Databricksクイックスタートガイドのコンテンツです。
Get started as a Databricks Data Science & Engineering user | Databricks on AWS [2021/5/26時点]の翻訳です。
このチュートリアルでDatabricksデータサイエンス&データエンジニアリングワークスペースをご説明します:クラスターやノートブックの作成、データセットからテーブルの作成、テーブルの検索、検索結果の表示を行います。
Tips
この記事の内容を補完するために、ワークスペースにログインした後に利用できる5分程度のハンズオンを実施できるクイックスタート チュートリアル ノートブックをご確認下さい。DatabricksにログインしてExplore the Quickstart Tutorialをクリックしてください。
要件
Databricksにログインすることで、データサイエンス&データエンジニアリングワークスペースに入ることができます。Sign up for a free Databricks trial(英語)を参照ください。
ステップ1 Databricksデータサイエンス&データエンジニアリングのUIに慣れる
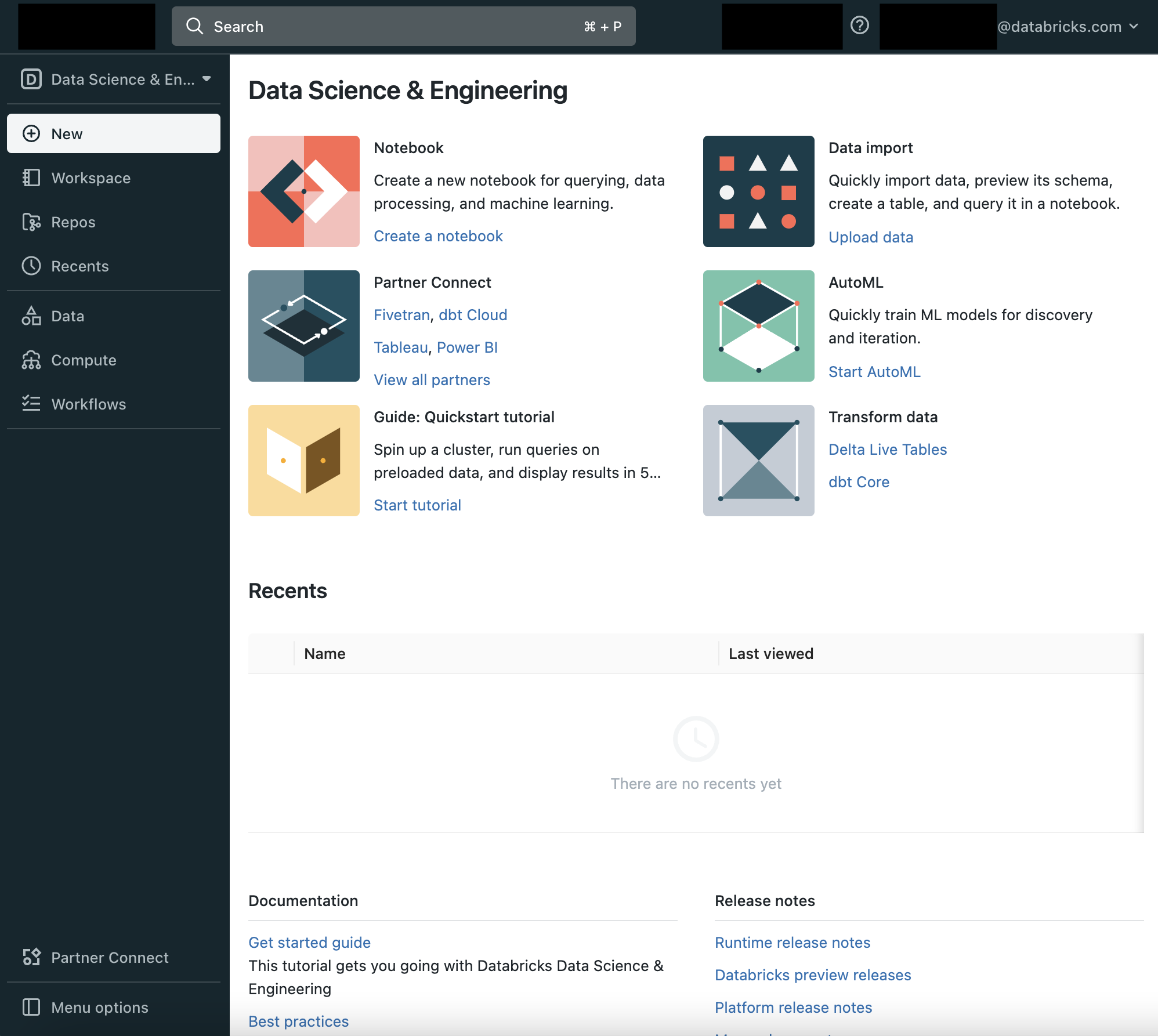
左のサイドバー、ランディングページのCommon Tasksリストから、Databricksデータサイエンス&データエンジニアリングの基本的な構成要素にアクセスすることができます:ワークスペース、クラスター、テーブル、ノートブック、ジョブ、そしてライブラリです。ワークスペースは、ノートブックやライブラリ、インポートしたデータなどのDatabricksアセットを格納する特別なルートフォルダーです。
サイドバーの利用
左のサイドバーからDatabricksの全てのアセットにアクセスできます。サイドバーのコンテンツは選択するペルソナ(Data Science & Engineering、Machine Learning、Databricks SQL)によって決まります。
- デフォルトではサイドバーは畳み込まれた状態で表示され、アイコンのみが表示されます。サイドバー上にカーソルを移動すると全体を表示することができます。
- ペルソナを変更するには、Databricksロゴの直下にあるアイコンからペルソナを選択します。

- 次回ログイン時に表示されるペルソナを固定するには、ペルソナの隣にある
 をクリックします。再度クリックするとピンを削除することができます。
をクリックします。再度クリックするとピンを削除することができます。 - サイドバーの一番下にあるMenu optionsで、サイドバーの表示モードを切り替えることができます。Auto(デフォルト)、Expand(展開)、Collapse(畳み込み)から選択できます。
- 機械学習に関連するページを開く際には、ペルソナは自動的にMachine Learningに切り替わります。
ヘルプの利用
ヘルプにアクセスするためには、右上のアイコン![]() をクリックします。
をクリックします。
ステップ2 クラスターの作成
クラスターはDatabricksの計算リソースの集合体です。クラスターを作成するには:
-
サイドバーのClustersボタンをクリックします。

-
クラスターページで、Create Clusterをクリックします。

-
クラスター作成ページで、クラスター名Quickstartを指定して、Databricksランタイムバージョンドロップダウンから**7.3 LTS (Scala 2.12, Spark 3.0.1)**を選択します。
-
Create Clusterをクリックします。
ステップ3 ノートブックの作成
ノートブックはApache Sparkクラスターでの処理を実行するセルの集合体です。ワークスペースでノートブックを作成するには:
- サイドバーでWorkspaceボタンをクリックします。

- ワークスペースのフォルダーで
 をクリックし、Create > Notebookを選択します。
をクリックし、Create > Notebookを選択します。

- ノートブック作成ダイアログで、名前を入力し、言語ドロップダウンではSQLを選択します。この選択が、ノートブックのデフォルト言語を決定します。
- Createをクリックします。先頭のセルが空白のノートブックが開きます。
ステップ4 テーブルの作成
Databricksクラスターにインストールされた分散ファイルシステムDatabricks File System (DBFS)にマウントされたデータセットコレクションであるDatabricks datasets(英語)のサンプルCSVファイルからテーブルを作成します。テーブルを作成するには2つの選択肢があります。
オプション1: CSVデータからSparkテーブルを作成する
標準的なパフォーマンスで十分で、すぐにテーブルを作りたいのであればこちらのオプションとなります。以下のスニペットをノートブックセルに貼り付けます。
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING CSV OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header "true")
オプション2: CSVデータをDelta Lake形式で書き込み、Deltaテーブルを作成する
Delta Lake(英語)は、高速な読み込み、その他のメリットを提供する強力なトランザクショナルストレージレイヤーです。Delta LakeフォーマットはParquetファイルとトランザクションログから構成されます。将来的なパフォーマンスを見据えた場合に最適な選択肢となります。
CSVデータをデータフレームに読み込み、Delta Lake形式で書き込みを行います。このコマンドでは、Pythonの言語マジックコマンドを使用し、ノートブックのデフォルト言語(SQL)以外の言語の処理を組み込みます。以下のコードスニペットをノートブックセルに貼り付けます。
%python
diamonds = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true")
diamonds.write.format("delta").save("/mnt/delta/diamonds")
格納場所にDeltaテーブルを作成します。 以下のコードスニペットをノートブックセルに貼り付けます。
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds USING DELTA LOCATION '/mnt/delta/diamonds/'
SHIFT + ENTERを押してセルを実行します。ノートブックは自動的にステップ2で作成したクラスターにアタッチされ、セル内のコマンドが実行されます。
ステップ5 テーブルを検索
色ごとのダイヤモンドの平均価格を計算するSQL分を実行します。
-
セルの下にある
 をクリックして、ノートブックにセルを追加します。
をクリックして、ノートブックにセルを追加します。

-
以下のスニペットをセルに貼り付けます。
SELECT color, avg(price) AS price FROM diamonds GROUP BY color ORDER BY COLOR
SHIFT + ENTERを押してセルを実行します。ダイヤモンドの色と平均価格が表示されます。

ステップ6 データの表示
色ごとの平均ダイヤモンド価格の図を表示します。
-
バーチャートアイコン
 をクリックします。
をクリックします。 -
Plot Optionsをクリックします。
- colorをKeysボックスにドラッグします。
- priceをValuesボックスにドラッグします。
- AggregationドロップダウンでAVGを選択します。

-
Applyをクリックしバーチャートを表示します。
次のステップ
ここまでで、クラスターの作成、ノートブックの作成、ノートブック上でのSQLコマンドの実行、結果の表示を行い、Databricksワークスペースの基礎を学ぶことができました。
- Apache Sparkに関する文献に関しては、Introduction to Apache Spark(英語)を参照ください。
- Databricksワークスペースで使用する主要なツールの理解を深めたいのであれば、以下をご覧ください:
- Databricksワークスペースの利用例を見るには、こちらの動画を参照ください。