニングされる必要がありますが、現状はチームのメンバーによって開発環境で実行される手動のプロセスとなっています。パイプラインの実行は外部ツールによって起動され、彼らはエンドツーエンドのフローを管理するために異なる環境を管理しなくてはなりません。
ソリューション
混沌に秩序をもたらすために、CoolFundCoはプロセスを自動化するためにDatabricksを導入しました。まず初めに、彼らはプロセスをトレーニングとスコアリングのワークフローに分離しました。
トレーニングワークフローにおいては、以下のことが必要となります。
- ラベリングされた画像をクラウドストレージから集中管理されるレイクハウスに投入
- 機械学習モデルをトレーニングするためにラベリングされた画像を使用
- 集中管理リポジトリに新規にトレーニングされたモデルを登録
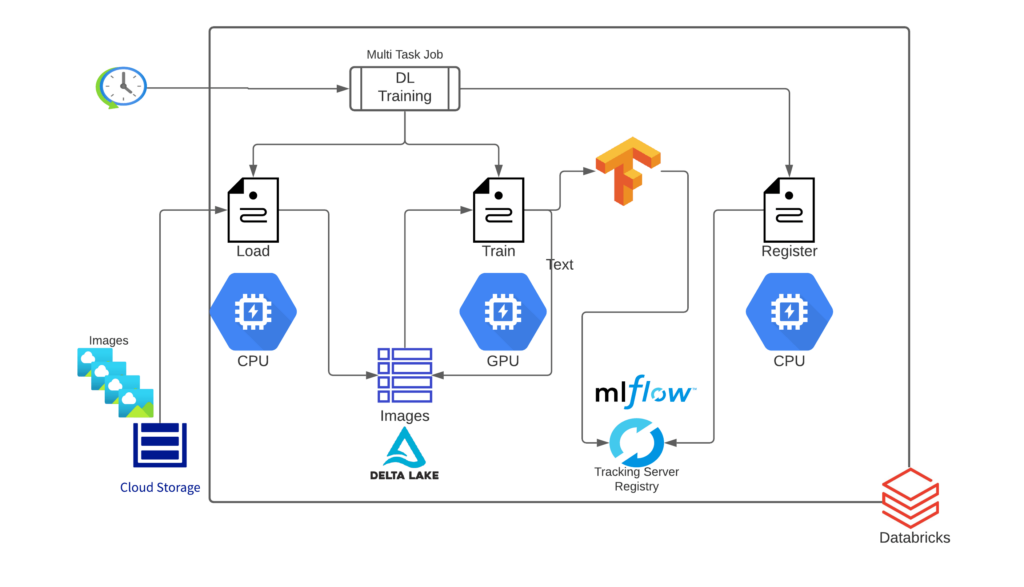
図2: DLトレーニングパイプラインにおけるエンドツーエンドのアーキテクチャ
それぞれのワークフローは期待される結果を得るための一連のタスクから構成されます。それぞれのタスクは異なるツールや機能を活用するため、それぞれが異なるリソース設定(クラスターのサイズ、インスタンスタイプ、CPUかGPUか、等)を必要とします。彼らは、それぞれのタスクを別々のノートブックとして実装することにしました。詳細なアーキテクチャを図2に示します。
スコアリングワークフローは、以下のステップから構成されます。
- 新たな画像をクラウドストレージから集中管理されるレイクハウスに投入
- リポジトリの最新モデルを用いて、それぞれの画像のスコアリングを高速に実行
- 集中管理されるレイクハウスにスコアリング結果を格納
- 精度を検証するために、画像のサブセットを手動のラベリングサービスに送信
DLトレーニングパイプライン
トレーニングパイプラインのそれぞれのタスクを見ていきましょう。
1. 新たな画像をクラウドストレージから集中管理されるレイクハウスに投入 [適切なインフラストラクチャ:大規模CPUクラスター]
このプロセスの最初のステップは、モデルトレーニングで使用できるフォーマットで画像データをロードすることです。彼らは、クラウドストレージに到着する新規データファイルをインクリメンタルかつ効率的に処理するDatabricksのオートローダーを使ってトレーニングデータ(新規画像)をロードします。オートローダーはデータ管理をサポートし、継続的に到着する新規画像を自動でハンドリングします。 CoolFundCoのチームは、オートローダーのtrigger onceを活用することで、オートローダーのストリーミングジョブの起動、前回のトレーニングジョブ実行以降の新規画像の検知を行い、新規ファイルのみをロードした後にストリームを停止するようにしました。そして、Apache Spark™のバイナリーファイルリーダを用いて全ての画像をロードし、それぞれの画像ファイルを生のコンテンツとファイルのメタデータを含むデータフレームの1レコードに変換しました。データフレームには以下のカラムが含まれます。
- path (StringType): ファイルパス
- modificationTime (TimestampType): ファイルの更新時刻。いくつかのHadoopファイルシステムの実装では、このパラメータは利用できない場合があり、その場合にはデフォルト値が適用されます。
- length (LongType): ファイルのバイト長
- content (BinaryType): ファイルの中身
raw_image_df = spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "binaryFile") \
.option("recursiveFileLookup", "true") \
.option("pathGlobFilter", "*.jpg") \
.load(caltech_256_path)
image_df = raw_image_df.withColumn("label", substring(element_at(split(raw_image_df['path'], '/'), -2),1,3).cast(IntegerType())) \
.withColumn("load_date", current_date())
そして、残りのトレーニングパイプラインとスコアリングパイプラインでアクセスし、更新できるように、全てのデータをDelta Lakeテーブルに書き込みます。Delta Lakeはデータレイクに信頼性、スケーラビリティ、セキュリティ、パフォーマンスをもたらし、標準的なSQLクエリーを用いたデータウェアハウス同様のデータアクセスを可能とします。これが、このアーキテクチャをレイクハウスという理由にもなっています。Deltaテーブルは自動でバージョン管理を行うため、テーブルが更新される都度、新たなバージョンにどの画像が追加されたのかがわかるようになります。
2. 機械学習モデルをトレーニングするためにラベリングされた画像を使用 [適切なインフラストラクチャ:GPUクラスター]
このプロセスの二つ目のステップは、モデルをトレーニングするためにラベリングされているデータを用いることです。ここでは、ParquetファイルやSparkデータフレームから直接ディープラーニングモデルをトレーニングできるようにするオープンソースライブラリであるPetastromを使用します。Deltaテーブルの画像を直接Sparkデータフレームに読み込み、それぞれの画像を適切な形状に処理、フォーマットし、PetastormのSparkコンバーターを用いてモデルに対する特徴量を生成します。
converter_train = make_spark_converter(df_train)
converter_val = make_spark_converter(df_val)
def transform_row(pd_batch):
pd_batch['features'] = pd_batch['content'].map(lambda x: preprocess(x))
pd_batch = pd_batch.drop(labels='content', axis=1)
return pd_batch
transform_spec_fn = TransformSpec(
transform_row,
edit_fields=[('features', np.float32, IMG_SHAPE, False)],
selected_fields=['features', 'label']
)
with converter_train.make_tf_dataset(transform_spec=transform_spec_fn,
cur_shard=hvd.rank(), shard_count=hvd.size(),
batch_size=BATCH_SIZE) as train_reader, \
converter_val.make_tf_dataset(transform_spec=transform_spec_fn,
cur_shard=hvd.rank(), shard_count=hvd.size(),
batch_size=BATCH_SIZE) as test_reader:
# tf.keras only accept tuples, not namedtuples
train_dataset = train_reader.map(lambda x: (x.features, x.label))
steps_per_epoch = len(converter_train) // (BATCH_SIZE * hvd.size())
test_dataset = test_reader.map(lambda x: (x.features, x.label))
ディープラーニングのトレーニングをスケールさせるためには、単一の大規模GPUではなく、GPUクラスターを活用したいと考えます。Databricksでは、UberのHorovodフレームワークを用いてSparkクラスターで分散ディープラーニングを行うための一般的なAPIであるHorovodRunnerをインポートし、利用することで、GPUクラスターでの分散トレーニングを実現することができます。
MLflowを用いることで、ハイパーパラメーター、トレーニング時間、ロス、精度のメトリクス、モデルのアーティファクト自身を含むモデルトレーニングプロセス全体を、MLflowエクスペリメントとして記録することができます。MLflow APIには、Spark MLlib、Keras、Tensorflow、SKlearn、XGBoostを含む著名なMLライブラリに対するオートロギング機能があります。この機能は、モデル固有のメトリクス、パラメーター、モデルアーティファクトを自動で記録します。Databricksでは、Deltaのトレーニングデータソースを用いた際には、オートロギングはモデルトレーニングに使われたデータのバージョンを記録するので、オリジナルのデータセットに対するトレーニングを容易に再現できるようになります。
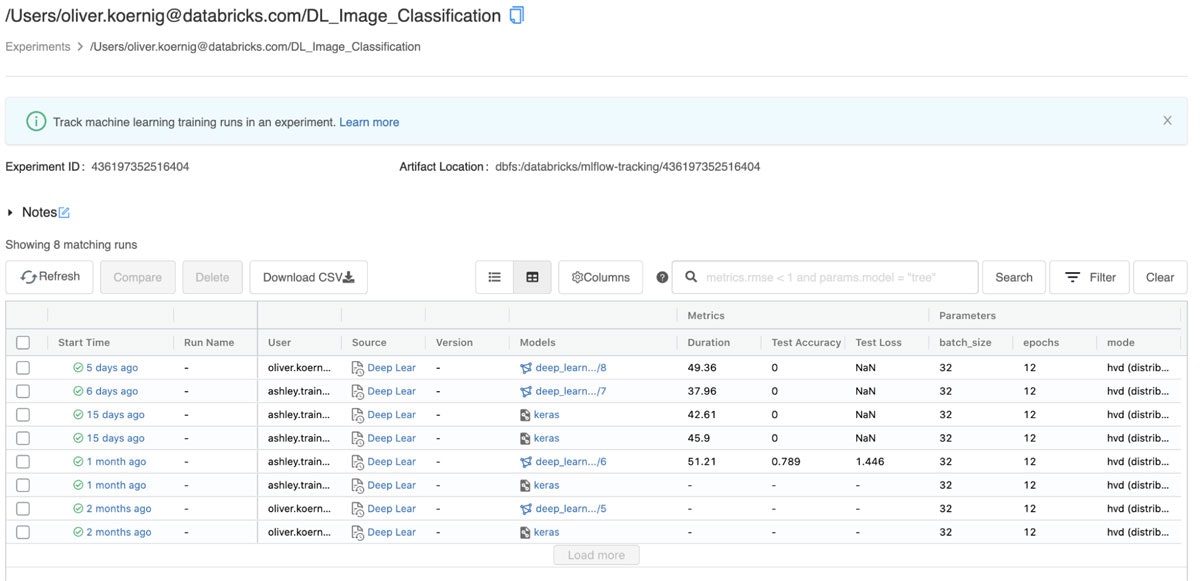
図3: DatabricksマネージドのMLflowエクスペリメントUI
3. 集中管理リポジトリに新規にトレーニングされたモデルを登録 [適切なインフラストラクチャ:シングルノードのCPUクラスター]
トレーニングパイプラインの最後のステップは、Databricksのモデルレジストリに新たにトレーニングしたモデルを登録することです。以前のトレーニングステップで記録されたアーティファクトを用いて、新バージョンの画像分類器を作成することができます。新バージョンのモデルはステージングからプロダクションに移行される際に、モデルのパフォーマンス、スケーラビリティなどを検証するための別のタスクを開発し実行することができます。DatabricksのモデルUIには、以下のようにモデルの最新ステータスが表示されます。
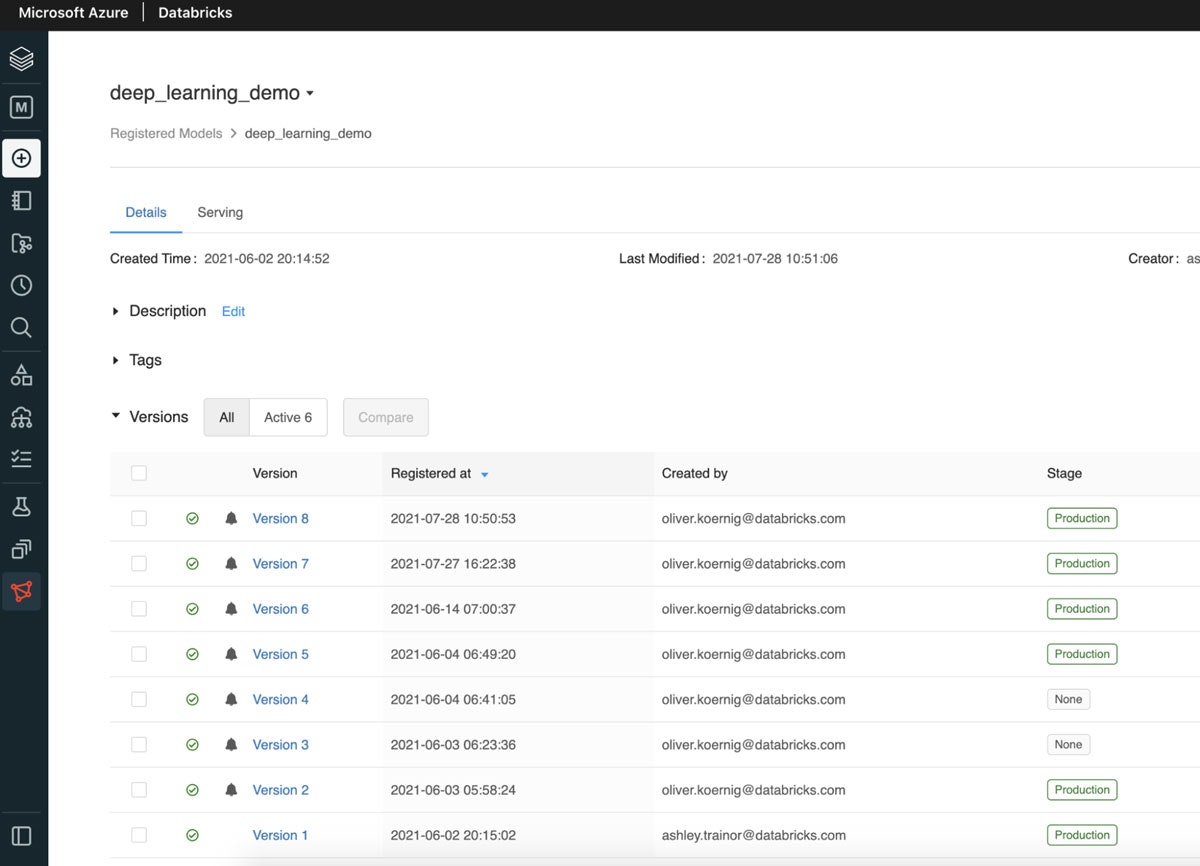
図4: 最新のプロダクションモデルを表示するモデルUI
スコアリングパイプライン
次に、CoolFundCoのスコアリングパイプラインを見ていきましょう。
1. 新規ラベルなし画像をクラウドストレージから集中管理されるレイクハウスに投入 [適切なインフラストラクチャ:大規模CPUクラスター]
スコアリングプロセスの最初のステップは、モデルが分類できるような形で、新たに到着した画像をロードすることです。CoolFundCoのチームはここでも、クラウドストレージに到着する新規データファイルをインクリメンタルかつ効率的に処理するDatabricksのオートローダーのtrigger once機能を活用することで、オートローダーのストリーミングジョブの開始、前回のトレーニングジョブ実行以降の新規画像の検知、新規ファイルのみをロードした後でストリームを停止するようにしました。将来的には、このジョブの実行を継続的なストリームに変更することも可能です。この場合、クラウドストレージに到着する新規画像は、到着するとすぐに検知され、スコアリングのためにモデルに送信されます。
最後のステップとして、すべてのラベルなし画像はDelta Lakeテーブルに格納され、スコアリングの残りのステップを通じてアクセス、更新されます。
2. 新規画像のスコアリングを行い、予測したラベルをDelta Lakeテーブルに格納 [適切なインフラストラクチャ:GPUクラスター]
新規画像がDeltaテーブルにロードされれば、モデルスコアリングノートブックを実行することができます。このノートブックは、まだ予測されておらずラベリングされていないテーブル上の全てのレコードを取得し、トレーニングパイプラインでトレーニングされた分類モデルのプロダクションバージョンをロードし、それぞれの画像を分類し、予測したラベルでDeltaテーブルを更新します。ここではDeltaフォーマットを使っているので、新規に予測した結果を用いて全てのレコードを更新するためにMERGE INTOコマンドを使用することができます。
%sql
MERGE INTO image_data i
USING preds p
ON i.path = p.path
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
3. Azure上で手動でラベリングを行うために画像を送信 [適切なインフラストラクチャ:シングルノードのCPUクラスター]
CoolFundCoは、新規画像のサブセットに手動でラベリングするために、Azure Machine Learning labeling serviceを使用しています。特に、DLモデルが信頼性高く判断できない画像サンプル(95%以下の確信度)を取得します。これらは簡単に、全ての画像、画像メタデータ、スコアリングパイプラインの結果として得られる予測ラベルが格納されているDeltaテーブルから取得することができます。これらの画像はラベリングサービスのデータストアに書き込まれます。ラベリングサービスのインクリメンタルなリフレッシュによって、ラベリングされるべき画像はラベリングプロジェクトによって検知され、ラベリングが行われます。ラベリングサービスのアウトプットは、Databricksによって前処理が行われ、Deltaテーブルにマージされることで、画像のラベルフィールドが充当されます。
図5: Azureラベリングサービスの準備
ワークフローのデプロイメント
無事にトレーニング、スコアリング、ラベリングタスクのノートブックのテストが終われば、これらをプロダクションパイプラインにまとめることができます。これらのパイプラインは、トレーニング、スコアリング、ラベリングプロセスを、チームが望むスケジュールに基づいて一定の周期(日次、週次、隔週、月次)で実行することができます。このためには、依存関係がある複数のタスクを含む一連のジョブをスケジュールし実行することができる、Databricksの新機能であるジョブオーケストレーションが最適なソリューションとなります。それぞれのノートブックがタスクとなり、全体的なトレーニングパイプラインを構成するので、これによって有向非巡回グラフ(DAG)が生成されます。これはApache Airflowのようなオープンソースツールのコンセプトと同じようなものです。しかし、ここでのメリットは、全てのエンドツーエンドのプロセスがDatabricks環境で完結するということであり、プロセスの管理、実行、モニタリングが一つの場所で容易に行えるようになります。
タスクのセットアップ
ワークフローのそれぞれのステップ、"タスク"には、専用のDatabricksノートブック、クラスター設定が割り当てられます。これによって、ワークフローのそれぞれのステップは、異なるインスタンス数、インスタンスタイプ(メモリー最適化、コンピュート最適化、CPUかGPUか)、ライブラリ、オートスケーリングの設定を持つ異なるクラスターで実行することができます。また、それぞれのタスクにパラメーターを設定することもできます。
パブリックプレビューのジョブオーケストレーション機能を使うためには、ワークスペース管理者によって機能を有効化する必要があります。有効化すると、既存のジョブ機能(シングルタスク)には戻せなくなります。このため、これまでに定義したシングルタスクのジョブとの互換性を検証するために、別にDatabricksワークスペースを作って試験することをお勧めします。
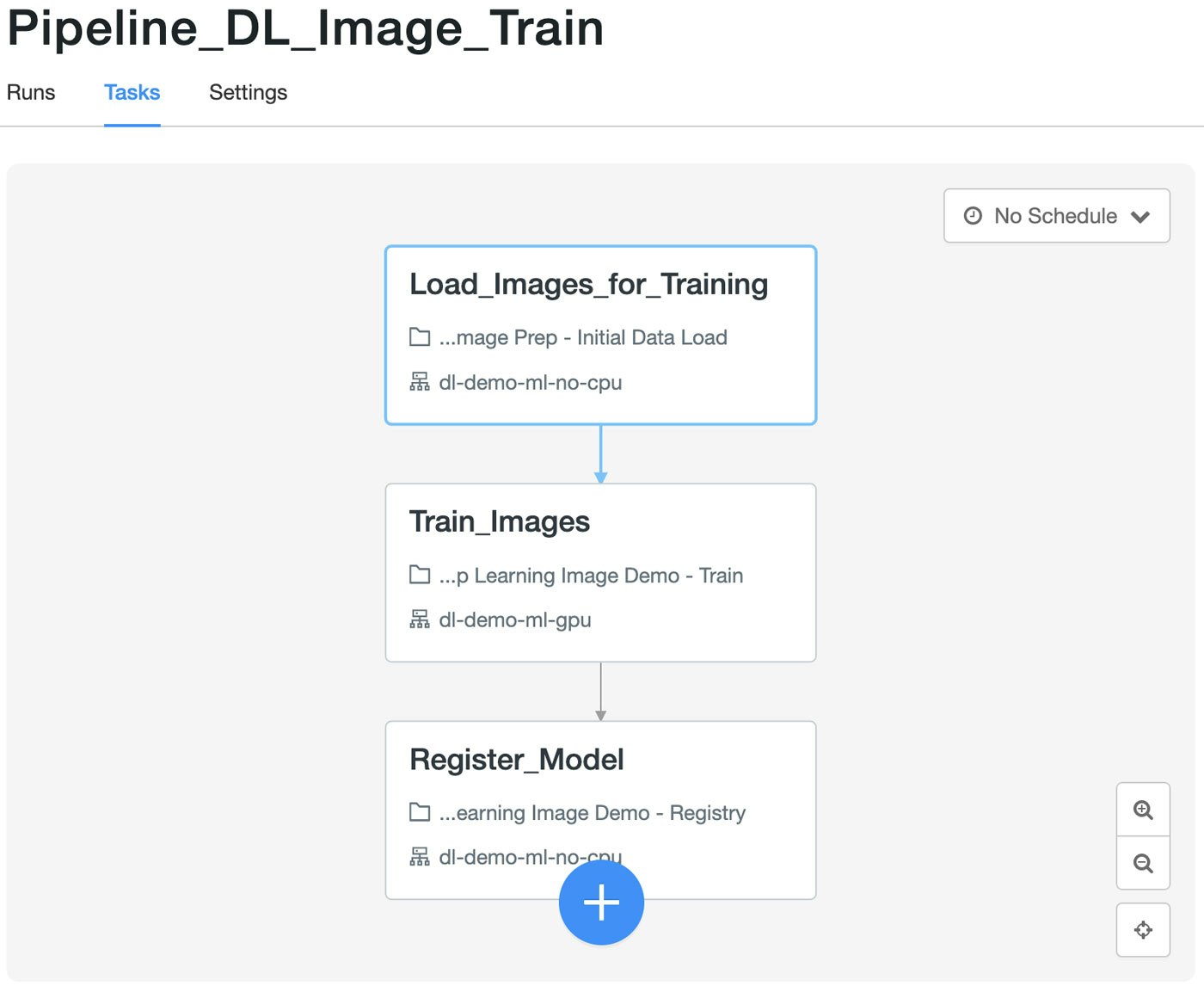
図6: Databricksジョブオーケストレーションにおけるトレーニングパイプライン
{
"email_notifications": {},
"name": "Pipeline_DL_Image_Train",
"max_concurrent_runs": 1,
"tasks": [
{
"existing_cluster_id": "0512-123048-hares793",
"notebook_task": {
"notebook_path": "/Repos/oliver.koernig/databricks_dl_demo/Deep Learning Image Prep - Initial Data Load",
"base_parameters": {
"image_path": "/tmp/256_ObjectCategories/"
}
},
"email_notifications": {},
"task_key": "Load_Images_for_Training"
},
…
}
画像スコアリングワークフローは、日次で実行される別のジョブオーケストレーションパイプラインとなります。画像のスコアリングにおいては、GPUは最適な選択肢とは言えないので、全てのノードは一般的なCPUベースのクラスターを使用します。
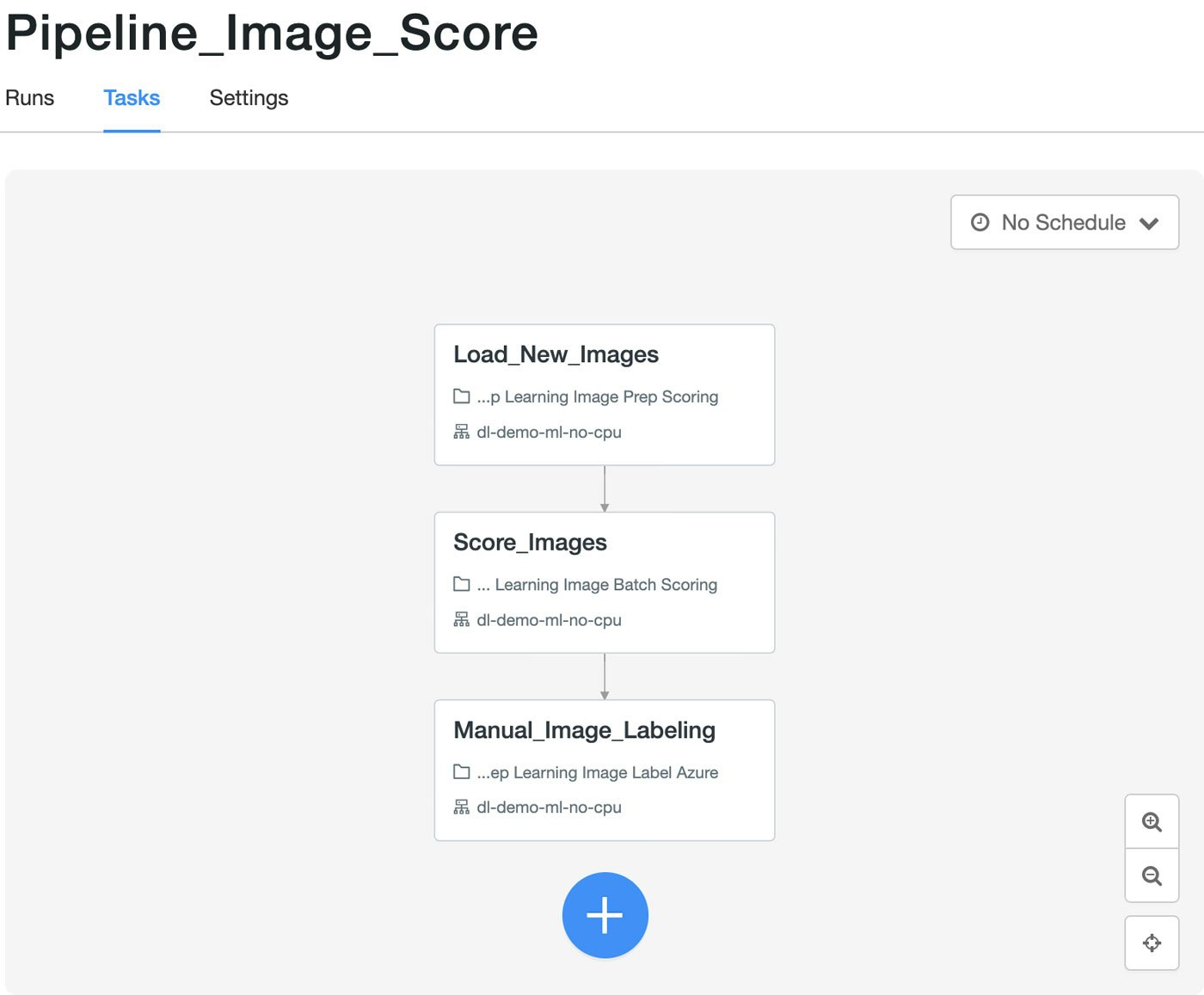
図7: Databricksジョブオーケストレーションにおけるスコアリングパイプライン
最後に、分類の精度を検証しさらに改善するために、スコアリングワークフローは画像のサブセットを抽出し、手動のラベリングサービスで利用できるようにします。この例では、Azure MLの手動のラベリングサービスを使用しています。他のクラウドプロバイダーでも類似のサービスを提供しています。
ジョブオーケストレーションパイプラインの実行、モニタリング
ジョブオーケストレーションパイプラインが実行されると、ジョブのビューアーでユーザーはリアルタイムで新緑を確認できます。これによって、パイプラインが適切に実行されているか、どれだけの時間を要しているのかを簡単にチェックすることができます。
どのようにジョブオーケストレーションパイプラインを管理するのかの詳細については、ドキュメントを参照ください。
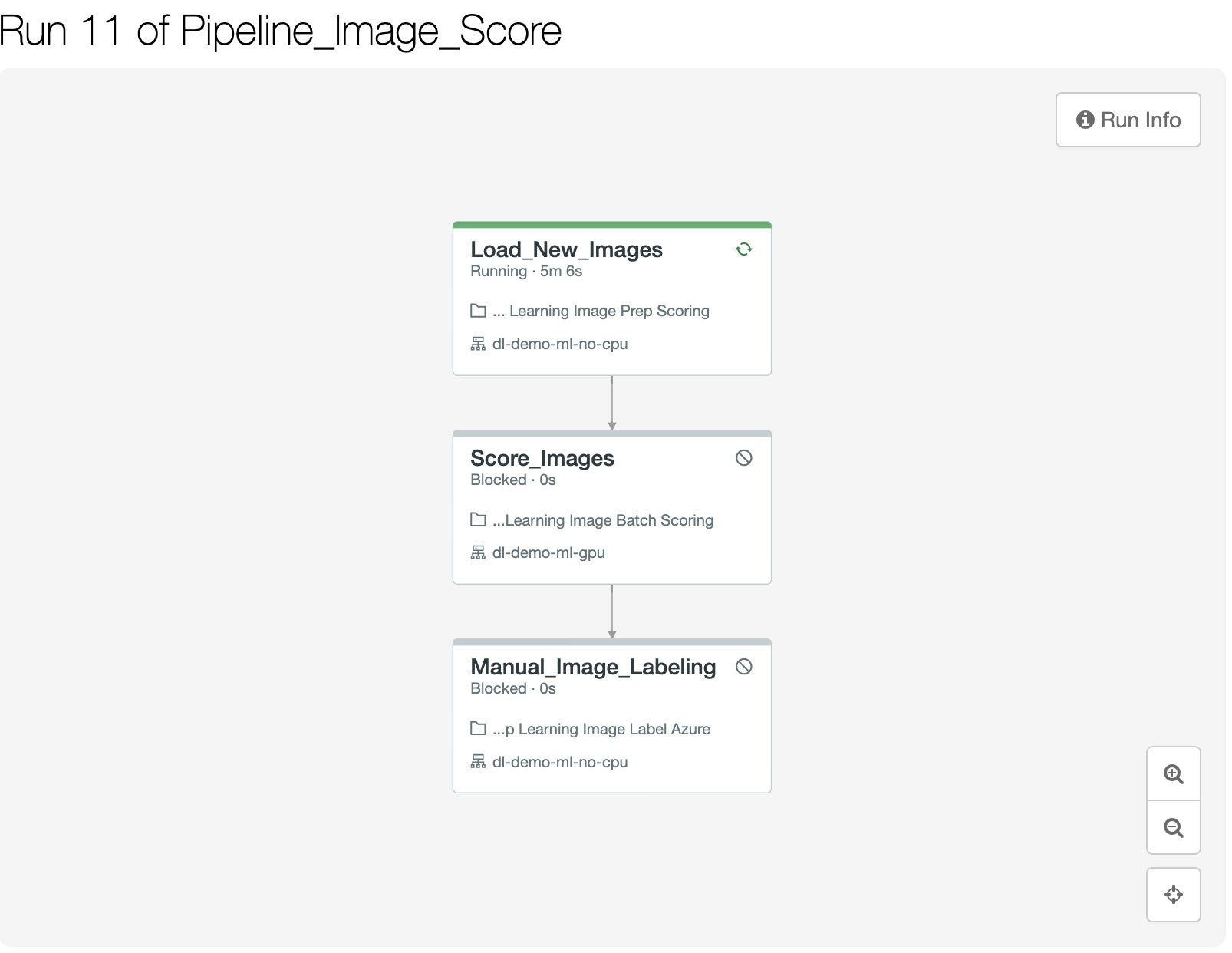
図8: Databricksジョブオーケストレーションにおけるスコアリングパイプラインの実行
まとめ
DatabricksでDLパイプラインを実装したことで、CoolFundCoは彼らの主要な課題を解決することができました。
- 全ての画像とラベルは集中管理された場所に格納され、エンジニア、データサイエンティスト、アナリストなどが容易にアクセスできるようになりました。
- 新たに改善されたモデルのバージョンは中央レポジトリ(MLflowモデルレジストリ)で管理され、アクセスできるようになりました。もはや、どのバージョンのモデルが適切にテストされ、どれが最新バージョンであり、どれを本格運用に移行したらいいのかわからないと言った混乱は無くなりました。
- 複数のパイプラインを、それぞれ異なる計算資源、異なるタイミングで実行することができるようになりました。同一パイプラインでも、タスクごとに異なる設定を用いることができます。
- Databricksジョブオーケストレーションを用いることで、パイプラインの実行は同じDatabricks環境で完結するため、スケジュール、モニタリング、管理が容易となりました。
新たに改善されたプロセスを活用することで、データサイエンティスト、MLエンジニアは、MLOpsに関連した問題に奮闘するのではなく、本当に重要なこと、深い洞察を得ることに集中できるようになりました。
使ってみる
この記事で用いられた全てのコードは以下のGitHubリポジトリから取得することができます。
DatabricksのRepos機能を使うことで、簡単にお使いのワークスペースにリポジトリをクローンすることができます。
サンプルのセットアップ手順
このデモで使用された画像は、KaggleなどでアクセスできるCaltech256データセットをベースにしています。このデータセットは、Databricksファイルシステム(DBFS)の
/tmp/256_ObjectCategories/に格納されます。このデータセットをダウンロードし、インストールするためノートブックを公開しています。
リポジトリでは、セットアップのためのノートブックも提供しています。これには、パイプラインで用いるDeltaテーブルのDDLも含まれています。上述のステップでKaggleからダウンロードされた画像データのサブセットを分離し、別のスコアリングフォルダーに格納します。このフォルダーはDBFS上の/tmp/unlabeled_images/256_ObjectCategories/であり、モデルによるスコアリングが行われるラベルなし画像が到着する場所となります。
セットアップノートブック
トレーニング、スコアリングジョブもJSONファイルとしてリポジトリに格納されています。
現状、ジョブオーケストレーションのUIでは、JSONを指定してジョブを作成することができません。リポジトリのJSONを使いたい場合には、Databricks CLIをインストールする必要があります。
CLIをインストールして設定を行った後で、お使いのDatabricksワークスペースにジョブを複製するには以下の手順を踏んでください。
-
ローカルにリポジトリをクローン(コマンドライン)
git clone https://github.com/koernigo/databricks_dl_demo cd databricks_dl_demo -
GPU、CPUクラスターの作成
このデモでは、GPUクラスター、CPUクラスターを一台づつ使っています。クラスターのスペックについては、以下を参照してください。特定のスペック(ノードタイプなど)はAzure固有のものであることに注意してください。AWSやGCPで実行する際には、同等のGPU/CPUノードタイプを選択してください。 -
JSONジョブスペックの編集
修正したいジョブのJSONを選択してください。例えばトレーニングパイプライン(https://github.com/koernigo/databricks_dl_demo/blob/main/Pipeline_DL_Image_train.json)。クラスターIDは、上記ステップで作成したクラスター(CPU/GPU)のIDで置換してください。 -
ノートブックパスの編集
リポジトリにある既存のJSONでは、パスは/Repos/oliver.koernig@databricks.com/…となっています。これをお使いのワークスペースのパスに変更してください。(例:/Repos/<あなたのメールアドレス>)/…) -
Databricks CLIによるジョブの作成
databricks jobs create –json-file Pipeline_DL_Image_train.json –profile <お使いのCLIプロファイル名>
```
- Jobs UIでジョブが作成されたことを確認