はじめに
Databricks上でRAG(Retrieval-Augmented Generation)アプリケーションを構築し、モデルサービングにデプロイしたとき、AI Playgroundでストリーミング(トークンが順次表示される)動作にならないという問題に直面しました。
本記事では、この問題の原因を特定し、Playground対応のストリーミングRAGエージェントを構築するまでの過程を解説します。
結論
- 外部モデルのストリーミング: 特別な設定は不要。Playgroundは自動的にストリーミングリクエストを送信する
-
カスタムモデル(LangChain等)のストリーミング:
ChatModel形式でラップし、predict_streamメソッドを実装する必要がある - o3/o4-miniの遅延: モデル自体の推論時間(thinking phase)が原因であり、Databricksの問題ではない
検証1: 外部モデルでのストリーミング確認
まず、外部モデルを使ってストリーミング動作を確認しました。
外部モデルの作成
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
client.create_endpoint(
name="external-gpt-4o",
config={
"served_entities": [{
"name": "gpt-4o",
"external_model": {
"name": "gpt-4o",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": "{{secrets/your-scope/openai_api_key}}"
}
}
}]
}
)
結果
どちらもストリーミングしていますが、モデルによってTTFT(Time To First Token)が異なります。

| モデル | TTFT | ストリーミング |
|---|---|---|
| Claude Sonnet 4(FMAPI) | 1-3秒 | スムーズ |
| GPT-4o(外部モデル) | 1-2秒 | スムーズ |
| o4-mini(外部モデル) | 2-3秒以上 | 遅延後に出力 |
外部モデルの場合、特別な設定なしでPlaygroundからストリーミング利用可能です。o4-miniの遅延はモデル内部の推論フェーズによるものです。
検証2: LangChain RAGチェーンの問題
LangChainでRAGチェーンを構築してデプロイしたところ、Playgroundから利用できない問題が発生しました。
原因
PlaygroundはChatCompletion API形式(messages形式)でリクエストを送信します。単純なLangChainチェーンは文字列入出力のため、形式が合いません。
Playgroundと互換性を持たせるにはAgent Frameworkに準拠する必要があります。
参考: コードで AI エージェントを作成する | Databricks
解決策: ChatModelでラップする
LangChainチェーンをmlflow.pyfunc.ChatModelでラップし、predictとpredict_streamメソッドを実装します。
エージェント定義(rag_agent.py)
import mlflow
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import ChatMessage, ChatParams, ChatCompletionResponse, ChatCompletionChunk
from mlflow.langchain.output_parsers import ChatCompletionOutputParser
from databricks_langchain import ChatDatabricks, DatabricksEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from typing import List, Generator, Optional
mlflow.langchain.autolog()
config = mlflow.models.ModelConfig(development_config="agent_config.yaml")
LLM_ENDPOINT = config.get("llm_endpoint")
EMBEDDING_ENDPOINT = config.get("embedding_endpoint")
MAX_TOKENS = config.get("max_tokens")
RETRIEVER_K = config.get("retriever_k")
DOCUMENTS = [
"Databricks は、データエンジニアリング、データサイエンス、機械学習のための統合プラットフォームです。",
"Unity Catalog は Databricks のデータガバナンスソリューションです。",
"MLflow は機械学習のライフサイクル管理ツールです。",
"Delta Lake はオープンソースのストレージレイヤーです。",
]
embeddings = DatabricksEmbeddings(endpoint=EMBEDDING_ENDPOINT)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=50)
splits = text_splitter.create_documents(DOCUMENTS)
vectorstore = FAISS.from_documents(splits, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": RETRIEVER_K})
llm = ChatDatabricks(endpoint=LLM_ENDPOINT, max_tokens=MAX_TOKENS)
prompt = ChatPromptTemplate.from_template("""
以下のコンテキストを参考に質問に答えてください。
コンテキスト:
{context}
質問: {question}
回答:
""")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| ChatCompletionOutputParser()
)
class RAGAgent(ChatModel):
def __init__(self):
self.chain = chain
def _get_question(self, messages: List[ChatMessage]) -> str:
for msg in reversed(messages):
if msg.role == "user":
return msg.content
return ""
def predict(self, context, messages: List[ChatMessage], params: ChatParams) -> ChatCompletionResponse:
question = self._get_question(messages)
response = self.chain.invoke(question)
return ChatCompletionResponse.from_dict(response)
def predict_stream(self, context, messages: List[ChatMessage], params: ChatParams) -> Generator[ChatCompletionChunk, None, None]:
question = self._get_question(messages)
for chunk in self.chain.stream(question):
yield ChatCompletionChunk.from_dict(chunk)
mlflow.models.set_model(RAGAgent())
ポイント
-
ChatModelを継承: Playgroundと互換性のある入出力形式を提供 -
ChatCompletionOutputParser: LangChainの出力をChatCompletion形式に変換 -
predict_streamメソッド: ストリーミング出力を実装 -
mlflow.langchain.autolog(): トレース機能を有効化
モデルのログ
import mlflow
from mlflow.models.resources import DatabricksServingEndpoint
mlflow.set_registry_uri("databricks-uc")
input_example = {"messages": [{"role": "user", "content": "MLflow について教えてください"}]}
with mlflow.start_run(run_name="rag_agent") as run:
model_info = mlflow.pyfunc.log_model(
python_model=agent_path,
artifact_path="agent",
model_config=config_path,
input_example=input_example,
pip_requirements=[
"mlflow", "databricks-langchain", "langchain", "langchain-core",
"langchain-community", "langchain-text-splitters", "faiss-cpu", "pyyaml",
],
resources=[
DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT),
DatabricksServingEndpoint(endpoint_name=EMBEDDING_ENDPOINT),
],
registered_model_name=MODEL_NAME,
)
エンドポイント作成
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
config = EndpointCoreConfigInput(
name=ENDPOINT_NAME,
served_entities=[
ServedEntityInput(
entity_name=MODEL_NAME,
entity_version=str(latest_version),
workload_size="Small",
scale_to_zero_enabled=True,
)
],
)
w.serving_endpoints.create(name=ENDPOINT_NAME, config=config)
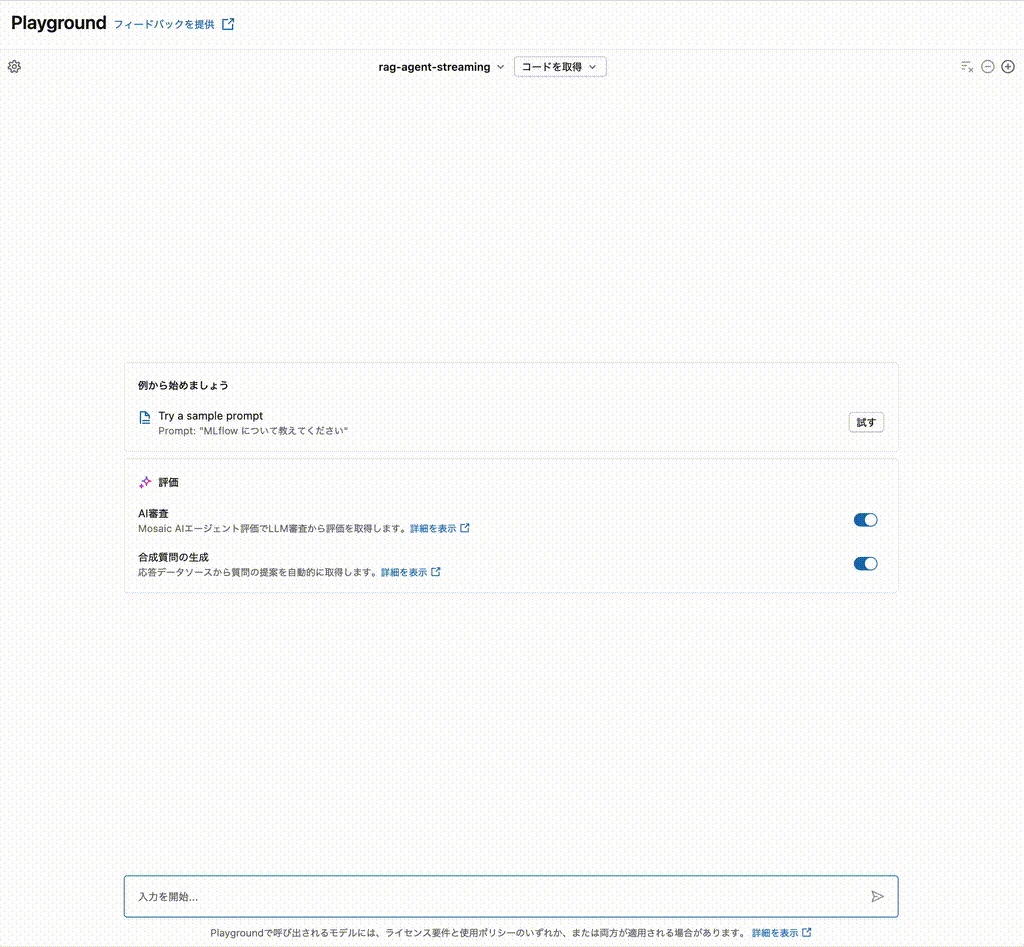
エンドポイントがREADYになったらPlaygroundで動作確認します。
ストリーミングしています。
まとめ
| パターン | Playgroundストリーミング | 必要な対応 |
|---|---|---|
| 外部モデル | ✅ そのまま動作 | なし |
| LangChainチェーン(単純) | ❌ 動作しない | ChatModelでラップ |
| ChatModel形式エージェント | ✅ 動作 | predict_stream実装 |
カスタムモデルをPlaygroundでストリーミング利用するには、ChatModel形式でラップし、predict_streamメソッドを実装することが必要です。
ノートブック
完全なノートブックはGitHubで公開しています。
参考リンク
- コードで AI エージェントを作成する | Databricks on AWS
- AI Playgroundにおけるツール呼び出しエージェントのプロトタイピング | Databricks
- MLflow ChatModel