Why and How We Built Databricks for GCP on the Google Kubernetes Engine (GKE) - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
マルチクラウドのデータ、分析、AIに対するコンテナ化アプローチ
Databricks on Google Cloud Platform (GCP)のリリースは、真のマルチクラウドである統合データ、分析、AIプラットフォームに向けた大きなマイルストーンでした。Databricks on GCPはジョイントで開発されたサービスであり、お使いのすべてのデータをシンプルかつオープンなレイクハウスプラットフォームに格納できるようにし、これはGoogle’s Kubernetes Engine (GKE)上で稼働している標準コンテナをベースとしています。
Databricks on GCPをリリースした際のフィードバックは「とりあえず動いたね!」というものでした。しかし、あなた方の何人かは、DatabricksとKubernetesに関する深い質問をしました。このため、GKEを採用した理由や学び、キーとなる実装の詳細を共有することを決断しました。
なぜGoogle Kubernetes Engineなのか?
オープンソースなソフトウェアとコンテナ
Databricksにおいては、我々が我々であり続けるためのコアとしてオープンソースがあり、これが、我々はApache Spark™、MLflow、Delta Lake、Delta Sharingのようなメジャーなオープンソースプロジェクトを作成し、貢献し続けている理由となっています。また、企業としてコミュニティに還元しており、オープンソースを日々活用しています。
我々は長年にわたってコンテナを使い続けています。例えば、MLflowにおいては、ユーザーはDockerイメージとして機械学習(ML)モデルを構築し、コンテナレジストリに格納し、レジストリからモデルをデプロイし実行します。
別の例はDatabricksノートブックです。バージョン管理されたコンテナイメージは、複数のSpark、Python、Scalaバージョンのサポートをシンプルにし、コンテナはソフトウェア開発におけるより高速なイテレーションと、より安定したプロダクションシステムを実現します。
Kubernetesとhyperscale
我々はKubernetesのようなコンテナオーケストレーションシステムは自身の課題を抱えていることに気づいています。Kubernetesの背後にあるコンセプトと豊富な機能は、経験と知識が豊富なデータエンジニアリングチームを必要とします。
しかし、Databricksではここ数年においてコンテナ上での構築に成功し、オープンソースソフトウェアを作成することで、超大規模な環境に成長しました。我々のお客様は、1日あたり数百万のインスタンスを起動しており、月あたり数十万のデータサイエンティストをサポートしています。
セキュリティとシンプルさ
我々にとって最も重要なことは、データエンジニアやデータサイエンティストに新機能を迅速に提供することです。Databricks on GCPを設計した際、我々のエンジニアリングチームはセキュリティとスケーラビリティ要件を充足するためのベストな選択肢を探索しました。我々のゴールは、実装をシンプルにし、低レベルのインフラストラクチャや依存関係やインスタンスのライフサイクルへのフォーカスを削減することでした。我々のエンジニアはKubernetesを用いることで、インフラストラクチャのロジックとセキュリティをドライブするためにオープンソースコミュニティからの強力なモーメンタムを活用することができました。
GKEと他のGoogle Cloudサービス
我々は必要とされるオペレーション上の専門性と、プロダクションにおいて大規模な上流のKubernetesを稼働させることによって得られるメリットの間を重点的に評価し、最終的にはセルフマネージのKubernetesクラスターを使わないことにしました。
代わりにGKEを選択した主要な理由は、新たなKubernetesバージョンが迅速に取り込まれることと、Googleのインフラストラクチャセキュリティに対する高い優先度でした。KubernetesのオリジナルクリエーターであるGoogleのGKEは、市場において最も先進的なマネージドKubernetesサービスです。
一方で、Google Cloud Storage、Google BigQuery、Google Lookerのような全ての主要なGCPクラウドサービスとDatabricksはインテグレーションされています。我々の実装はGKE上で稼働しています。
Google Kubernetes Engine上のDatabricks
分散システムをコントロールプレーンとデータプレーンを分割することは、よく知られたデザインパターンです。コントロールプレーンのタスクは、顧客の設定を管理しサーブすることです。多くの場合より大規模なデータプレーンは顧客のリクエストを実行する目的です。
Databricks on GCPは同じパターンに従っています。Databricksがオペレーションするコントロールプレーンが、顧客のGCPアカウントのデータプレーンを作成、管理、監視します。データプレーンには、お使いのSparkクラスターのドライバーノード、エグゼキューターノードが含まれます。
GKEクラスター、名前空間、カスタムリソース定義
Databricksアカウント管理者が新規Databricksワークスペースをローンチする際、対応するデータプレーンは、VPC内のリージョナルGKEクラスターとして、顧客のGCPアカウントの中に作成されます(図1をご覧ください)。ワークスペース、GKEクラスター、VPCは1対1の関係になります。ワークスペースのユーザーは決してデータプレーンのリソースと直接インタラクションすることはありません。代わりに彼らは、Databricksがユーザーに対するアクセスコントロールとリソース分離を行うコントロールプレーン経由で間接的にインタラクションします。また、Databricksはコストを削減するために顧客の利用パターンに基づいてインテリジェントにGKE計算リソースの割り当てを解除します。
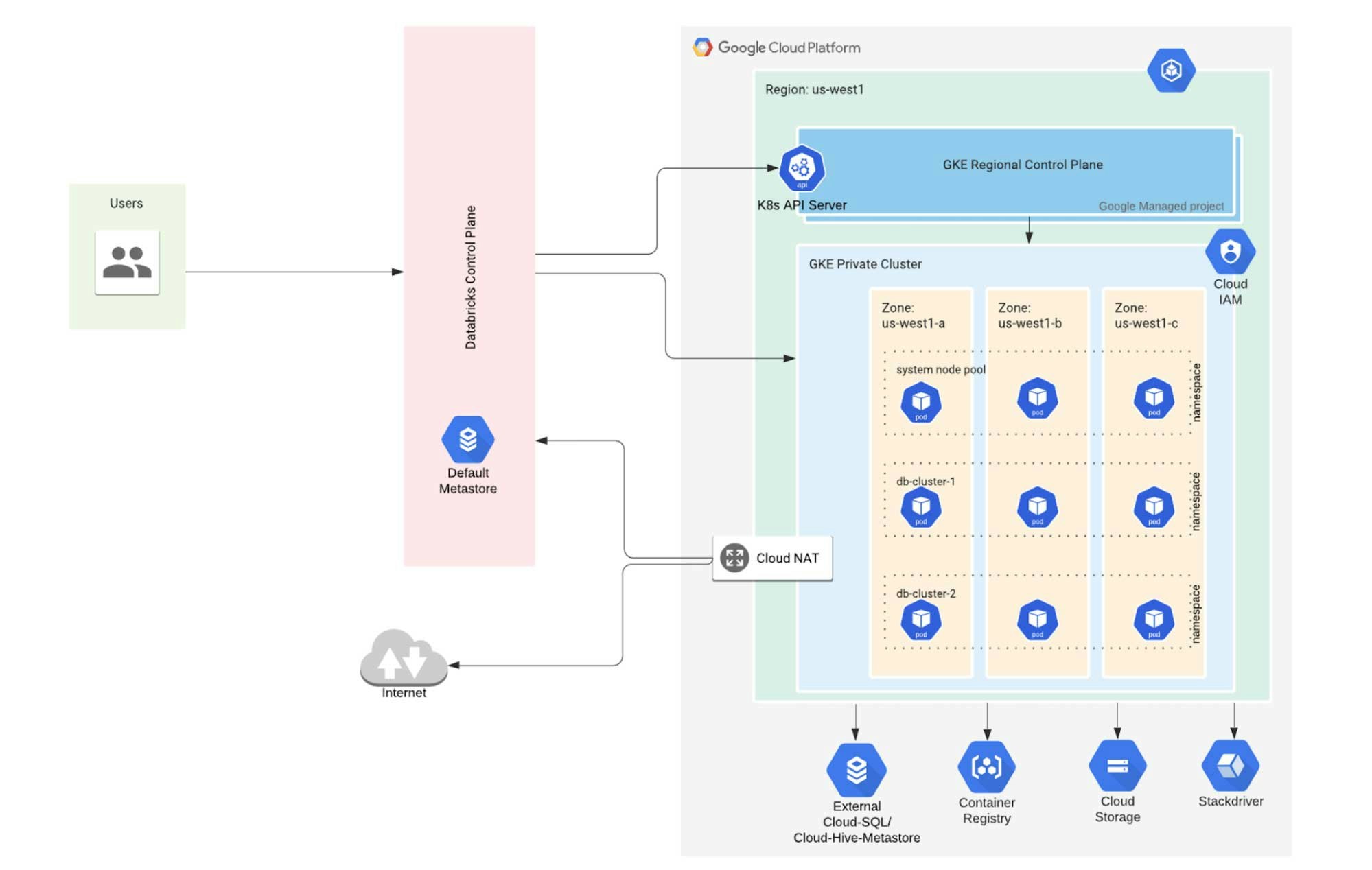
図1: Google Kubernetes Engineを用いたDatabricks
GKEクラスターとノードプール
GKEクラスターは、ワークスペース規模で稼働する信頼サービス専用のシステムノードプールによってブートストラップされます。Databricksクラスターを起動する際、ユーザーはエグゼキューターノードの数と、ドライバーノードとエグゼキューターノードのマシンタイプを指定します。コントロールプレーンの一部であるクラスターマネージャーは、これらのマシンタイプのそれぞれのGKEノードプールを作成・管理します。多くの場合、ドライバーとエグゼキューターノードば異なるマシンタイプで動作し、これらは別のノードプールから提供されます。
名前空間
Kubernetesはスコープのある名前(すなわち名前)を伴うバーチャルクラスターを作成するための名前空間を提供します。個々のDatabricksクラスターは、単一のGKEクラスターにおいてKubernetes名前空間を通じて互いが分離されており、単一のDatabricksワークスペースには、数百のDatabricksクラスターを含めることができます。GPCのネットワークポリシーが同じGKEクラスター内のDatabricksクラスターネットワークを分離し、セキュリティをさらに改善します。Databricksクラスター内のノードは、同じクラスター内の他のノードとのみコミュニケーションできます(あるいは、インターネットや他のパブリックGCPサービスにアクセスするためにNATゲートウェイを使用します)。
カスタムリソース定義
Kubernetesは、Kubernetesカスタムリソース定義(CRD)を用いたカスタマイゼーションと自身のAPIの拡張を可能にできるように徹底的に設計されました。ワークスペースのすべてのクラスターに対して、Databricksランタイム(DBR)をKubernetes CRDとしてデプロイします。
ノードプール、pods、サイドカー
Sparkドライバーとエグゼキューターは、Kubernetes podノードセレクターによって指定される対応ノードプールのノードの中で稼働するKubernetes podsとしてデプロイされます。一つのGKEノードは排他的にドライバーpodあるいはエグゼキューターpodによって使用されます。クラスターの名前空間は、Kubernetesのメモリーリクエストとリミットによって設定されます。
それぞれのKubernetesノードにおいては、Databricksはドライバーやエグゼキューターコンテナーとともに幾つかの信頼デーモンコンテナも動作させます。これらのデーモンはノードのデータアクセスとログ収集を行う信頼サイドカーサービスです。ドライバー、エグゼキューターコンテナは、制限されたインタフェースを通じて同じpodのデーモンコンテナのみとインタラクションすることができます。
Frequently Asked Questions (FAQ)
Q: Databricksが提供するGKEクラスターに自分のpodをデプロイできますか?
Databricks GKEクラスターにアクセスすることはできません。最大限のセキュリティによって制限され、リソース使用を最小化するように設定されています。
Q: 自分のカスタムGKEクラスターにDatabricksをデプロイできますか?
現時点ではサポートしていません。
Q: kubectlでDatabricks GKEクラスターにアクセスできますか?
GKEクラスターのデータプレーンはお客様のアカウントで稼働していますが、デフォルトのアクセス制限とファイアウォール設定が許可されないアクセスを防御しています。
Q: GKE上のDatabricksは他のクラウドはVM上のDatabricksよりも(クラスター起動時間などが)速いですか?
こちらに対する回答は多くの要素に依存するので、ご自身で計測することをお勧めします。Databricksのマルチクラウドのオファリングのメリットの一つは、このようなテストをクイックに行えるということです。我々の初期のテストでは、大規模の同時実行ワーカー、コールドスタートアップにおいては他のクラウドと比較してGKEの方が高速でした。同等のローカルSSDを持つインスタンスが特定のSparkワークロードを実行した際、他のクラウドの同等の計算リソース(コア、メモリー、ディスク)と比較して若干高速でした。
Q: なぜDatabricksクラスターごとに一つのGKEクラスターを使わないのですか?
効率性のためです。Databricksクラスターは頻繁に作成され、それらのいくつか(短時間のジョブなど)は短寿命です。
Q: 100ノードのクラスターを起動するにはどのくらいの時間を要しますか?
100ノード以上の大規模クラスターであっても、起動は並列で実行されるので、起動時間はクラスターサイズに依存しません。ご自身の設定を用いて自分で起動時間を計測することをお勧めします。
Q: コスト効率性のために、どのようにpodがノードに割り当てられるかをどのように最適化できますか?幾つかのSparkエグゼキューターpodをより大きなノードに割り当てたいのですが。
Podsはそれぞれの用途(ドライバー、ワーカーノード)に応じてDatabricksによって最適に設定されます。
Q: GKEクラスターに対して自分のVPCを持ち込むことができますか?
本機能に関して興味がある場合には、Databricksのアカウントマネージャーにコンタクトしてロードマップを確認してください。
Q: 単一のGKEクラスターでDatabricksが複数のDatabricksクラスターを実行しても安全ですか?
DatabricksクラスターはKubernetes名前空間とGCPネットワークポリシーを用いて、それぞれが完全に分離されています。コストを削減し、プロビジョンを高速にするために、同じDatabricksワークスペースのDatabricksクラスターのみがGKEクラスターを共有します。複数のワークスペースをお持ちであれば、それぞれにGKEクラスターが稼働することになります。
Q: 単にVMを使うのと比較して、GKEには追加のネットワークオーバーヘッドはありませんか?
GCPにおける初期のテストにおいて、us-west2/1におけるn1-standard-4でのiperf3ベンチマークは、9 Gpbs以上という素晴らしいpod間スループットを示しました。通常、GCPはインターネットに対して高いスループットと低いレーテンシーを示します。
Q: Databricksが完全にコンテナ化されているのであれば、(自分のローカルのKubernetesクラスターなどで)自分で使用するためにDatabricksイメージをプルすることはできませんか?
現状Databricksではこれをサポートしていません。
Q: Databricks on GCPを使用する際、リージョン内の1つのAZしか使えませんか?GKEへのノード割り当てはどのように動作しますか?
GKEクラスターはリージョン内のすべてのAZを使用します。
Q: Databricks on GCPにはどのような機能が含まれていますか?
最新の情報に関してはこちらのリンクをチェックしてください。
著者として、価値のあるインプットとサポートをしてくれたSilviu Tofanに感謝の意を表します。