はじめに
Databricks のモデルサービングでカスタムモデルをデプロイする際、従来はコンテナのビルドに時間がかかり、トレーニング環境とサービング環境の不一致が問題になることがありました。
「サーバーレス最適化デプロイメント」は、これらの課題を解決する機能です。本記事では、従来方式との比較を通じて、この機能の効果を検証します。
参考: 公式ドキュメント
サーバーレス最適化デプロイメントとは
サーバーレスノートブック環境でモデルを登録する際に、モデルのアーティファクトと環境を事前にパッケージ化・ステージングする機能です。
主なメリット:
- デプロイメント時間の大幅な短縮 (コンテナビルドが不要)
- トレーニング環境とサービング環境の一貫性を保証
従来方式との違い
| 観点 | 従来のデプロイメント | サーバーレス最適化デプロイメント |
|---|---|---|
| コンテナビルド | デプロイ時に実行 | 不要 (事前にパッケージ化済み) |
| 環境の一貫性 | 不一致の可能性あり | トレーニング環境と同一 |
| モデル登録時間 | 短い | 長い (パッケージ化を含む) |
| デプロイ時間 | 長い | 短い |
要件
サーバーレス最適化デプロイメントを使用するには、以下の要件を満たす必要があります。
- カスタムモデルであること (基盤モデルAPIではない)
- サーバーレスノートブックでバージョン 3 または 4 を使用してモデルを記録・登録
- MLflow 3.1 以上を使用
- Unity Catalog に登録されていること
- CPU でサービングされること
- モデルの最大環境サイズは 1GB
実践: 従来方式との比較検証
同じモデルを従来方式とサーバーレス最適化の両方でデプロイし、時間を比較します。
はじめにサーバレスの環境バージョンを3以上にします。
1. 環境準備
%pip install --upgrade mlflow
%restart_python
import mlflow
from mlflow.utils.env_pack import EnvPackConfig
from mlflow.models import infer_signature
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import (
EndpointCoreConfigInput,
EndpointStateReady,
ServedEntityInput,
)
print(f"MLflow version: {mlflow.__version__}")
# Workspace Client の初期化
w = WorkspaceClient()
実行結果:
MLflow version: 3.8.1
2. 設定パラメータ
CATALOG_NAME = "takaakiyayoi_catalog"
SCHEMA_NAME = "default"
# 従来方式用
MODEL_NAME_TRADITIONAL = "traditional_iris_model"
ENDPOINT_NAME_TRADITIONAL = "traditional-iris-endpoint"
# サーバーレス最適化用
MODEL_NAME_OPTIMIZED = "serverless_optimized_iris_model"
ENDPOINT_NAME_OPTIMIZED = "serverless-optimized-iris-endpoint"
registered_model_traditional = f"{CATALOG_NAME}.{SCHEMA_NAME}.{MODEL_NAME_TRADITIONAL}"
registered_model_optimized = f"{CATALOG_NAME}.{SCHEMA_NAME}.{MODEL_NAME_OPTIMIZED}"
3. 共通関数の定義
def wait_for_endpoint_ready(endpoint_name: str, timeout_minutes: int = 20):
"""エンドポイントが Ready になるまで待機し、所要時間を計測"""
print(f"エンドポイント '{endpoint_name}' の準備を待機中...")
start_time = time.time()
timeout_seconds = timeout_minutes * 60
while True:
try:
endpoint = w.serving_endpoints.get(name=endpoint_name)
state = endpoint.state.ready
if state == EndpointStateReady.READY:
elapsed = time.time() - start_time
print(f"✅ エンドポイントが Ready になりました")
print(f"⏱️ デプロイ所要時間: {elapsed:.1f}秒 ({elapsed/60:.1f}分)")
return endpoint, elapsed
elapsed = time.time() - start_time
if elapsed > timeout_seconds:
print(f"⏰ タイムアウト ({timeout_minutes} 分)")
return None, elapsed
print(f" 状態: {state} (経過時間: {int(elapsed)}秒)")
time.sleep(15)
except Exception as e:
print(f"状態確認エラー: {e}")
time.sleep(15)
def create_endpoint(endpoint_name: str, model_name: str, model_version: str):
"""エンドポイントを作成"""
try:
endpoint = w.serving_endpoints.create(
name=endpoint_name,
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name=model_name,
entity_version=model_version,
workload_size="Small",
scale_to_zero_enabled=True,
)
]
),
)
print(f"✅ エンドポイント '{endpoint_name}' を作成しました")
return endpoint
except Exception as e:
print(f"❌ エラー: {e}")
return None
4. サンプルモデルの作成
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# データの準備
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
# モデルの学習
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(f"テスト精度: {accuracy:.4f}")
# Unity Catalog をレジストリとして設定
mlflow.set_registry_uri("databricks-uc")
# モデルのシグネチャを推論
signature = infer_signature(X_train, model.predict(X_train))
実行結果:
テスト精度: 1.0000
5. 従来方式でのデプロイ
5.1 モデルの記録と登録
print("=== 従来方式: モデル登録 ===")
with mlflow.start_run(run_name="traditional_model") as run:
model_info_traditional = mlflow.sklearn.log_model(
sk_model=model,
artifact_path="model",
signature=signature,
)
# 従来方式でモデルを登録 (env_pack なし)
start_time = time.time()
model_version_traditional = mlflow.register_model(
model_uri=model_info_traditional.model_uri,
name=registered_model_traditional,
)
registration_time_traditional = time.time() - start_time
print(f"✅ 登録完了: {registered_model_traditional}")
print(f"登録時間: {registration_time_traditional:.1f}秒")
実行結果:
モデル登録中 (従来方式)...
Successfully registered model 'takaakiyayoi_catalog.default.traditional_iris_model'.
🔗 Created version '1' of model 'takaakiyayoi_catalog.default.traditional_iris_model': https://xxxx.cloud.databricks.com/explore/data/models/takaakiyayoi_catalog/default/traditional_iris_model/version/1?o=5099015744649857
✅ 登録完了: takaakiyayoi_catalog.default.traditional_iris_model
バージョン: 1
登録時間: 5.2秒
5.2 エンドポイント作成とデプロイ時間計測
create_endpoint(
ENDPOINT_NAME_TRADITIONAL,
registered_model_traditional,
str(model_version_traditional.version)
)
endpoint_traditional, deploy_time_traditional = wait_for_endpoint_ready(ENDPOINT_NAME_TRADITIONAL)
print(f"\n=== 従来方式: 結果 ===")
print(f"モデル登録時間: {registration_time_traditional:.1f}秒")
print(f"エンドポイントデプロイ時間: {deploy_time_traditional:.1f}秒")
print(f"合計: {registration_time_traditional + deploy_time_traditional:.1f}秒")
実行結果:
エンドポイント 'traditional-iris-endpoint' の準備を待機中...
状態: EndpointStateReady.NOT_READY (経過時間: 0秒)
状態: EndpointStateReady.NOT_READY (経過時間: 15秒)
状態: EndpointStateReady.NOT_READY (経過時間: 30秒)
状態: EndpointStateReady.NOT_READY (経過時間: 45秒)
状態: EndpointStateReady.NOT_READY (経過時間: 60秒)
状態: EndpointStateReady.NOT_READY (経過時間: 75秒)
状態: EndpointStateReady.NOT_READY (経過時間: 90秒)
状態: EndpointStateReady.NOT_READY (経過時間: 105秒)
状態: EndpointStateReady.NOT_READY (経過時間: 120秒)
状態: EndpointStateReady.NOT_READY (経過時間: 135秒)
状態: EndpointStateReady.NOT_READY (経過時間: 150秒)
状態: EndpointStateReady.NOT_READY (経過時間: 166秒)
状態: EndpointStateReady.NOT_READY (経過時間: 181秒)
状態: EndpointStateReady.NOT_READY (経過時間: 196秒)
状態: EndpointStateReady.NOT_READY (経過時間: 211秒)
状態: EndpointStateReady.NOT_READY (経過時間: 226秒)
状態: EndpointStateReady.NOT_READY (経過時間: 241秒)
状態: EndpointStateReady.NOT_READY (経過時間: 256秒)
状態: EndpointStateReady.NOT_READY (経過時間: 271秒)
状態: EndpointStateReady.NOT_READY (経過時間: 286秒)
状態: EndpointStateReady.NOT_READY (経過時間: 301秒)
状態: EndpointStateReady.NOT_READY (経過時間: 316秒)
状態: EndpointStateReady.NOT_READY (経過時間: 331秒)
状態: EndpointStateReady.NOT_READY (経過時間: 347秒)
状態: EndpointStateReady.NOT_READY (経過時間: 362秒)
状態: EndpointStateReady.NOT_READY (経過時間: 377秒)
状態: EndpointStateReady.NOT_READY (経過時間: 392秒)
状態: EndpointStateReady.NOT_READY (経過時間: 407秒)
✅ エンドポイントが Ready になりました
⏱️ デプロイ所要時間: 422.4秒 (7.0分)
=== 従来方式: 結果 ===
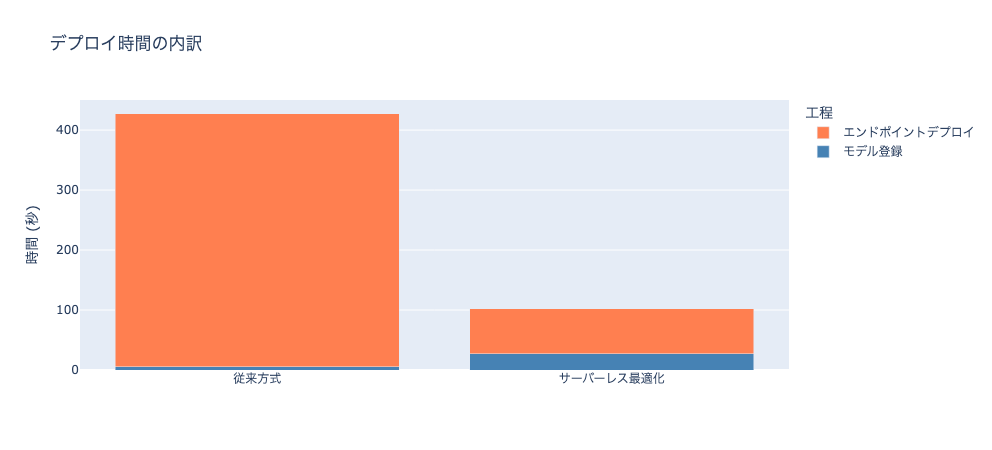
モデル登録時間: 5.2秒
エンドポイントデプロイ時間: 422.4秒
合計: 427.6秒
6. サーバーレス最適化方式でのデプロイ
6.1 モデルの記録と登録
env_pack パラメータを指定することで、サーバーレス最適化が有効になります。
print("=== サーバーレス最適化: モデル登録 ===")
with mlflow.start_run(run_name="optimized_model") as run:
model_info_optimized = mlflow.sklearn.log_model(
sk_model=model,
artifact_path="model",
signature=signature,
)
# サーバーレス最適化を有効にしてモデルを登録
start_time = time.time()
model_version_optimized = mlflow.register_model(
model_uri=model_info_optimized.model_uri,
name=registered_model_optimized,
env_pack=EnvPackConfig(name="databricks_model_serving")
)
registration_time_optimized = time.time() - start_time
print(f"✅ 登録完了: {registered_model_optimized}")
print(f"登録時間: {registration_time_optimized:.1f}秒")
実行結果:
モデル登録中 (サーバーレス最適化 - env_pack 使用)...
Registered model 'takaakiyayoi_catalog.default.serverless_optimized_iris_model' already exists. Creating a new version of this model...
Packing environment for Databricks Model Serving with install_dependencies True...
Installing model requirements...
🔗 Created version '2' of model 'takaakiyayoi_catalog.default.serverless_optimized_iris_model': https://xxxx.cloud.databricks.com/explore/data/models/takaakiyayoi_catalog/default/serverless_optimized_iris_model/version/2?o=5099015744649857
Staging model takaakiyayoi_catalog.default.serverless_optimized_iris_model version 2 for Databricks Model Serving...
✅ 登録完了: takaakiyayoi_catalog.default.serverless_optimized_iris_model
バージョン: 2
登録時間: 27.1秒
6.2 エンドポイント作成とデプロイ時間計測
create_endpoint(
ENDPOINT_NAME_OPTIMIZED,
registered_model_optimized,
str(model_version_optimized.version)
)
endpoint_optimized, deploy_time_optimized = wait_for_endpoint_ready(ENDPOINT_NAME_OPTIMIZED)
print(f"\n=== サーバーレス最適化: 結果 ===")
print(f"モデル登録時間: {registration_time_optimized:.1f}秒")
print(f"エンドポイントデプロイ時間: {deploy_time_optimized:.1f}秒")
print(f"合計: {registration_time_optimized + deploy_time_optimized:.1f}秒")
実行結果:
エンドポイント 'serverless-optimized-iris-endpoint' の準備を待機中...
状態: EndpointStateReady.NOT_READY (経過時間: 0秒)
状態: EndpointStateReady.NOT_READY (経過時間: 15秒)
状態: EndpointStateReady.NOT_READY (経過時間: 30秒)
状態: EndpointStateReady.NOT_READY (経過時間: 45秒)
状態: EndpointStateReady.NOT_READY (経過時間: 60秒)
✅ エンドポイントが Ready になりました
⏱️ デプロイ所要時間: 75.4秒 (1.3分)
=== サーバーレス最適化: 結果 ===
モデル登録時間: 27.1秒
エンドポイントデプロイ時間: 75.4秒
合計: 102.5秒
7. 結果の比較
print("=" * 60)
print("デプロイ時間比較")
print("=" * 60)
print()
print(f"{'項目':<30} {'従来方式':>12} {'最適化':>12} {'差分':>12}")
print("-" * 60)
print(f"{'モデル登録時間 (秒)':<30} {registration_time_traditional:>12.1f} {registration_time_optimized:>12.1f} {registration_time_optimized - registration_time_traditional:>+12.1f}")
print(f"{'エンドポイントデプロイ時間 (秒)':<30} {deploy_time_traditional:>12.1f} {deploy_time_optimized:>12.1f} {deploy_time_optimized - deploy_time_traditional:>+12.1f}")
print("-" * 60)
total_traditional = registration_time_traditional + deploy_time_traditional
total_optimized = registration_time_optimized + deploy_time_optimized
print(f"{'合計 (秒)':<30} {total_traditional:>12.1f} {total_optimized:>12.1f} {total_optimized - total_traditional:>+12.1f}")
if total_optimized < total_traditional:
improvement = (1 - total_optimized / total_traditional) * 100
print(f"\n✅ サーバーレス最適化により {improvement:.1f}% 高速化されました")
実行結果:
============================================================
デプロイ時間比較
============================================================
項目 従来方式 最適化 差分
------------------------------------------------------------
モデル登録時間 (秒) 5.2 27.1 +21.9
エンドポイントデプロイ時間 (秒) 422.4 75.4 -347.0
------------------------------------------------------------
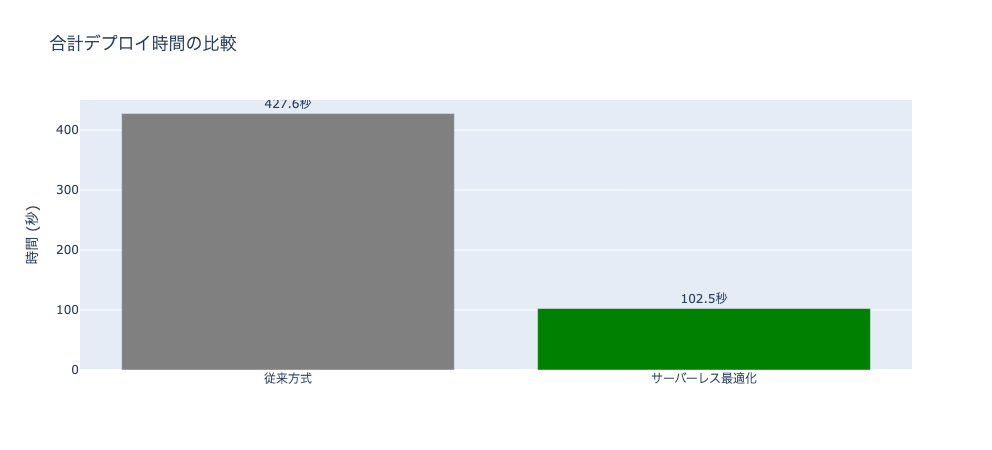
合計 (秒) 427.6 102.5 -325.1
合計 (分) 7.1 1.7 -5.4
✅ サーバーレス最適化により 76.0% 高速化されました
if RUN_TRADITIONAL and RUN_OPTIMIZED:
import plotly.graph_objects as go
import plotly.offline as pyo
# データ準備
labels = ['従来方式', 'サーバーレス最適化']
registration_times = [registration_time_traditional, registration_time_optimized]
deploy_times = [deploy_time_traditional, deploy_time_optimized]
totals = [registration_time_traditional + deploy_time_traditional,
registration_time_optimized + deploy_time_optimized]
colors = ['gray', 'green' if totals[1] < totals[0] else 'orange']
# 積み上げ棒グラフ
fig = go.Figure()
fig.add_trace(go.Bar(
x=labels,
y=registration_times,
name='モデル登録',
marker_color='steelblue'
))
fig.add_trace(go.Bar(
x=labels,
y=deploy_times,
name='エンドポイントデプロイ',
marker_color='coral'
))
fig.update_layout(
barmode='stack',
title='デプロイ時間の内訳',
yaxis_title='時間 (秒)',
legend_title_text='工程'
)
# 合計時間の比較
fig2 = go.Figure()
fig2.add_trace(go.Bar(
x=labels,
y=totals,
marker_color=colors,
text=[f'{v:.1f}秒' for v in totals],
textposition='outside'
))
fig2.update_layout(
title='合計デプロイ時間の比較',
yaxis_title='時間 (秒)'
)
# Databricksで表示
displayHTML(pyo.plot(fig, output_type='div'))
displayHTML(pyo.plot(fig2, output_type='div'))
8. クリーンアップ
def delete_endpoint(endpoint_name: str):
try:
w.serving_endpoints.delete(name=endpoint_name)
print(f"✅ エンドポイント '{endpoint_name}' を削除しました")
except Exception as e:
print(f"❌ 削除エラー: {e}")
delete_endpoint(ENDPOINT_NAME_TRADITIONAL)
delete_endpoint(ENDPOINT_NAME_OPTIMIZED)
実行結果:
エンドポイントを削除中...
✅ エンドポイント 'traditional-iris-endpoint' を削除しました
✅ エンドポイント 'serverless-optimized-iris-endpoint' を削除しました
考察
検証結果から、以下のことがわかります。
モデル登録時間:
- サーバーレス最適化では、環境のパッケージ化が行われるため登録時間が増加
- 従来方式に比べて数十秒〜数分長くなる
エンドポイントデプロイ時間:
- サーバーレス最適化では、コンテナビルドがスキップされるためデプロイが高速
- 従来方式に比べて大幅に短縮される
合計時間:
- 多くの場合、デプロイ時間の短縮が登録時間の増加を上回る
- 特に複雑な依存関係を持つモデルで効果が大きい
まとめ
サーバーレス最適化デプロイメントは、カスタムモデルのデプロイを高速化する機能です。
ポイント:
-
mlflow.register_model()でenv_packパラメータを指定するだけ - モデル登録時に環境がパッケージ化される (登録時間は増加)
- デプロイ時のコンテナビルドが不要になり、デプロイ時間が短縮
- トレーニング環境とサービング環境の一貫性が保証される
要件の再確認:
- サーバーレスノートブックを使用
- MLflow 3.1 以上
- カスタムモデル (基盤モデル API は対象外)
- Unity Catalog に登録
- CPU サービング
- 環境サイズ 1GB 以下