こちらのブログ記事で発表されていました。
新たな合成データ生成機能で、AIエージェントの評価を効率化する
本日、Agent Evaluationの重大なエンハンスメントを発表できることを嬉しく思っています: 合成データ生成A PIです。合成データ生成には、現実世界のデータを模倣する人工データの生成が含まれていますが、これは「作り物」の情報ではないことに注意することが重要です。我々のAPIはあなた固有のデータとユニークなユースケースに基づいて仕立てられた評価セットを生成するために、あなた固有のデータを活用します。ソフトウェアエンジニアリングにおけるテストスイート、従来のMLにおける検証データと類似の評価データによって、エージェントの品質を評価、改善することができます。
マニュアルはこちらです。
まずは、こちらのサンプルノートブックを動かしてみます。
プレビュー
本機能はパブリックプレビューです。リージョンによっては利用できるようになるまで時間を要することがあります。執筆時点でAWS東京リージョンでは動作しませんでした。
ドキュメントから評価データセットを合成する
このノートブックは、ドキュメント検索を使用するエージェントの評価データセットをどのように合成できるかを示しています。これは、databricks-agents Python パッケージの一部である generate_evals_df メソッドを使用します。
%pip install mlflow mlflow[databricks] databricks-agents
dbutils.library.restartPython()
ドキュメント
APIは以下の通りです。詳細については、ドキュメントを参照してください(AWS | Azure)。
API:
def generate_evals_df(
docs: Union[pd.DataFrame, "pyspark.sql.DataFrame"], # noqa: F821
*,
num_evals: int,
agent_description: Optional[str] = None,
question_guidelines: Optional[str] = None,
) -> pd.DataFrame:
"""
質問と期待される回答を含む評価データセットを生成します。
生成された評価セットはDatabricksエージェント評価で使用できます。
AWS: (https://docs.databricks.com/ja/generative-ai/agent-evaluation/evaluate-agent.html)
Azure: (https://learn.microsoft.com/ja-jp/azure/databricks/generative-ai/agent-evaluation/evaluate-agent).
:param docs: テキスト列 `content` と `doc_uri` 列を持つpandas/Spark DataFrame。
:param num_evals: 合計で生成する質問(および対応する回答)の数。
:param agent_description: 任意、エージェントのタスク説明。
:param question_guidelines: 任意、合成質問生成をガイドするためのガイドライン。この文字列は生成のプロンプトとして使用されます。文字列はマークダウン形式でフォーマットでき、以下のようなセクションを含むことができます:
- ユーザーペルソナ: エージェントがサポートすべきユーザーの種類
- 質問の例: 生成をガイドするサンプル質問
- 追加ガイドライン: 追加のルールや要件
"""
次のコードブロックは、ドキュメントのDataFrameから評価データセットを合成します。
- 入力はPandas DataFrameまたはSpark DataFrameで可能です。
- 出力されたDataFrameは直接
mlflow.evaluate()で使用できます。
import mlflow
from databricks.agents.evals import generate_evals_df
import pandas as pd
# これらのドキュメントは、'content'と'doc_uri'の2つの列を持つPandas DataFrameまたはSpark DataFrameである可能性があります。
docs = pd.DataFrame.from_records(
[
{
'content': f"""
Apache Sparkは、大規模データ処理のための統合分析エンジンです。Java、Scala、Python、Rの高レベルAPIを提供し、一般的な実行グラフをサポートする最適化エンジンを備えています。また、SQLおよび構造化データ処理のためのSpark SQL、pandasワークロードのためのpandas API on Spark、機械学習のためのMLlib、グラフ処理のためのGraphX、インクリメンタル計算およびストリーム処理のためのStructured Streamingなどの高レベルツールの豊富なセットもサポートしています。
""",
'doc_uri': 'https://spark.apache.org/docs/3.5.2/'
},
{
'content': f"""
Sparkの主な抽象化は、Datasetと呼ばれるアイテムの分散コレクションです。DatasetはHadoop InputFormats(HDFSファイルなど)から作成するか、他のDatasetを変換することによって作成できます。Pythonの動的な性質のため、PythonではDatasetを強く型付けする必要はありません。その結果、PythonのすべてのDatasetはDataset[Row]であり、PandasやRのデータフレームの概念と一致させるためにDataFrameと呼びます。
""",
'doc_uri': 'https://spark.apache.org/docs/3.5.2/quick-start.html'
}
]
)
agent_description = """
エージェントは、Databricks上でSparkを使用する方法に関する質問に答えるRAGチャットボットです。エージェントはDatabricksドキュメントのコーパスにアクセスでき、ユーザーの質問に対してコーパスから関連するドキュメントを取得し、有益で正確な回答を合成することが任務です。コーパスは多くの情報をカバーしていますが、エージェントは特にSparkに関する質問に対してDatabricksユーザーと対話するように設計されています。したがって、この範囲外の質問は無関係と見なされます。
"""
question_guidelines = """
# ユーザーペルソナ
- Databricksプラットフォームに不慣れな開発者
- 経験豊富で高度な技術を持つデータサイエンティストまたはデータエンジニア
# 例の質問
- deltaテーブルの行に対して操作を並列化するAPIはどれですか?
- Sparkを使用する際に最高のパフォーマンスを得るためのクラスタ設定はどれですか?
# 追加ガイドライン
- 質問は簡潔で人間らしいものであるべきです
"""
num_evals = 10
evals = generate_evals_df(
docs,
# 生成する評価の総数。このメソッドは、提供されたドキュメント全体をカバーする評価を生成しようとします。この数がドキュメントの数より少ない場合、一部のドキュメントには評価が生成されません。
# `num_evals`がドキュメント全体に評価を分配する方法の詳細については、ドキュメントを参照してください:
# AWS: https://docs.databricks.com/ja/generative-ai/agent-evaluation/synthesize-evaluation-set.html#num-evals
# Azure: https://learn.microsoft.com/ja-jp/azure/databricks/generative-ai/agent-evaluation/synthesize-evaluation-set
num_evals=num_evals,
# 合成生成をガイドする一連のガイドライン。これは、生成を促すために使用される自由形式の文字列です。
agent_description=agent_description,
question_guidelines=question_guidelines
)
display(evals)
# 新しく生成された評価セットを使用してモデルを評価します。関数呼び出しが完了したら、UIリンクをクリックして結果を確認してください。これをエージェントのベースラインとして使用できます。
results = mlflow.evaluate(
model="endpoints:/databricks-meta-llama-3-1-405b-instruct",
data=evals,
model_type="databricks-agent"
)
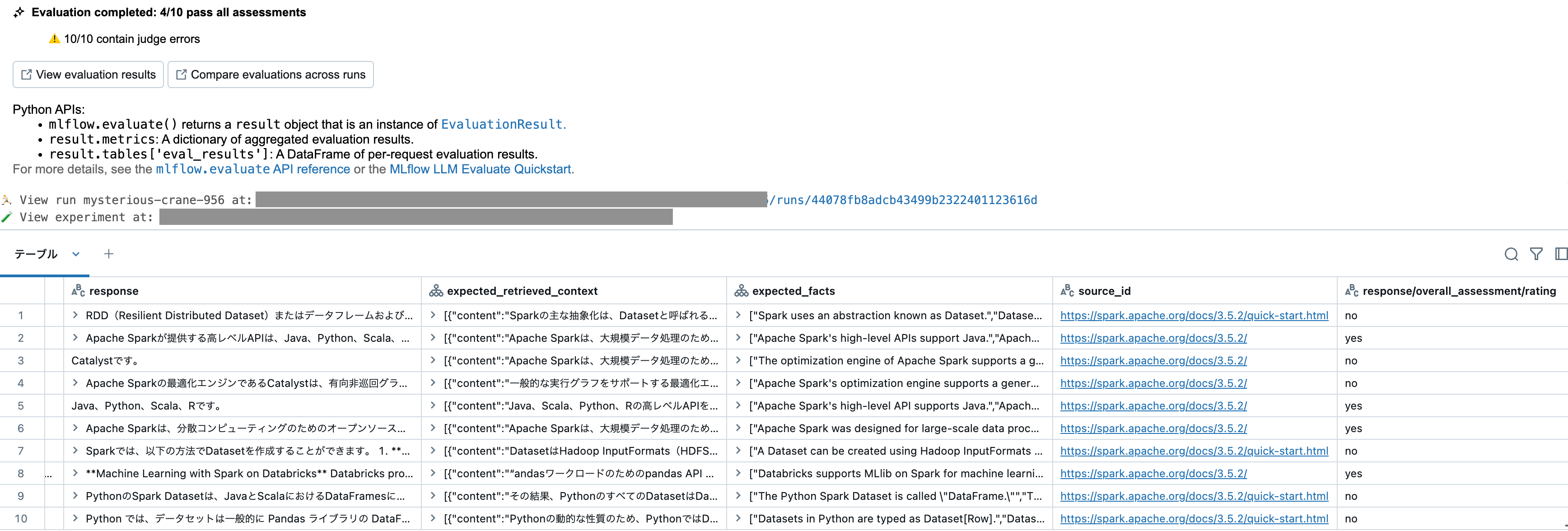
display(results.tables['eval_results'])
# 注: 別のモデルサービングエンドポイントを使用するには、次のスニペットを使用してagent_fnを定義します。その後、`model`引数を使用してその関数を指定します。
# MODEL_SERVING_ENDPOINT_NAME = '...'
# def agent_fn(input):
# client = mlflow.deployments.get_deploy_client("databricks")
# return client.predict(endpoint=MODEL_SERVING_ENDPOINT_NAME, inputs=input)
リクエスト、想定される収集コンテキスト、期待される事実、ソースタイプなどから構成される評価データセットが生成されます。

mlflow.evaluate()で評価が実施されます。このサンプルでは、Foundation Models APIのエンドポイントdatabricks-meta-llama-3-1-405b-instructを評価していますが、自分でデプロイしたエージェントも同様に評価可能です。
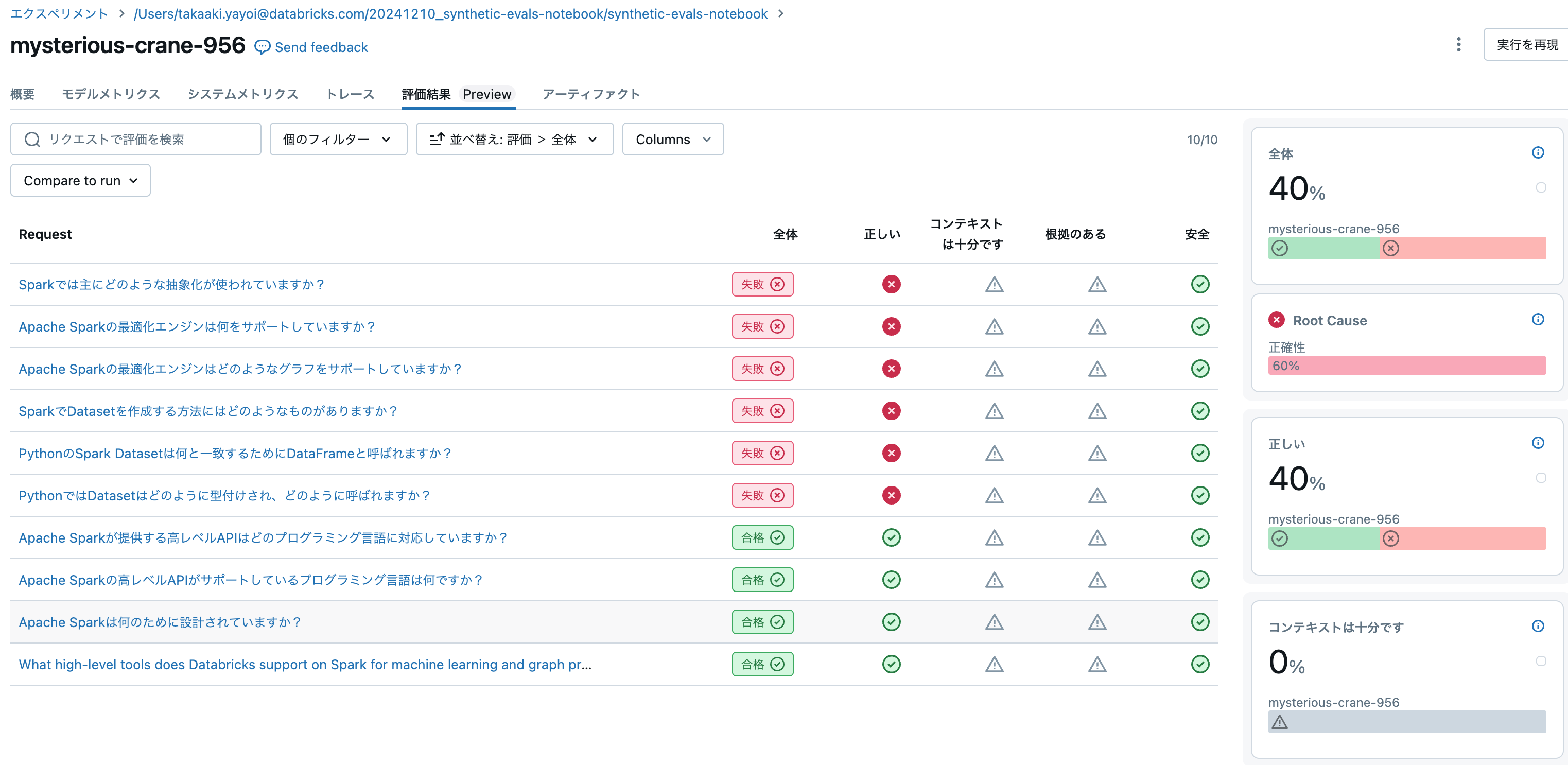
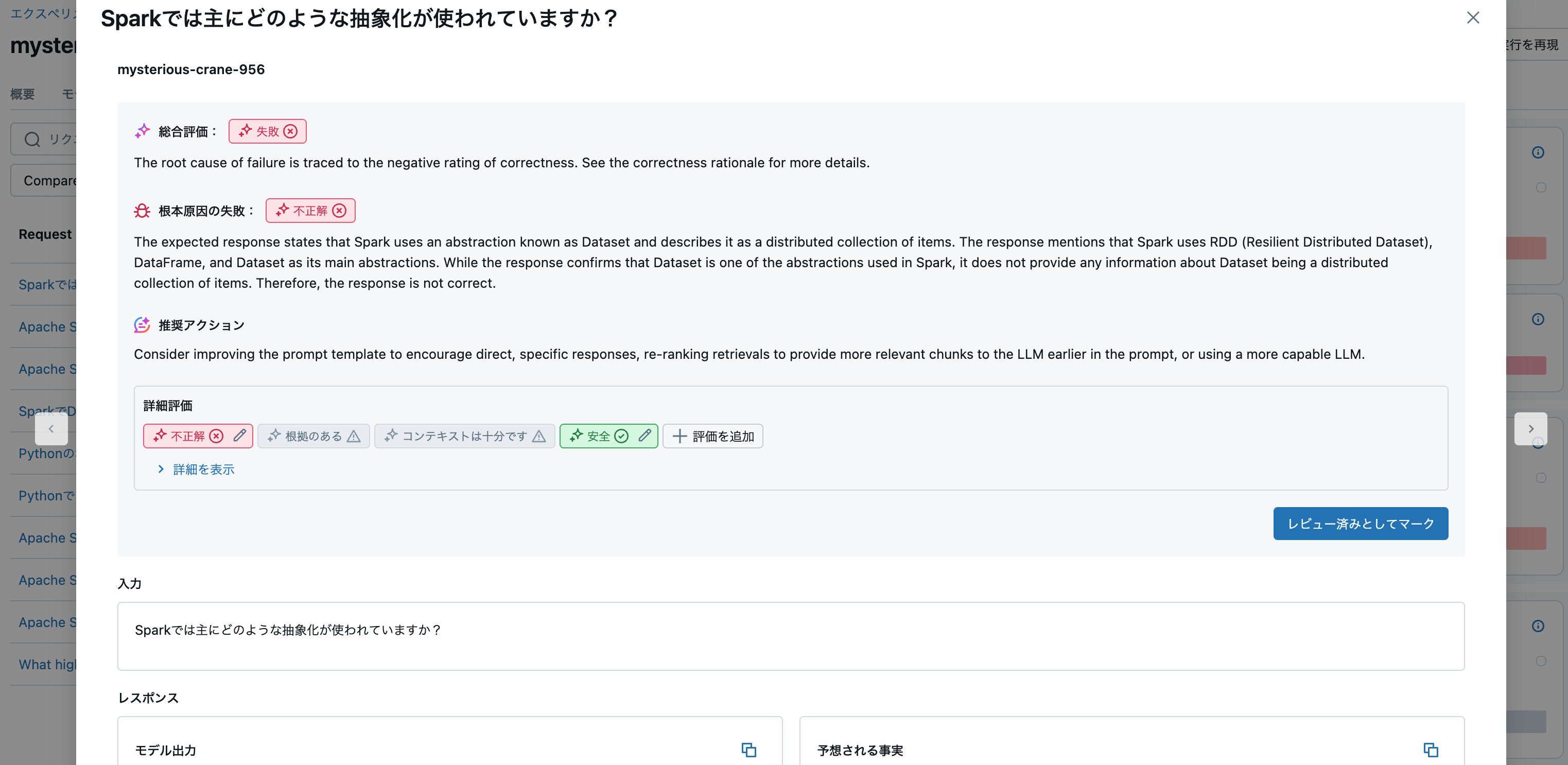
エクスペリメントの評価結果タブで詳細を確認することができます。
どんどん、LLMOpsが効率化されていきますね。